







欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。
一项目简介
一、项目背景与意义
随着交通流量的不断增长和交通环境的日益复杂,交通标志在道路交通中的重要性愈发凸显。然而,传统的交通标志检测方法受限于其效率和准确性,难以满足现代交通管理的需求。因此,开发一个基于深度学习的交通标志目标检测系统具有重要的现实意义和广阔的应用前景。
本项目旨在利用YoloV3(You Only Look Once version 3)算法,构建一个高效、准确的交通标志目标检测系统。该系统能够实时处理交通监控视频,自动检测并识别视频中的交通标志,为交通管理部门提供实时、准确的交通标志信息,从而提升道路安全和交通效率。
二、系统组成与工作原理
本系统主要由以下几个部分组成:
数据预处理模块:收集并整理交通标志图像数据集,包括训练集、验证集和测试集。对图像进行预处理操作,如缩放、裁剪、归一化等,以适应YoloV3模型的输入要求。
YoloV3模型:作为系统的核心组件,YoloV3模型负责对输入的图像进行特征提取和目标检测。该模型采用深度学习的技术,通过卷积神经网络(CNN)提取图像特征,并利用多尺度特征融合机制检测不同尺度的目标。在训练过程中,YoloV3模型学习如何区分和识别不同的交通标志。
训练与测试模块:使用标注好的交通标志图像数据集对YoloV3模型进行训练。通过不断调整模型的参数和优化算法,提高模型的识别准确率和检测速度。训练完成后,使用独立的测试数据集对模型进行测试,评估其性能。
结果展示模块:将检测到的交通标志信息以可视化的方式展示给用户。用户可以通过界面查看交通标志的种类、位置、置信度等信息,并可以对检测结果进行保存和导出。
工作原理如下:
系统实时获取交通监控视频流或静态图像作为输入。
将输入图像送入数据预处理模块进行预处理操作。
预处理后的图像被送入训练好的YoloV3模型中进行目标检测。
YoloV3模型输出检测结果,包括交通标志的种类、位置、置信度等信息。
将检测结果送入结果展示模块进行可视化展示,同时保存和导出检测结果。
三、系统优势
准确性高:YoloV3算法在目标检测领域具有出色的性能,能够准确识别各种交通标志。
实时性强:YoloV3算法采用单阶段检测方法,具有较快的检测速度,能够满足实时交通监控的需求。
多尺度特征融合:YoloV3算法引入多尺度特征融合的机制,能够有效检测不同尺度的目标,提高系统在各种交通场景下的适应能力。
操作简便:系统界面简洁易用,用户只需上传视频或图像即可获得检测结果,无需复杂的操作步骤。
二、功能
深度学习之基于YoloV3交通标志目标检测系统
三、系统
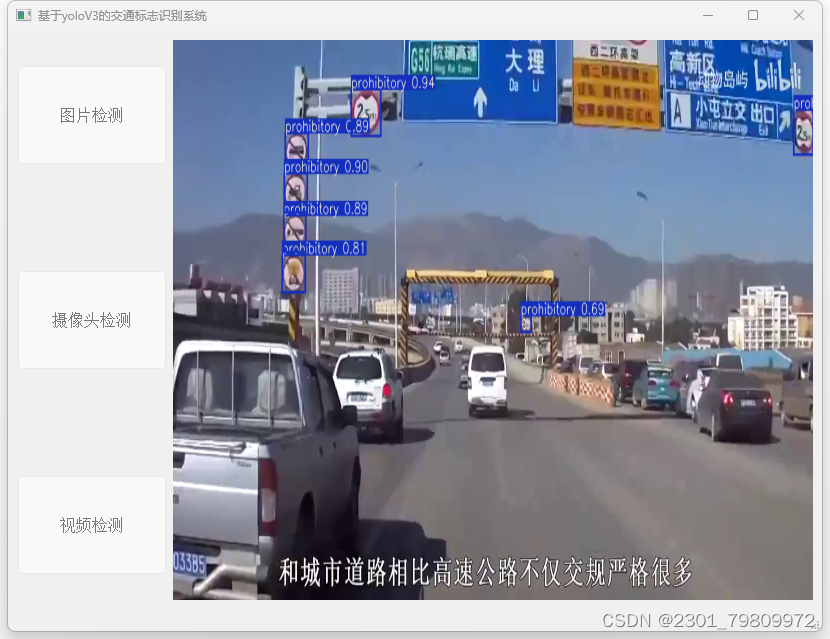
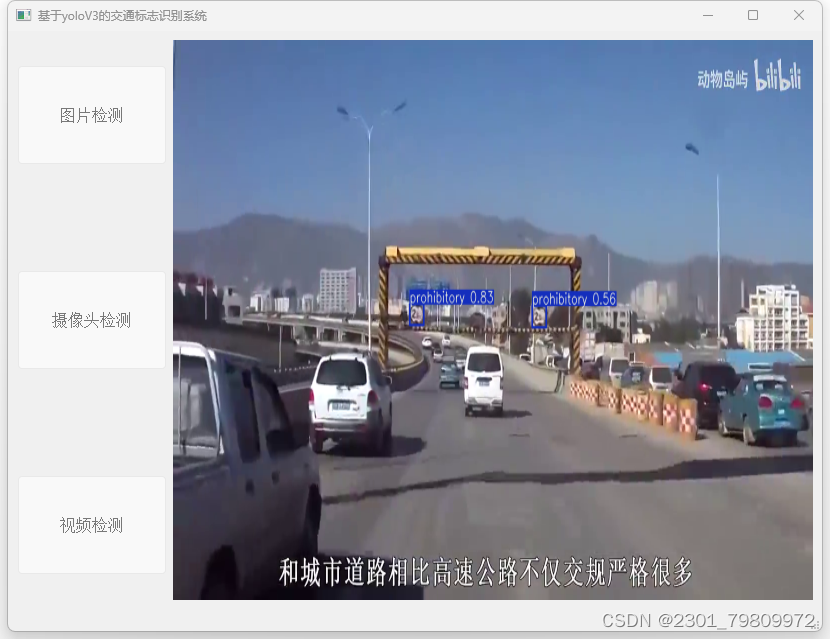
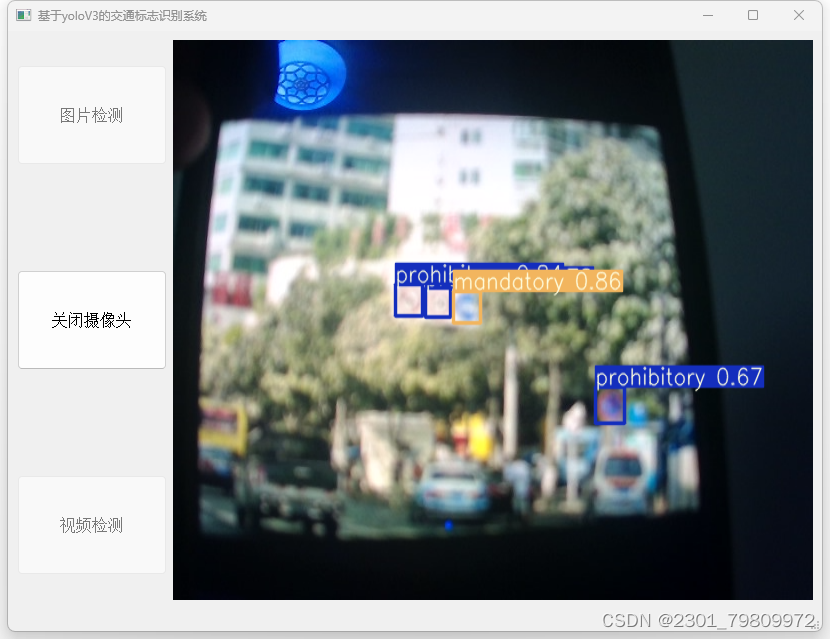
四. 总结
交通监控:实时检测交通监控视频中的交通标志,为交通管理部门提供实时的交通标志信息,助力提升道路安全和交通效率。
自动驾驶:作为自动驾驶系统的重要组成部分,为自动驾驶车辆提供实时的交通标志信息,帮助车辆更好地理解和遵守交通规则。
智能交通系统:结合其他传感器和数据分析技术,构建智能交通系统,实现交通信息的全面感知和智能决策。
综上所述,基于YoloV3的交通标志目标检测系统是一个高效、准确的解决方案,将为现代交通管理和自动驾驶技术的发展提供有力的技术支持。















 3593
3593

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









