






NVIDIA NeMo是什么?
NVIDIA NeMo™ 是一个端到端平台,用于随时随地开发自定义生成式 AI,包括大语言模型 (LLM)、多模态、视觉和语音 AI。通过精确的数据整合、前沿的定制、检索增强生成(RAG)和加速性能,提供适用于企业的模型。NeMo 是 NVIDIA AI Foundry 的一部分,这是一个用于使用企业数据和特定领域知识构建定制生成式 AI 模型的平台和服务。
训练框架
训练生成式 AI 架构通常需要大量的数据和计算资源。NeMo 利用 PyTorch Lightning 进行高效、高性能的多 GPU /多节点混合精度训练。 NeMo 建立在 NVIDIA 强大的 Megatron-LM 和 Transformer 引擎之上,适用于其大型语言模型 (LLM) 和多模态模型 (MM),利用模型训练和优化方面的尖端进步。对于语音 AI 应用程序、自动语音识别 (ASR) 和文本转语音 (TTS),NeMo 是使用原生 PyTorch 和 PyTorch Lightning 开发的,可确保无缝集成和易用性。未来计划进行更新,以使语音 AI 模型与 Megatron 框架保持一致,从而提高训练效率和模型性能。
NVIDIA NeMo 框架为大型语言模型 (LLM)、多模态模型 (MM)、计算机视觉 (CV)、自动语音识别 (ASR) 和文本转语音 (TTS) 模型提供了单独的集合。每个集合都包含预构建的模块,这些模块包含对数据进行训练所需的一切。这些模块可以轻松定制、扩展和组合,以创建新的生成式 AI 模型架构。
主要优势
1. 灵活,安全,更低的成本:可以在所有主要云平台、数据中心和边缘端上,随时随地训练和部署生成式 AI;大规模快速训练、自定义和部署大语言模型 (LLM)、视觉、多模态和语音 AI,减少提供解决方案所需的时间,并提高投资回报率;借助安全、优化的全栈解决方案,将产品部署到生产环境中,该解决方案提供 NVIDIA AI Enterprise 中支持、安全和 API 稳定性的功能。
2. 性能的提升:支持多节点、多 GPU 训练和推理,能够更大限度地提高吞吐量并缩短 LLM 训练时间。
3. 端到端工作流:体验为 LLM 管道提供的完整解决方案的优势——从数据处理和训练到生成式 AI 模型的推理。
功能
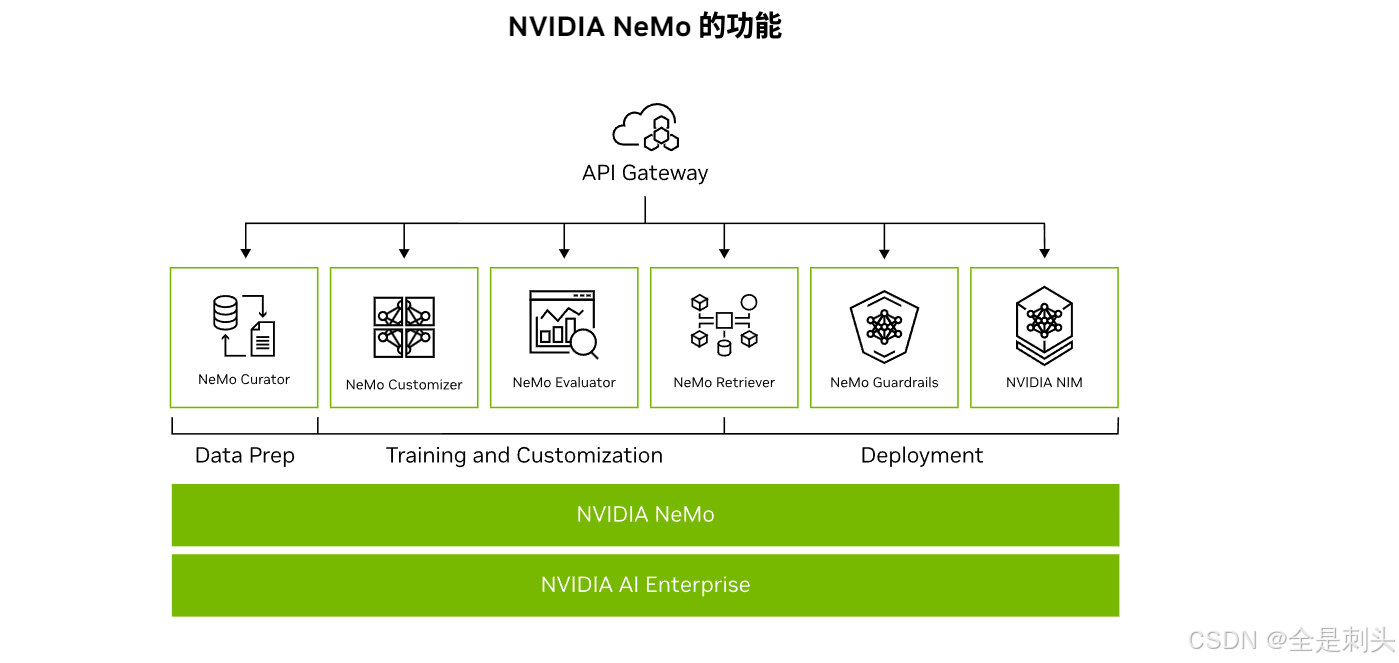

官方使用文档
使用
先决条件
-
Python 版本 3.10 或更高版本。
-
Pytorch 版本 1.13.1 或 2.0+。
-
访问 NVIDIA GPU 进行模型训练。
环境安装
安装 NeMo 框架 — NVIDIA NeMo 框架用户指南
通过Docker容器或Conda和pip
构造
NeMo API
NeMo 集合(模型的集成)
配置
通过 YAML 文件完成的,下面是简单示例:
#NeMo 模型定义(Python 伪代码)
class ExampleEncDecModel:
# cfg is passed so it only contains "model" section
def __init__(self, cfg, trainer):
self.tokenizer = init_from_cfg(cfg.tokenizer)
self.encoder = init_from_cfg(cfg.encoder)
self.decoder = init_from_cfg(cfg.decoder)
self.loss = init_from_cfg(cfg.loss)
# optimizer configured via parent class
def setup_training_data(self, cfg):
self.train_dl = init_dl_from_cfg(cfg.train_ds)
def forward(self, batch):
# forward pass defined,
# as is standard for PyTorch models
...
def training_step(self, batch):
log_probs = self.forward(batch)
loss = self.loss(log_probs, labels)
return loss#实验配置 (YAML)
# configuration of the NeMo model
model:
tokenizer:
...
encoder:
...
decoder:
...
loss:
...
optim:
...
train_ds:
...
# configuration of the
# PyTorch Lightning trainer object
trainer:
...示例训练脚本
# run_example_training.py
import pytorch_lightning as pl
from nemo.collections.path_to_model_class import ExampleEncDecModel
from nemo.core.config import hydra_runner
@hydra_runner(
config_path="config_file_dir_path",
config_name="config_file_name"
)
def main(cfg):
trainer = pl.Trainer(**cfg.trainer)
model = ExampleEncDecModel(cfg.model, trainer)
trainer.fit(model)
if __name__ == '__main__':
main(cfg)
















 151
151

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









