






 本文介绍了Python中sys.path的使用、sigmoid/tanh/ReLU激活函数、numpy多维数组ndarray的特性、np.random.rand()和np.random.randn()的用法,以及交叉熵和随机梯度下降(SGD)在机器学习中的应用,包括权重更新策略。
本文介绍了Python中sys.path的使用、sigmoid/tanh/ReLU激活函数、numpy多维数组ndarray的特性、np.random.rand()和np.random.randn()的用法,以及交叉熵和随机梯度下降(SGD)在机器学习中的应用,包括权重更新策略。
1.sys.path.append(..)的两个点代表什么?
sys.path.append(’…’)括号里这两个点是什么意思?
这是目录的意思,即代表上一级目录。
通过这种方式,python程序会在上一级查找相应的其他python包或者文件。
sys.path.append(’…’)还有类似的sys.path.append(’…/…’) 就是代表当前位置得上两级的目录地址。
改变当前python脚本的默认搜索路径的第二种方式
把路径添加到系统的环境变量,或把该路径的文件夹放进已经添加到系统环境变量的路径内。
环境变量的内容会自动添加到模块搜索路径中。
sys模块包含了与python解释器和它的环境有关的函数;可以通过dir(sys)来查看方法和成员属性。
下面的两个方法可以将模块路径加到当前模块扫描的路径里:
sys.path.append(‘你的模块的名称’)
sys.path.insert(0,‘模块的名称’)
2.sigmiod 函数详解
激活函数在神经网络中的作用有很多,主要作用是给神经网络提供非线性建模能力。如果没有激活函数,那么再多层的神经网络也只能处理线性可分问题。常用的激活函数有 sigmoid、 tanh、 relu、 softmax等。
1.1、sigmoid函数
sigmoid函数将输入变换为(0,1)上的输出。它将范围(-inf,inf)中的任意输入压缩到区间(0,1)中的值:

sigmoid函数是⼀个⾃然的选择,因为它是⼀个平滑的、可微的阈值单元近似。当我们想要将输出视作⼆元分类问题的概率时, sigmoid仍然被⼴泛⽤作输出单元上的激活函数(你可以将sigmoid视为softmax的特例)。然而, sigmoid在隐藏层中已经较少使⽤,它在⼤部分时候被更简单、更容易训练的ReLU所取代。下面为sigmoid函数的图像表示,当输入接近0时,sigmoid更接近线形变换。

ReLU函数
线性整流单元(ReLU),ReLU提供了一种非常简单的非线性变换。给定元素x ,ReLU函数被定义为该元素与0的最大值。

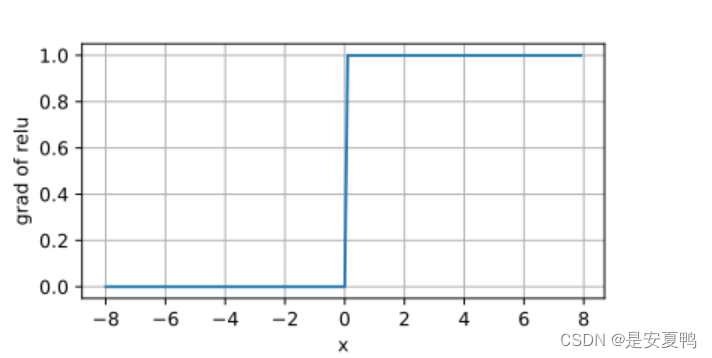
当输入为负时,reLU函数的导数为0,而当输入为正时,ReLU函数的导数为1。当输入值等于0时,ReLU函数不可导。如下为ReLU函数的导数:
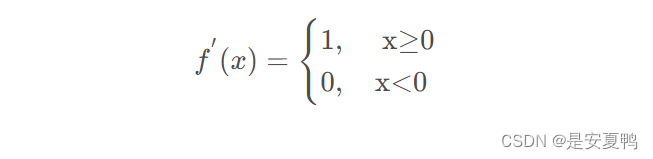
对其求导的函数图像的实现:
3.Numpy中的多维数组ndarray
1 Python中的数组
- 用list和tuple等数据结构表示数组
- 一维数组 List1 = [1, 2, 3]
- 二维数组 Tuple1 = ([1, 2, 3], [4, 5, 6], [7, 8, 9])
但是:列表是动态指针数组,它保存的是对象的指针,其元素可以是任意类型的对象。比如要保存上述的List1,需要3个指针和3个整数对象,浪费内存和计算时间。
- array模块(非内置模块)
- 通过array函数创建数组 array.array()
- 提供append、insert和read等方法
但是:array模块中的array函数不支持多维数组,且函数功能不丰富。
2 NumPy中的N维数组ndarray
- NumPy中基本的数据结构
- 所有元素是同一种类型
- 别名array(数组)
- 节省内存,提高CPU计算时间
- 有丰富的函数
注:NumPy的思维模式是面向数组。
3 ndarray数组属性
- 下标从0开始。
- 一个ndarray数组中的所有元素的类型必须相同。
- 轴(axis):
每一个线性的数组称为是一个轴,也就是维度(dimensions)。比如,二维数组相当于是两个一维数组,其中第一个一维数组中每个元素又是一个一维数组,所以一维数组就是ndarray中的轴,第一个轴(也就是第0轴)相当于是底层数组,第二个轴(也就是第1轴)是底层数组里的数组。
很多时候可以声明axis。axis=0,表示沿着第0轴进行操作,即对每一列进行操作;axis=1,表示沿着第1轴进行操作,即对每一行进行操作。
- 秩(rank):
维数,一维数组的秩为1,二维数组的秩为2,以此类推。即轴的个数。
- 基本属性
ndarray1.ndim - 秩
ndarray1.shape - 维度 # 是一个元组,表示数组在每个维度上的大小。比如,一个二维数组,其维度表示“行数”和“列数”。该元组的长度即为秩。
ndarray1.size - 元素总个数 # 等于shape属性中元组元素的乘积。
ndarray1.dtype - 元素类型
4.详述numpy中的np.random.rand(),np.random.randn()的用法
1.np.random.rand()
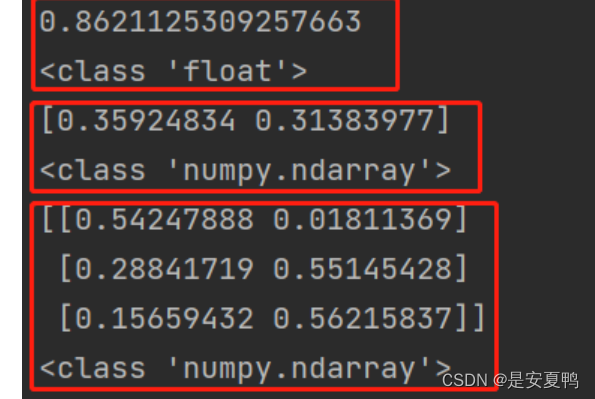
该函数括号内的参数指定的是返回结果的形状,如果不指定,那么生成的是一个浮点型的数;如果指定一个数,那么生成的是一个numpy.ndarray类型的数组;如果指定两个数字,那么生成的是一个二维的numpy.ndarray类型的数组。如果是两个以上的数组,那么返回的维度就和指定的参数的数量个数一样。其返回结果中的每一个元素是服从0~1均匀分布的随机样本值,也就是返回的结果中的每一个元素值在0-1之间。
import numpy as np
mat = np.random.rand()
print(mat)
print(type(mat))
mat = np.random.rand(2)
print(mat)
print(type(mat))
mat = np.random.rand(3, 2)
print(mat)
print(type(mat))运行结果:
2.np.random.randn()
该函数和rand()函数比较类似,只不过运用该函数之后返回的结果是服从均值为0,方差为1的标准正态分布,而不是局限在0-1之间,也可以为负值,因为标准正态分布的曲线是关于x轴对阵的。其括号内的参数如果不指定,那么生成的是一个浮点型的数;如果指定一个数,那么生成的是一个numpy.ndarray类型的数组;如果指定两个数字,那么生成的是一个二维的numpy.ndarray类型的数组。和rand()相比,除了元素值不一样,其他的性质是一样的。
import numpy as np
mat = np.random.randn()
print(mat)
print(type(mat))
mat = np.random.randn(2)
print(mat)
print(type(mat))
mat = np.random.randn(3, 2)
print(mat)
print(type(mat))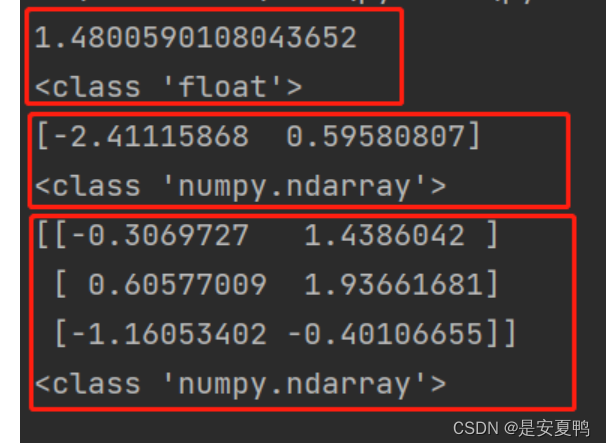
5.交叉熵详解
损失函数原理详解
之前在代码中经常看见交叉熵损失函数(CrossEntropy Loss),只知道它是分类问题中经常使用的一种损失函数,对于其内部的原理总是模模糊糊,而且一般使用交叉熵作为损失函数时,在模型的输出层总会接一个softmax函数,至于为什么要怎么做也是不懂,所以专门花了一些时间打算从原理入手,搞懂它,故在此写一篇博客进行总结,以便以后翻阅。
交叉熵简介
交叉熵是信息论中的一个重要概念,主要用于度量两个概率分布间的差异性,要理解交叉熵,需要先了解下面几个概念。
信息量
信息奠基人香农(Shannon)认为“信息是用来消除随机不确定性的东西”,也就是说衡量信息量的大小就是看这个信息消除不确定性的程度。
“太阳从东边升起”,这条信息并没有减少不确定性,因为太阳肯定是从东边升起的,这是一句废话,信息量为0。
”2018年中国队成功进入世界杯“,从直觉上来看,这句话具有很大的信息量。因为中国队进入世界杯的不确定性因素很大,而这句话消除了进入世界杯的不确定性,所以按照定义,这句话的信息量很大。
根据上述可总结如下:信息量的大小与信息发生的概率成反比。概率越大,信息量越小。概率越小,信息量越大。
设某一事件发生的概率为P(x),其信息量表示为:

其中I ( x ) 表示信息量,这里log \loglog表示以e为底的自然对数。
信息熵
信息熵也被称为熵,用来表示所有信息量的期望。
期望是试验中每次可能结果的概率乘以其结果的总和。
所以信息量的熵可表示为:
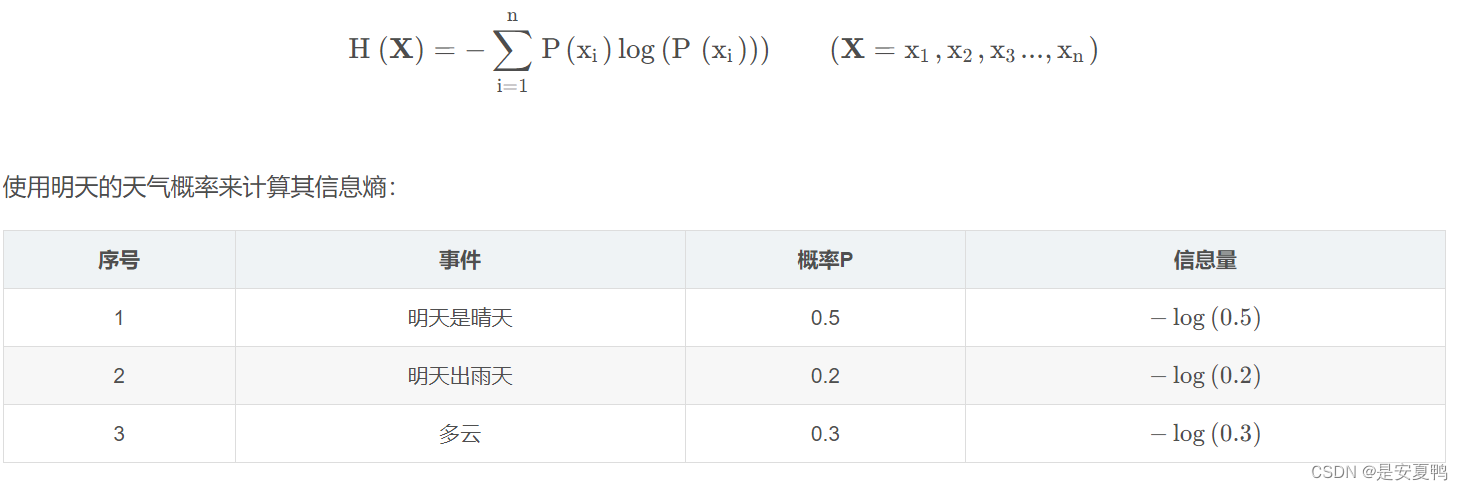
其他解释:

参考文章:
https://blog.csdn.net/tsyccnh/article/details/79163834
6.reshape的应用
Numpy中reshape的用法_numpy reshape-CSDN博客
7.None的深度理解
本文链接:【python】Python中的None_python none 0-CSDN博客
8.grads[0][...] = dW
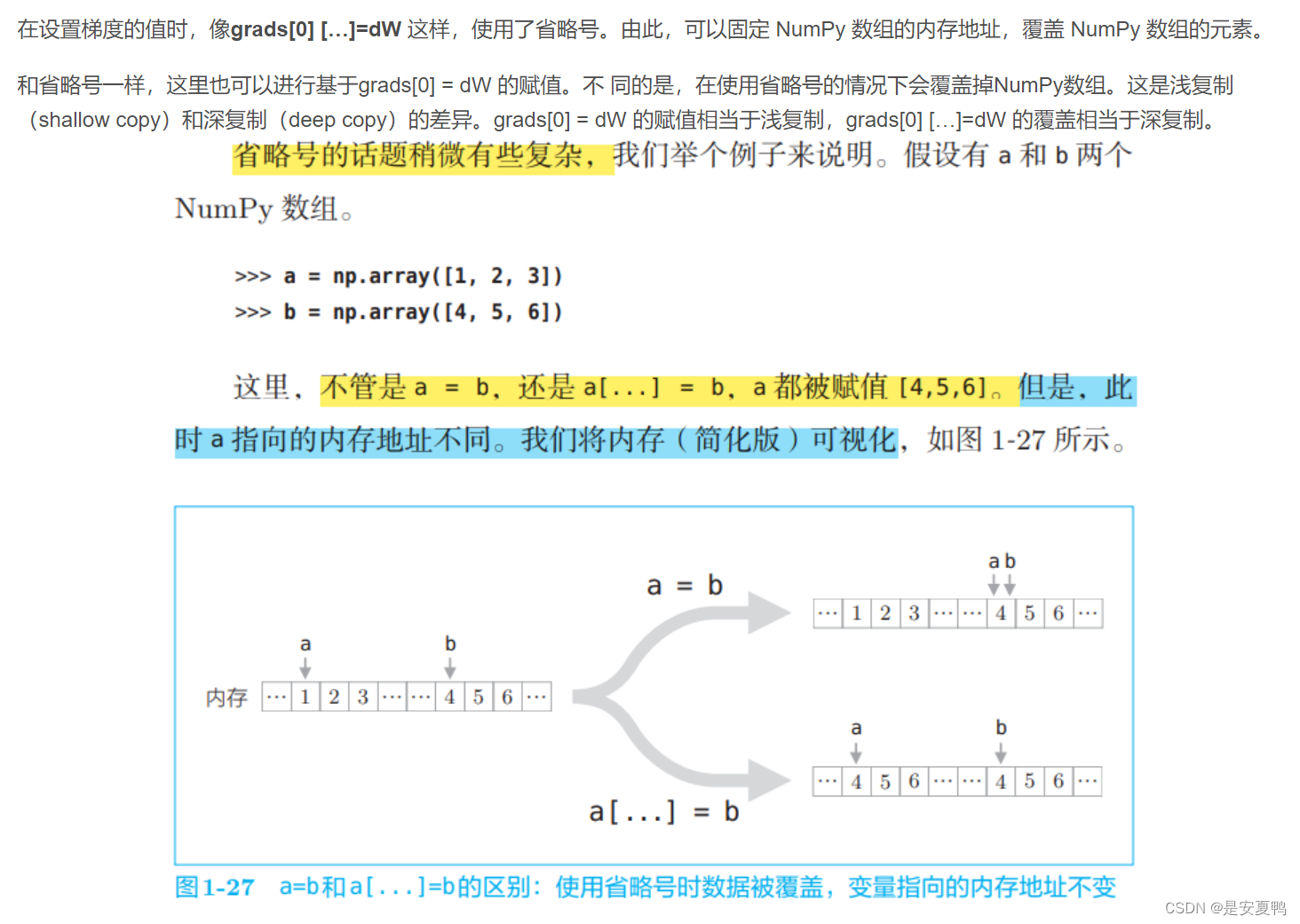

9.np.zeros_like() 函数
np.zeros_like() 是一个 NumPy 函数,它可以创建一个新数组,其形状和类型与给定数组相同,但是所有元素都被设置为 0。
例如:
import numpy as np
a = np.array([[1, 2, 3], [4, 5, 6]])
b = np.zeros_like(a)
print(b)
[[0 0 0] [0 0 0]]
参数:
- a:输入数组。
返回值:
一个新的数组,其形状和类型与给定数组相同,但所有元素都被设置为 0。
10.ndim的作用:

本文链接:Numpy中ndim、shape、dtype、astype的用法_numpy ndim-CSDN博客
11.Softmax函数(形象分析):
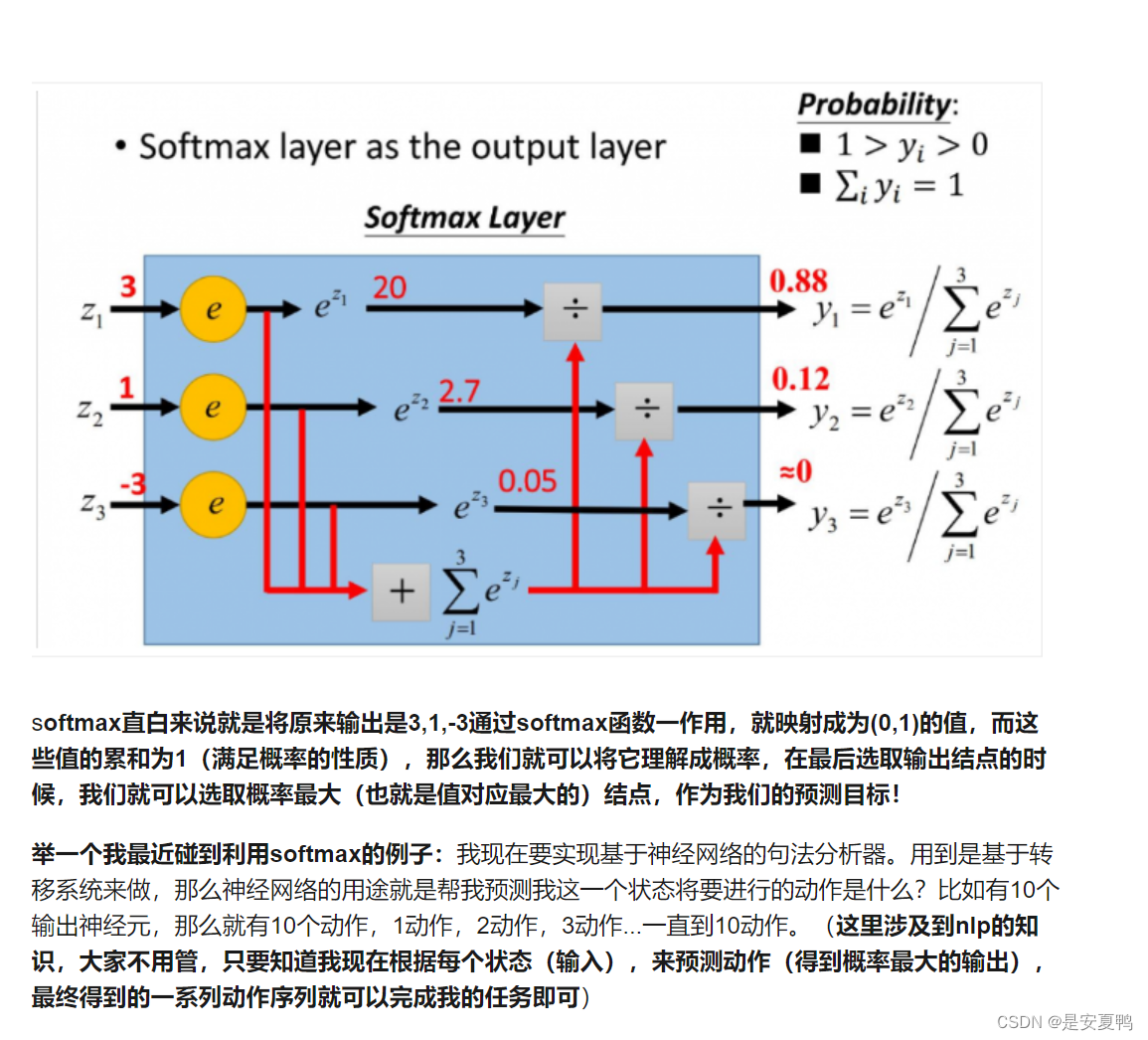
12.随机梯度下降法(stochastic gradient descent,SGD)
SGD算法是从样本中随机抽出一组,训练后按梯度更新一次,然后再抽取一组,再更新一次,在样本量及其大的情况下,可能不用训练完所有的样本就可以获得一个损失值在可接受范围之内的模型了。(重点:每次迭代使用一组样本。)
为什么叫随机梯度下降算法呢?这里的随机是指每次迭代过程中,样本都要被随机打乱,这个也很容易理解,打乱是有效减小样本之间造成的参数更新抵消问题。
对于权值的更新不再通过遍历全部的数据集,而是选择其中的一个样本即可。一般来说其步长的选择比梯度下降法的步长要小一点,因为梯度下降法使用的 是准确梯度,所以它可以朝着全局最优解(当问题为凸问题时)较大幅度的迭代下去,但是随机梯度法不行,因为它使用的是 近似梯度,或者对于全局来说有时候它走的也许根本不是梯度下降的方向,故而它走的比较缓,同样这样带来的好处就是相比于梯度下降法,它不是那么容易陷入到局部最优解中去。
优点:
(1)由于不是在全部训练数据上的损失函数,而是在每轮迭代中,随机优化某一条训练数据 上的损失函数,这样每一轮参数的更新速度大大加快。
缺点:
(1)准确度下降。由于即使在目标函数为强凸函数的情况下,SGD仍旧无法做到线性收敛。
(2)可能会收敛到局部最优,由于单个样本并不能代表全体样本的趋势。
(3)不易于并行实现。
代码实现:
def SGD_LR(data_x, data_y, alpha=0.1, maxepochs=10000,epsilon=1e-4):
xMat = np.mat(data_x)
yMat = np.mat(data_y)
m, n = xMat.shape
weights = np.ones((n, 1)) # 模型参数
epochs_count = 0
loss_list = []
epochs_list = []
while epochs_count < maxepochs:
rand_i = np.random.randint(m) # 随机取一个样本
loss = cost(xMat,weights,yMat) #前一次迭代的损失值
hypothesis = sigmoid(np.dot(xMat[rand_i,:],weights)) #预测值
error = hypothesis -yMat[rand_i,:] #预测值与实际值误差
grad = np.dot(xMat[rand_i,:].T,error) #损失函数的梯度
weights = weights - alpha*grad #参数更新
loss_new = cost(xMat,weights,yMat)#当前迭代的损失值
print(loss_new)
if abs(loss_new-loss)<epsilon:
break
loss_list.append(loss_new)
epochs_list.append(epochs_count)
epochs_count += 1
print('迭代到第{}次,结束迭代!'.format(epochs_count))
plt.plot(epochs_list,loss_list)
plt.xlabel('epochs')
plt.ylabel('loss')
plt.show()
return weights原文链接:https://www.cnblogs.com/hls-code/p/15337302.html
















 856
856











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









