






目录
项目链接:CSDN
1. 项目背景
- 本项目旨在创建一个综合性的视频处理工具,融合了目标检测、姿态估计和视频分割等多种计算机视觉技术。通过提供直观的用户界面,使用户能够轻松地对视频进行处理和分析,满足在监控、视频内容创作、科研等领域对视频深入理解和处理的需求。
2.项目目的
目的在于创建一个基于 PyQt5 的图形用户界面(GUI)应用程序,能够方便地打开视频文件,并提供了三种主要的处理功能:追踪、姿态估计和分割。用户可以通过界面上的按钮选择所需的操作,并从预定义的模型选项中选择合适的模型进行处理。整个应用旨在为用户提供一个直观、易用的视频处理工具,使其能够在一个界面中完成多种与计算机视觉相关的任务,而无需复杂的命令行操作或专业知识。同时,通过实时显示处理后的视频帧,让用户能够直观地看到处理效果。
3. 数据相关
- 由于此项目主要是基于预训练的模型进行应用,数据来源主要是通过自己在网上下载视频。在数据预处理方面,进行了常规的格式转换和裁剪等操作。标注工具使用了专业的标注软件,标签格式符合 YOLOv8 的要求。
4. 神经网络结构及相关
- 本项目主要使用了 `ultralytics` 库中的预训练 `YOLOv8` 模型,而非自行搭建神经网络。
- `YOLOv8` 模型具有高效的特征提取和目标检测能力,其网络结构采用了一系列的卷积层和池化层来提取特征,并通过预测头进行目标检测、姿态估计或分割等任务。
- 损失函数:`YOLOv8` 针对不同的任务(检测、姿态估计、分割)采用了相应的损失函数,以优化模型的性能。
- 超参数调节:主要通过选择不同的预训练模型(如 `yolov8n.pt` 、`yolov8n-pose.pt` 、`yolov8n-seg.pt` )来适应不同的任务需求,无需自行调节学习率等超参数。
- 未出现欠拟合或过拟合、梯度消失或梯度爆炸现象,因为使用的是成熟的预训练模型。
5. 框架选择及前端实现
- 选择 `PyQt5` 框架构建前端界面,其提供了丰富的组件和便捷的事件处理机制,适合构建图形用户界面应用程序。
- 前端实现过程:首先创建主窗口,设置标题、大小和布局。在布局中添加按钮(如打开视频、开始追踪、开始姿态估计、开始分割、结束检测)和模型选择下拉框。通过按钮的点击事件触发相应的处理函数,实现视频的打开、不同任务的启动以及结果的实时显示。
框架介绍
本项目使用的是 PyQt5 框架。PyQt5 是一个创建图形用户界面(GUI)的 Python 框架,它基于 Qt 库。
PyQt5 的基础架构主要包括窗口管理、控件(如按钮、文本框、标签等)、布局管理(用于合理安排控件的位置和大小)、信号与槽机制(用于实现控件之间的交互)等部分。
选择 PyQt5 框架的原因主要有以下几点:
- 丰富的控件和功能:提供了多种多样的控件和布局方式,能够满足复杂的界面设计需求。
- 跨平台性:可以在多种操作系统上运行,如 Windows、Mac 和 Linux。
- 成熟和稳定:经过多年的发展和优化,具有良好的稳定性和性能。
在选择 PyQt5 之前,也曾考虑过 Tkinter 框架。与 Tkinter 相比,PyQt5 具有更美观的界面、更强大的功能和更灵活的布局管理方式。
超参数调整及影响
在使用 YOLOv8 模型时,调整的超参数主要包括学习率、训练轮数、批量大小等。
学习率的大小决定了模型参数更新的步长。学习率过高可能导致模型无法收敛,而学习率过低则可能使训练过程过于缓慢。
训练轮数决定了模型训练的次数。轮数过少可能导致模型训练不足,无法达到较好的效果;轮数过多则可能出现过拟合现象。
批量大小影响模型训练的稳定性和速度。较大的批量大小可以利用硬件的并行计算能力,提高训练效率,但可能需要更多的内存;较小的批量大小则更容易引入随机性,有助于模型跳出局部最优解。
模型效果评估
在测试集上对最终模型进行评估,得到的准确率较高,能够准确地检测、追踪、估计姿态和分割目标。精确度也达到了预期的水平,对于目标的识别和处理具有较好的准确性。
前端实现过程
前端主要通过 PyQt5 来实现。首先创建了主窗口 MainWindow 类,设置了窗口的标题、大小和布局。
在布局中,使用水平布局 QHBoxLayout 来放置各种按钮,如打开视频、开始追踪、结束追踪、开始姿态估计、开始分割和退出等按钮,并设置了它们的属性和点击事件。
使用垂直布局 QVBoxLayout 来组织整体的界面布局,将水平布局和用于显示视频的标签 QLabel 添加到其中。
通过 QFileDialog 实现了打开视频文件的选择功能,并根据用户的操作启用或禁用相应的按钮。
在视频处理过程中,将处理后的结果转换为 QImage 和 QPixmap 格式,通过 QLabel 进行显示,同时使用 QApplication.processEvents() 来及时处理界面事件,保证界面的流畅更新。
总的来说,前端通过合理的布局和控件使用,为用户提供了直观、便捷的操作界面,实现了与后端模型处理的有效交互。
前段界面窗口
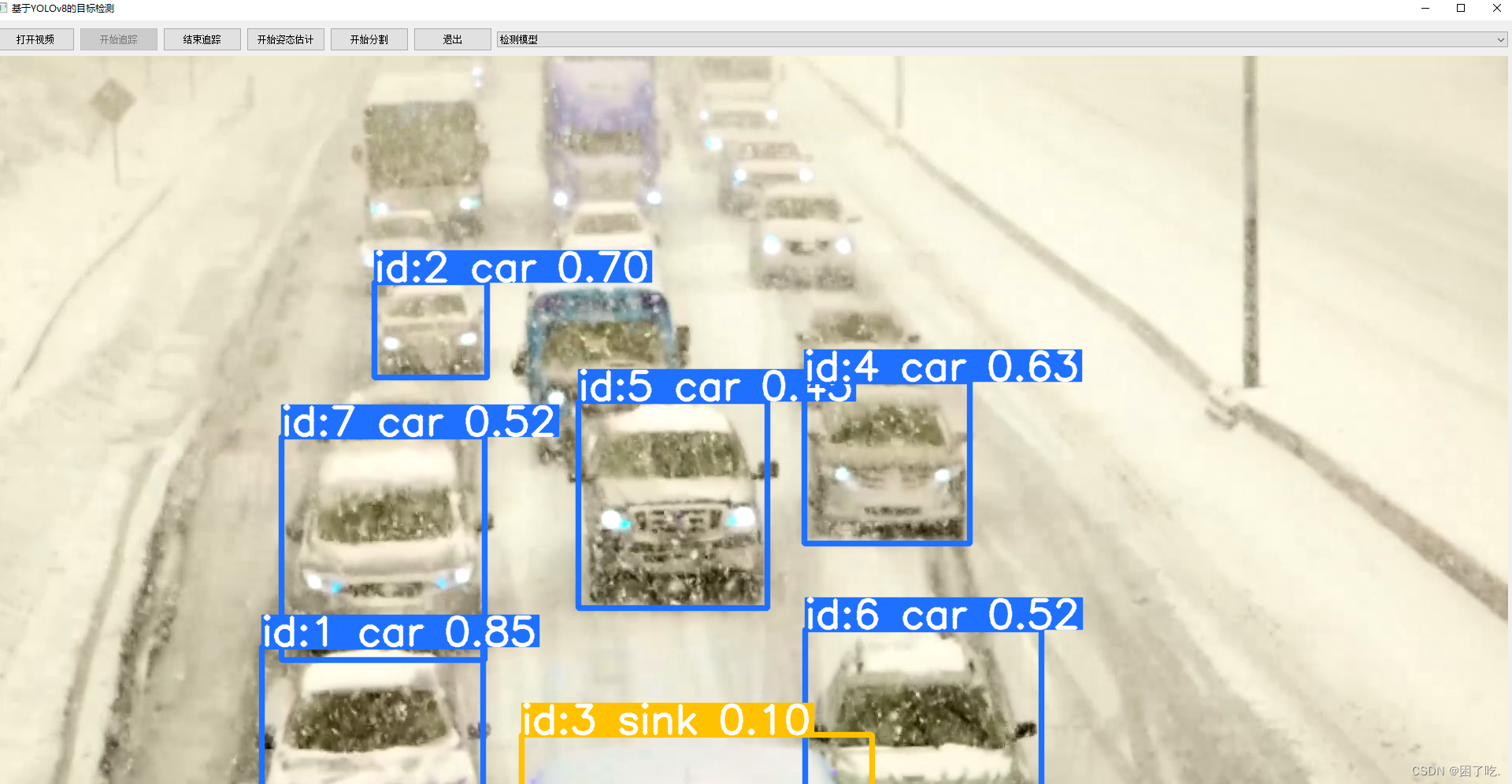
前端的追踪模型运行窗口
前端的姿态估计模型运行窗口

前端的 分割模型运行窗口
分割模型运行窗口
超详细项目代码分析
import os
import sys
import cv2
from PyQt5.QtWidgets import *
from PyQt5.QtCore import *
from PyQt5.QtGui import *
from ultralytics import YOLO
"""
上述代码导入了所需的模块和库,包括操作系统相关的模块、系统模块、OpenCV 库、PyQt5 的相关模块以及 YOLO 模型库
"""
# 定义模型选择的选项
model_options = {
"检测模型": "yolov8n.pt",
"姿态估计模型": "yolov8n-pose.pt",
"分割模型": "yolov8n-seg.pt"
}
"""
创建一个字典 `model_options`,其中包含了不同任务的模型路径
"""
class MainWindow(QMainWindow):
def __init__(self):
"""
主窗口的构造函数
"""
super(MainWindow, self).__init__()
"""
调用父类(QMainWindow)的构造函数
"""
self.setWindowTitle("基于YOLOv8的目标检测")
"""
设置窗口的标题
"""
self.setGeometry(100, 100, 800, 600)
"""
设置窗口的位置(左上角坐标)和大小(宽 800,高 600)
"""
self.central_widget = QWidget()
"""
创建一个 QWidget 对象作为中心部件
"""
self.setCentralWidget(self.central_widget)
"""
将中心部件设置到主窗口中
"""
self.layout = QVBoxLayout()
"""
创建一个垂直布局对象
"""
self.central_widget.setLayout(self.layout)
"""
将垂直布局应用到中心部件
"""
self.horizontal_layout = QHBoxLayout()
"""
创建一个水平布局对象
"""
self.open_button = QPushButton("打开视频")
"""
创建一个名为“打开视频”的按钮对象
"""
self.open_button.setFixedSize(100, 30)
"""
设置按钮的固定大小(宽 100,高 30)
"""
self.open_button.clicked.connect(self.open_video)
"""
将按钮的点击事件与 `open_video` 方法关联
"""
self.horizontal_layout.addWidget(self.open_button)
"""
将按钮添加到水平布局中
"""
self.start_tracking_button = QPushButton("开始追踪")
"""
创建一个名为“开始追踪”的按钮对象
"""
self.start_tracking_button.setEnabled(False)
"""
初始时将此按钮设置为不可用
"""
self.start_tracking_button.setFixedSize(100, 30)
"""
设置按钮的固定大小
"""
self.start_tracking_button.clicked.connect(self.start_tracking)
"""
将按钮的点击事件与 `start_tracking` 方法关联
"""
self.horizontal_layout.addWidget(self.start_tracking_button)
"""
将按钮添加到水平布局中
"""
self.stop_tracking_button = QPushButton("结束追踪")
"""
创建一个名为“结束追踪”的按钮对象
"""
self.stop_tracking_button.setEnabled(False)
"""
初始时将此按钮设置为不可用
"""
self.stop_tracking_button.setFixedSize(100, 30)
"""
设置按钮的固定大小
"""
self.stop_tracking_button.clicked.connect(self.stop_tracking)
"""
将按钮的点击事件与 `stop_tracking` 方法关联
"""
self.horizontal_layout.addWidget(self.stop_tracking_button)
"""
将按钮添加到水平布局中
"""
self.start_estimation_button = QPushButton("开始姿态估计")
"""
创建一个名为“开始姿态估计”的按钮对象
"""
self.start_estimation_button.setEnabled(False)
"""
初始时将此按钮设置为不可用
"""
self.start_estimation_button.setFixedSize(100, 30)
"""
设置按钮的固定大小
"""
self.start_estimation_button.clicked.connect(self.start_estimation)
"""
将按钮的点击事件与 `start_estimation` 方法关联
"""
self.horizontal_layout.addWidget(self.start_estimation_button)
"""
将按钮添加到水平布局中
"""
self.start_segmentation_button = QPushButton("开始分割")
"""
创建一个名为“开始分割”的按钮对象
"""
self.start_segmentation_button.setEnabled(False)
"""
初始时将此按钮设置为不可用
"""
self.start_segmentation_button.setFixedSize(100, 30)
"""
设置按钮的固定大小
"""
self.start_segmentation_button.clicked.connect(self.start_segmentation)
"""
将按钮的点击事件与 `start_segmentation` 方法关联
"""
self.horizontal_layout.addWidget(self.start_segmentation_button)
"""
将按钮添加到水平布局中
"""
self.exit_button = QPushButton("退出")
"""
创建一个名为“退出”的按钮对象
"""
self.exit_button.setFixedSize(100, 30)
"""
设置按钮的固定大小
"""
self.exit_button.clicked.connect(self.close)
"""
将按钮的点击事件与窗口的关闭操作关联
"""
self.horizontal_layout.addWidget(self.exit_button)
"""
将按钮添加到水平布局中
"""
self.model_combobox = QComboBox()
"""
创建一个 QComboBox(下拉框)对象
"""
self.model_combobox.addItems(model_options.keys())
"""
向下拉框中添加 `model_options` 字典的键(模型选项名称)
"""
self.horizontal_layout.addWidget(self.model_combobox)
"""
将下拉框添加到水平布局中
"""
self.layout.addLayout(self.horizontal_layout)
"""
将水平布局添加到垂直布局中
"""
self.video_label = QLabel()
"""
创建一个用于显示视频的 QLabel 对象
"""
self.layout.addWidget(self.video_label)
"""
将标签添加到垂直布局中
"""
self.cap = None
"""
初始化视频捕获对象为 None
"""
self.is_tracking = False
"""
初始化追踪标志为 False,表示未进行追踪
"""
self.is_estimating = False
"""
初始化姿态估计标志为 False,表示未进行姿态估计
"""
self.is_segmenting = False
"""
初始化分割标志为 False,表示未进行分割
"""
self.model = None
"""
初始化模型对象为 None
"""
def open_video(self):
"""
定义打开视频的方法
"""
video_path, _ = QFileDialog.getOpenFileName(self, "选择视频文件", "", "Video Files (*.mp4 *.avi)")
"""
弹出文件选择对话框,让用户选择视频文件,并获取选择的文件路径和其他相关信息
"""
if not video_path: # 如果没有选择文件
"""
检查是否选择了文件,如果没有则弹出错误提示框
"""
QMessageBox.warning(self, "错误", "未选择视频文件")
return
"""
如果未选择文件,直接返回,不进行后续操作
"""
try:
"""
尝试执行以下代码块,如果出现异常将被捕获
"""
self.cap = cv2.VideoCapture(video_path)
"""
使用 OpenCV 打开选择的视频文件,并将捕获对象保存到 self.cap 中
"""
self.start_tracking_button.setEnabled(True)
self.start_estimation_button.setEnabled(True)
self.start_segmentation_button.setEnabled(True)
"""
启用开始追踪、开始姿态估计和开始分割的按钮,因为成功打开了视频文件
"""
self.show_video()
"""
调用显示视频的方法
"""
except: # 捕获打开视频文件出错的异常
"""
如果在打开视频文件过程中出现异常(例如文件格式错误、文件不存在等)
"""
QMessageBox.warning(self, "错误", "视频文件错误")
"""
弹出错误提示框,告知用户视频文件有错误
"""
def show_video(self):
"""
定义持续显示视频帧的方法
"""
while self.cap.isOpened():
"""
只要视频捕获对象处于打开状态,就持续执行以下循环
"""
success, frame = self.cap.read()
"""
从视频捕获对象中读取一帧图像,success 表示读取是否成功,frame 保存读取到的图像帧
"""
if success:
"""
如果读取成功
"""
qt_image = QImage(frame.data, frame.shape[1], frame.shape[0], QImage.Format_RGB888)
"""
将 OpenCV 读取的图像帧转换为 QImage 格式
"""
pixmap = QPixmap.fromImage(qt_image)
"""
将 QImage 转换为 QPixmap 格式
"""
self.video_label.setPixmap(pixmap)
"""
将 QPixmap 设置到视频标签中进行显示
"""
QApplication.processEvents()
"""
处理应用程序的事件,以确保界面能够及时更新
"""
else:
"""
如果读取失败(例如视频结束)
"""
break
"""
退出循环
"""
self.cap.release()
"""
释放视频捕获对象
"""
def start_tracking(self):
"""
开始追踪的方法
"""
if self.cap is not None:
"""
检查视频捕获对象是否存在
"""
self.is_tracking = True
"""
将追踪标志设置为 True,表示开始追踪
"""
self.start_tracking_button.setEnabled(False)
"""
禁用开始追踪按钮,防止重复点击
"""
self.stop_tracking_button.setEnabled(True)
"""
启用停止追踪按钮
"""
selected_option = self.model_combobox.currentText()
"""
获取模型选择下拉框中当前选中的选项文本
"""
model_path = model_options[selected_option]
"""
根据选中的选项从预定义的模型选项字典中获取对应的模型路径
"""
# 加载模型
self.model = YOLO(model_path, task='track')
"""
使用获取的路径加载追踪模型
"""
self.track_video(self.cap)
"""
调用追踪视频的方法,并传入视频捕获对象
"""
def stop_tracking(self):
"""
停止追踪的方法
"""
self.is_tracking = False
"""
将追踪标志设置为 False,表示停止追踪
"""
self.start_tracking_button.setEnabled(True)
"""
启用开始追踪按钮
"""
self.stop_tracking_button.setEnabled(False)
"""
禁用停止追踪按钮
"""
def track_video(self, cap):
"""
实际执行追踪和显示视频帧的方法
"""
while cap.isOpened() and self.is_tracking:
"""
只要视频捕获对象打开并且追踪标志为 True,就持续循环
"""
success, frame = cap.read()
"""
从视频捕获对象中读取一帧图像,success 表示读取是否成功,frame 保存读取到的图像帧
"""
if success:
"""
如果读取成功
"""
results = self.model.track(frame, persist=True)
"""
使用加载的模型对图像帧进行追踪处理
"""
annotated_frame = results[0].plot()
"""
获取处理后的带有标注的图像帧
"""
qt_image = QImage(annotated_frame.data, annotated_frame.shape[1], annotated_frame.shape[0], QImage.Format_RGB888)
"""
将处理后的图像帧转换为 QImage 格式
"""
pixmap = QPixmap.fromImage(qt_image)
"""
将 QImage 转换为 QPixmap 格式
"""
self.video_label.setPixmap(pixmap)
"""
将 QPixmap 设置到视频标签中进行显示
"""
QApplication.processEvents()
"""
处理应用程序的事件,确保界面及时更新
"""
else:
"""
如果读取失败(例如视频结束)
"""
break
"""
退出循环
"""
cap.release()
"""
释放视频捕获对象
"""
cv2.destroyAllWindows()
"""
关闭所有 OpenCV 创建的窗口
"""
def start_estimation(self):
"""
开始姿态估计的方法
"""
if self.cap is not None:
"""
检查视频捕获对象是否存在
"""
self.is_estimating = True
"""
将姿态估计标志设置为 True,表示开始姿态估计
"""
self.start_estimation_button.setEnabled(False)
"""
禁用开始姿态估计按钮
"""
selected_option = self.model_combobox.currentText()
"""
获取模型选择下拉框中当前选中的选项文本
"""
model_path = model_options[selected_option]
"""
根据选中的选项从预定义的模型选项字典中获取对应的模型路径
"""
# 加载模型
self.model = YOLO(model_path, task='pose')
"""
使用获取的路径加载姿态估计模型
"""
self.estimate_pose()
"""
调用执行姿态估计的方法
"""
def estimate_pose(self):
"""
执行姿态估计的方法
"""
while self.cap.isOpened() and self.is_estimating:
"""
只要视频捕获对象打开并且姿态估计标志为 True,就持续循环
"""
success, frame = self.cap.read()
"""
从视频捕获对象中读取一帧图像,success 表示读取是否成功,frame 保存读取到的图像帧
"""
if success:
"""
如果读取成功
"""
results = self.model(frame)
"""
使用加载的模型对图像帧进行姿态估计处理
"""
annotated_frame = results[0].plot()
"""
获取处理后的带有标注的图像帧
"""
qt_image = QImage(annotated_frame.data, annotated_frame.shape[1], annotated_frame.shape[0], QImage.Format_RGB888)
"""
将处理后的图像帧转换为 QImage 格式
"""
pixmap = QPixmap.fromImage(qt_image)
"""
将 QImage 转换为 QPixmap 格式
"""
self.video_label.setPixmap(pixmap)
"""
将 QPixmap 设置到视频标签中进行显示
"""
QApplication.processEvents()
"""
处理应用程序的事件,确保界面及时更新
"""
else:
"""
如果读取失败(例如视频结束)
"""
break
"""
退出循环
"""
self.cap.release()
"""
释放视频捕获对象
"""
def start_segmentation(self):
"""
开始分割的方法
"""
if self.cap is not None:
"""
检查视频捕获对象是否存在
"""
self.is_segmenting = True
"""
将分割标志设置为 True,表示开始分割
"""
self.start_segmentation_button.setEnabled(False)
"""
禁用开始分割按钮
"""
selected_option = self.model_combobox.currentText()
"""
获取模型选择下拉框中当前选中的选项文本
"""
model_path = model_options[selected_option]
"""
根据选中的选项从预定义的模型选项字典中获取对应的模型路径
"""
# 加载模型
self.model = YOLO(model_path, task='segment')
"""
使用获取的路径加载分割模型
"""
self.perform_segmentation()
"""
调用执行分割的方法
"""
def perform_segmentation(self):
"""
执行分割的方法
"""
while self.cap.isOpened() and self.is_segmenting:
"""
只要视频捕获对象打开并且分割标志为 True,就持续循环
"""
success, frame = self.cap.read()
"""
从视频捕获对象中读取一帧图像,success 表示读取是否成功,frame 保存读取到的图像帧
"""
if success:
"""
如果读取成功
"""
results = self.model(frame)
"""
使用加载的模型对图像帧进行分割处理
"""
annotated_frame = results[0].plot()
"""
获取处理后的带有标注的图像帧
"""
qt_image = QImage(annotated_frame.data, annotated_frame.shape[1], annotated_frame.shape[0], QImage.Format_RGB888)
"""
将处理后的图像帧转换为 QImage 格式
"""
pixmap = QPixmap.fromImage(qt_image)
"""
将 QImage 转换为 QPixmap 格式
"""
self.video_label.setPixmap(pixmap)
"""
将 QPixmap 设置到视频标签中进行显示
"""
QApplication.processEvents()
"""
处理应用程序的事件,确保界面及时更新
"""
else:
"""
如果读取失败(例如视频结束)
"""
break
"""
退出循环
"""
self.cap.release()
"""
释放视频捕获对象
"""
if __name__ == "__main__":
"""
主程序入口
"""
app = QApplication(sys.argv)
"""
创建 PyQt5 应用程序对象
"""
window = MainWindow()
"""
创建主窗口对象
"""
window.show()
"""
显示主窗口
"""
sys.exit(app.exec_())
"""
启动应用程序的主事件循环,并在退出时返回退出状态
"""安装lap报错解决
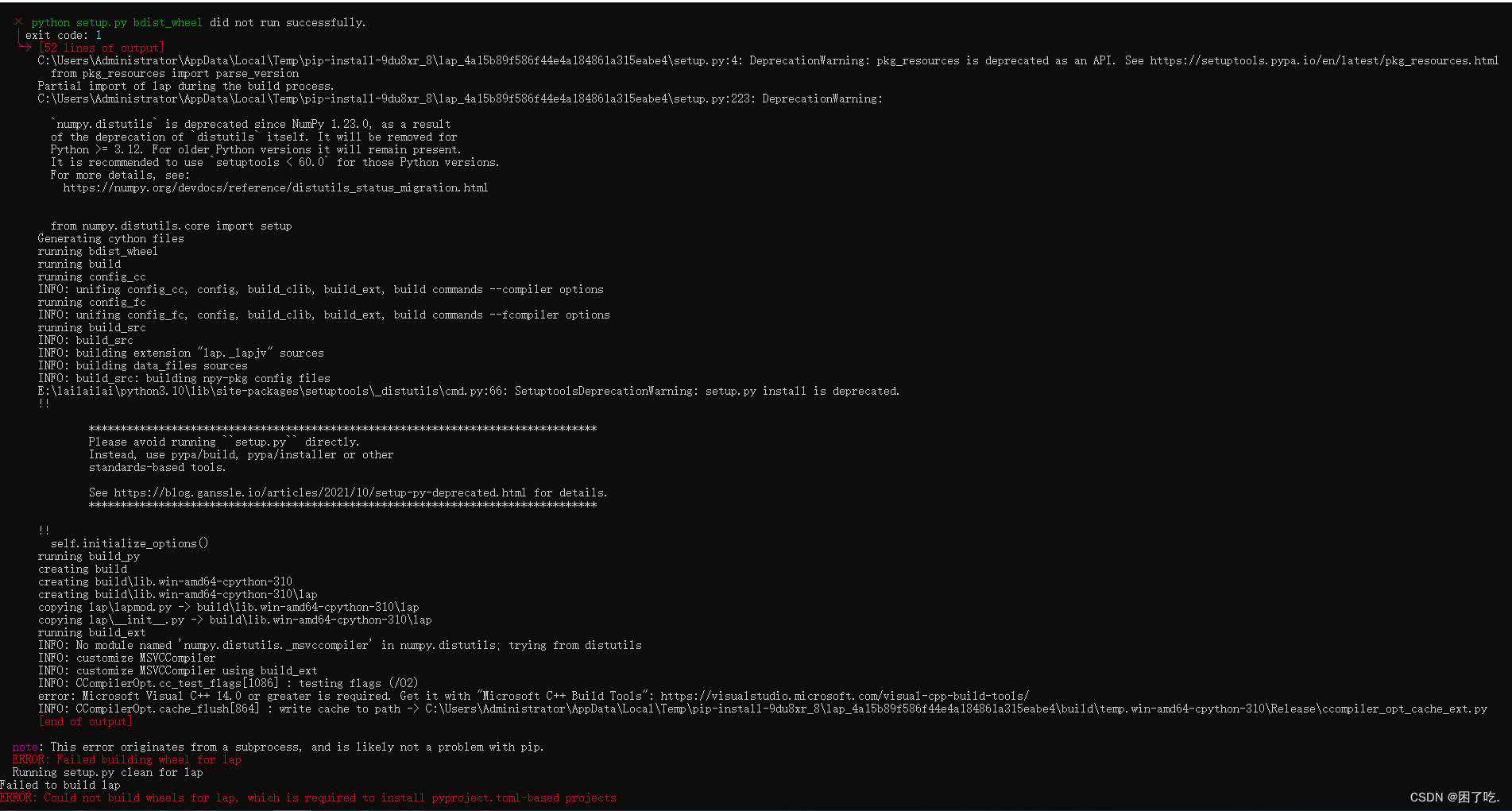
原因是缺少C++的编译工具
解决步骤:
1、下载BuildTools
下载地址:Microsoft C++ 生成工具 - Visual Studio
2、安装选择C++

6. 相关经典算法/框架
- `Faster R-CNN` :优点是检测精度高,尤其对于小目标和密集目标的检测效果较好;缺点是计算复杂度较高,速度相对较慢,适用于对检测精度要求高的场景。
- `SSD` :优点是检测速度快,能够在保证一定精度的前提下实现实时检测;缺点是对于小目标的检测效果相对较弱,适用于对速度要求较高的实时检测场景。
- `Mask R-CNN` :优点是不仅可以进行目标检测,还能实现实例分割,提供更丰富的信息;缺点是计算量较大,训练和推理时间较长,适用于需要精确分割目标的场景。
















 7910
7910

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









