






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
在数字化时代的浪潮中,计算机视觉技术正以其独特的魅力引领着科技创新的潮流。其中,目标检测作为计算机视觉的核心任务之一,其目的在于从复杂的图像或视频场景中准确地识别并定位出感兴趣的目标对象。近年来,随着深度学习技术的蓬勃发展,目标检测领域也取得了长足的进步,其中YOLO(You Only Look Once)系列模型以其高效、精准的特性受到了广泛关注。本文就基于YOLO(you Only Look Once)模型进行目标检测。
一、yolo是什么?
YOLO (You Only Look Once) 是一种先进的实时目标检测算法,由Joseph Redmon、Santosh Divvala、RossGirshick和Ali Farhadi在2015年首次提出,并在后续的版本中得到了不断的优化和改进。YOLO的核心思想是将目标检测任务当作一个单一的回归问题来处理,从而实现了快速的检测速度和高精度。
二、基于yolov4模型实现目标检测
1.yolov4模型介绍
YOLOv4 网络的结构可分为四部分:输入端、主干网络(Backbone)-主干特征提取网络、颈部网络(Neck)-加强特征提取网络和头部网络(Head)--用来预测(Prediction)下图为 YOLOv4 算法的网络框架示意图。
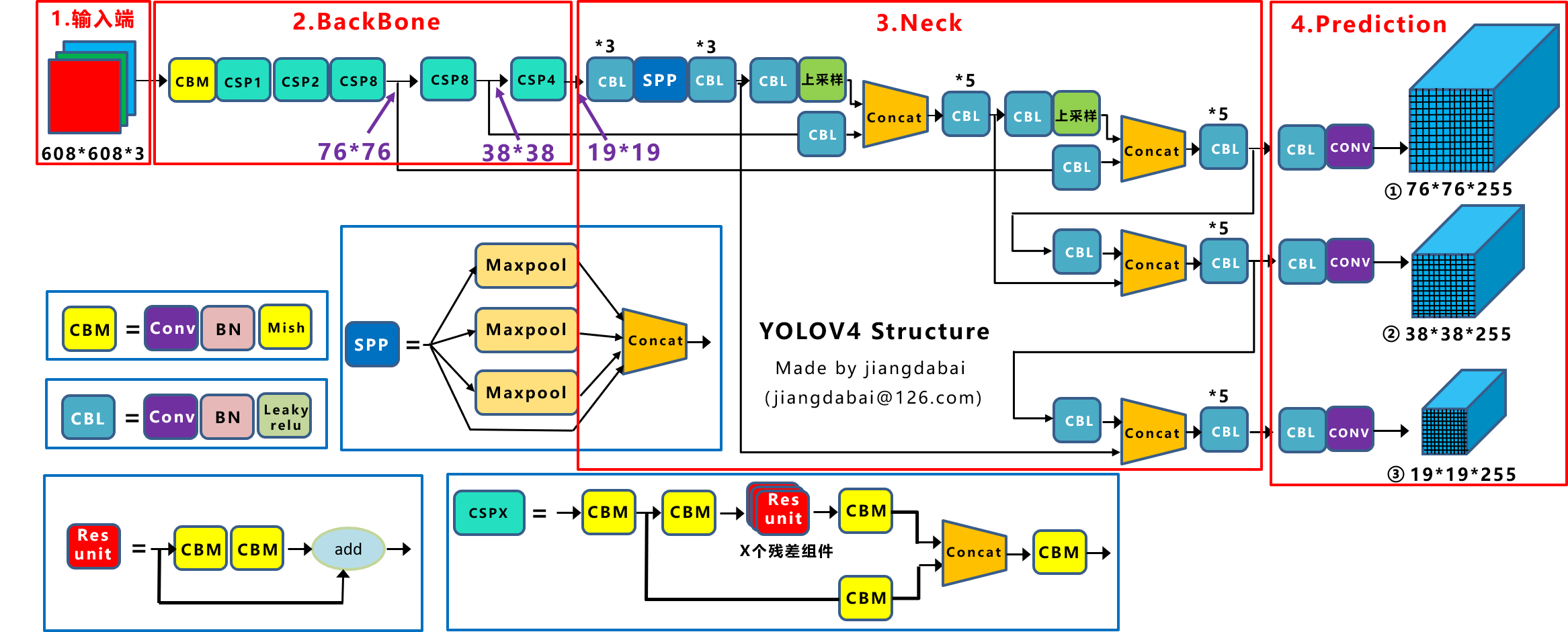
YOLOv4的五个基本组件:
CBM:Yolov4网络结构中的最小组件,由Conv+Bn+Mish激活函数三者组成。
CBL:由Conv+Bn+Leaky_relu激活函数三者组成。
Res unit:借鉴Resnet网络中的残差结构,让网络可以构建的更深。
CSPX:借鉴CSPNet网络结构,由三个卷积层和X个Res unint模块Concate组成。
SPP:采用1×1,5×5,9×9,13×13的最大池化的方式,进行多尺度融合。
2.labellmg简介
yolov4模型实现目标检测的实现需要用到labellmg工具的辅助,LabelImg是一款功能强大、易于使用的图片标注工具,它提供了直观的图形用户界面,支持多种标注格式,并且可以在多个平台上运行。使用LabelImg可以快速、准确地进行图片标注,为计算机视觉和机器学习任务提供了重要的数据支持。以下是使用LabelImg进行图片标注的示例代码:
pythonCopy codeimport os
import sys
from labelImg import main
if __name__ == '__main__':
# 设置图片文件夹路径和标注文件夹路径
image_folder = 'path/to/images'
annotation_folder = 'path/to/annotations'
# 检查标注文件夹是否存在,若不存在则创建
if not os.path.exists(annotation_folder):
os.makedirs(annotation_folder)
# 设置命令行参数
argv = ['labelImg.py', image_folder, 'pascal', annotation_folder]
# 调用LabelImg的主函数进行标注
main(argv)在上述示例代码中,需要将image_folder和annotation_folder分别设置为图片文件夹和标注文件夹的路径。然后通过调用main函数传入命令行参数进行标注。其中,'pascal'表示使用PASCAL VOC格式进行标注,你也可以根据需要选择其他标注格式。 运行上述代码后,将会打开LabelImg的图形用户界面,你可以使用鼠标在图片上进行标注,并保存标注结果到指定的标注文件夹中。 请注意,在运行示例代码之前,需要先安装LabelImg和其依赖的库。你可以使用pip install labelImg命令进行安装。
3.数据集准备
这里我准备了一百张.jpg图片,利用labellmg进行图片标注,以下是具体流程:
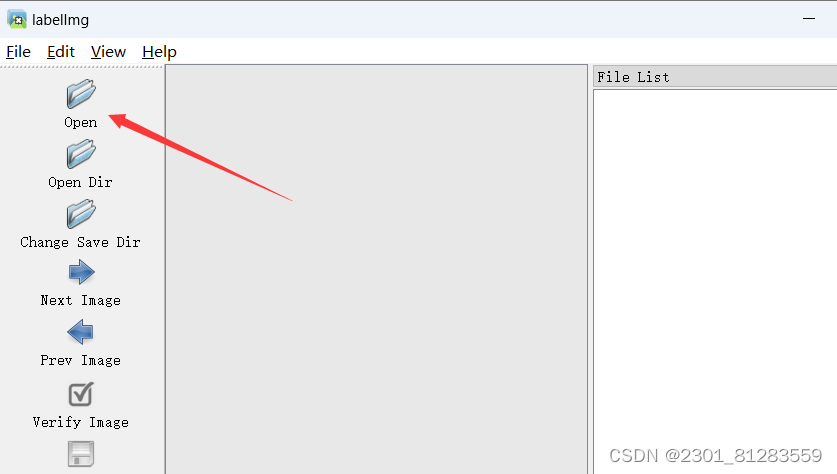
(1)在labellmg的左上角的open打开你要标注的图片
(2)按w键对图片进行标注,标注完点击左上角的File然后save as在yolov4-pytorch-master(2)\yolov4-pytorch-master\VOCdevkit\VOC2007\Annotations,文件类型为(*.xml)
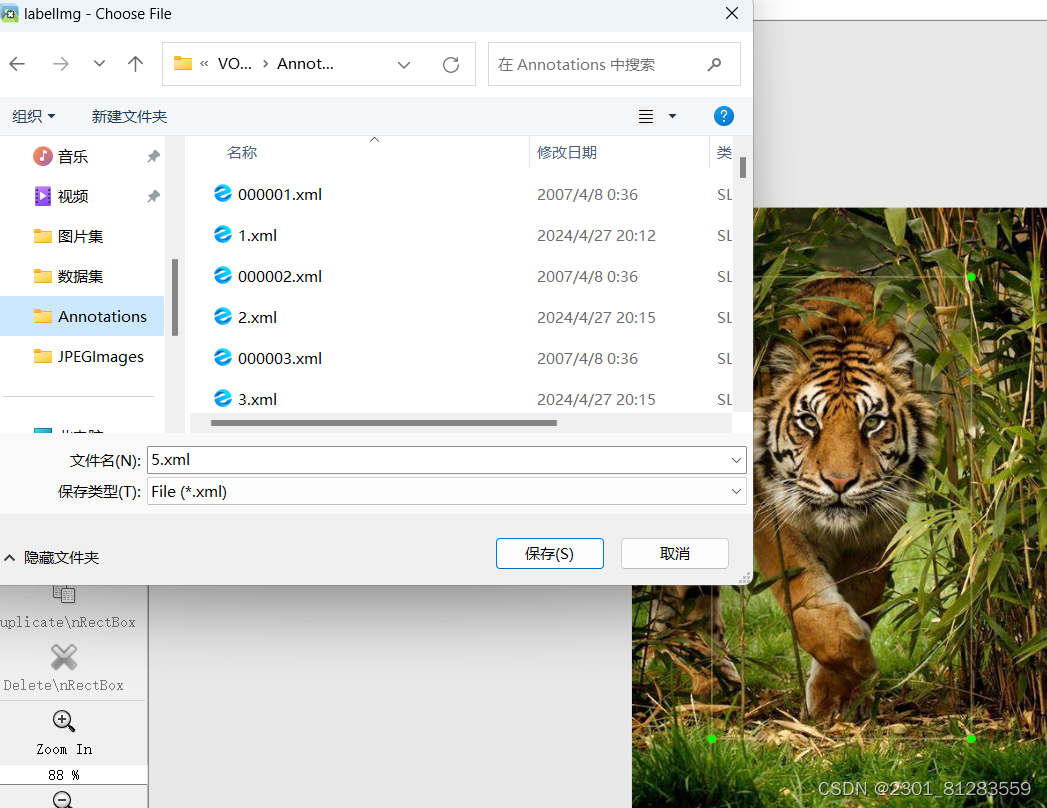
这样就对图片标注完成了。
注:上述提到的yolov4-pytorch-master(2)\yolov4-pytorch-master\VOCdevkit\VOC2007\Annotations文件地址是我上课老师向我们提供的,还有就是你要进行标注的图片要保存在yolov4-pytorch-master(2)\yolov4-pytorch-master\VOCdevkit\VOC2007\JPEGImages文件夹下。
4.环境搭建
这里我是用pycharm来运行的,详细的pycharm安装见https://blog.csdn.net/Z987421/article/details/131422753
安装并搭好环境后,打开我们的yolov4项目,我用到的是python的解释器,对缺少的库我们可以在终端输入pip install 你想要的库 -i 镜像源网址 命令来进行安装。

5.运行yolo.py
注意:
- 使用自己训练好的模型进行预测一定要修改model_path和classes_path!
- model_path指向log文件夹下的权值文件,classes_pth指向madel_data下的txt
- 训练好后logs文件夹下存在多个权值文件,选择验证集损失较低的即可。
- 验证集损失较低不代表mAP较高,仅代表该权值在验证集上泛化性能较好。
- 如果出现shape不匹配,同时要注意训练时的model_path和classes_path参数的修改
运行结果如下:

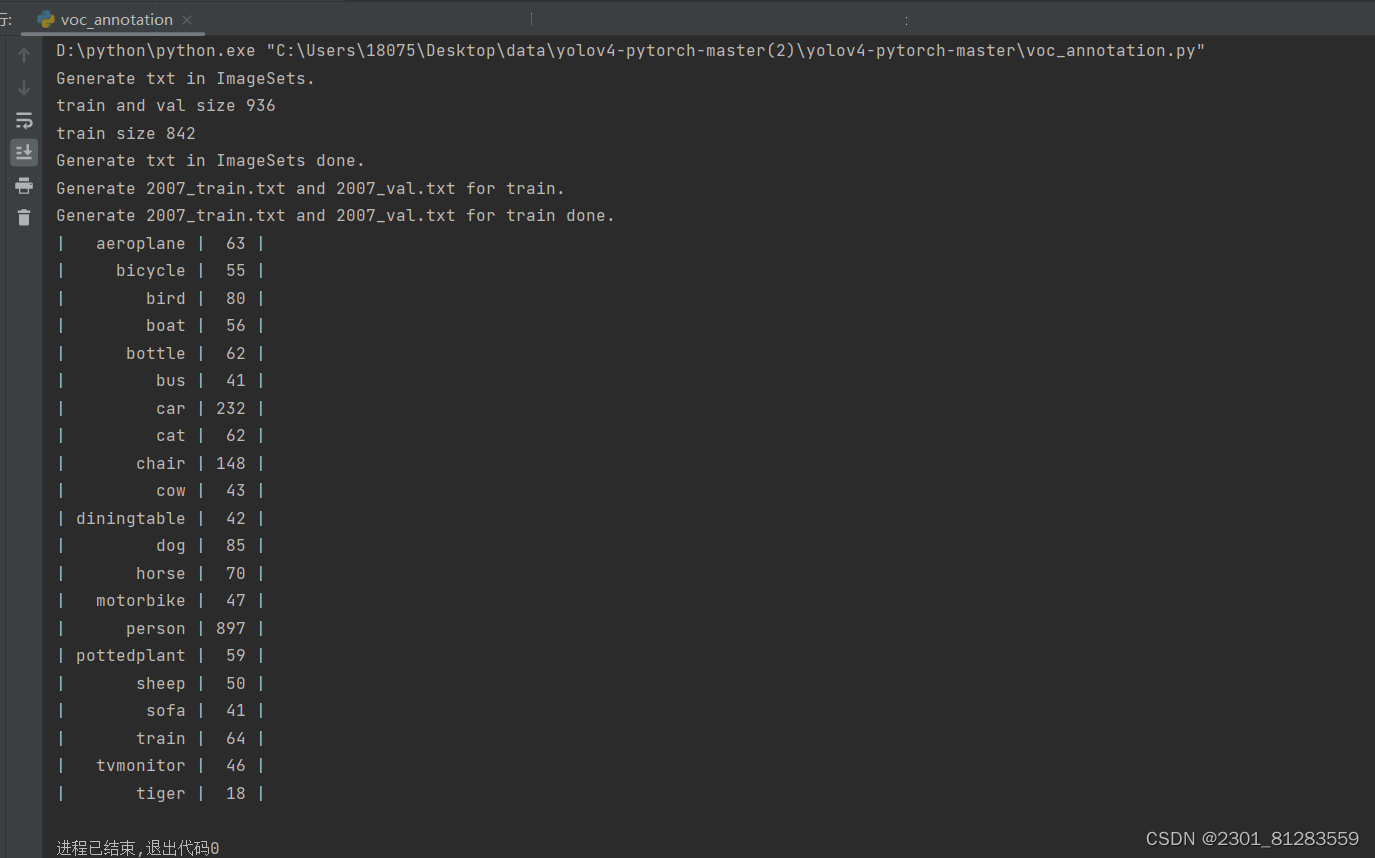
6.运行voc_annotation.py
此程序是读取我们保存在VOCdevkit文件下的图片
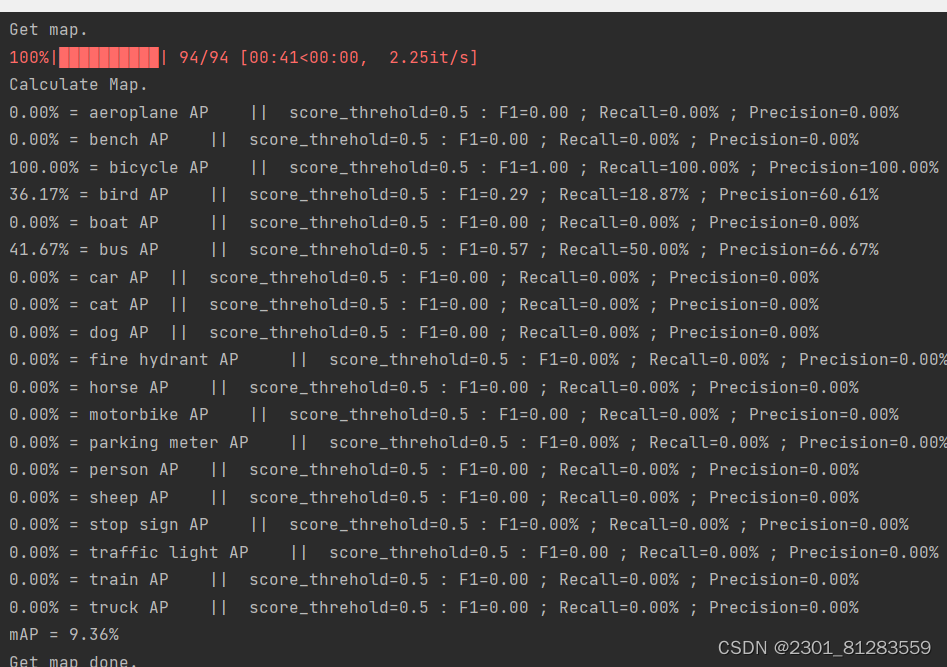
7.运行train.py
对数据集进行训练,训练自己的目标检测模型一定需要注意以下几点:
- 训练前仔细检查自己的格式是否满足要求,该库要求数据集格式为VOC格式,需要准备好的内容有输入图片和标签;输入图片为.jpg图片,无需固定大小,传入训练前会自动进行resize。灰度图会自动转成RGB图片进行训练,无需自己修改。输入图片如果后缀非jpg,需要自己批量转成jpg后再开始训练。标签为.xml格式,文件中会有需要检测的目标信息,标签文件和输入图片文件相对应。
- 损失值的大小用于判断是否收敛,比较重要的是有收敛的趋势,即验证集损失不断下降,如果验证集损失基本上不改变的话,模型基本上就收敛了。 损失值的具体大小并没有什么意义,大和小只在于损失的计算方式,并不是接近于0才好。如果想要让损失好看点,可以直接到对应的损失函数里面除上10000。训练过程中的损失值会保存在logs文件夹下的loss_%Y_%m_%d_%H_%M_%S文件夹中
- 训练好的权值文件保存在logs文件夹中,每个训练世代(Epoch)包含若干训练步长(Step),每个训练步长(Step)进行一次梯度下降。如果只是训练了几个Step是不会保存的,Epoch和Step的概念要捋清楚一下。
8.运行predict.py
predict.py将单张图片预测、摄像头检测、FPS测试和目录遍历检测等功能。
输入图片的地址就能看到检测结果:

总结
YOLO目标检测模型在性能、精度和实时性方面均表现出了较好的表现,具有广泛的应用前景。尽管YOLO模型在目标检测任务中表现出了较好的性能,但仍存在一定的改进空间。首先,在精度方面,可以通过改进模型结构、优化损失函数等方法进一步提高检测精度。其次,在实时性能方面,可以通过优化算法、减少模型参数等方式进一步提高检测速度。此外,还可以考虑将YOLO模型与其他算法进行融合,以充分利用各自的优势,进一步提高目标检测的性能。















 12万+
12万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









