






1.目标:
熟练掌握使用Python语言实现Apriori关联分析模型的方法。
2.内容:
- 使用mlxtend工具包得出频繁项集合规则
- 自定义购物数据集

- 设置支持度(support)来选择频繁项集
- 计算规则:指定不同的衡量标准与最小阈值

- 将数据转成one-hot编码
- 最终输出结果

3.具体实施:
3.1使用mlxtend工具包得出频繁项集合规则
import pandas as pd
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules3.2自定义购物数据集
import pandas as pd
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
data = {
'ID': [1, 2, 3, 4, 5, 6],
'Onion': [1, 0, 0, 1, 1, 1],
'Potato': [1, 1, 0, 1, 1, 1],
'Burger': [1, 1, 0, 0, 1, 1],
'Milk': [0, 1, 1, 1, 0, 1],
'Beer': [0, 0, 1, 0, 1, 0]}
df = pd.DataFrame(data)
df = df[['ID', 'Onion', 'Potato', 'Burger', 'Milk', 'Beer']]
df
print(df);3.3设置支持度来选择频繁项集
import pandas as pd
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
data = {
'ID': [1, 2, 3, 4, 5, 6],
'Onion': [1, 0, 0, 1, 1, 1],
'Potato': [1, 1, 0, 1, 1, 1],
'Burger': [1, 1, 0, 0, 1, 1],
'Milk': [0, 1, 1, 1, 0, 1],
'Beer': [0, 0, 1, 0, 1, 0]}
df = pd.DataFrame(data)
df = df[['ID', 'Onion', 'Potato', 'Burger', 'Milk', 'Beer']]
df
frequent_itemsets = apriori(df[['Onion', 'Potato', 'Burger', 'Milk', 'Beer']], min_support=0.50,use_colnames = True)
frequent_itemsets
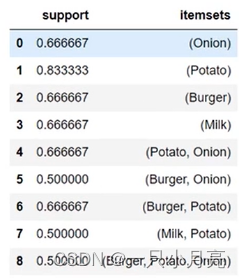
print(frequent_itemsets);3.4计算规则:指定不同的衡量标准与最小阈值
import pandas as pd
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
data = {
'ID': [1, 2, 3, 4, 5, 6],
'Onion': [1, 0, 0, 1, 1, 1],
'Potato': [1, 1, 0, 1, 1, 1],
'Burger': [1, 1, 0, 0, 1, 1],
'Milk': [0, 1, 1, 1, 0, 1],
'Beer': [0, 0, 1, 0, 1, 0]}
df = pd.DataFrame(data)
df = df[['ID', 'Onion', 'Potato', 'Burger', 'Milk', 'Beer']]
df
frequent_itemsets = apriori(df[['Onion', 'Potato', 'Burger', 'Milk', 'Beer']], min_support=0.50,use_colnames = True)
frequent_itemsets
rules = association_rules(frequent_itemsets, metric='lift', min_threshold=1)
rules [(rules['lift'] > 1.125) & (rules['confidence'] > 0.8) ]
rules
print(rules [(rules['lift'] > 1.125) & (rules['confidence'] > 0.8) ]);3.5将数据转成one-hot编码
import pandas as pd
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
retail_shopping_basket ={'ID': [1, 2, 3, 4, 5, 6],
'Basket': [['Beer', 'Diaper', 'Pretzels', 'Chips', 'Aspirin'],
['Diaper', 'Beer', 'Chips', 'Lotion', 'Juice', 'BabyFood', 'Milk'],
['soda', 'Chips', 'Milk'],
['Soup', 'Beer', 'Diaper', 'Milk', 'IceCream'],
['Soda', 'Coffee', 'Milk', 'Bread'],
['Beer', 'Chips']
]
}
retail = pd.DataFrame(retail_shopping_basket)
retail = retail[['ID', 'Basket']]
pd.options.display.max_colwidth = 100
retail_id = retail.drop('Basket' , 1)
retail_id
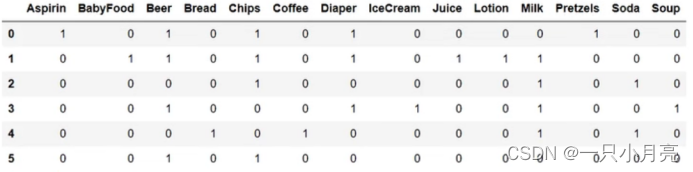
retail_Basket = retail.Basket.str.join(',')
retail_Basket = retail_Basket.str.get_dummies(',')
retail_Basket
retail = retail_id.join(retail_Basket)
retail3.6最终结果输出
import pandas as pd
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
retail_shopping_basket ={'ID': [1, 2, 3, 4, 5, 6],
'Basket': [['Beer', 'Diaper', 'Pretzels', 'Chips', 'Aspirin'],
['Diaper', 'Beer', 'Chips', 'Lotion', 'Juice', 'BabyFood', 'Milk'],
['soda', 'Chips', 'Milk'],
['Soup', 'Beer', 'Diaper', 'Milk', 'IceCream'],
['Soda', 'Coffee', 'Milk', 'Bread'],
['Beer', 'Chips']
]
}
retail = pd.DataFrame(retail_shopping_basket)
retail = retail[['ID', 'Basket']]
pd.options.display.max_colwidth = 100
retail_id = retail.drop('Basket', 1)
retail_id
retail_Basket = retail.Basket.str.join(',')
retail_Basket = retail_Basket.str.get_dummies(',')
retail_Basket
retail = retail_id.join(retail_Basket)
retail
frequent_itemsets_2 = apriori(retail.drop('ID', 1), use_colnames= True)
association_rules(frequent_itemsets_2, metric='lift')
frequent_itemsets_2
print(association_rules(frequent_itemsets_2, metric='lift'))
最终得出结论:{Diaper,Beer}更关联。















 567
567











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









