






目录
urllib库
是Python内置的HTTP请求库,它可以看做是处理URL的组件集合。
模块名称
urllib.request(请求模块)
urllib.error(异常处理模块)
urllib.parse(url解析模块)
urllib.robotparser(robots.txt解析模块)
快速爬取网页
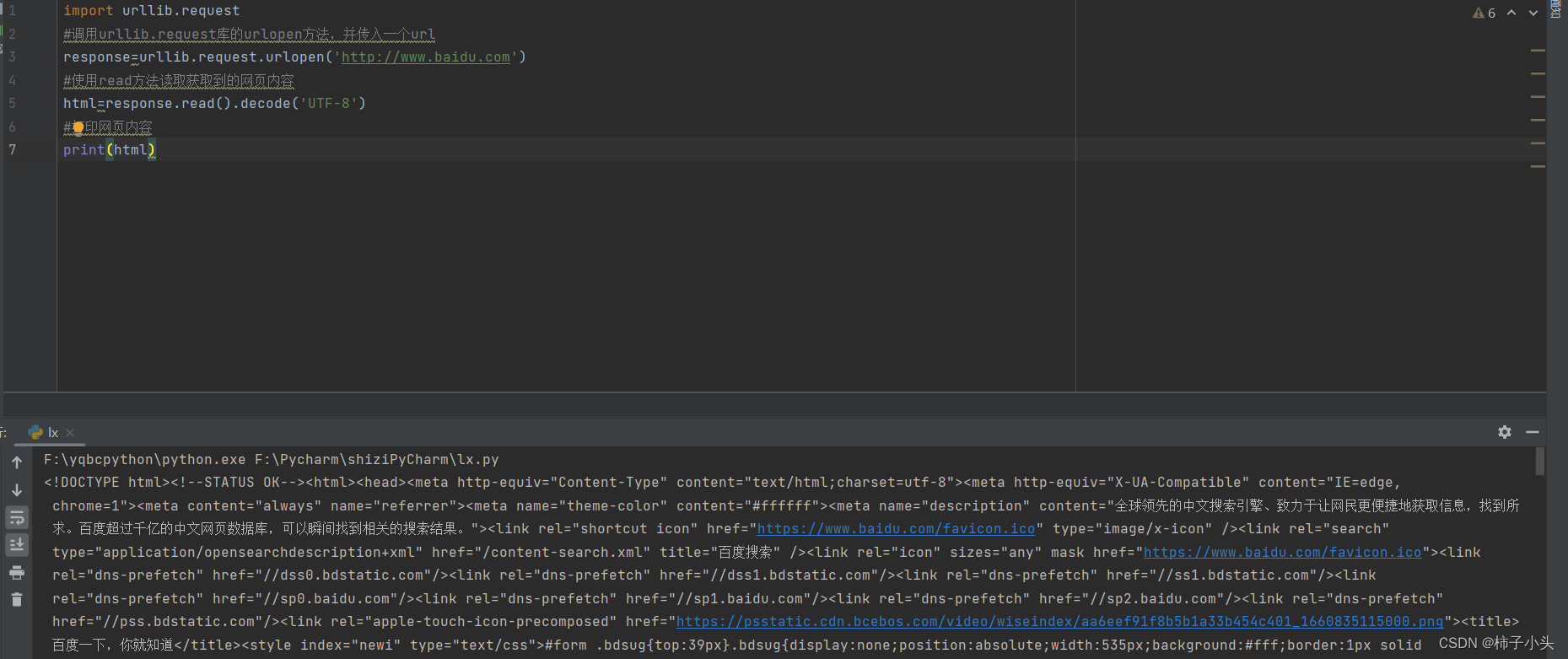
import urllib.request
#调用urllib.request库的urlopen方法,并传入一个url
response=urllib.request.urlopen('http://www.baidu.com')
#使用read方法读取获取到的网页内容
html=response.read().decode('UTF-8')
#打印网页内容
print(html)上述案例仅仅用了几行代码,就已经帮我们把百度的首页的全部代码下载下来了。
实际上,如果我们在浏览器上打开百度主页,右键选择“检查”,你会发现,跟我们刚才打印出来的是一模一样。
示例结果:
urlopen方法
前面在爬取网页时,有一句核心的爬虫代码:
response=urllib.request.urlopen('http://www.baidu.com')
上述代码调用的是urllib.request模块中的urlopen方法,它传入了一个百度首页的URL,使用的协议是HTTP,这是urlopen方法最简单的用法。
urlopen中的参数
urlopen方法可以接收多个参数,定义格式如下:

参数如下:
·url -- 表示目标资源在网站中的位置。
·data -- 用来指明向服务器发送请求的额外信息。
·timeout -- 该参数用于设置超时时间,单位是秒。
·context -- 实现SSL加密传输,该参数很少使用。
使用HTTPRsponse对象
使用urlopen方法发送HTTP请求后,服务器返回的响应内容封装在一个HTTPRsponse类型的对象中。
例如:
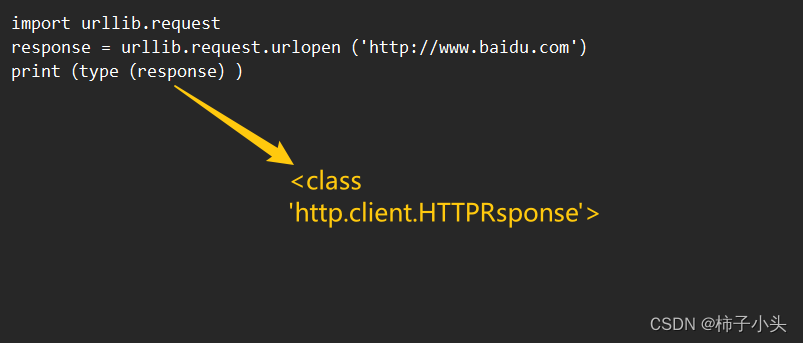
HTTPRsponse类属于http.client模块,该类提供了获取URL、状态码、响应内容等一系列方法。
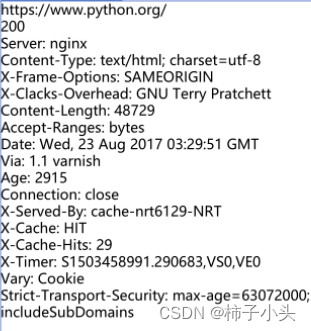
·geturl() -- 用于获取响应内容的URL,该方法可以验证发送的HTTP请求是否被重新调配。
·info() -- 返回页面的元信息。
·getcode() -- 返回HTTP请求的响应状态码。
示例:

示例结果:
构造Request对象
如果希望对请求执行复杂操作,则需要创建一个Request对象来作为urlopen方法的参数。
#将url作为Request方法的参数,构造并返回一个Request对象
request=urllib.request.Request('http://www.baidu.com')
#将Request对象作为urlopen方法的参数,发送给服务器并接收响应
response=urllib.request.urlopen(request)在使用urllib库发送URL的时候,我们推荐大家使用构造Request对象的方式。
在构建请求时,除了必须设置的url参数外,还可以加入很多内容,例如下面的参数:
·data -- 默认为空,该参数表示提交表单数据,同时HTTP请求方法将从默认的GET方式改为POST方式。
·headers -- 默认为空,该参数是一个字典类型,包含了需要发送的HTTP报头的键值对。















 625
625











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









