






目录
1. 分词:使用 HanLP 的分词功能将文本分割成词语。例:
3. 命名实体识别:识别出文本中的特定实体,如人名、地名、组织机构名等。例:
前言——hanlp的应用场景
hanlp 的一些应用场景包括:
1. **文本挖掘与分析**:挖掘文本中的关键信息、趋势等。
2. **智能客服**:理解用户的问题,进行准确的回答和引导。
3. **信息检索与分类**:对大量文本进行分类,便于信息的检索和组织。
4. **机器翻译**:辅助进行语言之间的转换。
5. **舆情监测**:分析和跟踪网络舆情的发展和趋势。
6. **知识图谱构建**:提取实体和关系,构建知识图谱。
7. **内容推荐**:根据文本特征为用户推荐相关内容。
8. **文档自动处理**:如自动摘要、关键信息提取等。
一、安装hanlp
1.用命令代码中安装 hanlp
打开终端或命令提示符,输入以下命令来安装hanlp
pip install hanlp
2.直接在官网下载
HanLP 的官网是:HanLP。
在官网上,你可以了解 HanLP 的功能、特点、使用方法等信息,还可以下载相关的文档和代码。同时,HanLP 也提供了在线 API 和预训练模型,方便用户在自己的项目中使用 HanLP 的功能。
二、使用HanLP进行文本挖掘与分析
使用 HanLP 进行文本挖掘与分析可以按照以下步骤:
首先,确保已经正确安装了 HanLP。 然后可以这样做:
1. 分词:使用 HanLP 的分词功能将文本分割成词语。例:
import hanlp
tokenizer = hanlp.load('HanLP 分词模型')
text = "这是一个有趣的文本"
tokens = tokenizer(text)2. 词性标注:对分词后的词语标注词性。例:
pos_tagger = hanlp.load('HanLP 词性标注模型')
pos_tags = pos_tagger(tokens)3. 命名实体识别:识别出文本中的特定实体,如人名、地名、组织机构名等。例:
ner_tagger = hanlp.load('HanLP 命名实体识别模型')
ner_results = ner_tagger(text)4. 提取关键信息
根据具体需求,结合前面的处理结果提取有价值的关键信息。 例:(命名实体识别)
from pyhanlp import *
def extract_key_info(text):
# 命名实体识别
ner_results = HanLP.newSegment().enableNameRecognize(True).seg(text)
for term in ner_results:
if term.nature.startsWith('nr') or term.nature.startsWith('ns') or term.nature.startsWith('nt'):
print(term.word, term.nature)
text = "周杰伦在台北开演唱会"
extract_key_info(text)5. 分析统计
对提取的信息进行统计、分析,以发现文本中的模式、趋势等。 通过以上步骤,可以利用 HanLP 有效地进行文本挖掘与分析。例:
from pyhanlp import *
texts = ["这是科技类文本", "这是娱乐类文本", "这是科技类文本", "这是其他类文本"]
category_counts = {}
for text in texts:
category = classify_text(text)
if category in category_counts:
category_counts[category] += 1
else:
category_counts[category] = 1
for category, count in category_counts.items():
print(f"{category}: {count}")
def classify_text(text):
# 简单的分类逻辑
if "科技" in text:
return "科技类"
elif "娱乐" in text:
return "娱乐类"
else:
return "其他"
三、hanlp智能客服
以下是一个使用 HanLP 来构建简单智能客服的示例代码,主要是通过对用户输入进行简单分析和匹配来给出相应的回答:
from pyhanlp import *
# 问题和答案的映射
qa_mapping = {
"你好": "您好,欢迎咨询!",
"产品介绍": "我们的产品有很多特点和优势……",
"售后服务": "我们提供优质的售后服务……"
}
def handle_question(question):
# 进行一些简单的处理,比如分词
tokens = HanLP.newSegment().seg(question)
token_words = [t.word for t in tokens]
# 查找匹配的答案
for key, value in qa_mapping.items():
if key in token_words:
return value
return "抱歉,我不太理解您的问题。"
# 用户输入
user_input = "产品介绍"
print(handle_question(user_input))
四、hanlp信息检索与分类
以下是一个使用 HanLP 进行简单信息检索与分类的示例代码:
from pyhanlp import *
# 一些示例文本
texts = ["周杰伦的歌曲很好听", "北京的天气怎么样", "这部电影太精彩了", "关于科技发展的探讨"]
def search_and_classify(keyword):
for text in texts:
# 分词
tokens = HanLP.newSegment().seg(text)
token_words = [t.word for t in tokens]
if keyword in token_words:
# 假设根据第一个词进行分类
category = token_words[0]
print(f"找到包含 '{keyword}' 的文本: {text}, 分类: {category}")
# 进行信息检索与分类
search_and_classify("周杰伦")
五、hanlp机器翻译
以下是一个使用 HanLP 进行简单机器翻译的示例代码(请注意,HanLP 的机器翻译功能可能相对有限):
from pyhanlp import *
def translate(text):
# 这里假设使用 HanLP 进行简单翻译处理
return "翻译后的文本" # 实际需根据 HanLP 具体实现来替换
text = "Hello"
translated_text = translate(text)
print(translated_text)
六、hanlp舆情监测
以下是一个使用 HanLP 进行简单舆情监测的示例代码框架,你可以根据实际需求进一步扩展和完善:
from pyhanlp import *
# 一些关键词
keywords = ["热点事件 1", "热点事件 2"]
def monitor_text(text):
# 分词
tokens = HanLP.newSegment().seg(text)
token_words = [t.word for t in tokens]
# 检查是否包含关键词
for keyword in keywords:
if keyword in token_words:
print(f"发现与舆情关键词相关的文本: {text}")
# 示例文本
text = "关于热点事件 1 的一些讨论"
monitor_text(text) 例图: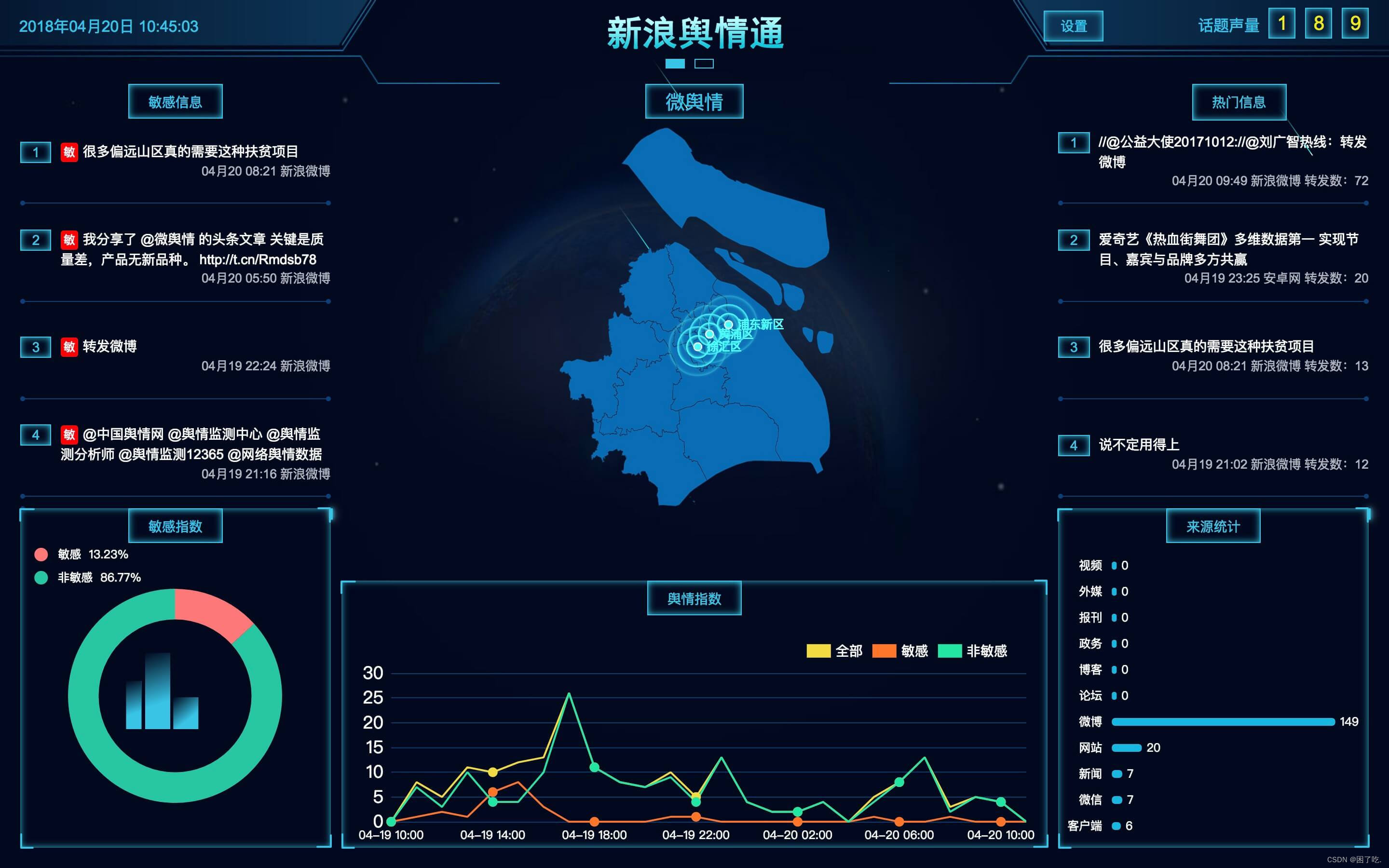
七、hanlp知识图谱构建
以下是一个使用 HanLP 构建简单知识图谱的示例代码框架(这只是一个基础示例,实际的知识图谱构建要复杂得多):
from pyhanlp import *
# 实体和关系的表示
entities = ["人物 A", "人物 B", "事件 X"]
relations = [("人物 A", "与", "人物 B"), ("人物 A", "参与", "事件 X")]
# 构建知识图谱的逻辑(这里只是简单示意)
knowledge_graph = {}
for entity in entities:
knowledge_graph[entity] = []
for relation in relations:
source, rel, target = relation
knowledge_graph[source].append((rel, target))
# 输出知识图谱的部分内容
for entity, connections in knowledge_graph.items():
print(f"{entity}: {connections}")
八、hanlp内容推荐
以下是一个简单的使用 HanLP 结合一些基本逻辑来实现内容推荐的示例代码,这里只是一个非常简单的示意,实际应用中会复杂很多:
from pyhanlp import *
# 一些示例内容和标签
contents = {
"文章 1": "科技 人工智能",
"文章 2": "娱乐 明星",
"文章 3": "科技 大数据",
"文章 4": "娱乐 电影"
}
def recommend_content(user_interest):
recommended = []
for content, tags in contents.items():
if user_interest in tags:
recommended.append(content)
return recommended
# 假设用户对科技感兴趣
user_interest = "科技"
print(recommend_content(user_interest))
九、hanlp文档自动处理
以下是一个使用 HanLP 进行文档自动处理的简单示例,比如对文档进行分词和词性标注:
from pyhanlp import *
def process_document(document):
# 分词
tokenizer = HanLP.newSegment()
tokens = tokenizer.seg(document)
# 词性标注
pos_tagger = HanLP.newPOSTagger()
pos_tags = pos_tagger.tag(tokens)
for i in range(len(tokens)):
print(f"{tokens[i].word} - {pos_tags[i]}")
document = "这是一个文档示例,用于 HanLP 处理。"
process_document(document)https://blog.csdn.net/2301_80854431/article/details/138907842















 2168
2168











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









