






一.断点回归分析
1.断点回归分析:其基本思想是假设存在一个连续变量, 该变量能决定个体在某一临界点两侧接受政策干预的概率, 由于X在该临界点两侧是连续的, 因此个体针对X的取值落入该临界点任意一侧是随机发生的, 即不存在人为操控使得个体落入某一侧的概率更大, 则在临界值附近构成了一个准自然实验。类似于在临界点两侧形成了局部的随机对照实验。
2.分类:断点回归分析主要分为两类,精确断点回归与模糊断点回归。
精确断点回归设计(SRD):特征是在断点 (也就是上面所说的临界点) x=c处, 个体接受政策干预的概率从0跳跃到1;
模糊断点回归设计(FRD):在断点x=c处, 个体接受政策干预的概率从a变为b, 其中a≠b,且a,b处于0-1之间。
3.断点回归分析的模型解释:断点回归分析需要确定驱动变量(x),结果变量(y),临界值/断点(c)以及干预措施(D)。
假设在实验之前,结果变量y与x之间存在如下线性关系:
![]()
若存在一个临界值c,当x>c时,个体会接受干预措施D,此时,变量y可能会发生改变,为让图更加好看,我们使整体沿x轴向左平移c个单位,则y与x的关系此时可表示为:

但实际情况中,y与x并非绝对的线性关系,因此我们会使用多次项方程来使曲线更接近实际的变化曲线。
4.断点回归的平均处理效应估计:其平均处理效应的估计主要有全局参数估计和局部非参数估计两种方法。全局参数估计即以全部数据来进行分析,而局部非参数估计则是在临界值左右两侧确定不同或相同的带宽,仅针对临界值附近的局部数据进行分析。两种分析均可进行线性回归和多次项回归模型,并可由AIC选择最合适的模型。不同的是,局部非参数估计还需要确定最优带宽。
5.断点回归需要满足的条件:
(1)干预措施在断点处存在跳跃。
(2)驱动变量在断点处无明显跳跃,即近似连续曲线,说明其不受人为干预。
(3)非结局变量在断点处不存在跳跃。
6.断点回归分析的一般过程
(1)驱动变量与干预措施之间的关系图:通过绘制散点图和拟合线等方式观察干预措施在断点处是否存在跳跃。只有存在跳跃才能进行断点回归分析。
(2)驱动变量的密度分布图:可以使用rddensity命令检验配置变量的概率密度函数,判断驱动变量是否被操纵;也可以画出驱动变量的分布图,一般可采用直方图,箱体的宽度尽量小,驱动变量若未被操控,则分布图应近似光滑的曲线,无明显的跳跃。
(3)非结局变量与驱动变量的关系图:进行局部平滑性检验,确认除结果变量外,其他相关的非结局变量在断点附近需不存在跳跃,可以通过绘制散点图加以检验。
(4)结局变量与驱动变量的关系图:可以帮助初步预估干预效应的大小,以及初步判断结局变量与驱动变量之间的函数关系。
(5)带宽的选择:局部估计可直接利用rdrobust函数中的bdselect参数指定选择最优带宽的方法。 带宽选择还可以先利用rdbwselect函数计算出最优带宽,然后用rdrobust函数中的h参数手动指定左右的带宽。
(6)平均处理效应的估计:效应大小的估计方法一共有两种。
a.全局参数估计(Parametric/global strategy): 即是利用全部个体的数据,对驱动变量和结局变量拟合线性、二次项、三次项、四次项回归模型。 可表示未yi = α + β0 ⋅ Di+ β1 ⋅ (xi − c)^k + β2 ⋅ D ⋅ (xi − c)^k + β3 ⋅ Confoudersi + ϵi。β0就是核心关注的系数,表示干预措施在断点处的边际效应,也就是干预的处理效应。驱动变量减去cutpoint的目的是为了中心化,为了使α反映的是断点处的平均值,因为差值在断点处为0。至于如何如何选择合适的次项数,需要多次尝试,通过比较AIC,选择AIC最小的模型。合适的次幂能是方程曲线与实际曲线更好地重合。但是全局估计又容易产生内生性问题。
b.局部非参数估计(Nonparametric/local strategy): 即是在cut-point左右选择一段合适的带宽(bandwidth),在这一段带宽局部范围内,拟合驱动变量和结局变量的线性或者多项式回归模型。此方法适用于样本量较大的情况,因为样本量太少,设定带宽之后样本量将会不足,增加估计误差。局部非参数估计需要使用带宽,故需要对带宽进行最优选择。
(7)敏感性分析:检验模型估计结果的稳健性,断点回归分析主要有四种敏感性分析方式。
a.针对非结局变量:除了干预变量外,其他的任何非结局变量(包括混杂因素在内)都不能在断点处出现不连续或称为跳跃,如果存在,则无法推断结局变量的跳跃是由干预引起的,检验方式就是将所有的混杂因素作为结局,利用rdrobust函数进行检验,输出结果的coef应该很小,且p值应该统计学不显著。
b.针对断点的敏感性分析:更换断点,检验是否左右还存在处理效应,如果更换断点后,仍然存在处理效应,则无法说明本研究的干预措施是有效的,这说明在研究设定的断点处识别到的处理效应,有可能是由其他因素引起的。
c.针对断点附近个体的敏感性分析:驱动变量不可被操控,但是这个无法直接检验,因此,换个思路,如果驱动变量被超控,那自然是在断点左右离得最近的值被操纵的可能性最大,所以如果将这部分个体剔除,若仍然能观测到处理效应,则说明这种效应是真实由干预所导致。
d.针对带宽的敏感性分析:即断点不改变,但更换选择的最优带宽,进行多次局部非参数检验,如果更换带宽之后,仍然能在断点处识别的处理效应,说明研究的干预措施是有效的,因为在研究设定的断点处识别到的处理效应不是由于某一特点的带宽下才观测到的,说明处理效应稳健。
(8)关于模糊断点回归:rdrobust包的rdrobust函数中,有一个fuzzy的逻辑参数,用来指定RD类型是否为fuzzy,可以很方便的进行fuzzy类型的模型估计。
二.R语言代码
R语言进行断点回归分析常用的包:rdrobust。
这里我们使用rdrobust中的一个数据集,RDsenate.其主要有两个变量。
vote:表示某次选举民主党在州参议院的席位占比,值从0到100,是RD分析中结局变量。 margin:表示民主党上次选举中获得参议院一定席位的边际收益,其值为-100至100,其中大于0表示民主党胜出,反之则为失败。可以理解为民主党在上次选举中获得一定席位所产生的对民主党有利的效应。大于0说明民主党胜出,为正面影响。
这里我们利用RDD估计民主党在上次参议院席位中是否胜出对其在下次选举中获得该席位的选票份额的影响。
读取数据
#R语言进行断点回归分析常用的包:rdrobust
install.packages("rdrobust")
install.packages("rddensity")
install.packages("tidyverse")
install.packages("stargazer")
library(rdrobust)
library(rddensity)
library(magrittr)
library(ggplot2)
library(tidyverse)
library(stargazer)
data(rdrobust_RDsenate)
head(rdrobust_RDsenate)
#vote:表示某次选举民主党在州参议院的席位占比,值从0到100,是RD分析中结局变量
#margin:表示上次选举中获得相同参议院席位的边际收益,其中大于0表示民主党胜出,反之则为失败。
#利用RDD估计民主党赢得参议院席位对其在下次选举中获得该席位的选票份额的影响
margin vote
1 -7.6885610 36.09757
2 -3.9237082 45.46875
3 -6.8686604 45.59821
4 -27.6680565 48.47606
5 -8.2569685 51.74687
6 0.7324815 39.80264
检验驱动变量是否受到操控,从直方图来看,没有明显的跳跃点。
#检验驱动变量是否受到操控
#驱动变量的直方图,若大致呈现光滑曲线,无明显的断点,说明不受到操控。
hist(x = rdrobust_RDsenate$margin, breaks = 200, col = 'black',
xlab = 'margin', ylab = 'Frequance', main = 'Histogram of Rating Variable')
#或者使用也可以利用rddenstiy包中的rddenstiy函数画密度图,
#输出结果中,最下面一行robust的p值大于0.05,就说明驱动变量未受到操纵。
rdplotdensity(rddensity(rdrobust_RDsenate$margin), X = rdrobust_RDsenate$margin)
画驱动变量与干预的散点图,判断为sharp还是fuzzy类型,从结果看,本例属于精确断点回归类型。
#画驱动变量与干预的散点图,判断为sharp还是fuzzy类型
#可见本例断点前后干预率0-1,基本可判断为sharp类型
rdrobust_RDsenate$treatment <- ifelse(rdrobust_RDsenate$margin < 0, 0, 1)
rdrobust_RDsenate$color <- ifelse(rdrobust_RDsenate$margin < 0, 'blue', 'red')
plot(x = rdrobust_RDsenate$margin, y = rdrobust_RDsenate$treatment, col = rdrobust_RDsenate$color,
type = 'p', pch = 16, xlab = 'Margin', ylab = 'Treatment',
main = 'Relationship between rating variable and treatment') 画驱动变量与结果变量的关系图,初步看一下关系。从图中可以看到,似乎存在一个断点,但并非很清晰。
画驱动变量与结果变量的关系图,初步看一下关系。从图中可以看到,似乎存在一个断点,但并非很清晰。
#画驱动变量与结果变量的关系图
#散点图初步判定关系
plot(x = rdrobust_RDsenate$margin, y = rdrobust_RDsenate$vote, type = 'p',
col = rdrobust_RDsenate$color, pch = 16, cex = 0.8, xlab = 'Margin', ylab = 'Vote')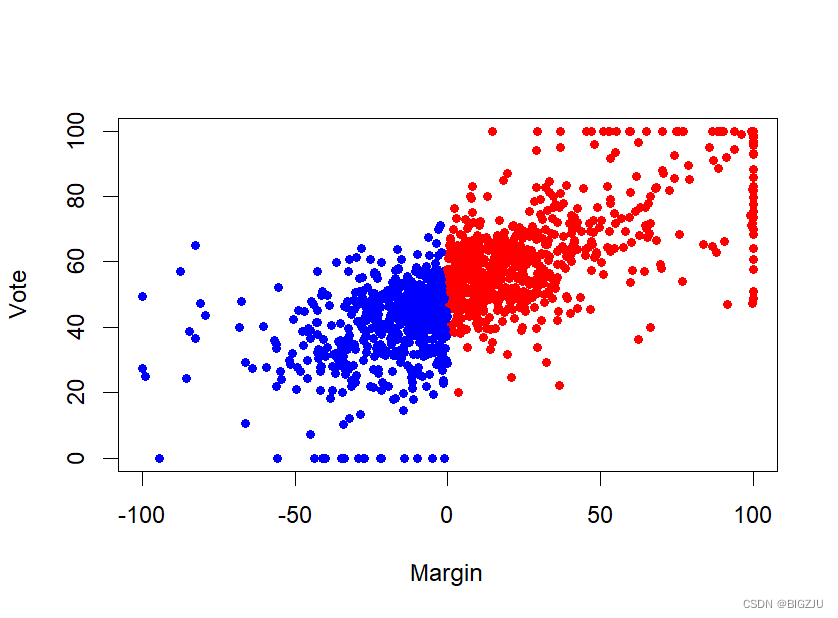
进行曲线拟合,可以清晰看到存在断点。
#拟合图
#将驱动变量分成若干宽度(width)相等的区间(bin),但不能存在骑跨断点,断点两侧的区间数量可不相等
#选择合适的区间和带宽。可以采用rdrobust包中的rdplot函数进行判断
bins <- rdplot(rdrobust_RDsenate$vote, rdrobust_RDsenate$margin, c = 0, p = 4,
nbins = c(20, 20), binselect = 'esmv', kernel = 'uniform')
summary(bins)
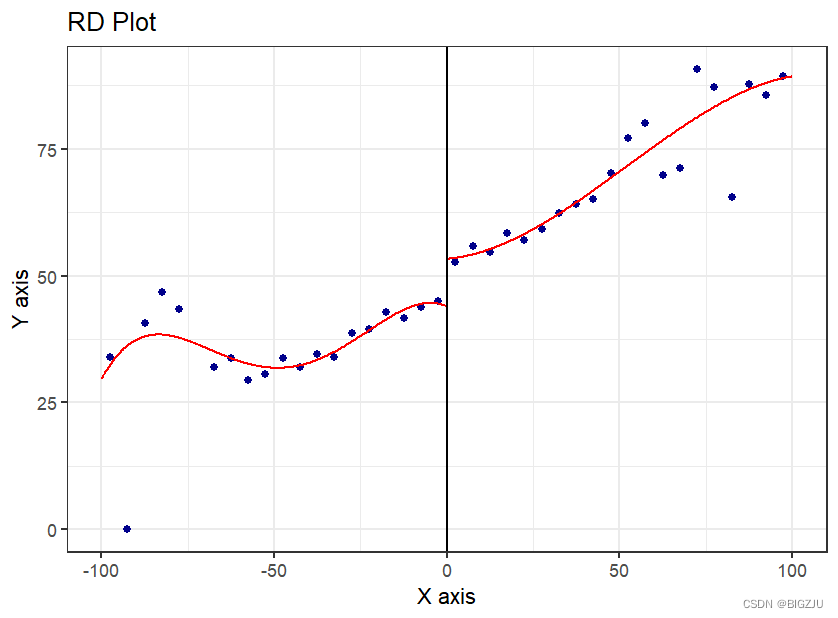
优化曲线拟合,选取断点附近局部拟合。
#进一步缩小样本范围(-50,50),提升拟合效果
rdrobust_RDsenate2<-subset(rdrobust_RDsenate,
rdrobust_RDsenate$margin>-50&rdrobust_RDsenate$margin<50,
select = margin:vote)
rdplot(rdrobust_RDsenate2$vote, rdrobust_RDsenate2$margin, c = 0, p = 4,nbins = c(20, 20),
title="四次型拟合",ci=95)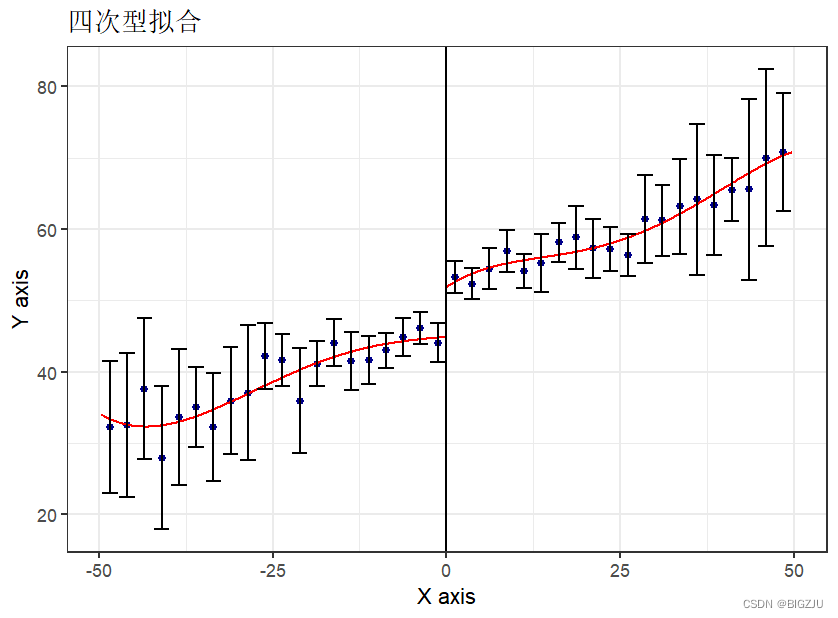
全局参数估计
#全局参数估计
rdrobust_RDsenate$margin_del <- rdrobust_RDsenate$margin - 0
# linear
fit_1 <- lm(vote ~ margin_del + treatment, data = rdrobust_RDsenate)
# linear interaction
fit_2 <- lm(vote ~ margin_del * treatment, data = rdrobust_RDsenate)
# quadratic
fit_3 <- lm(vote ~ margin_del + I(margin_del ^ 2) + treatment, data = rdrobust_RDsenate)
# quadratic interaction
fit_4 <- lm(vote ~ (margin_del + I(margin_del ^ 2)) * treatment, data = rdrobust_RDsenate)
# cubic
fit_5 <- lm(vote ~ margin_del + I(margin_del ^ 2) + I(margin_del ^ 3) + treatment, data = rdrobust_RDsenate)
# cubic interaction
fit_6 <- lm(vote ~ (margin_del + I(margin_del ^ 2) + I(margin_del ^ 3)) * treatment, data = rdrobust_RDsenate)
stargazer::stargazer(fit_1, fit_2, fit_3, fit_4, fit_5, fit_6, type = 'html', style = 'all')#输出表格形式的结果
#比较AIC或者回归残差,较小者模型较优。
AIC(fit_1, fit_2, fit_3, fit_4, fit_5, fit_6)
df AIC
fit_1 4 10083.70
fit_2 5 10056.71
fit_3 5 10049.89
fit_4 7 10048.72
fit_5 6 10046.19
fit_6 9 10045.74局部非参数估计
#局部非参数估计
#利用rdrobust包的rdrobust函数进行拟合。
#局部估计可直接利用rdrobust函数中的bdselect参数指定选择最优带宽的方法。
#带宽选择还可以先利用rdbwselect函数计算出最优带宽,然后用rdrobust函数中的h参数手动指定左右的带宽。
#rdbwselect方法
#结果中前缀mse更适用于进行点估计的带宽选择,而cer更适合区间估计的带宽选择。后缀rd指两侧区间相等,而two则不相等
#结果中h即为选择的左右最优带宽,而b给出的是用来进行敏感性分析时应该考虑的带宽。
rdbwselect(y = rdrobust_RDsenate$vote, x = rdrobust_RDsenate$margin, all = TRUE) %>% summary()
#拟合,c用来指定cut-point,p用来指定局部加权回归的多项式幂次,kernel为选择的核函数
loc_fit_1 <- rdrobust(rdrobust_RDsenate$vote, rdrobust_RDsenate$margin, c = 0, p = 1,
kernel = 'triangular', bwselect = 'mserd',h=17.754)# 如果有混杂因素需要控制,可以用covs = c('var1', 'var2')
loc_fit_2 <- rdrobust(rdrobust_RDsenate$vote, rdrobust_RDsenate$margin, c = 0, p = 2,
kernel = 'triangular', bwselect = 'msetwo',h=17.754)
summary(loc_fit_1)
summary(loc_fit_2)#结果中coef即为效应值
#结果
Sharp RD estimates using local polynomial regression.
Number of Obs. 1297
BW type Manual
Kernel Triangular
VCE method NN
Number of Obs. 595 702
Eff. Number of Obs. 360 323
Order est. (p) 2 2
Order bias (q) 3 3
BW est. (h) 17.754 17.754
BW bias (b) 17.754 17.754
rho (h/b) 1.000 1.000
Unique Obs. 595 702
=============================================================================
Method Coef. Std. Err. z P>|z| [ 95% C.I. ]
=============================================================================
Conventional 8.321 2.065 4.030 0.000 [4.274 , 12.368]
Robust - - 4.167 0.000 [6.017 , 16.704]
=============================================================================敏感性分析
1.对cut-point的敏感性分析
#对cut-point的敏感性分析
#选择一个虚拟的断点用来替换真正的断点,但是真实的干预情况不改变。
#虚拟断点选择并没有明确的标准,通常在真实断点的附近,左右对称选取即可
sen_cut_1 <- rdrobust(rdrobust_RDsenate$vote, rdrobust_RDsenate$margin, c = 5, p = 2,
kernel = 'triangular', bwselect = 'certwo') # 除c意外的其他参数应该与前面分析保持一致
sen_cut_2 <- rdrobust(rdrobust_RDsenate$vote, rdrobust_RDsenate$margin, c = -5, p = 2,
kernel = 'triangular', bwselect = 'certwo') # 除c意外的其他参数应该与前面分析保持一致
summary(sen_cut_1)
summary(sen_cut_2)2.对cut-point附近个体的敏感性分析
#对cut-point附近个体的敏感性分析
#对称剔除真实断点左右一定较小范围内的个体。
#关于范围的大小同样没有明确的标准,通常选取多个范围比较即可。
rdrobust_RD_hole_1 <- subset(rdrobust_RDsenate, abs(margin) > 0.3)
rdrobust_RD_hole_2 <- subset(rdrobust_RDsenate, abs(margin) > 0.4)
sen_hole_1 <- rdrobust(rdrobust_RD_hole_1$vote, rdrobust_RD_hole_1$margin, c = 0, p = 2,
kernel = 'triangular', bwselect = 'msetwo') # 除c意外的其他参数应该与前面分析保持一致
sen_hole_2 <- rdrobust(rdrobust_RD_hole_2$vote, rdrobust_RD_hole_2$margin, c = 0, p = 2,
kernel = 'triangular', bwselect = 'msetwo') # 除c意外的其他参数应该与前面分析保持一致
summary(sen_hole_1)
summary(sen_hole_2)
3.对不同带宽的敏感性分析
#对带宽bandwidth的敏感性分析
#更换不同的带宽即可
loc_fit_3 <- rdrobust(rdrobust_RDsenate$vote, rdrobust_RDsenate$margin, c = 0, p = 2,
kernel = 'triangular', bwselect = 'mserd',h=28.028)# 如果有混杂因素需要控制,可以用covs = c('var1', 'var2')
loc_fit_4 <- rdrobust(rdrobust_RDsenate$vote, rdrobust_RDsenate$margin, c = 0, p = 2,
kernel = 'triangular', bwselect = 'msetwo',h=20.086)
summary(loc_fit_3)
summary(loc_fit_4)以上即为断点回归分析的大致过程。

















 1404
1404

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









