






详细解释如何在自定义数据集上有效地训练目标检测算法 —— YOLOv5
引言
识别图像中的对象被认为是人脑的一项常见任务,但对于机器而言并非如此简单。照片中物体的识别和定位是一项称为“目标检测”的计算机视觉任务,过去几年出现了很多种算法来解决这个问题。迄今为止最流行的实时对象检测算法之一是 YOLO(You Only Look Once),最初由 Redmond 等人提出。
在本教程中,您将学习如何使用 YOLOv5 实现在自定义数据集上执行端到端目标检测项目。我们将使用迁移学习技术来训练我们自己的模型、评估其性能、将其用于推理,甚至将其转换为其他文件格式,例如 ONNX 和 TensorRT。
本教程面向具有目标检测算法理论背景的人员。为了您的方便,下面提供了一份可以快速上手的完整项目代码。
数据处理
数据集创建
对于本教程,我生成了自己的企鹅数据集,方法是手动标记约 250 幅来自网络的企鹅图像和视频帧。为获得稳健的 YOLOv5 模型,建议每类训练超过 1500 张图像,每类训练超过 10,000 个目标。还建议添加最多 10% 的背景图像,以减少误差。由于我的数据集非常小,我将使用迁移学习技术缩短训练时间。
YOLO标注格式
大多数标注平台支持以 YOLO 标签格式导出,为每张图像提供一个标注文本文件。每个文本文件都包含图像中每个对象的边界框 (BBox) 标注。标注数据被归一化为图像大小,并位于 0 到 1 的范围内。它们以以下格式表示:
< object-class-ID> <X center> <Y center> <Box width> <Box height>
如果图像中有两个目标,YOLO 标注文本文件的内容可能如下所示:

数据目录结构
为了符合 Ultralytics 目录结构,数据按以下结构提供:

为了方便起见,我在我的代码中提供了自动创建这些目录的功能,只需将您的数据复制到正确的文件夹中即可。
配置文件
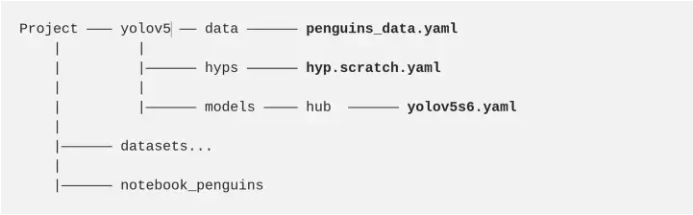
训练的配置分为三个 YAML 文件,这些文件与 repo 本身一起提供。我们将根据任务自定义这些文件,以满足我们的需求。
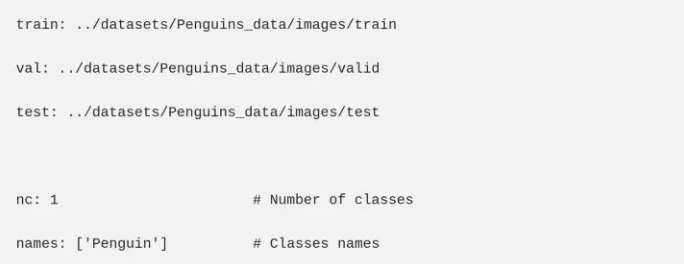
1. 数据配置文件描述了数据集参数。由于我们正在训练我们的自定义企鹅数据集,我们将编辑此文件并提供:训练、验证和测试(可选)数据集的路径;类别数 (nc);以及与其索引相对应的类名。在本教程中,我们只有一个类,名为“Penguin”。我们将自定义数据配置文件命名为“penguin_data.yaml”,并将其放在“data”目录下。这个 YAML 文件的内容如下:
2. 模型配置文件规定了模型架构。 Ultralytics 支持多种 YOLOv5 架构,称为 P5 模型,主要根据参数大小而变化:YOLOv5n (nano)、YOLOv5s (small)、YOLOv5m (medium)、YOLOv5l (large)、YOLOv5x (extra large)。这些架构适用于 640*640 像素的图像大小的训练。除此之外,针对 1280*1280 的更大图像尺寸的训练进行了优化,称为 P6(YOLOv5n6、YOLOv5s6、YOLOv5m6、YOLOv5l6、YOLOv5x6)。P6 模型包括一个额外的输出层,用于检测更大的物体。他们从更高分辨率的训练中获益最多,并产生更好的结果。
Ultralytics 为上述每种架构提供了内置的模型配置文件,这些文件位于“models”目录下。如果您是从头开始训练,请选择具有所需架构的模型配置 YAML 文件(本教程中的“YOLOv5s6.yaml”),然后只需将类数 (nc) 参数修改为您自定义中的正确类别数目即可。

当像本教程中那样从预训练权重初始化训练时,无需编辑模型配置文件,因为模型将加载预训练权重。
3. hyperparameters-configurations 文件定义了训练的超参数,包括学习率、动量、损失、增强等。Ultralytics 在“data/hyp/hyp.scratch.yaml”目录下提供了一个默认的超参数文件。建议使用默认超参数开始训练以建立性能基线,正如我们将在本教程中所做的那样。
YAML 配置文件嵌套在以下目录中:
训练
为了简化本教程,我们将训练小参数模型 YOLOv5s6,但可以使用更大的模型来改善模型效果。不同的情况可能会考虑不同的训练方法,这里我们将介绍最常用的技术。
从零开始训练
当拥有足够大的数据集时,模型将从头开始训练受益最大。通过将空字符串 (' ') 传递给权重参数来随机初始化权重。训练由以下命令引起:
python train.py
--batch 32
--epochs 300
--data 'data/penguins_data.yaml'
--weights ''
--cfg 'models/penguins_yolov5s6.yaml'
--cachebatch — 批量大小(-1 为自动批量大小)。使用硬件允许的最大批量。
epochs — epochs 的数量。
data — 数据配置文件的路径。
cfg — 模型配置文件的路径。
weights — 初始权重的路径。
cache —缓存图像以加快训练速度。
img — 以像素为单位的图像大小(默认 — 640)。
迁移学习
从预训练模型热启动:
由于我的企鹅数据集相对较小(约 250 张图像),因此迁移学习预计会产生比从头开始训练更好的结果。Ultralytic 的默认模型在 COCO 数据集上进行了预训练,但也支持其他预训练模型(VOC、Argoverse、VisDrone、GlobalWheat、xView、Objects365、SKU-110K)。COCO 是一个目标检测数据集,包含来自日常场景的图像。它包含 80 个类,包括相关的“鸟”类,但不包括“企鹅”类。通过将模型名称传递给“weights”参数,我们的模型将使用来自 COCO 模型的预训练权重进行初始化,预训练模型将自动下载。
特征提取
模型由两个主要部分组成:用作特征提取器的骨干网络和计算输出预测的 Head 层。为了进一步弥补较小的数据集带来的短板,我们将使用与预训练 COCO 模型相同的主干网络,并且只训练模型的头部。YOLOv5s6 骨干网络由 12 层组成,将由“冻结”参数固定。
python train.py
--batch 32
--epochs 150
--data 'data/penguins_data.yaml'
--weights 'yolov5s6.pt'
--cache
--freeze 12
--project 'runs_penguins'
--name 'feature_extraction'weights — 初始权重的路径,COCO模型会自动下载。
freeze — 要冻结的层数
project——项目名称
name — 运行的名称
如果提供了“project”和“name”参数,结果会自动保存在那里。否则,它们将保存到“runs/train”目录中。我们可以查看保存到 results.png 文件的指标和损失:
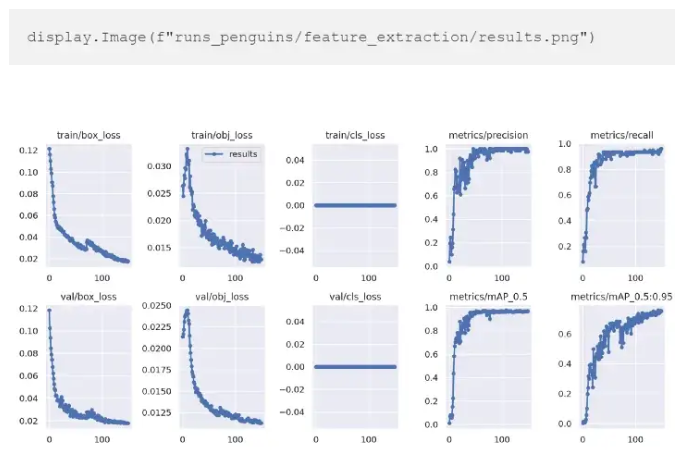
“特征提取”训练的结果
为了更好地理解结果,让我们总结一下 YOLOv5 损失和指标。YOLO损失函数由三部分组成:
box_loss — 边界框回归损失(均方误差)。
obj_loss — 目标存在的置信度损失(二元交叉熵)。
cls_loss — 分类损失(交叉熵)。
由于我们的数据只有一个类别,因此不存在类别错误识别,并且分类错误始终为零。
Precision 用来衡量有多少 bbox 预测是正确的(True positives /(True positives + False positives)),Recall 测量有多少 true bbox 被正确预测(True positives /(True positives + False negatives))。“mAP_0.5”是 IoU(并集交集)阈值为 0.5 时的平均精度(mAP)。‘mAP_0.5:0.95’是不同 IoU 阈值的平均 mAP,范围从 0.5 到 0.95。
微调
训练的最后一个可选步骤是微调,包括 un-freeze 我们上面获得的整个模型,并以非常低的学习率在我们的数据上重新训练它。通过逐步使预训练特征适应新数据,这可能会实现有意义的改进。可以在超参数配置文件中调整学习率参数。对于教程演示,我们将采用内置“hyp.finetune.yaml”文件中定义的超参数,其学习率比默认值小得多。权重将使用上一步中保存的权重进行初始化。
python train.py
--hyp 'hyp.finetune.yaml'
--batch 16
--epochs 100
--data 'data/penguins_data.yaml'
--weights 'runs_penguins/feature_extraction/weights/best.pt'
--project 'runs_penguins'
--name 'fine-tuning'
--cachehyp — 超参数配置文件的路径
正如我们在下面看到的,在微调阶段,指标和损失仍在改善。
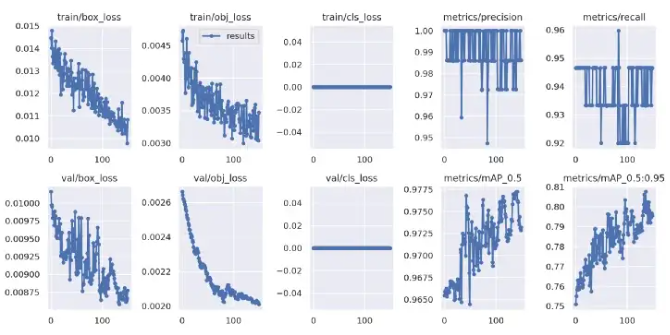
“微调”训练结果
验证
为了评估我们的模型,我们将使用验证脚本。性能可以通过训练、验证或测试数据集拆分进行评估,由“任务”参数控制。评估测试数据集:
python val.py
--batch 64
--data 'data/penguins_data.yaml'
--weights 'runs_penguins/fine-tuning/weights/best.pt'
--task test
--project 'runs_penguins'
--name 'Validation'
--augment我们还可以获得每次验证时自动保存的 Precision-Recall 曲线。
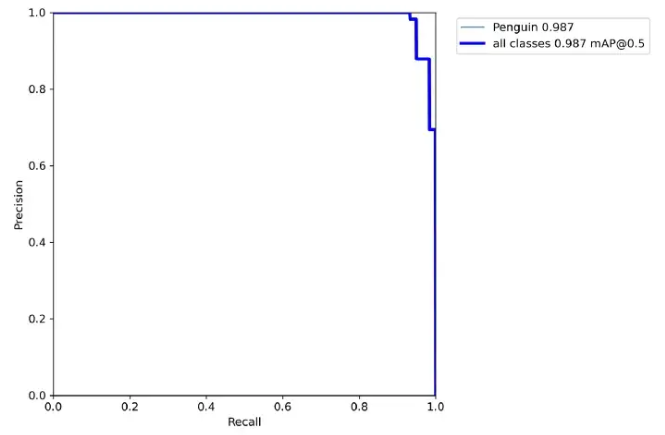
Precision - 测试数据的召回曲线
推理
一旦我们获得了令人满意的训练结果,我们的模型就可以进行推理了。根据推断,我们可以通过应用测试时间增强 (TTA) 进一步提高预测准确性:每个图像都被增强(水平翻转和 3 种不同的分辨率),最终预测是所有这些增强的集合。如果我们严格控制每秒帧数 (FPS),我们将不得不放弃 TTA,因为使用它的推理时间要长 2-3 倍。
推理的输入可以是图像、视频、目录、网络摄像头、流甚至是视频链接。在以下检测命令中,测试数据用于推理。
python detct.py
--source '../datasets/Penguins_data/images/test'
--weights 'runs_penguins/fine-tuning/weights/best.pt'
--conf 0.6
--iou 0.45
--augment
--project 'runs_penguins'
--name 'detect_test'source — 输入路径(0 表示网络摄像头)
weights - 权重路径
img — 用于推理的图像大小,以像素为单位
conf — 置信度阈值
iou - NMS(非最大抑制)的 IoU 阈值
augment — 增强推理 (TTA)
推理结果自动保存到定义的文件夹中。让我们回顾一下测试预测的样本:

推理结果
导出为其他文件格式
至此,我们的模型已经完成,并保存为带有“.pt”文件扩展名的通用 PyTorch 约定文件。该模型也可以导出为其他文件格式,例如 ONNX 和 TensorRT。ONNX 是一种“中间”机器学习文件格式,用于在不同的机器学习框架之间进行转换。TensorRT 是 NVIDIA 开发的用于优化机器学习模型的库,以在 NVIDIA 图形处理单元 (GPU) 上实现更快的推理。
“export.py”脚本用于通过将类型格式应用于“include”参数,将 PyTorch 模型转换为 ONNX、TensorRT 或其他格式。以下命令用于将我们训练的企鹅模型导出到 ONNX 和 TensorRT。这些新文件格式保存在与 PyTorch 模型相同的“weights”文件夹下。
python export.py
--weights 'runs_penguins/Transfer_learning/weights/best.pt'
--include engine onnx
--data 'data/penguins_data.yaml'
--device 0
--imgsz 640 640
· END ·
HAPPY LIFE















 1417
1417











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









