






文章目录
在计算机科学的广袤领域中,拓扑排序犹如一颗璀璨的明珠,特别是在处理有向无环图(DAG)的相关问题时,其重要性不言而喻。今天,让我们一同深入探究拓扑排序在 C++ 中的奥秘。
基本概念
拓扑排序,简单来说,就是对有向无环图的顶点进行一种特定的排序。这种排序需满足对于图中的每条有向边 (u, v) ,顶点 u 总是在排序中位于顶点 v 之前。这种排序方式清晰地反映了顶点之间的先后依赖关系。
为了更直观地理解,想象一个项目流程,其中不同的任务之间存在着先后顺序的约束。比如,任务 A 必须在任务 B 开始之前完成,任务 B 又依赖于任务 C 的结束。通过拓扑排序,我们能够准确地确定这些任务的执行顺序,从而避免混乱和错误。
拓扑排序就是将一张图拍扁,变成一个序列A,满足:对于图中的每条边 (x,y),x在 A 中都出现在 y 之前,则称 A 是该图的一个拓扑序列。
应用场景
拓扑排序在众多领域都有着广泛且关键的应用:
-
任务调度:在复杂的项目管理中,各种任务之间的依赖关系错综复杂。通过拓扑排序,可以科学地规划任务的执行顺序,确保项目的顺利进行。
- 例如,在软件开发中,模块的编译顺序至关重要。某些模块可能需要依赖其他模块先完成编译,否则会出现错误。通过拓扑排序,能够准确地确定编译的先后顺序,提高开发效率,减少错误。
-
课程安排:在学校的课程体系中,课程之间往往存在先修关系。有的课程必须在完成某些先修课程之后才能学习。利用拓扑排序,可以合理地安排课程的学习顺序,使学生能够循序渐进地掌握知识。
-
数据库操作:在数据库的事务处理中,不同的操作可能存在依赖关系。拓扑排序有助于确定操作的执行顺序,保证数据的一致性和完整性。
-
电路设计:在电子电路的设计中,元件之间的连接和信号传递存在先后顺序。拓扑排序可以帮助设计人员规划电路的布局和信号流向。
求法
我们检查每一个点的入度,入度为0说明已经没有其他点应该在他之前进入序列了,那就把他放进序列里,并把所有和他相连的点的
实现拓扑排序的常见方法
- 使用深度优先搜索(DFS)
深度优先搜索是一种遍历图或树的经典算法。在拓扑排序中,通过深度优先搜索,可以从某个起始顶点开始,沿着有向边尽可能深入地探索,直到无法继续,然后回溯。
以下是使用深度优先搜索实现拓扑排序的 C++ 代码示例:
#include <iostream>
#include <vector>
#include <stack>
using namespace std;
void dfs(vector<vector<int>>& graph, int v, vector<bool>& visited, stack<int>& st) {
visited[v] = true;
for (int i = 0; i < graph[v].size(); ++i) {
if (!visited[graph[v][i]]) {
dfs(graph, graph[v][i], visited, st);
}
}
st.push(v);
}
vector<int> topologicalSort(vector<vector<int>>& graph) {
int n = graph.size();
vector<bool> visited(n, false);
stack<int> st;
for (int i = 0; i < n; ++i) {
if (!visited[i]) {
dfs(graph, i, visited, st);
}
}
vector<int> result;
while (!st.empty()) {
result.push_back(st.top());
st.pop();
}
return result;
}
int main() {
vector<vector<int>> graph = {
{1, 2},
{3},
{3},
{}
};
vector<int> sorted = topologicalSort(graph);
for (int v : sorted) {
cout << v << " ";
}
cout << endl;
return 0;
}
深度优先搜索实现拓扑排序的时间复杂度主要取决于图的顶点数 V 和边数 E 。
在最坏情况下,每个顶点和每条边都会被访问一次,因此时间复杂度为 O(V + E) 。
- 使用广度优先搜索(BFS)
广度优先搜索则是按照距离起始顶点的层次逐步遍历图。
以下是使用广度优先搜索实现拓扑排序的 C++ 代码:
#include <iostream>
#include <vector>
#include <queue>
using namespace std;
vector<int> topologicalSort(vector<vector<int>>& graph) {
int n = graph.size();
vector<int> inDegree(n, 0);
for (int i = 0; i < n; ++i) {
for (int j = 0; j < graph[i].size(); ++j) {
inDegree[graph[i][j]]++;
}
}
queue<int> q;
for (int i = 0; i < n; ++i) {
if (inDegree[i] == 0) {
q.push(i);
}
}
vector<int> result;
while (!q.empty()) {
int v = q.front();
q.pop();
result.push_back(v);
for (int i = 0; i < graph[v].size(); ++i) {
int u = graph[v][i];
inDegree[u]--;
if (inDegree[u] == 0) {
q.push(u);
}
}
}
return result;
}
int main() {
vector<vector<int>> graph = {
{1, 2},
{3},
{3},
{}
};
vector<int> sorted = topologicalSort(graph);
for (int v : sorted) {
cout << v << " ";
}
cout << endl;
return 0;
}
广度优先搜索实现拓扑排序的时间复杂度同样为 O(V + E) 。首先计算入度的过程需要遍历所有的边,时间复杂度为 O(E) 。然后进行 BFS 遍历,每个顶点和边最多访问一次,时间复杂度为 O(V + E) 。
性能比较与选择
在实际应用中,选择深度优先搜索还是广度优先搜索实现拓扑排序,取决于具体的问题和图的特点。
深度优先搜索通常具有较低的空间复杂度,但其时间复杂度可能因图的结构而有所不同。在一些复杂的图中,可能会出现递归深度过大的情况。
广度优先搜索在空间复杂度上可能相对较高,但时间复杂度相对较为稳定,并且对于一些需要按照层次顺序处理顶点的问题更为适用。
模板题
[题目描述]
给定一个 n 个点 m 条边的有向图,点的编号是 1 到 n,图中可能存在重边和自环。
请输出任意一个该有向图的拓扑序列,如果拓扑序列不存在,则输出 −1。
若一个由图中所有点构成的序列 A满足:对于图中的每条边 (x,y),x在 A 中都出现在 y 之前,则称 A 是该图的一个拓扑序列。
输入格式
第一行包含两个整数 n和 m。
接下来 m 行,每行包含两个整数 x和 y,表示存在一条从点 x 到点 y 的有向边 (x,y)。
输出格式
共一行,如果存在拓扑序列,则输出任意一个合法的拓扑序列即可。
否则输出-1。
数据范围
1≤n,m≤105
输入样例:
3 3
1 2
2 3
1 3
输出样例:
1 2 3
AC代码
#include<bits/stdc++.h>
using namespace std;
const int N=100010;
vector <int>g[N];
int d[N],q[N],n,m;
queue<int>qu;
bool topsort()
{
int hh=0,tt=-1;
for(int i=1;i<=n;i++){
//cout<<d[i]<<endl;
if(d[i]==0)q[++tt]=i;
}
while(hh<=tt){
int t=q[hh++];
//qu.pop();
for(int i=0;i<g[t].size();i++){
int j=g[t][i];
d[j]--;
if(d[j]==0)q[++tt]=j;
}
}
return tt==n-1;
}
int main(){
int i;
scanf("%d %d",&n,&m);
for(i=1;i<=m;i++){
int a,b;
scanf("%d %d",&a,&b);
g[a].push_back(b);
d[b]++;
}
if(topsort()){
for(int i=0;i<n;i++)cout<<q[i]<<" ";
puts("");
}
else puts("-1");
return 0;
}
如果出题人犯懒,不想写SpecialJudge,那么输出格式就会变成这样
共一行,如果存在拓扑序列,则输出字典序最小的拓扑序列即可。
否则输出 −1。
其实也不用慌,字典序最小一般都用的是贪心的思路
为什么会出现多种拓扑排序呢?
显然,当在某一个时刻,又多个点的入度等于零,这时,无论我们选哪个点,都能生成一个合法的拓扑排序
在这一步中,只要我们不断找到编号最小的点加入就可以生成字典序最小的拓扑排序了
代码如下
#include<bits/stdc++.h>
using namespace std;
const int N=1e5+7;
int head[N],tot=0;
struct star{
int to,nxt;
}s[N];
void add(int x,int y){
s[++tot]={y,head[x]};
head[x]=tot;
}
priority_queue<int,vector<int>,greater<int>>q;
int in[N],ans[N],idx=0;
int main(){
ios::sync_with_stdio(false);cin.tie(nullptr);
int n,m;
cin>>n>>m;
for(int i=1;i<=n;++i)head[i]=-1;
for(int i=1;i<=m;++i){
int x,y;
cin>>x>>y;
add(x,y);
in[y]++;
}
for(int i=1;i<=n;++i){
if(in[i]==0)q.push(i);
}
while(not q.empty()){
int now=q.top();
q.pop();
ans[++idx]=now;
for(int i=head[now];~i;i=s[i].nxt){
int to=s[i].to;
if(--in[to]==0)q.push(to);
}
}
if(idx==n){
for(int i=1;i<=n;++i){
cout<<ans[i]<<" ";
}
cout<<"\n";
}
else cout<<"-1\n";
return 0;
}
例题讲解
【模板】拓扑排序 / 家谱树
题目描述
有个人的家族很大,辈分关系很混乱,请你帮整理一下这种关系。给出每个人的后代的信息。输出一个序列,使得每个人的后辈都比那个人后列出。
输入格式
第 1 1 1 行一个整数 N N N( 1 ≤ N ≤ 100 1 \le N \le 100 1≤N≤100),表示家族的人数。接下来 N N N 行,第 i i i 行描述第 i i i 个人的后代编号 a i , j a_{i,j} ai,j,表示 a i , j a_{i,j} ai,j 是 i i i 的后代。每行最后是 0 0 0 表示描述完毕。
输出格式
输出一个序列,使得每个人的后辈都比那个人后列出。如果有多种不同的序列,输出任意一种即可。
样例 #1
样例输入 #1
5
0
4 5 1 0
1 0
5 3 0
3 0
样例输出 #1
2 4 5 3 1
思路
对于一个家庭关系,一定是一个有向无环图,体面描述的就是拓扑排序的板子题。
AC代码
#include<cstdio>
#include<iostream>
#include<cstring>
#include<algorithm>
using namespace std;
const int N=110,M=N*N/2;
int n,m;
int h[N],e[M],ne[M],idx;
int q[N],d[N];
void add(int a,int b){
e[idx]=b,ne[idx]=h[a],h[a]=idx++;
}
void topsort(){
int hh=0,tt=-1;
for(int i=1;i<=n;i++)
if(!d[i])
q[++tt]=i;
while(hh<=tt){
int t=q[hh++];
for(int i=h[t];~i;i=ne[i]){
int j=e[i];
if(--d[j]==0)
q[++tt]=j;
}
}
return ;
}
int main(){
ios::sync_with_stdio(0);
cin>>n;
memset(h,-1,sizeof(h));
for(int i=1;i<=n;i++){
int son;
while (cin>>son,son){
add(i,son);
d[son]++;
}
}
topsort();
for(int i=0;i<n;i++)cout<<q[i]<<" ";
}
【一本通图 拓扑排序与关键路径】 奖金
[题目描述]
由于无敌的凡凡在2005年世界英俊帅气男总决选中胜出,Yali Company总经理Mr.Z心情好,决定给每位员工发奖金。公司决定以每个人本年在公司的贡献为标准来计算他们得到奖金的多少。
于是Mr.Z下令召开m方会谈。每位参加会谈的代表提出了自己的意见:“我认为员工a的奖金应该比b高!”Mr.Z决定要找出一种奖金方案,满足各位代表的意见,且同时使得总奖金数最少。每位员工奖金最少为100元。
输入
第一行两个整数n,m,表示员工总数和代表数;
以下m行,每行2个整数a,b,表示某个代表认为第a号员工奖金应该比第b号员工高。
输出
若无法找到合法方案,则输出“Poor Xed”;否则输出一个数表示最少总奖金。
样例输入
2 1
1 2
样例输出
201
提示
80%的数据满足n<=1000,m<=2000;
100%的数据满足n<=10000,m<=20000。
思路
这道题是差分约束的简化版本,差分约束中,如果边权为负数,跑SPFA,为非负数,可以用Tarjan,这道题边权为定值,直接最长路即可。
AC代码
#include<bits/stdc++.h>
using namespace std;
const int N=10010,M=20010;
int n,m;
int h[N],e[M],ne[M],idx;
int q[N],d[N],dis[N];
void add(int a,int b){
e[idx]=b,ne[idx]=h[a],h[a]=idx++;
}
bool topsort(){
int hh=0,tt=-1;
for(int i=1;i<=n;i++){
int j=e[i];
if(!d[i])
q[++tt]=i;
}
while(hh<=tt){
int t=q[hh++];
for(int i=h[t];~i;i=ne[i]){
int j=e[i];
if(--d[j]==0)
q[++tt]=j;
}
}
return tt==n-1;
}
int main(){
scanf("%d%d",&n,&m);
memset(h,-1,sizeof h);
while(m--){
int a,b;
scanf("%d%d",&a,&b);
add(b,a);
d[a]++;
}
if(!topsort())puts("Poor Xed");
else {
for(int i=1;i<=n;i++)
dis[i]=100;
for(int i=0;i<n;i++){
int j=q[i];
for(int k=h[j];~k;k=ne[k])
dis[e[k]]=max(dis[e[k]],dis[j]+1);
}
int res=0;
for(int i=1;i<=n;i++)res+=dis[i];
printf("%d\n",res);
}
return 0;
}
可达性统计
题目描述
给定一张 N N N 个点 M M M 条边的有向无环图,分别统计从每个点出发能够到达的点的数量。
输入格式
第一行两个整数 N , M N,M N,M,接下来 M M M 行每行两个整数 x , y x,y x,y,表示从 x x x 到 y y y 的一条有向边。
输出格式
输出共 N N N 行,表示每个点能够到达的点的数量。
样例 #1
样例输入 #1
10 10
3 8
2 3
2 5
5 9
5 9
2 3
3 9
4 8
2 10
4 9
样例输出 #1
1
6
3
3
2
1
1
1
1
1
提示
测试数据满足 1 ≤ N , M ≤ 30000 1 \le N,M \le 30000 1≤N,M≤30000, 1 ≤ x , y ≤ N 1 \le x,y \le N 1≤x,y≤N。
思路
显然,一个有向无环图有一个特别可爱的性质——无后效性,为DP创造好了条件,STL里提供一个bitset容器,我们用它来存储对于每个点,他所能到达的点,而一个新的点能到达的点,就是所有与它相连的的能到达的点的并集(|)运算,显然,为了保证他所连接的点都已经被算过了,应该按照拓扑排序的顺序拿点。
AC代码
#include <cstdio>
#include <cstring>
#include <iostream>
#include <algorithm>
#include <bitset>
using namespace std;
const int N = 30010, M = 30010;
int n, m;
int h[N], e[M], ne[M], idx;
int d[N], q[N];
bitset<N> f[N];
void add(int a, int b)
{
e[idx] = b, ne[idx] = h[a], h[a] = idx ++ ;
}
void topsort()
{
int hh = 0, tt = -1;
for (int i = 1; i <= n; i ++ )
if (!d[i])
q[ ++ tt] = i;
while (hh <= tt)
{
int t = q[hh ++ ];
for (int i = h[t]; ~i; i = ne[i])
{
int j = e[i];
if ( -- d[j] == 0)
q[ ++ tt] = j;
}
}
}
int main()
{
scanf("%d%d", &n, &m);
memset(h, -1, sizeof h);
for (int i = 0; i < m; i ++ )
{
int a, b;
scanf("%d%d", &a, &b);
add(a, b);
d[b] ++ ;
}
topsort();
for (int i = n - 1; i >= 0; i -- )
{
int j = q[i];
f[j][j] = 1;
for (int k = h[j]; ~k; k = ne[k])
f[j] |= f[e[k]];
}
for (int i = 1; i <= n; i ++ ) printf("%d\n", f[i].count());
return 0;
}
[NOIP2013 普及组] 车站分级
题目背景
NOIP2013 普及组 T4
题目描述
一条单向的铁路线上,依次有编号为
1
,
2
,
…
,
n
1, 2, …, n
1,2,…,n 的 $n $ 个火车站。每个火车站都有一个级别,最低为
1
1
1 级。现有若干趟车次在这条线路上行驶,每一趟都满足如下要求:如果这趟车次停靠了火车站
x
x
x,则始发站、终点站之间所有级别大于等于火车站 $ x$ 的都必须停靠。
注意:起始站和终点站自然也算作事先已知需要停靠的站点。
例如,下表是 $ 5 $ 趟车次的运行情况。其中,前 $ 4$ 趟车次均满足要求,而第 5 5 5 趟车次由于停靠了 3 3 3 号火车站( 2 2 2 级)却未停靠途经的 6 6 6 号火车站(亦为 2 2 2 级)而不满足要求。
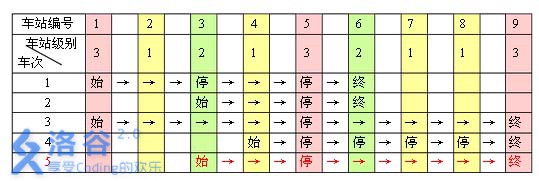
现有 m m m 趟车次的运行情况(全部满足要求),试推算这 $ n$ 个火车站至少分为几个不同的级别。
输入格式
第一行包含 2 2 2 个正整数 n , m n, m n,m,用一个空格隔开。
第 i + 1 i + 1 i+1 行 ( 1 ≤ i ≤ m ) (1 ≤ i ≤ m) (1≤i≤m) 中,首先是一个正整数 s i ( 2 ≤ s i ≤ n ) s_i\ (2 ≤ s_i ≤ n) si (2≤si≤n),表示第 $ i$ 趟车次有 s i s_i si 个停靠站;接下来有 $ s_i$ 个正整数,表示所有停靠站的编号,从小到大排列。每两个数之间用一个空格隔开。输入保证所有的车次都满足要求。
输出格式
一个正整数,即 n n n 个火车站最少划分的级别数。
样例 #1
样例输入 #1
9 2
4 1 3 5 6
3 3 5 6
样例输出 #1
2
样例 #2
样例输入 #2
9 3
4 1 3 5 6
3 3 5 6
3 1 5 9
样例输出 #2
3
提示
对于 $ 20%$ 的数据, 1 ≤ n , m ≤ 10 1 ≤ n, m ≤ 10 1≤n,m≤10;
对于 50 % 50\% 50% 的数据, 1 ≤ n , m ≤ 100 1 ≤ n, m ≤ 100 1≤n,m≤100;
对于 100 % 100\% 100% 的数据, 1 ≤ n , m ≤ 1000 1 ≤ n, m ≤ 1000 1≤n,m≤1000。
思路
不难发现,每一个区间内部,我们都可以选择一个分界点,所有大于这个点的车全停,下面的全不停,这个点即为所求。
显然,运用差分约束的思想,求出每个点的最小值,其中的最大值即为本题所求,最后优化一下建边
AC代码
#include <cstdio>
#include <cstring>
#include <iostream>
#include <algorithm>
#include <bitset>
using namespace std;
const int N = 2010, M = 4000010;
int n, m;
int h[N], e[M], ne[M],w[M], idx;
int d[N], q[N],dis[N];
bool st[N];
void add(int a, int b,int c)
{
e[idx] = b,w[idx]=c, ne[idx] = h[a], h[a] = idx ++ ;
d[b]++;
}
void topsort()
{
int hh = 0, tt = -1;
for (int i = 1; i <= n+m; i ++ )
if (!d[i])
q[ ++ tt] = i;
while (hh <= tt)
{
int t = q[hh ++ ];
for (int i = h[t]; ~i; i = ne[i])
{
int j = e[i];
if ( -- d[j] == 0)
q[ ++ tt] = j;
}
}
}
int main()
{
scanf("%d%d", &n, &m);
memset(h, -1, sizeof h);
for (int i = 1; i <= m; i ++ )
{
memset(st,0,sizeof(st));
int cnt;
scanf("%d",&cnt);
int start =n,end=1;
while(cnt--){
int stop;
scanf("%d",&stop);
start=min(start,stop);
end=max(end,stop);
st[stop]=true;
}
int ver=n+i;
for(int j=start;j<=end;j++){
if(!st[j])add(j,ver,0);
else add(ver,j,1);
}
}
topsort();
for(int i=1;i<=n;i++)dis[i]=1;
for(int i=0;i<n+m;i++){
int j=q[i];
for (int k = h[j]; ~k; k = ne[k])
dis[e[k]]=max(dis[e[k]],dis[j]+w[k]);
}
int res=0;
for(int i=1;i<=n;i++)res=max(res,dis[i]);
printf("%d\n",res);
return 0;
}
这是我的第二十六篇文章,如有纰漏也请各位大佬指正
辛苦创作不易,还望看官点赞收藏打赏,后续还会更新新的内容。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









