







写在前面:
本次是根据前文讲解的爬虫、数据清洗、分析进行的一个纵隔讲解案例,也是对自己这段时间python爬虫、数据分析方向的一个总结。
本例设计一个豆瓣读书数据⽂件,book.xlsx⽂件保存的是爬取豆瓣⽹站得到的图书数据,共 60671 条。下⾯进⾏探索性数据分析。
文章目录
一、清洗爬取的网站数据
1. 导入数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rc('font', \*\*{'family':'SimHei'})
# 导⼊数据
df = pd.read_excel('books.xlsx')
# 删除第9列
df = df.drop('Unnamed: 9', axis=1)
2、清洗方法
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rc('font', \*\*{'family':'SimHei'})
# 导⼊数据
df = pd.read_excel('books.xlsx')
# 删除第9列
df = df.drop('Unnamed: 9', axis=1)
# 对数据做清洗(缺失值与异常值)
df.describe()
df.info()
df.dtypes
"""
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 60671 entries, 0 to 60670
Data columns (total 9 columns):
书名 60671 non-null object
作者 60668 non-null object
出版社 60671 non-null object
出版时间 60671 non-null object
页数 60671 non-null object
价格 60656 non-null object
ISBN 60671 non-null object
评分 60671 non-null float64
评论数量 60671 non-null object
dtypes: float64(1), object(8)
memory usage: 2.3+ MB
"""
3. 处理页数数据
⽬前只要评分是数值型数据,我们还要将⻚数、价格、评论数量转换成数值型数据。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rc('font', \*\*{'family':'SimHei'})
# 导⼊数据
df = pd.read_excel('books.xlsx')
# 删除第9列
df = df.drop('Unnamed: 9', axis=1)
# 对数据做清洗(缺失值与异常值)
df.describe()
df.info()
df.dtypes
print("---------------------------------")
# 前期分析
print( df['页数'].describe() )
'''
count 60671
unique 2109
top None
freq 4267
Name: 页数, dtype: object
'''
print( df['页数'].isnull().sum() ) # 返回:0 ,这样看不出来
print( len(df[df['页数']=='None']) ) # 返回:4267 , 看看有多少 None 值页数信息
print("---------------------------------")
# 转换
# 定义 convert\_to\_int ⽅法处理页数数据,如果为 None 则填充 0
import re
def convert2int(x):
if re.match('^\d+$',str(x)):
return x
else:
return 0
df['页数'] = df['页数'].apply(convert2int)
'''
# 或者⽤ lambda 表达式
df['页数'] = df['页数'].apply(lambda x: x if re.match('^\d+$', str(x)) else 0)
df['页数'] = df['页数'].astype(int)
'''
print( df['页数'].describe() )
'''
count 6.067100e+04
mean 6.883281e+06
std 1.695365e+09
min 0.000000e+00
25% 1.940000e+02
50% 2.640000e+02
75% 3.600000e+02
max 4.175936e+11
Name: 页数, dtype: float64
'''
print( df['页数'].isnull().sum() ) # 返回:0
print( len(df[df['页数']=='None']) ) # 返回:0
4.处理价格数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rc('font', \*\*{'family':'SimHei'})
# 导⼊数据
df = pd.read_excel('books.xlsx')
# 删除第9列
df = df.drop('Unnamed: 9', axis=1)
# 对数据做清洗(缺失值与异常值)
df.describe()
df.info()
df.dtypes
print("---------------------------------")
# 处理价格数据
df['价格'] = df['价格'].apply(lambda x: x if re.match('^[\d\.]+$', str(x)) else 0)
df['价格'] = df['价格'].astype(float)
# 价格为 0 的图书数量
print( len(df[df['价格'] == 0]) ) # 3217
5.处理评论数量数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rc('font', \*\*{'family':'SimHei'})
# 导⼊数据
df = pd.read_excel('books.xlsx')
# 删除第9列
df = df.drop('Unnamed: 9', axis=1)
# 对数据做清洗(缺失值与异常值)
df.describe()
df.info()
df.dtypes
print("---------------------------------")
# 处理评论数量数据
df['评论数量'] = df['评论数量'].apply(lambda x: x if re.match('^\d+$', str(x)) else 0)
df['评论数量'] = df['评论数量'].astype(int)
print( df.dtypes )
'''
书名 object
作者 object
出版社 object
出版时间 object
页数 int64
价格 float64
ISBN object
评分 float64
评论数量 int32
dtype: obje
'''
二、分析爬取的网站数据
1.处理出版时间
后⾯需要⽤到年份信息,这⾥先对年份信息进⾏加⼯:处理出版时间,只要年份。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rc('font', \*\*{'family':'SimHei'})
# 导⼊数据
df = pd.read_excel('books.xlsx')
# 删除第9列
df = df.drop('Unnamed: 9', axis=1)
# 对数据做清洗(缺失值与异常值)
df.describe()
df.info()
df.dtypes
# 处理⻚数数据
# 定义 convert\_to\_int ⽅法处理页数数据,如果为 None 则填充 0
import re
def convert2int(x):
if re.match('^\d+$',str(x)):
return x
else:
return 0
df['页数'] = df['页数'].apply(convert2int)
# 处理价格数据
df['价格'] = df['价格'].apply(lambda x: x if re.match('^[\d\.]+$', str(x)) else 0)
df['价格'] = df['价格'].astype(float)
# 处理评论数量数据
df['评论数量'] = df['评论数量'].apply(lambda x: x if re.match('^\d+$', str(x)) else 0)
df['评论数量'] = df['评论数量'].astype(int)
print("---------------------------------")
# 处理出版时间,只要年份
def year(s):
y = re.findall('\d{4}',str(s))
if len(y)>0:
return y[0]
return ''
df['出版年份'] = df['出版时间'].apply(year)
# 看看还有多少没有年份信息的
print( len(df[df['出版年份'] == '']) ) # 返回: 1035
2.分析图书数量与年份的关系
# 与上面示例源代码相同,这里省略
print("---------------------------------")
print("---------------------------------")
# 按出版年份进⾏分组
grouped = df.groupby('出版年份')
data = grouped['ISBN'].count()
# 有两条数据⽐较奇怪,处理⼀下
df[df['出版年份'] == '1979']
df.loc[df.index[60632], ['书名', '出版时间', '出版年份']]
"""
书名 鲁迅作品中的绍兴⽅⾔注释
出版时间 1979/初版印
出版年份 1979
Name: 60632, dtype: object
"""
df.loc[df.index[60632], ['出版年份']] = '1979'
df[df['出版年份'] == '2002']
df.loc[df.index[4544], ['书名', '出版时间', '出版年份']]
"""
书名 俄罗斯插画作品集
出版时间 2002/2
出版年份 2002
Name: 4544, dtype: object
"""
df.loc[df.index[4544], ['出版年份']] = '2002'
# 然后按”出版年份“进⾏分组
grouped = df.groupby('出版年份')
data = grouped['ISBN'].count()
print( data )
print("---------------------------------")
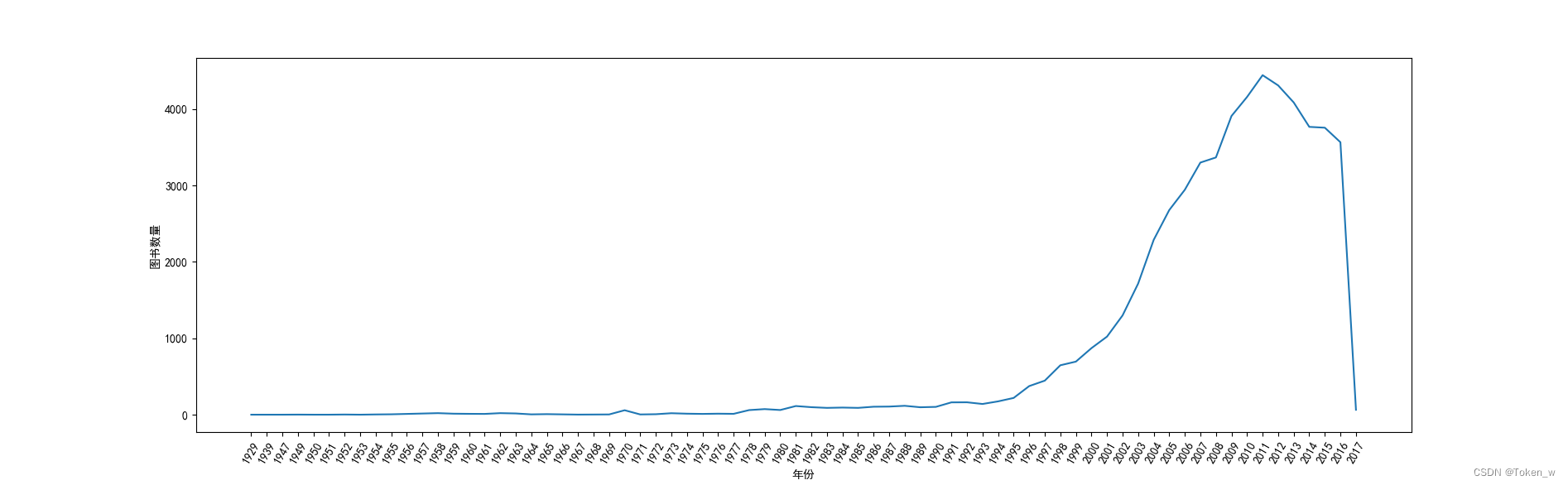
# 判断前7条数据和后4条数据属于异常数据,所以删除前7后4的数据
data2 = data[7:-4]
# 准备画图,设置宽⼀点
plt.figure(figsize=(15, 5))
# 设置 x 周标签的倾斜⻆度
plt.xticks(rotation=60)
plt.xlabel('年份')
plt.ylabel('图书数量')
plt.plot(data2.index, data2.values)
plt.show()
3.分析图书评分与年份的关系
# 与上面示例源代码相同,这里省略
print("---------------------------------")
print("---------------------------------")
# 按出版年份进⾏分组
grouped = df.groupby('出版年份')
data = grouped['ISBN'].count()
# 有两条数据⽐较奇怪,处理⼀下
df[df['出版年份'] == '1979']
df.loc[df.index[60632], ['书名', '出版时间', '出版年份']]
"""
书名 鲁迅作品中的绍兴⽅⾔注释
出版时间 1979/初版印
**自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。**
**深知大多数Python工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!**
**因此收集整理了一份《2024年Python开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。**






**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上前端开发知识点,真正体系化!**
**由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新**
**如果你觉得这些内容对你有帮助,可以扫码获取!!!(备注:Python)**
...(img-a7dovuas-1713682712826)]


**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上前端开发知识点,真正体系化!**
**由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新**
**如果你觉得这些内容对你有帮助,可以扫码获取!!!(备注:Python)**
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









