







DeepSeek-Prover-V1 展示了大模型在数学定理证明领域的潜力,通过将数学问题转换为 Lean 编程语言,帮助数学家严格验证证明正确性。
今天,DeepSeek 开源 Prover-V1.5 版本,引入了类似 AlphaGo 的强化学习系统,模型通过自我迭代和 Lean 证明器监督,构建了一个“围棋”式的学习环境。
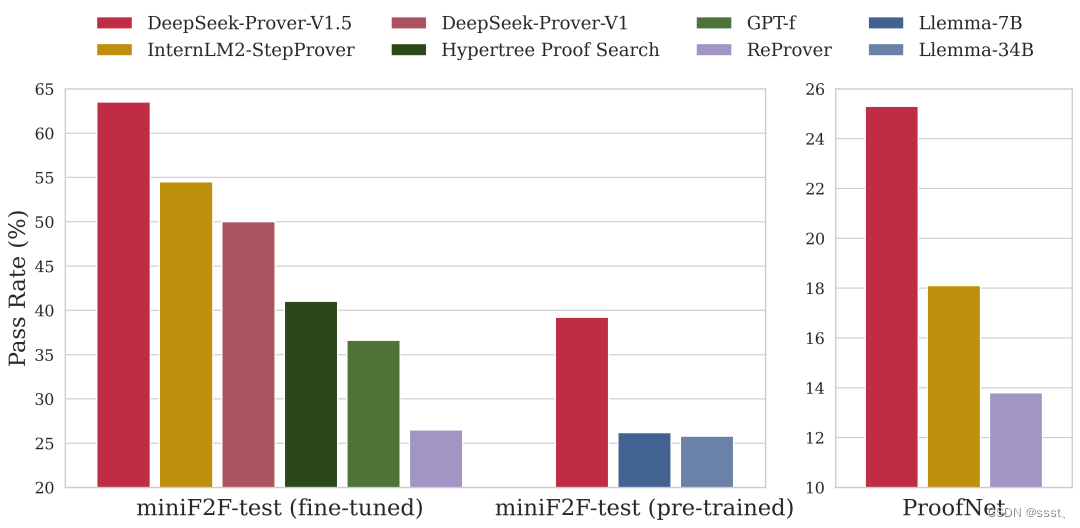
最终,仅 7B 参数规模的 Prover-V1.5,在高中(miniF2F)和大学(ProofNet)数学定理证明测试中分别达到了 63.5% 和 25.3% 的成功率,超越了多款开源模型(InternLM2-StepProver、Llemma)。
Highlights
- 数据:使用 DeepSeek-Coder-V2 合成自然语言思维链标注数据,结合 Lean 证明器标注的中间状态信息,将模型的形式化证明能力与自然语言推理对齐,同时满足程序验证的要求。
- 训练:以 Lean 证明器的验证结果直接作为奖励信号,使用 GRPO 算法对模型进行强化学习训练。
- 蒙特卡洛树搜索:引入 RMaxTS 算法,激励探索行为以解决证明搜索中的奖励稀疏问题,增强模型灵活生成多样化证明的能力。
- 实验结果:在高中水平的 miniF
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4460
4460

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









