






结构方程模型(Structural Equation Modeling,SEM)是一种建立、估计和检验因果关系模型的方法,其核心在于分析变量间协方差。构建一个SEM模型首先根据数据集的实际含义模拟关联路径,进而拟合SEM模型并进行检验。如果模型效果不佳,再回到第一步重新调整路径直到模型通过检测。
SEM相关概念
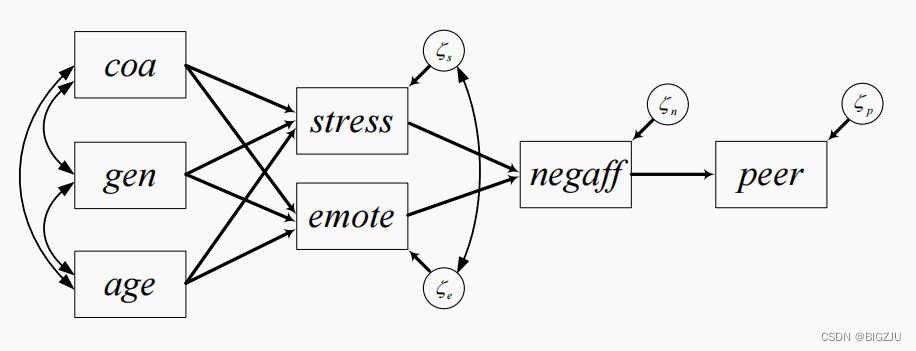
结构方程模型中的变量可分类成内生变量和外生变量两类。外生变量不受模型中其他因素影响(即没有指向其的单向箭头),而内生因素受到其他因素的影响(有指向其的单向箭头)。如下图中的变量coa、gen和age为外生变量,其余均为内生变量,圆圈中的为残差。

SEM可分成观测模型和路径模型两部分。如下图中探究心梗患者创伤后成长(Posttraumatic Growth)的模型,观测模型以蓝色蓝色框线内为例,pro(subjective evaluation of prognosis)、th(threat to future health)、time(time since diagnosis)为实际测量的项目,共同构成潜在变量(Event Related Factors)。而路径模型则涉及到各潜在因子的相关关系,如红色框线中的五个潜在变量之间的关联,可以通过回归方程描述。

SEM构建示例
SEM构建可以分成回归方程(路径模型,‘~’连接)、潜变量定义(观测模型,‘=~’连接)、方差和协方差(经验性判断变量残差是否关联,‘~~’连接)及截距项四个部分。

以《Associations of dietary patterns with brain health from behavioral, neuroimaging, biochemical and genetic analyses》的模型为例,探究饮食偏好、精神健康、大脑结构间的潜在关联。
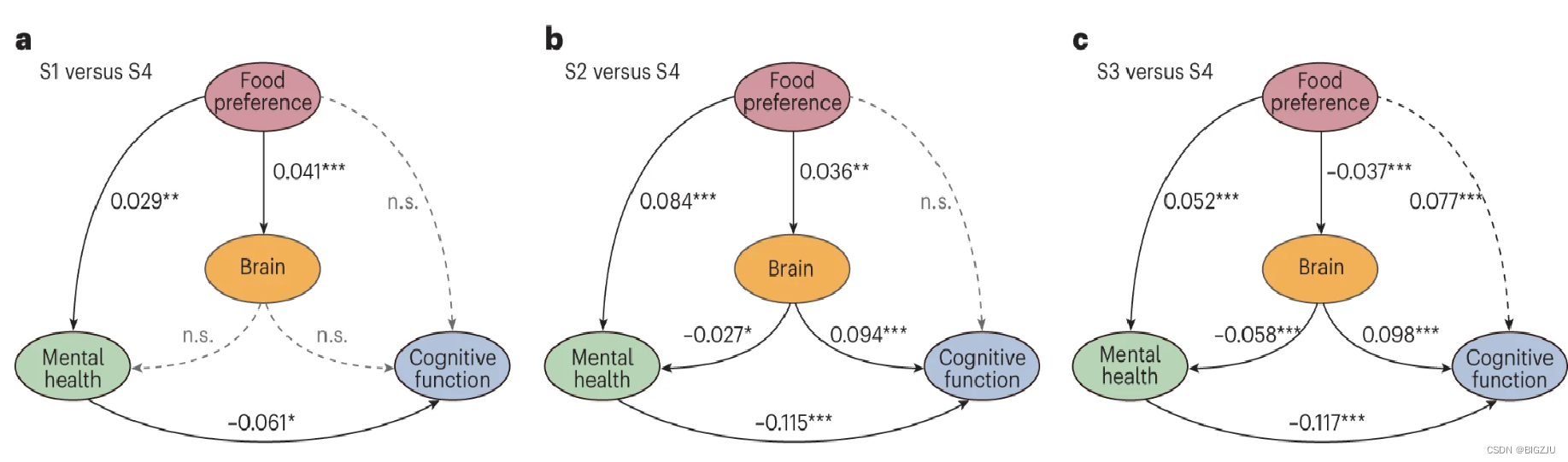
以c中的模型为例,第一部分measurement model分成:精神健康(mentalL)可由MHQ量表中的焦虑、抑郁、自我伤害、创伤和幸福感构建,认知功能则由cogitionL式中的三项测量指标构建,大脑结构由MRI中显著差异的脑区构建。
第二部分structural model 则描述了图c中精神健康、认知功能和大脑结构的关系,等式左侧为被箭头指向的变量,右边为发出箭头的变量。构建完成后将模型放入sem函数进行拟合。

代码演示及结果解读
代码参考来源:R语言保姆级教程/结构方程模型SEM/全B站最牛逼,没有之一_哔哩哔哩_bilibili
SEM模型使用R包‘lavaan’建立,‘semPlot’用于绘图。使用lavaan中描述中学生智力的内置数据集(HolzingerSwineford1939)。智力水平可由visual、textual(或verbal)、speed评估。
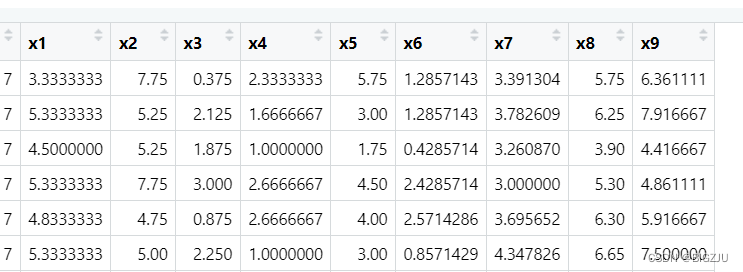
数据集展示如下,x1-9对应具体智力测量项目。视觉因子(visual)对应x1,x2,x3;文本因子(textual)对应x4,x5,x6;速度因子(speed)对应x7,x8,x9。
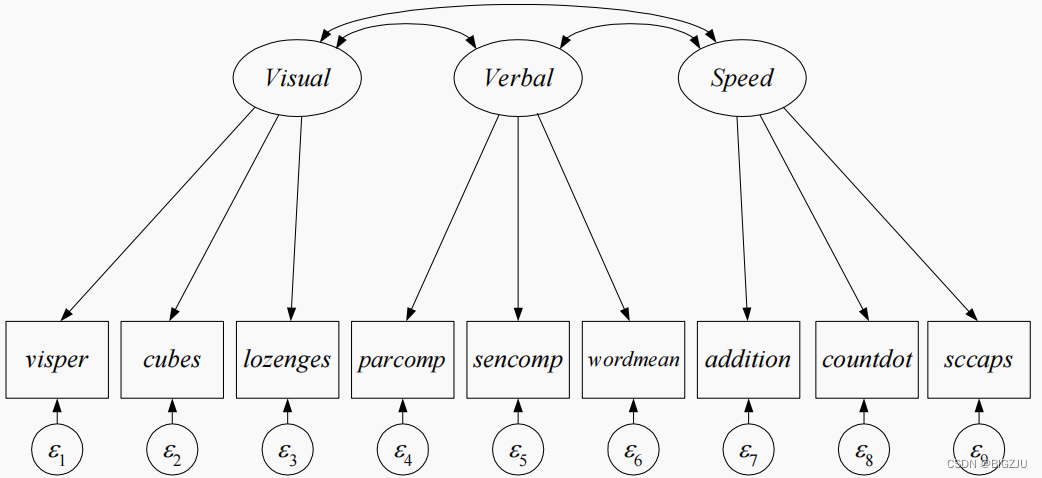
构建如下图所示的模型(仅观测模型)
代码如下
#载入包和data
install.packages("lavaan", dependencies = TRUE) # 安装lavaan包
install.packages("semPlot")
library(lavaan) # 载入lavaan包
library(semPlot)
data(HolzingerSwineford1939)
##仅观测模型
HS.model <- ' visual =~ x1 + x2 + x3
textual =~ x4 + x5 + x6
speed =~ x7 + x8 + x9 '
fit <- sem(HS.model, data=HolzingerSwineford1939)
summary(fit, fit.measures=TRUE, standard=TRUE)
拟合模型结果如下,只需要看P值和std.all(标准化载荷)。std.all即测量因素与潜变量间或回归模型变量间的相关程度(即相关系数或标准化回归系数)。std.all也是最后呈现在图中的数据。
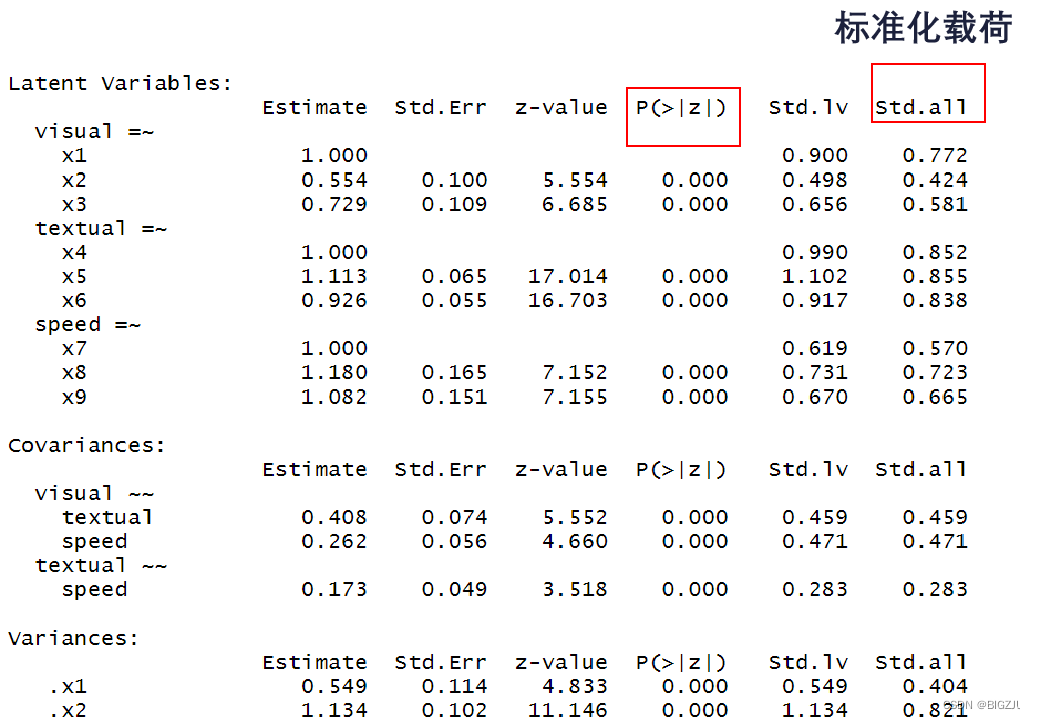
进一步检验模型效果,可以采用多种方式检验。
#检验模型效果
fitMeasures(fit,c("chisq","df","pvalue",
"gfi","cfi","rmr","srmr","rmsea"))
#结果如下
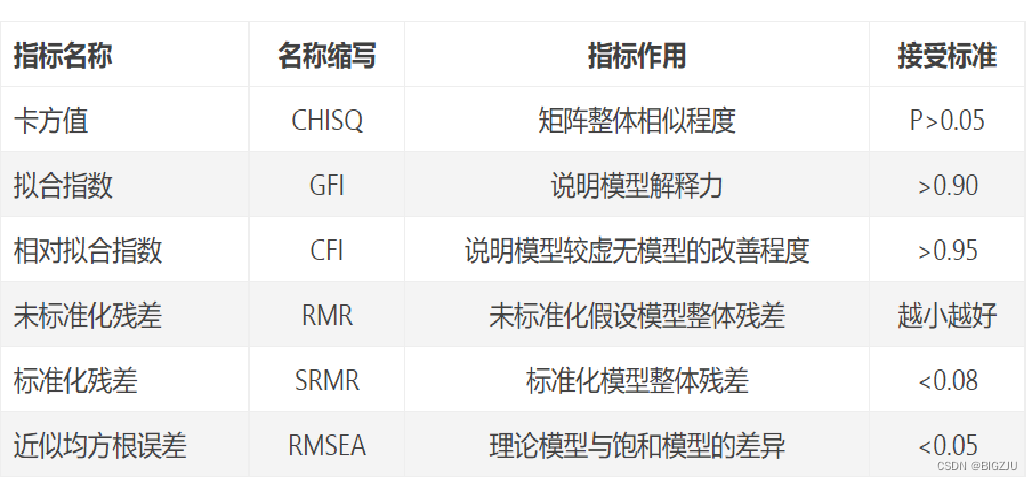
chisq df pvalue gfi cfi rmr srmr rmsea
85.306 24.000 0.000 0.943 0.931 0.082 0.065 0.092 根据下图的接受标准,只有GFI符合接受标准,说明上述模型效果不佳,需要进一步调试初始HS.model。
 SEM模型也可纳入路径。速度可能与视觉和文本(语言)相关,因此可构建如下模型:
SEM模型也可纳入路径。速度可能与视觉和文本(语言)相关,因此可构建如下模型:
#观测模型+路径模型
HS.model<- ' visual =~ x1 + x2 + x3
textual =~ x4 + x5 + x6
speed =~ x7 + x8 + x9
speed ~ visual + textual'
fit <- sem(HS.model, data=HolzingerSwineford1939)
summary(fit, fit.measures=TRUE, standard=TRUE)
回归项中visual和speed显著关联,而textual与speed关联不显著。
 最后将上述关系做图,使用semPlot包中的semPaths函数。
最后将上述关系做图,使用semPlot包中的semPaths函数。
##作图
semPaths(fit, #上面跑出来的数据模型
what = "std", #图中边的格式,#"path","std","est ","cons "
layout = "tree2", #图的格式, tree circle spring tree2 circle2
fade = F, #褪色,按照相关度褪色
residuals = F ,#残差/方差要不要体现在图中,可T和F
nCharNodes = 0)最终结果如下,直线箭头表示相关系数,弧线表示协方差。
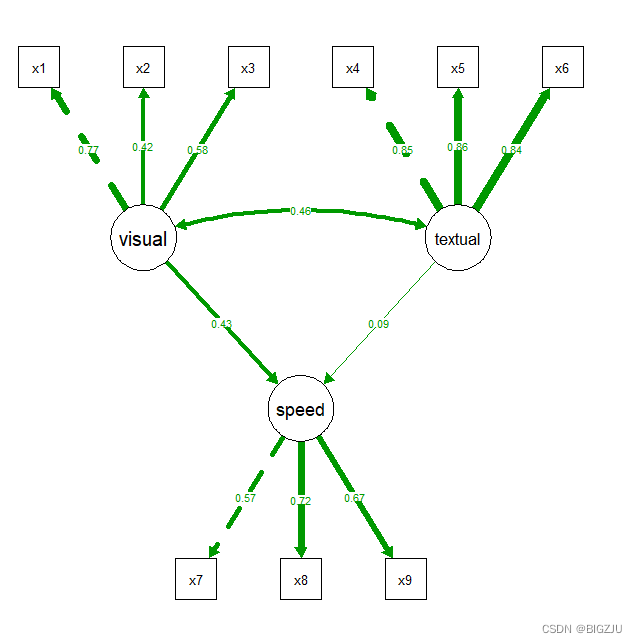

















 812
812

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









