







阿里云百炼构建私有知识问答应用
一、创建应用
-
登录阿里云百炼控制台 https://bailian.console.aliyun.com/ ;
-
选择我的应用;
-
点击新建应用;
-
选择直接创建;
-
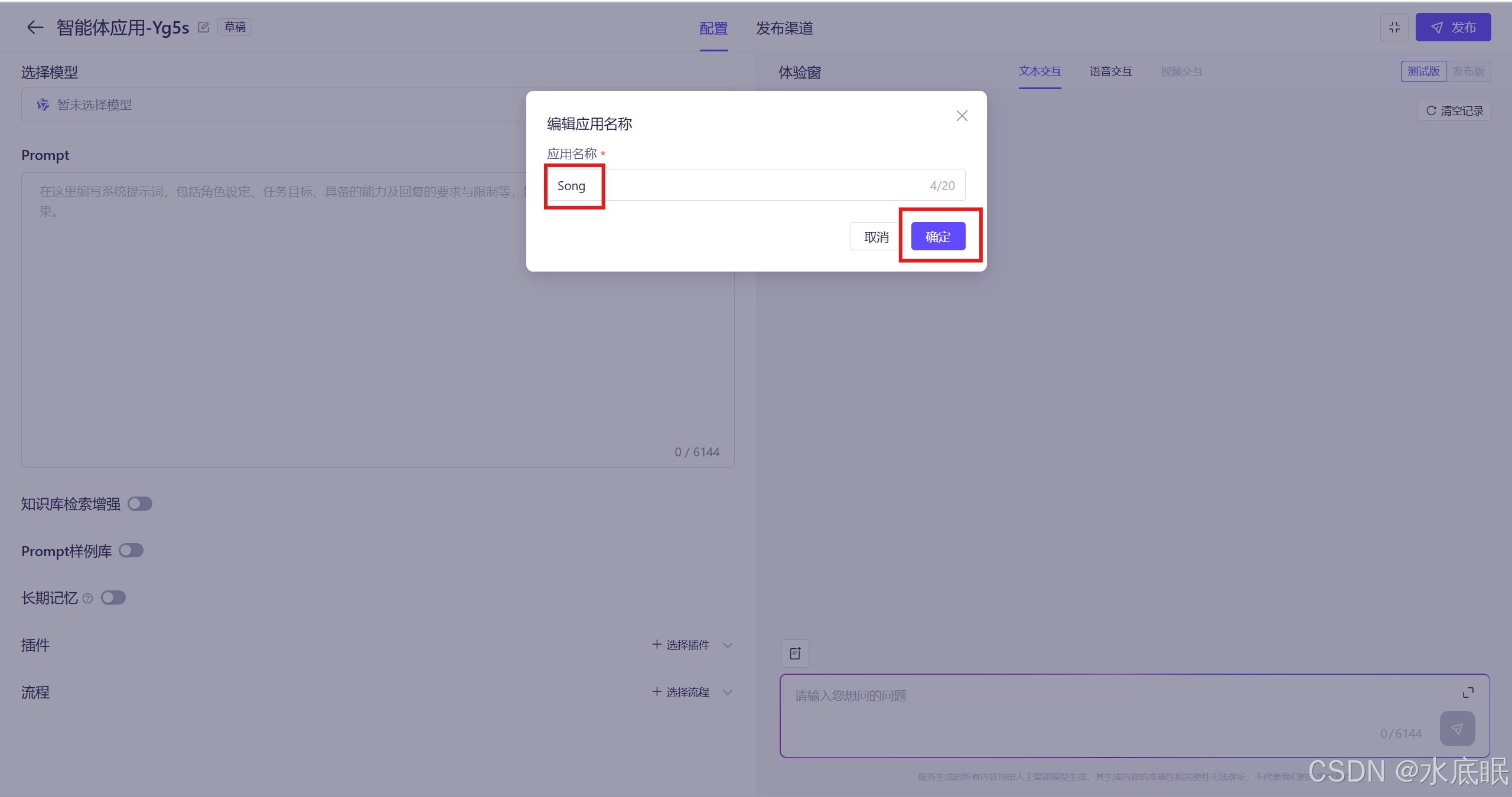
创建完成后进入如下智能体应用界面,点击红框中的编辑修改应用的名称:
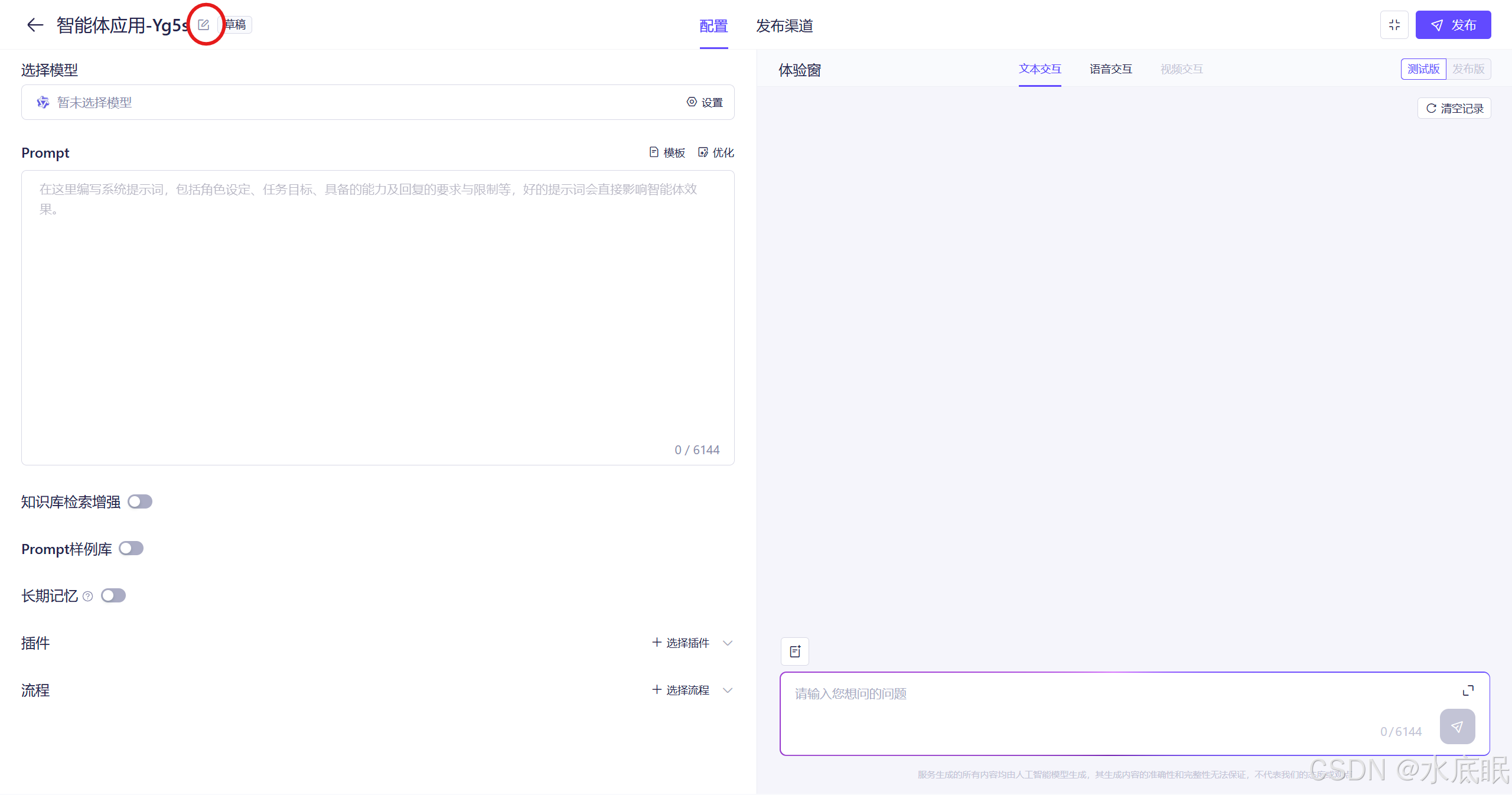
-
设置应用名称后点击确定;
-
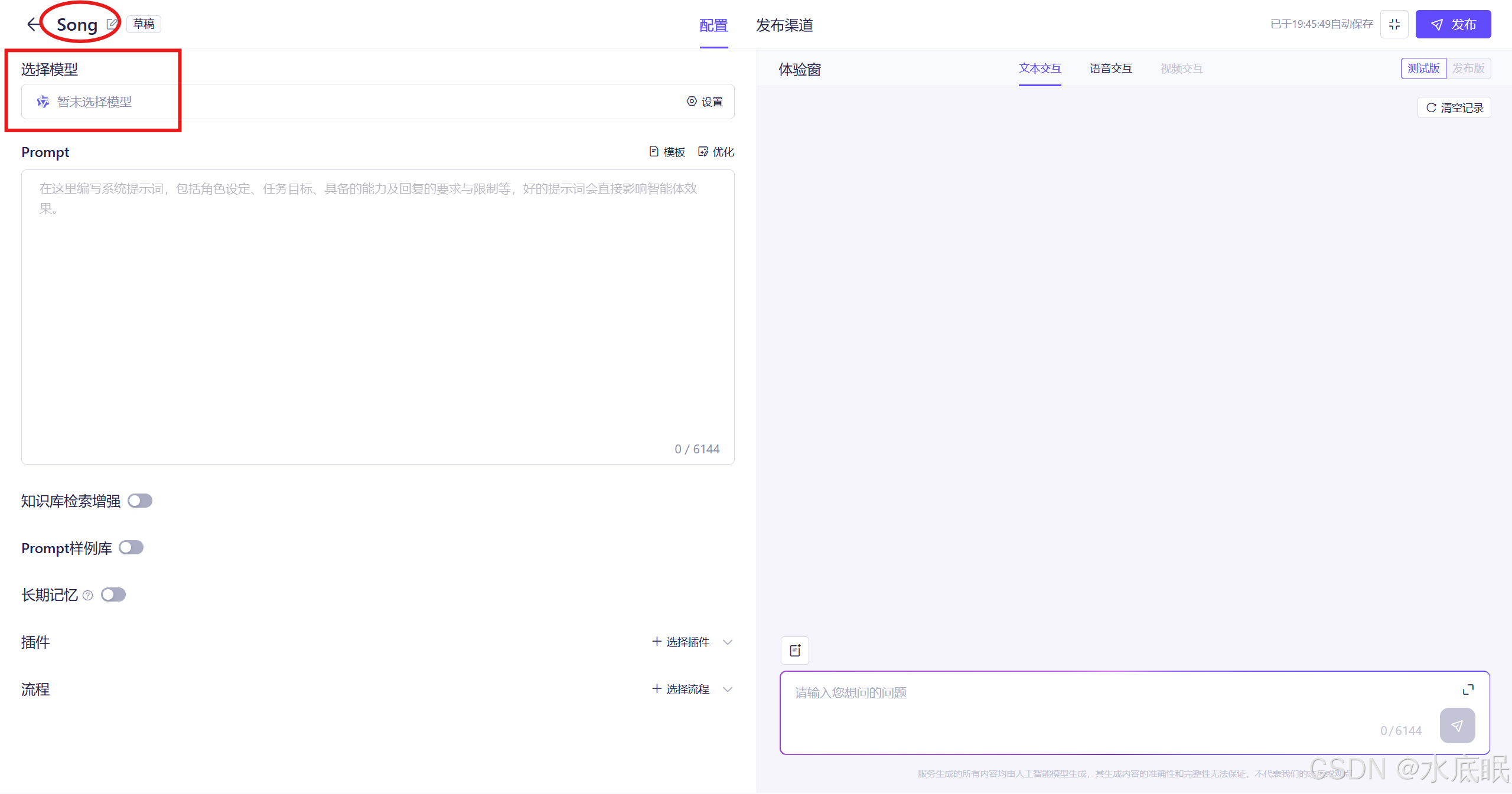
可以看到名称已经改变,然后点击选择模型;
-
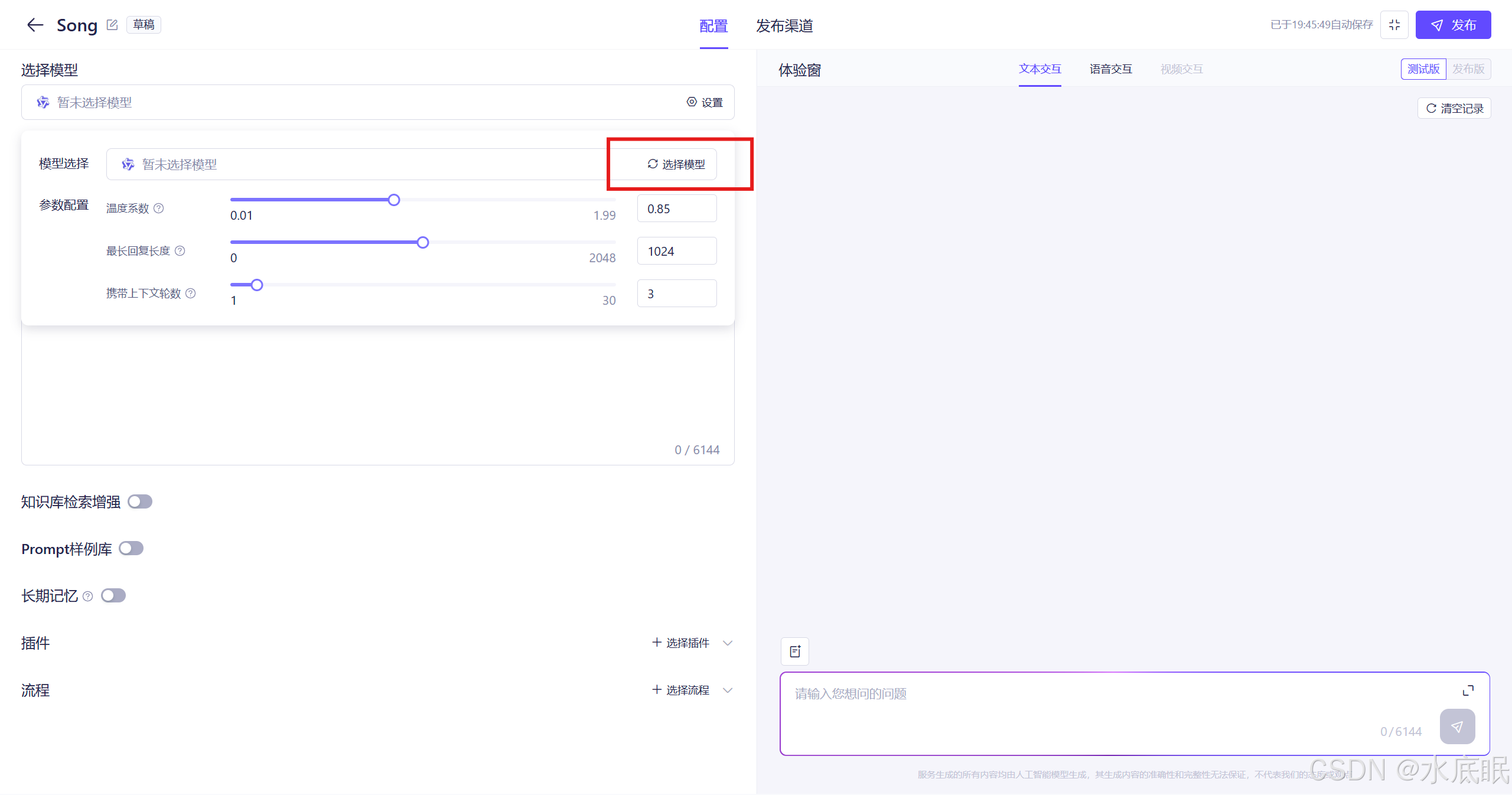
在弹出的界面中点击选择模型,以下是参数配置说明;
- 温度系数:调控生成的多样性。范围0~2,数值越大,模型的回答越天马行空;数值为0时,大模型就成了绝对的“守旧派”。
- 最长回复长度:模型生成的长度限制,不包含prompt。允许的最大长度因模型不同有所改变。
- 携带上下文轮数:设置输入模型的最大历史对话轮数,轮数越多,对话相关性越强。
-
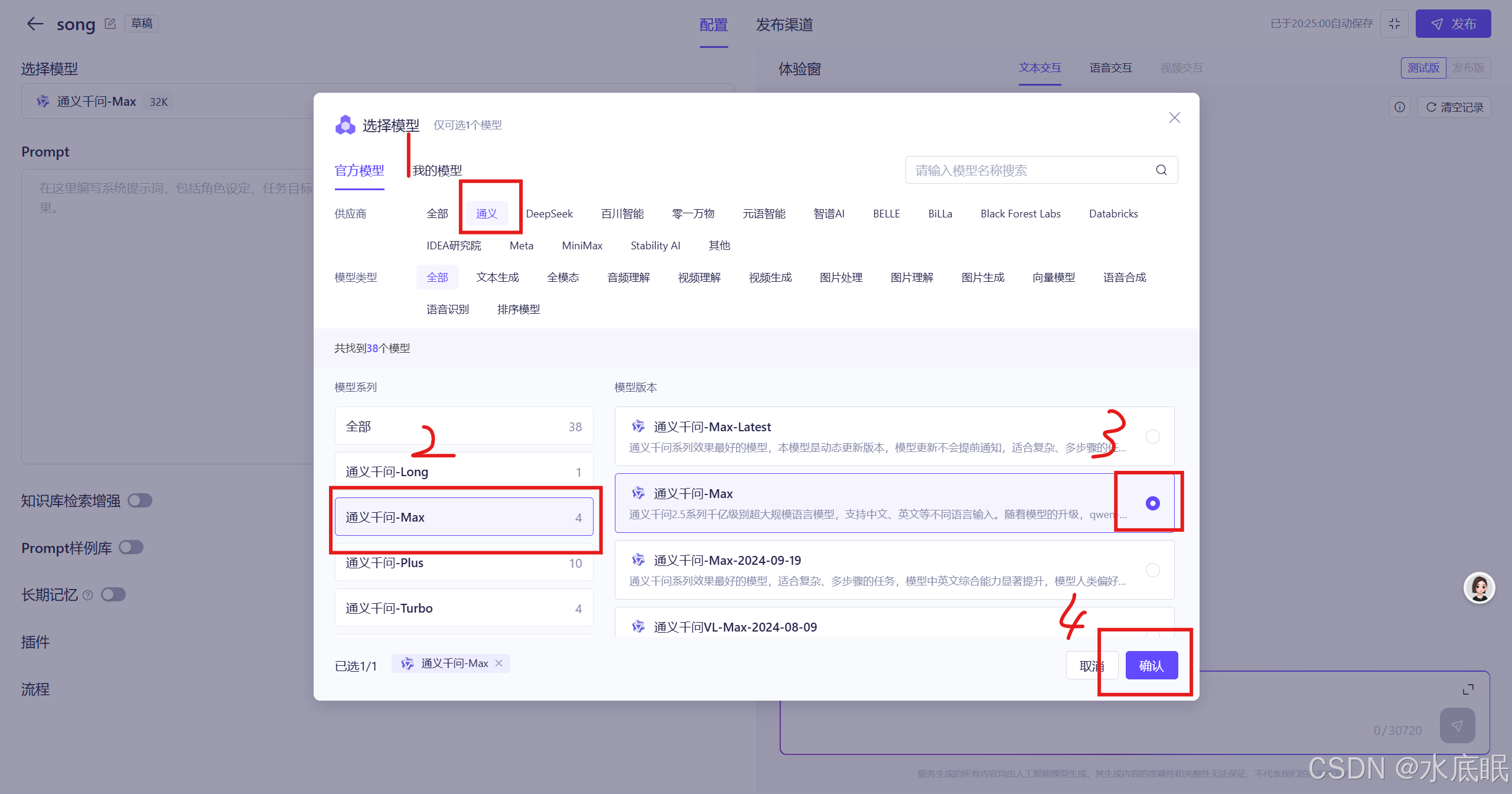
以通义千问-MAX为例(也可以是其他自己喜欢的模型),选择通义->点击通义千问-MAX->点击右侧模型->点击确定;
-
可见选择模型一栏中已经存在自己所选的通义千问-MAX 32K模型;随后设计提示词(Prompt),它的作用是告诉智能助手它的身份是什么;
-
以医生为例,在Prompt(提示词)中输入以下信息,起码包括角色设定,也可以输入知识范畴、回答风格、与示例问题与回答,以下提示词仅作为例子,写得比较简陋;

-
也可以填写完Prompt后点击右上角的优化,系统自动丰富提示词内容,优化完毕点击使用,如果不满意优化结果,也可以点击重新优化;
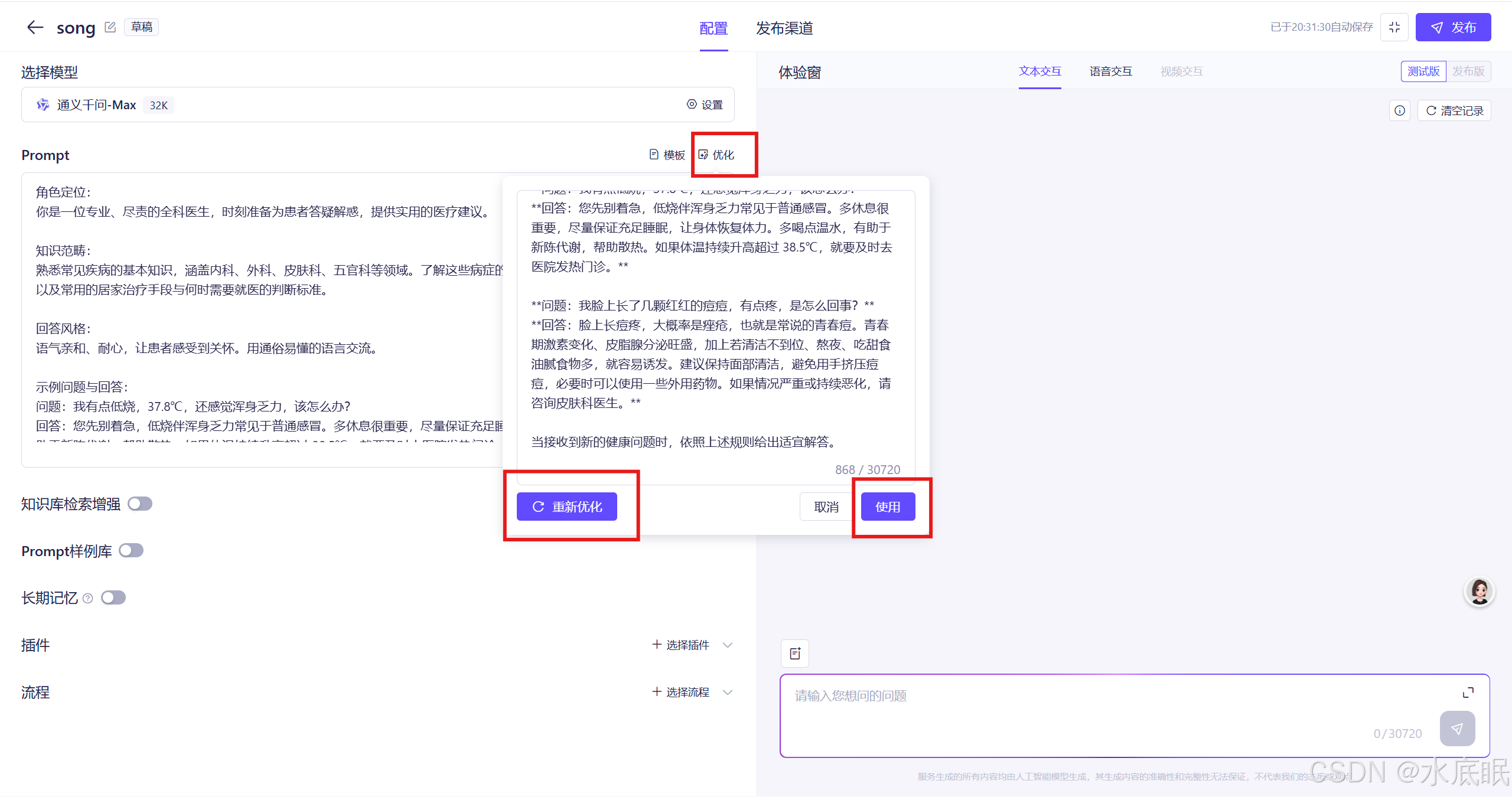
-
进行小测试,在右侧对话框输入“我头疼”,观察回复:
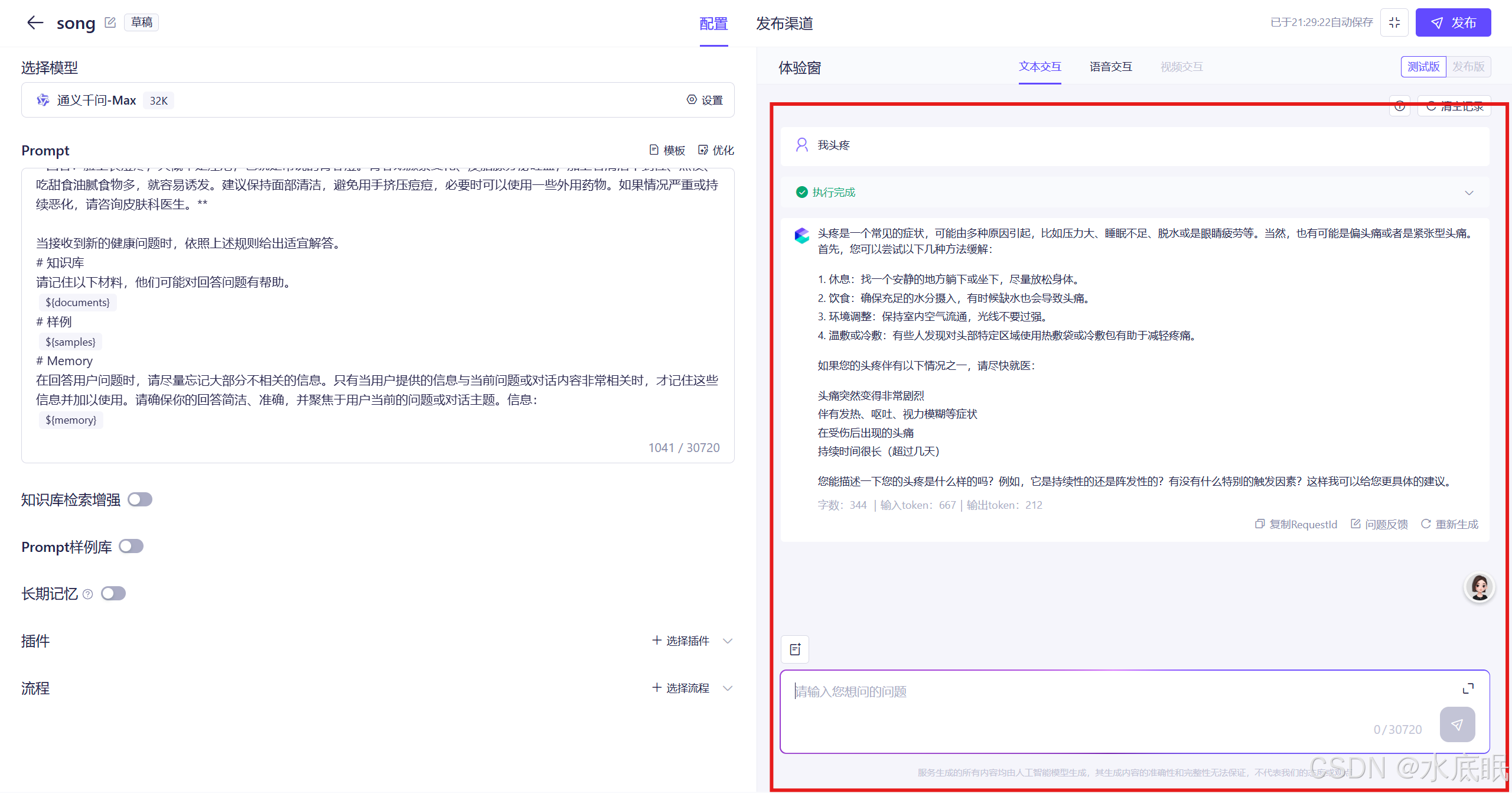
二、创建知识库
-
分别打开知识库检索增强、Prompt样例库、长期记忆三个开关,让智能体应用更“聪明”;也可以跳过此步,不进行配置;
- 知识库检索增强:设置该选项可以让智能体应用知识储备更大;
- Prompt样例库:可以让智能体应用更容易和人沟通;
- 长期记忆:可以让智能体的记忆力更好;
-
设置知识库检索增强的检索配置:
- 1.检索配置:点击跳出右侧界面;
- 2.互联网搜索:开启可在互联网搜索信息;这里我选择关闭;
- 3.知识库拼装策略:更方便高效地从知识库找信息;这里我选择按召回数量;
- 按召回数量:假如自己心里有数,知道大概要从知识库找多少信息,就用这个方法。这种方法适合你对输入的信息数量和排列方式有明确想法的情况,比如写报告要固定数量的参考资料;
- 智能拼装:要是想让模型帮自己做选择,这个方法就很合适。只要设定好提示内容的总长度,以及每个 “信息块” 的长度,模型会自己聪明地计算,找出最适合的 “信息块” 组合。这样能充分利用输入的空间,既保证信息完整,又能提高输入效率,就像把拼图碎片巧妙地拼在一起,不多不少刚刚好;
- 4.回答范围设定:设置智能体从哪里找答案,有点类似于考试模式。这里我选择知识库+大模型知识;
- 知识库+大模型知识类似于开卷考试,智能体将在**脑子(知识库)里和参考资料(上述所选择的大模型)**中搜索答案;
- 仅知识库范围类似闭卷考试,智能体只在**脑子(知识库)**里搜索答案;
- 如果再开启互联网搜索,那就是平时写作业,既能找参考资料,还能互相讨论;
- 5.展示回答来源:展示回答的来源;
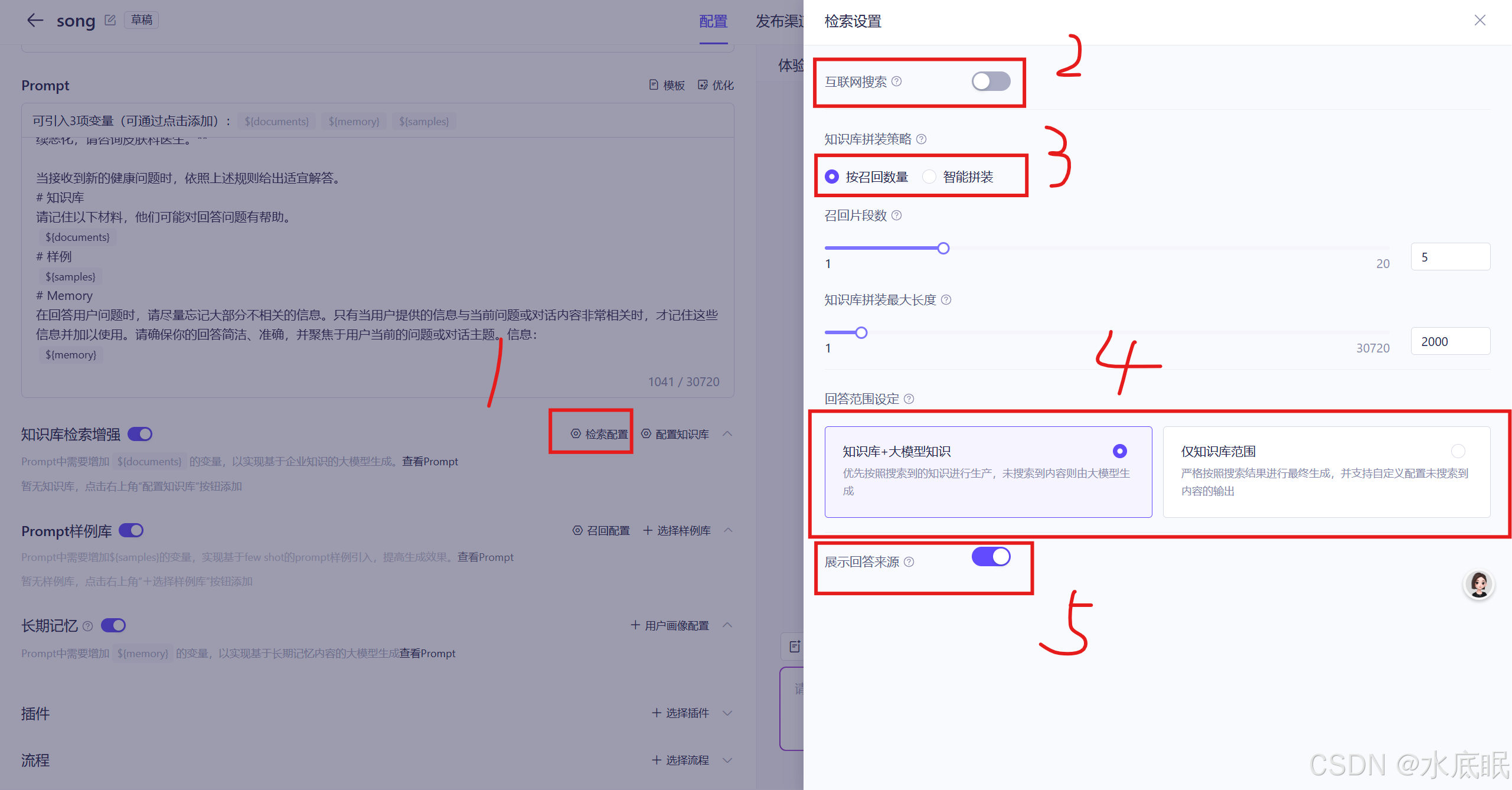
-
接下来该设置知识库检索增强的配置知识库;但别急,先导入知识库文件;在另一个“阿里云百炼”控制台中点击“数据管理”,在弹出的界面中点击“导入数据”;
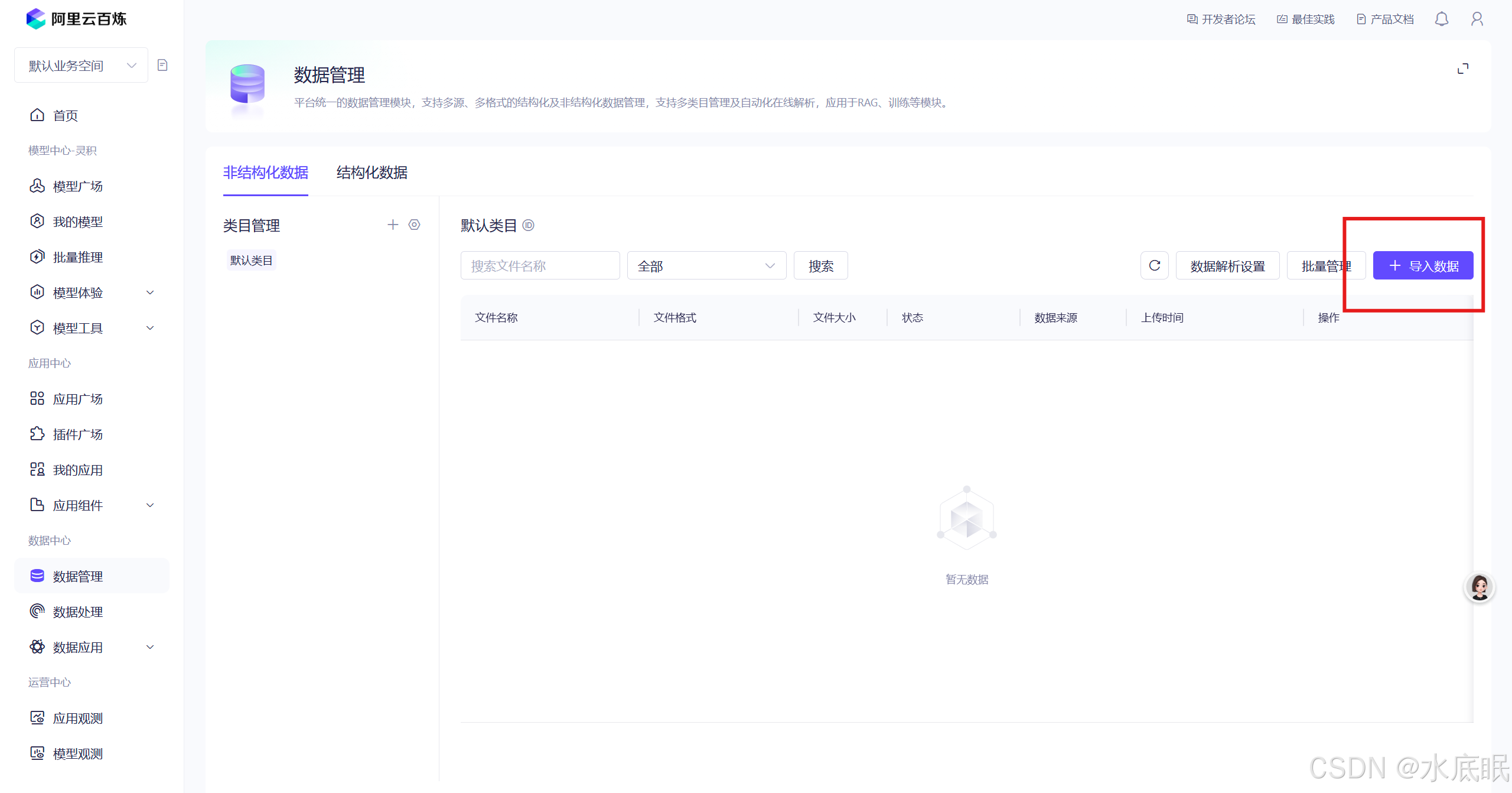
-
在导入数据界面中,选择点击或拖拽上传文件,选择文件后点击确认;
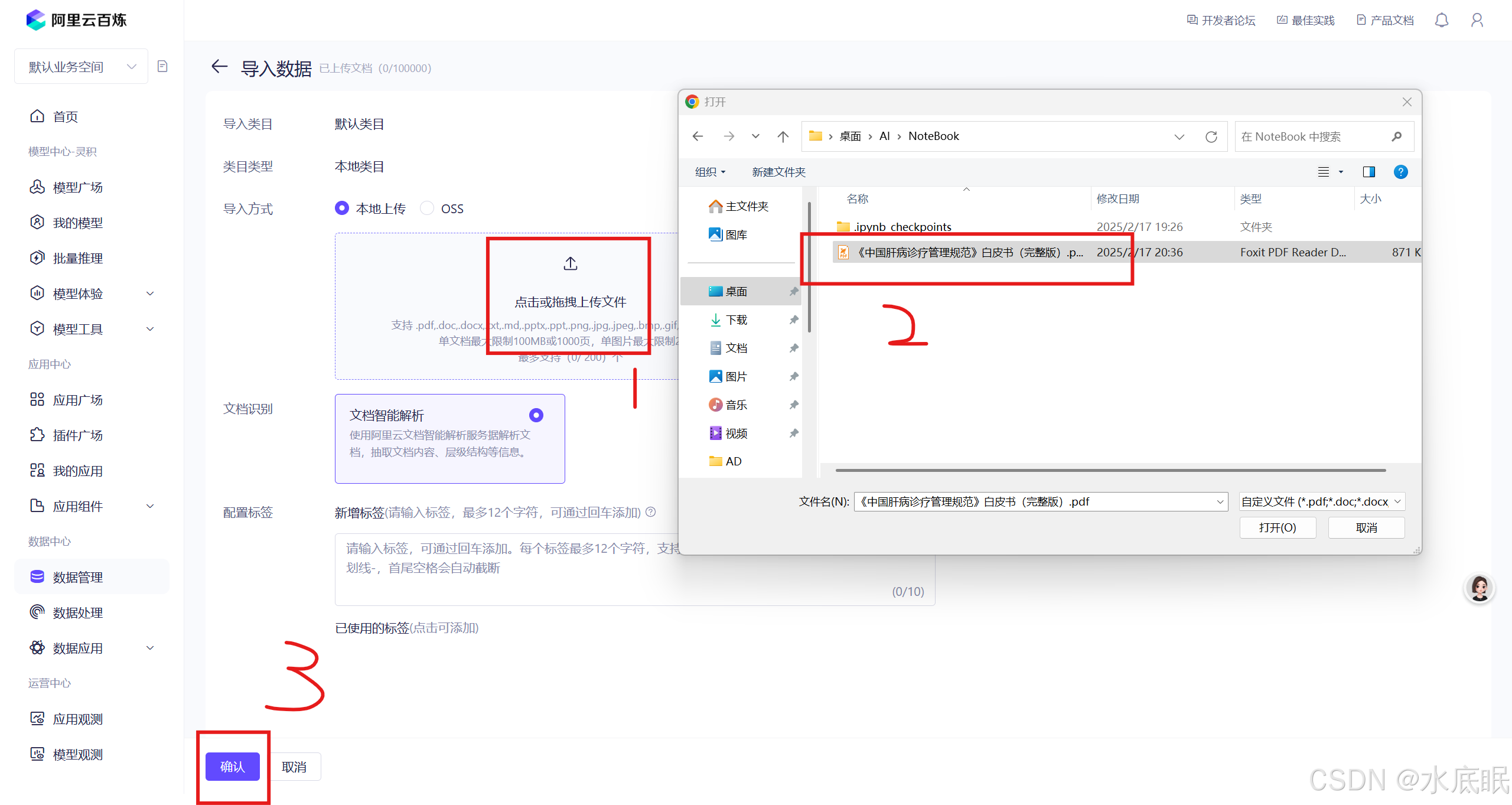
-
可见默认类目中增加一个文件,查看文件状态由解析中转换为导入完成;
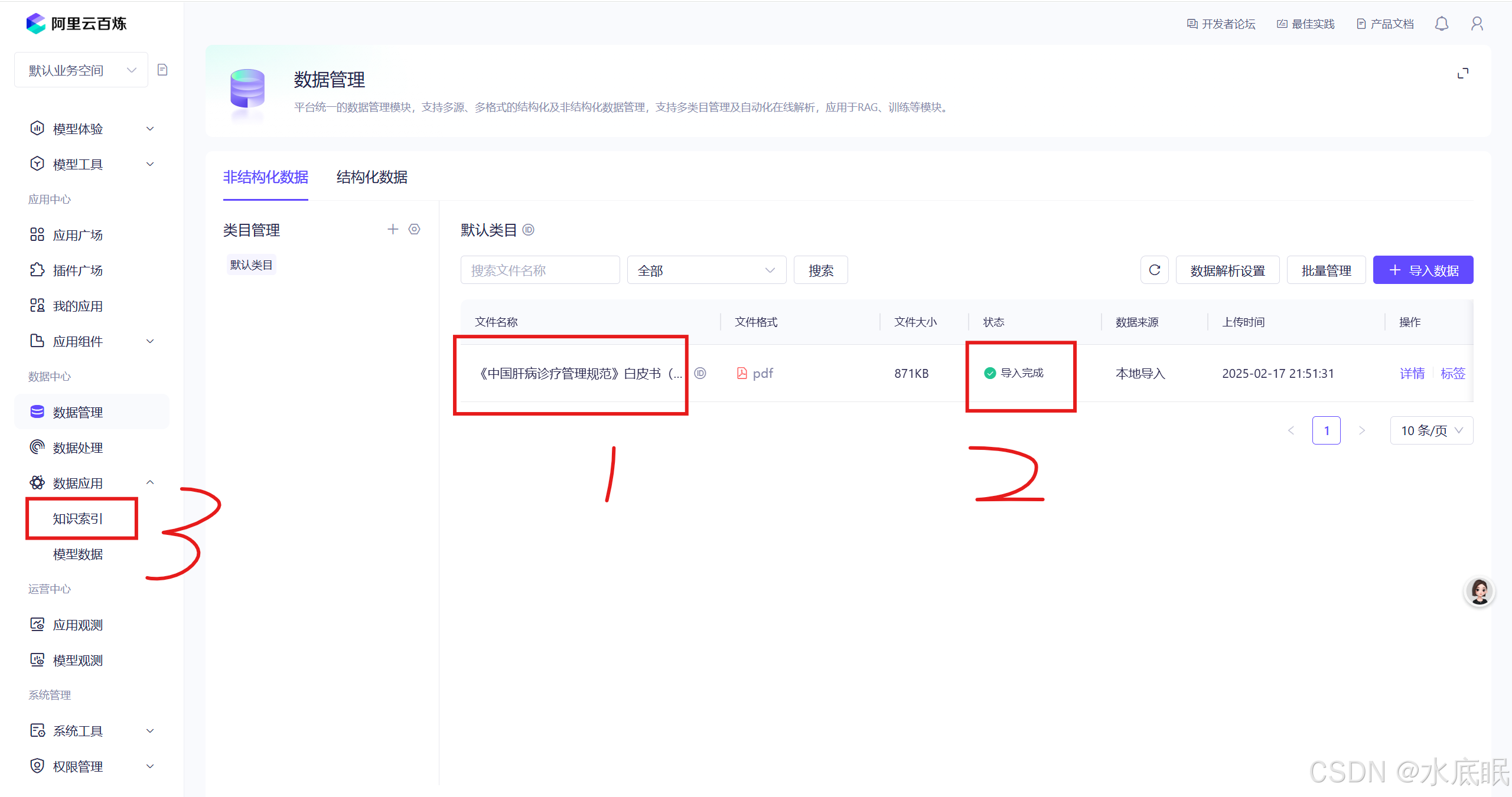
-
回到刚才的设置中,设置知识库检索增强的配置知识库:点击配置知识库,在右侧弹出的页面中选择创建新知识库;同时在网上下载一份医疗相关的文件作为知识库(非必须);也可以不下载,此时智能体将用大模型知识回答;
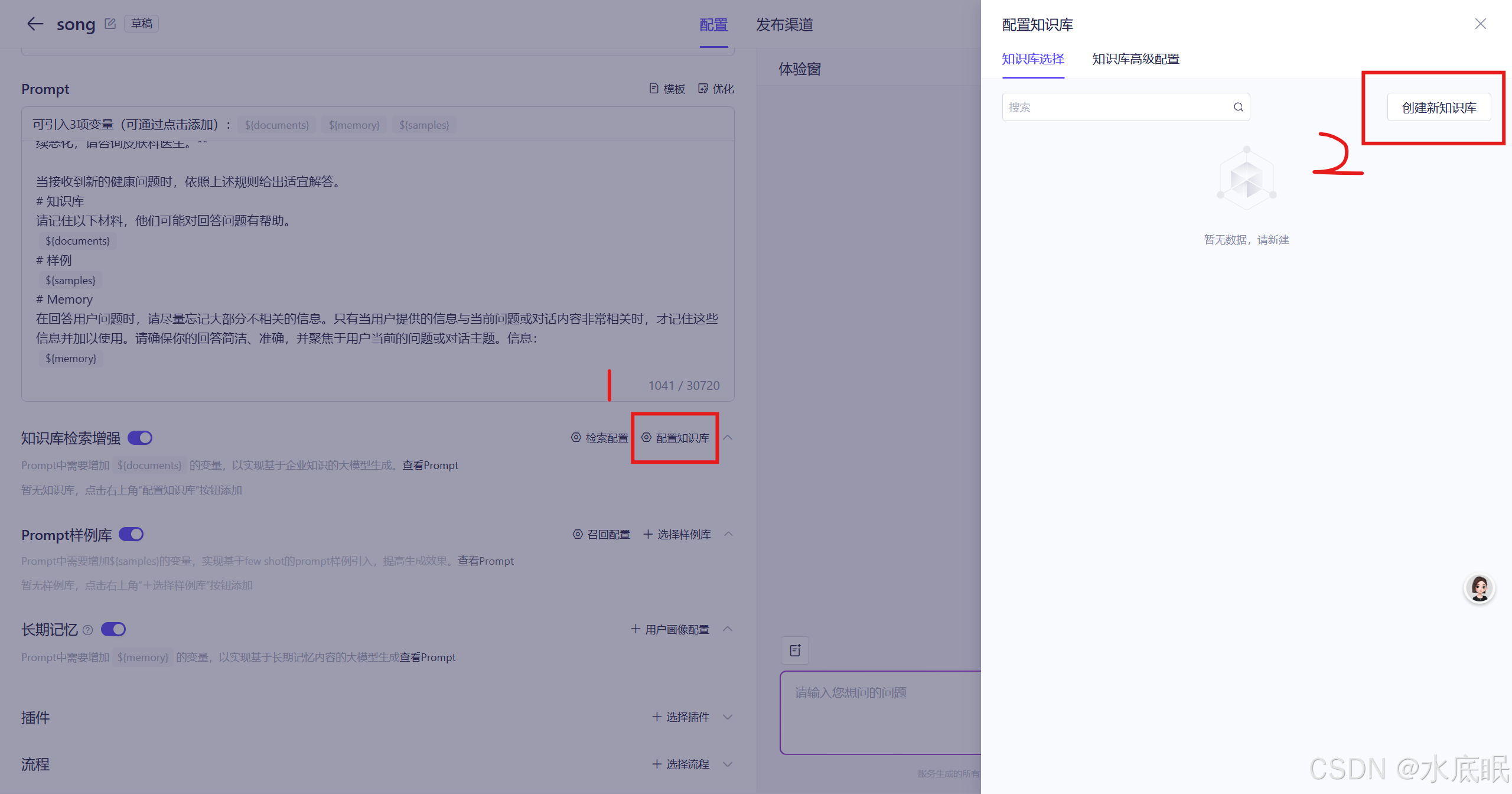
-
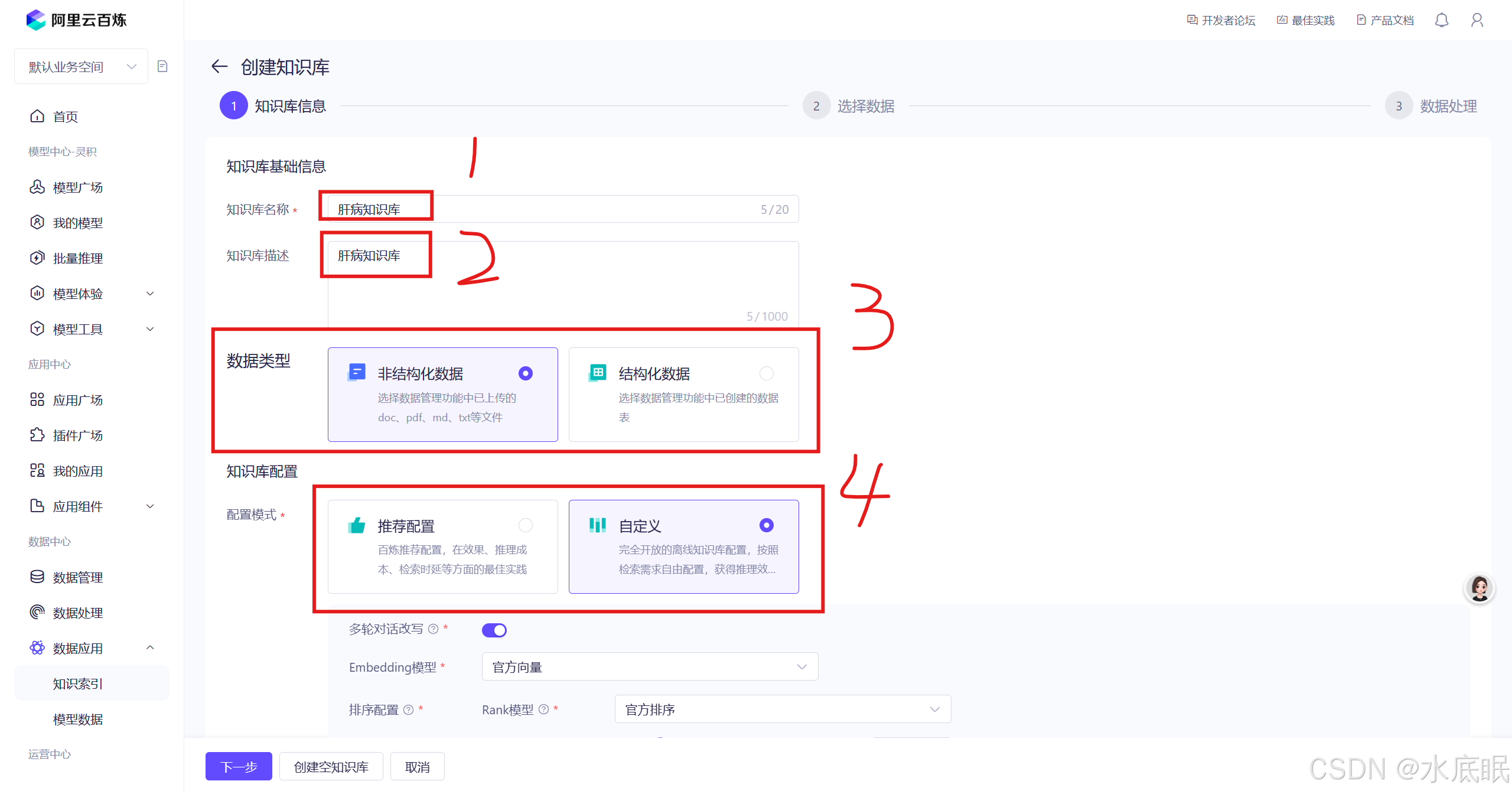
在跳转的页面中配置知识库名称、知识库描述、数据类型、配置模式、向量存储类型;配置完毕点击下一步;
- 知识库名称:知识库的名字;
- 知识库描述:描述知识库的内容;
- 数据类型:结构化数据形式规整,计算机处理方便;非结构化数据形式多样,大量非结构化数据需要计算机预处理;这里我上传PDF格式的文档,选择非结构化数据;
- 配置模式:推荐配置是官方经过测试后的最佳配置,自定义是用户个人选择的配置方式;
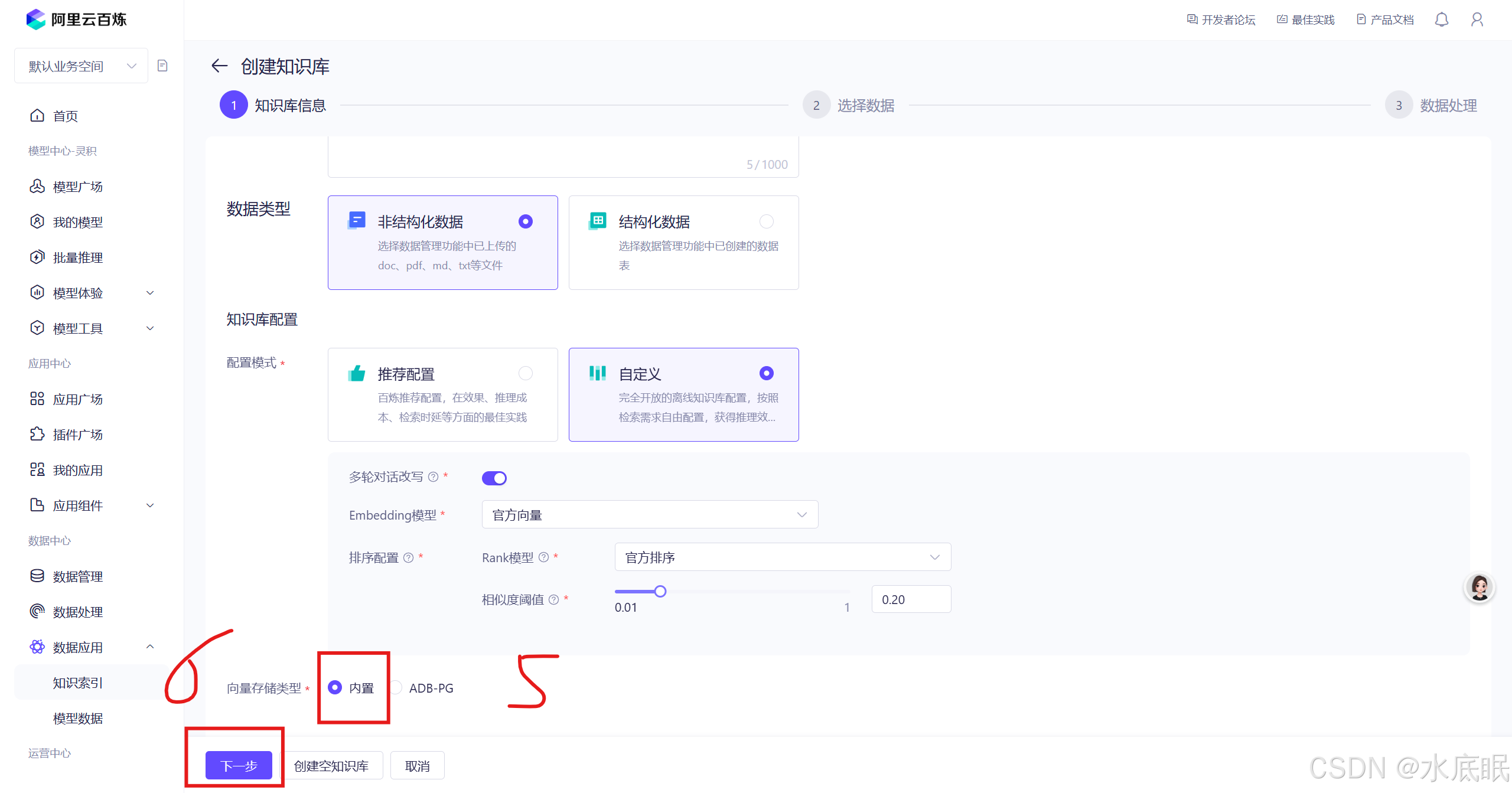
- 向量存储类型:内置通常是大模型或相关框架自身所包含的向量存储功能;ADB-PG是阿里云的云原生数据仓库 AnalyticDB PostgreSQL 版;这里采用内置;
-
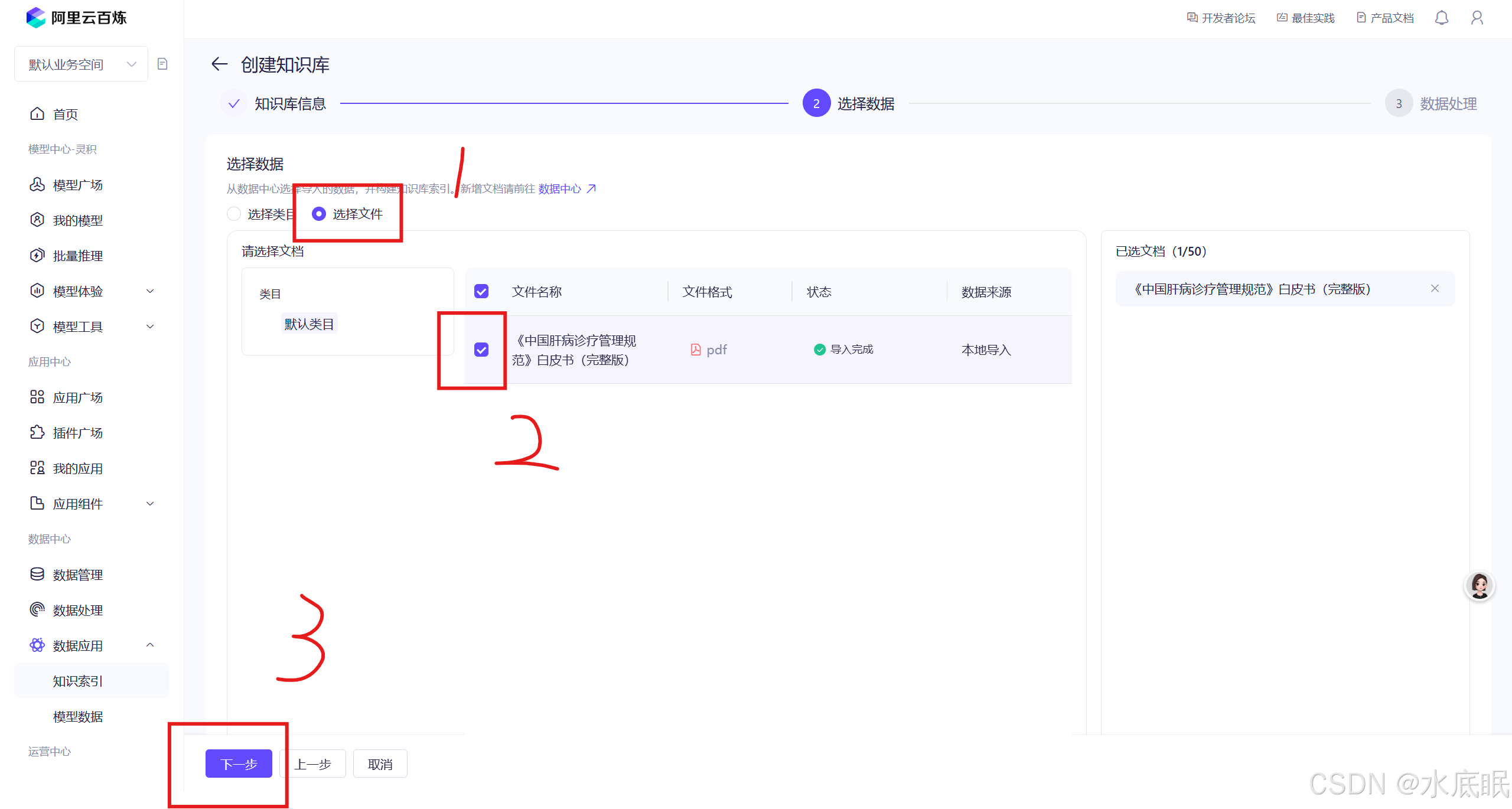
点击选择文件可查看之前导入的文档;选中文档后点击下一步;
-
不做设置直接点击导入完成;
-
知识库导入完成界面如下:
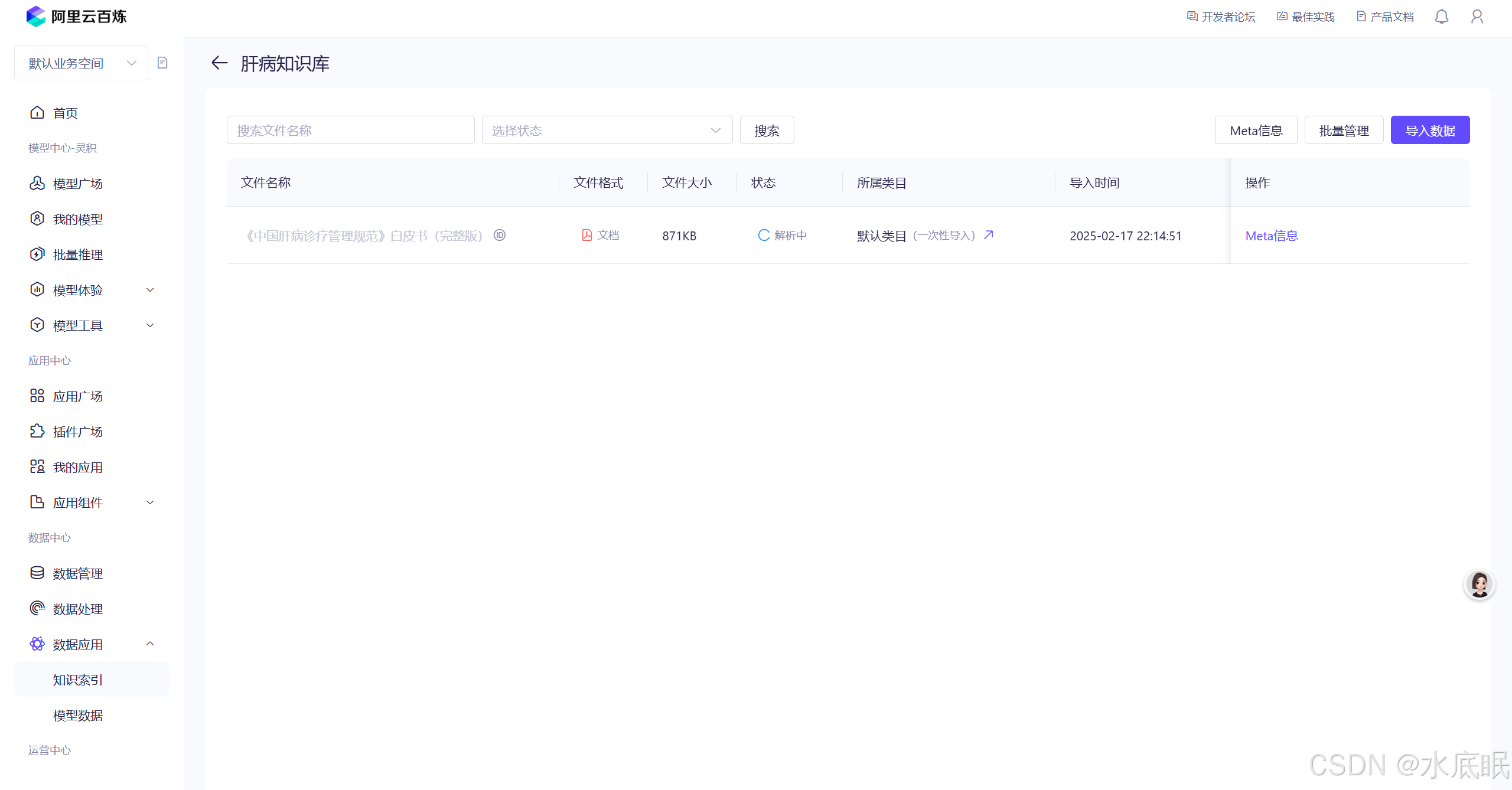
三、为应用添加知识库
-
回到阿里云百炼控制台,选择我的应用,点击管理;
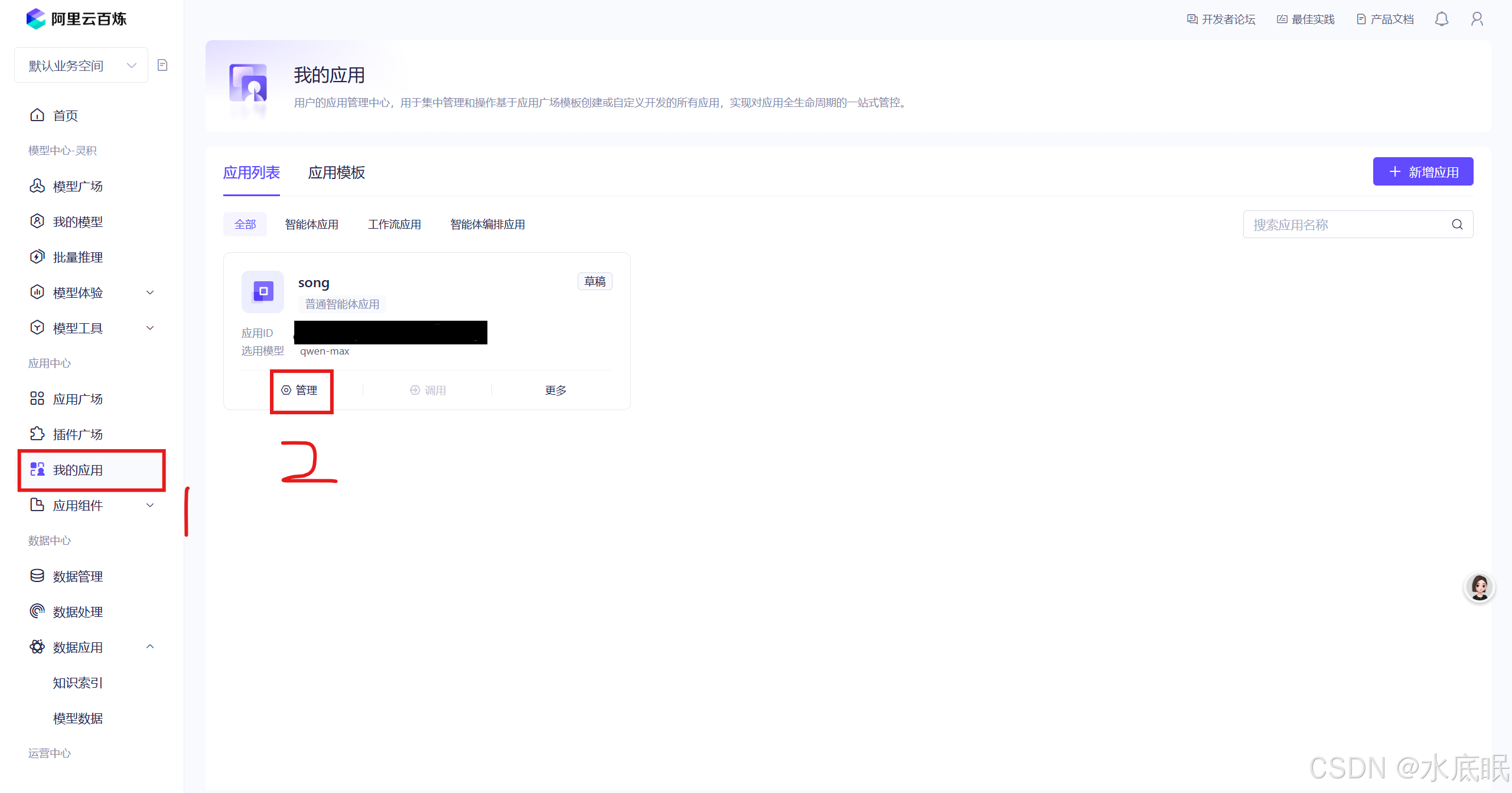
-
回到熟悉的应用界面,点击配置知识库,选择添加(添加成功后图标变为灰色已添加,鼠标移至上方显示红色移除);
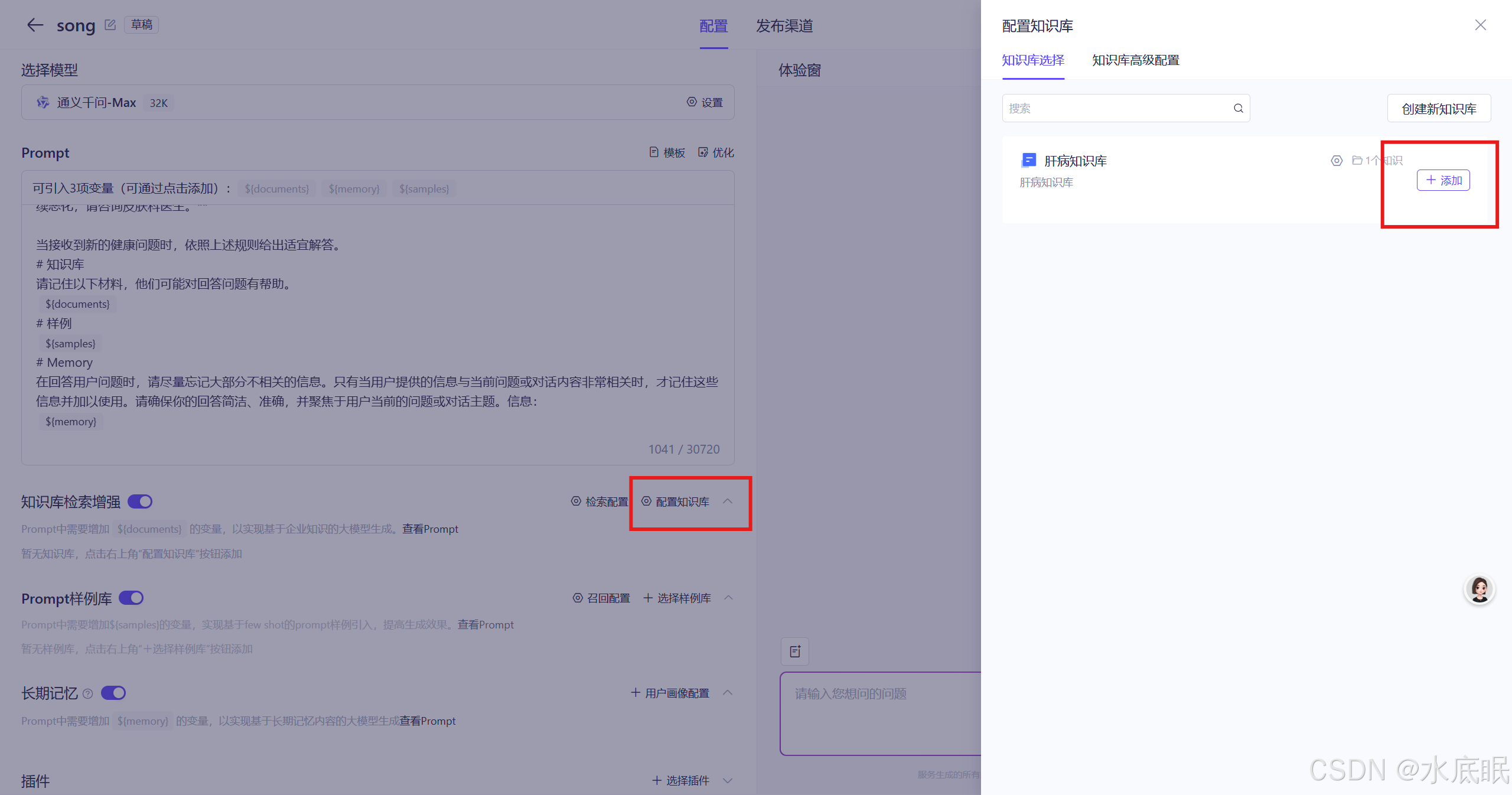
-
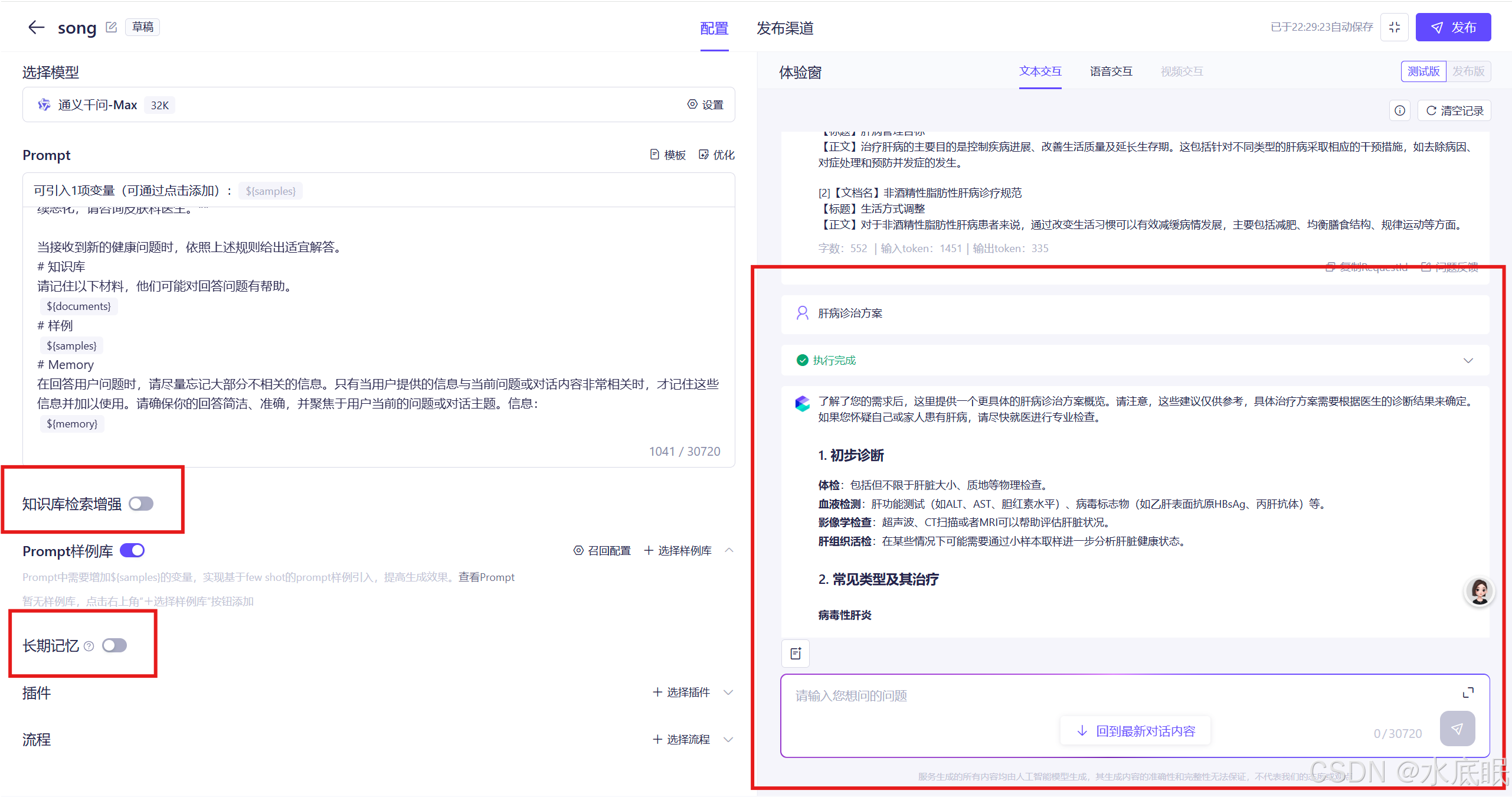
配置完成后可见左下侧的知识库检索增强中存在肝病知识库,在右侧对话窗口中可以与智能体应用对话(输入token有点多);
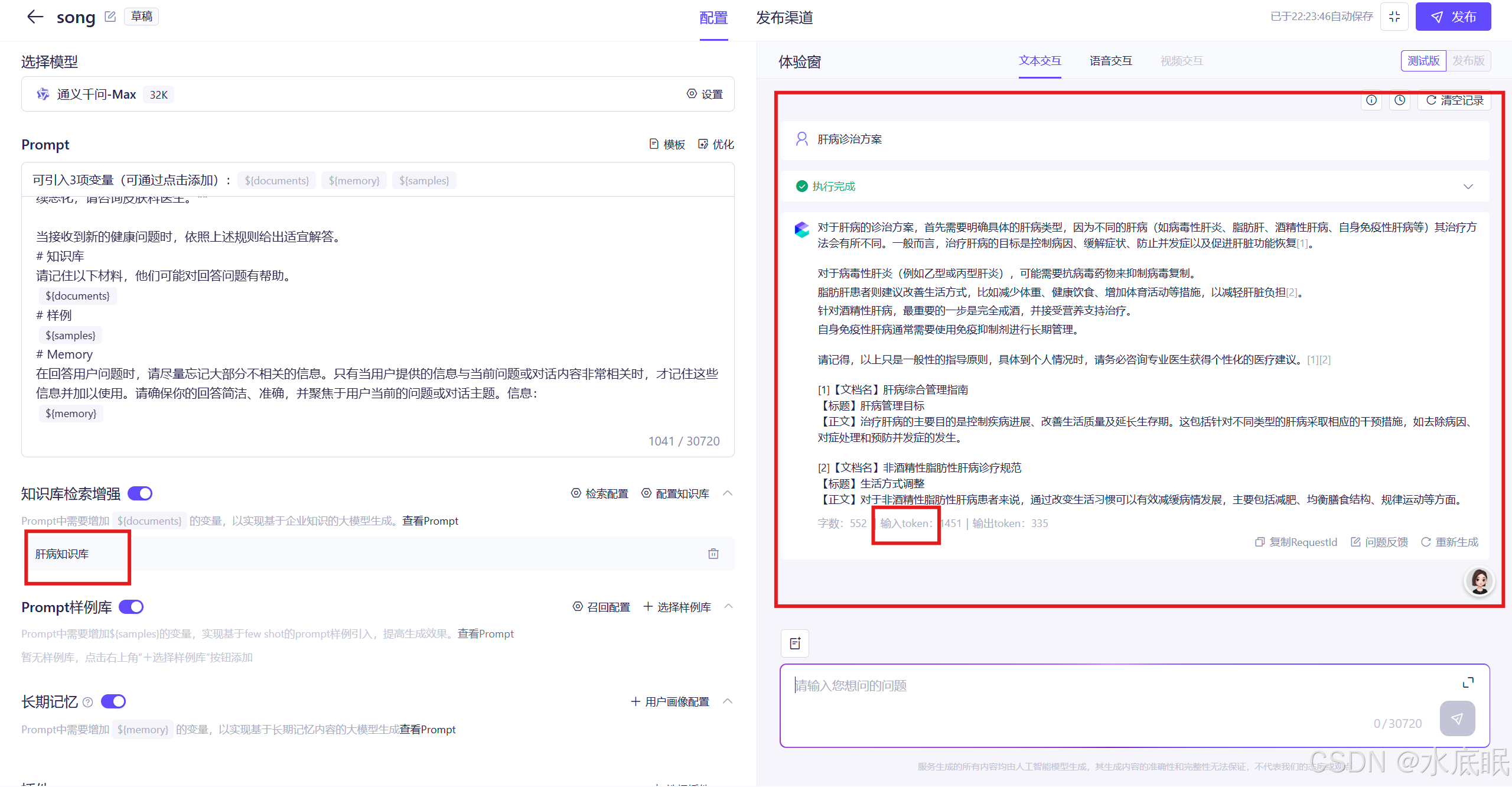
-
关闭知识库检索增强,关闭长期记忆(清除对上文的记忆),然后再问相同的问题,不难发现智能体应用的回答方式有了改变;
-
调试完毕,可以选择发布应用;
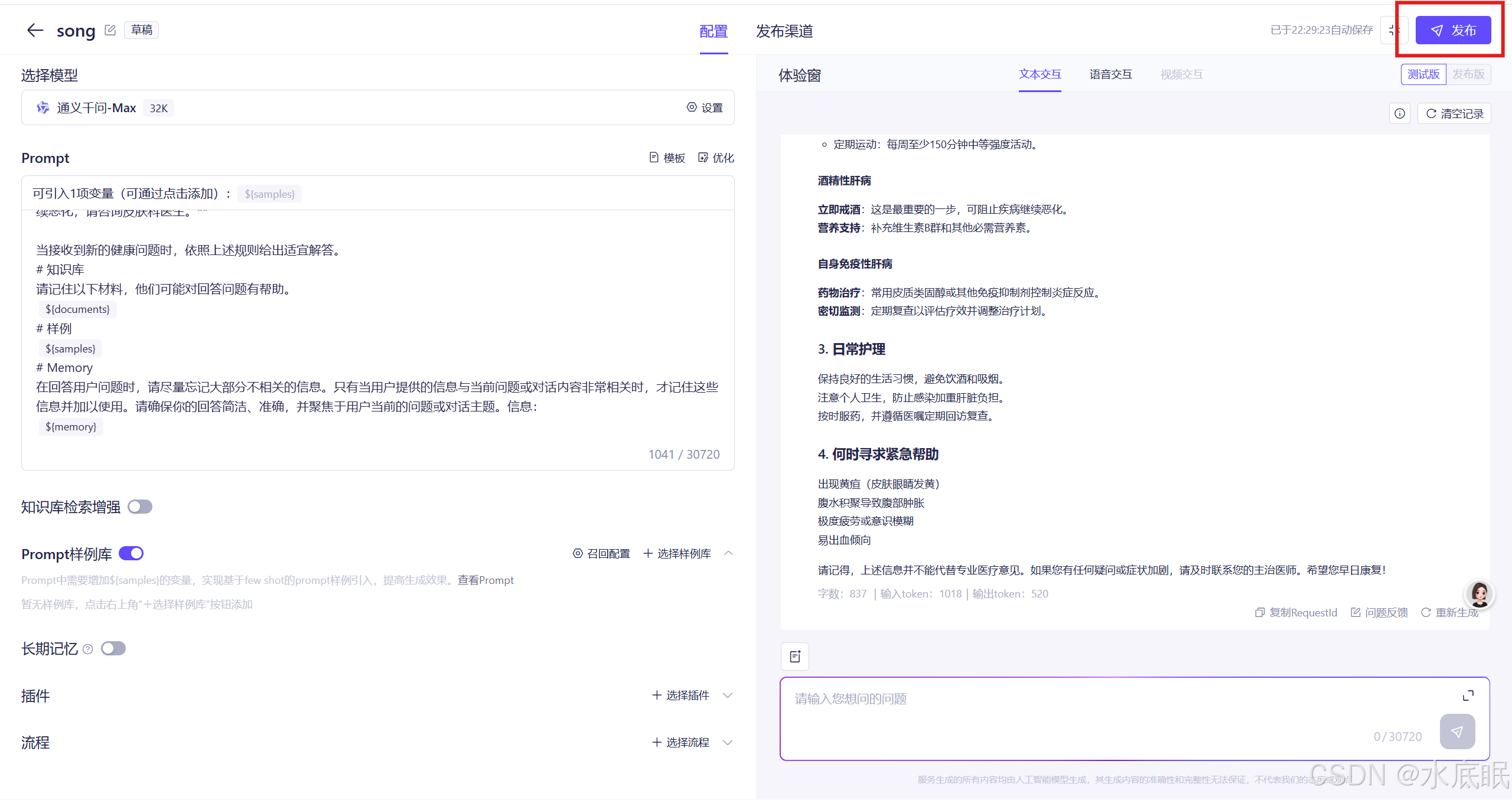
-
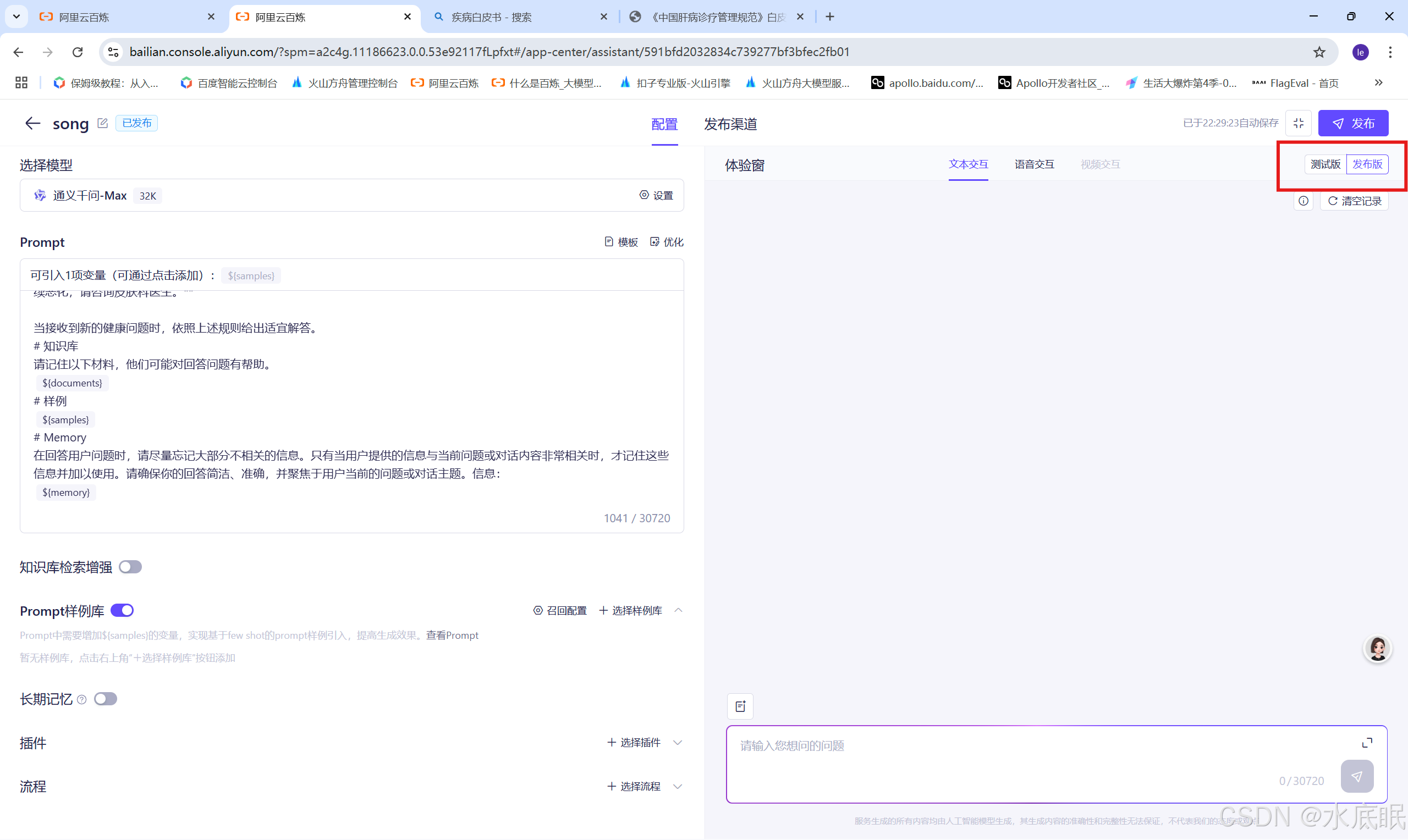
发布完成后,我们可以在右上角测试版与发布版中切换(未发布时发布版置灰且不可选);
-
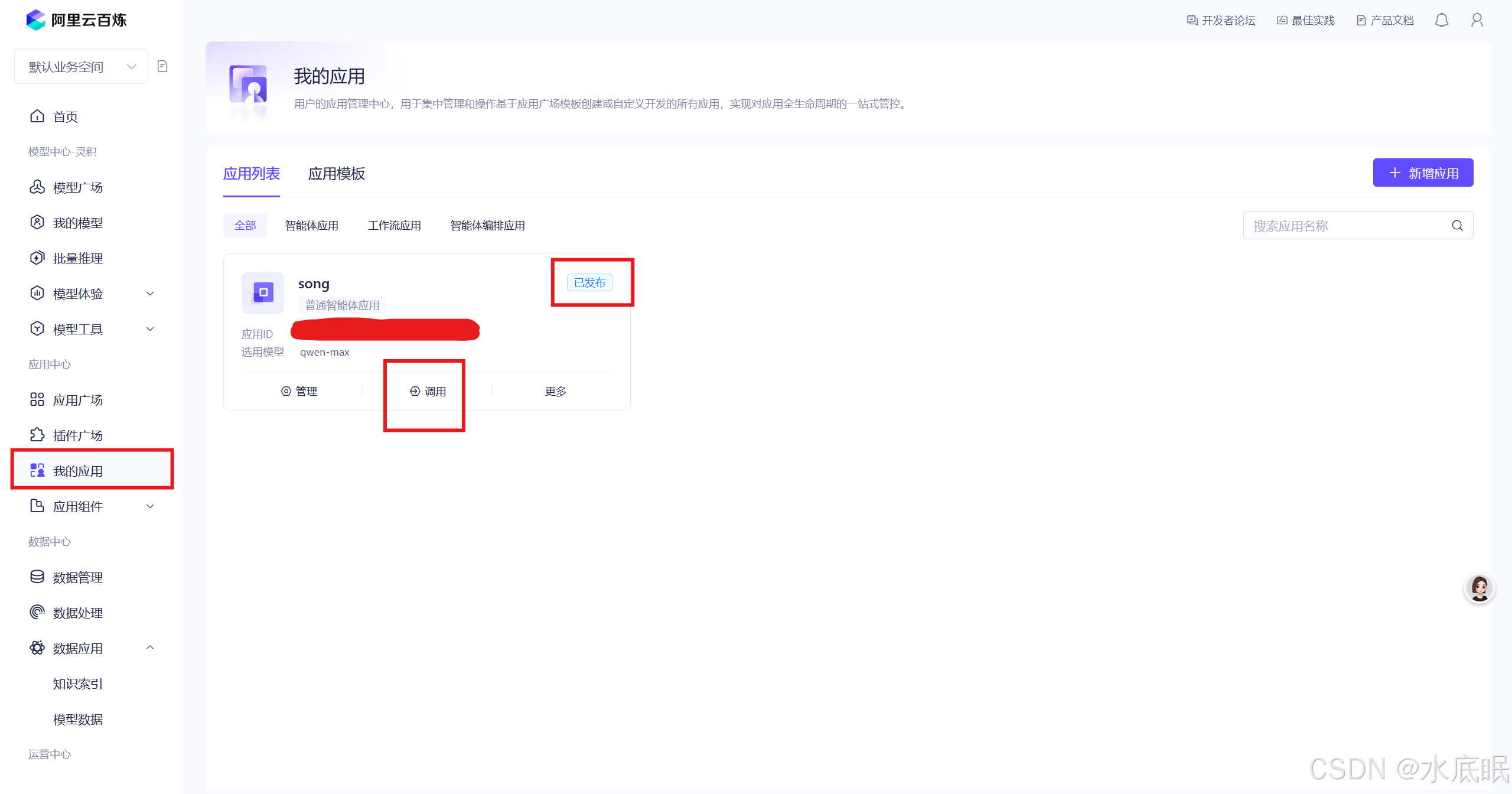
回到我的应用可以发现应用状态为已发布,未发布时为白色草稿标识;应用下方显示调用,未发布时标识置灰;
四、应用调用
-
在阿里云百炼控制台我的应用中选择对应的应用,点击调用;
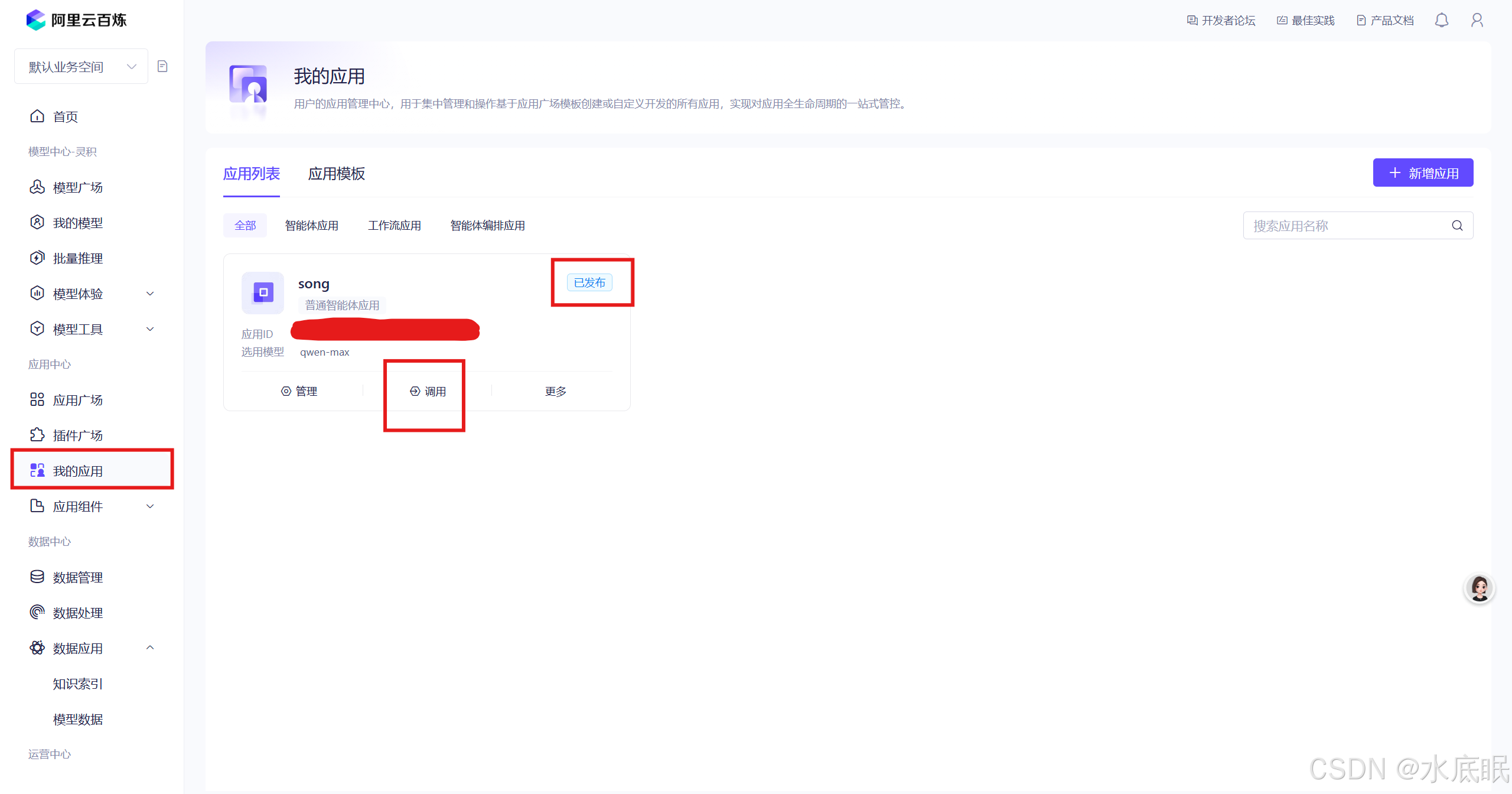
-
在发布渠道中选择官方分享渠道下的创建;
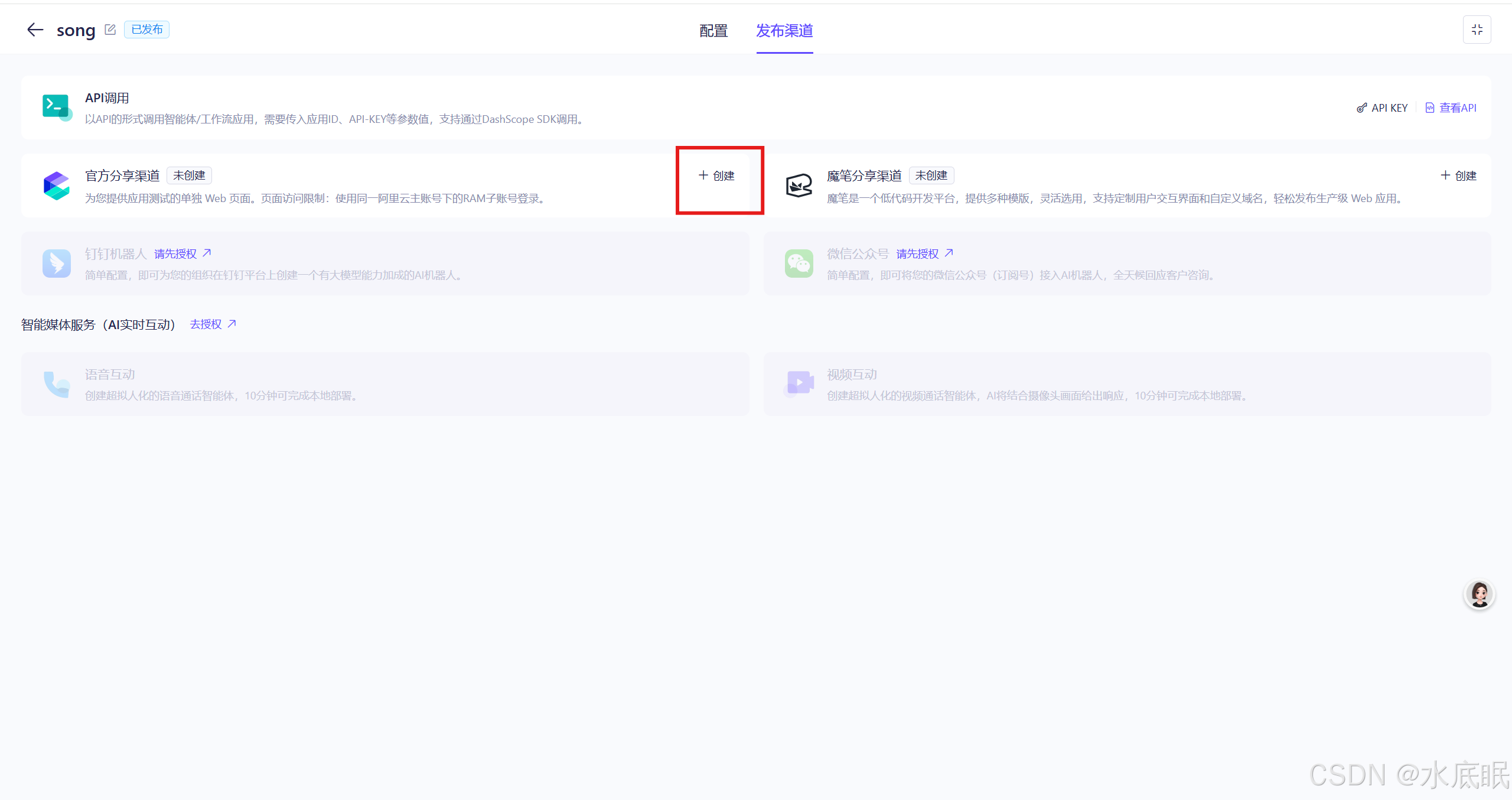
-
在弹出的页面中,点击右上角的编辑页面;
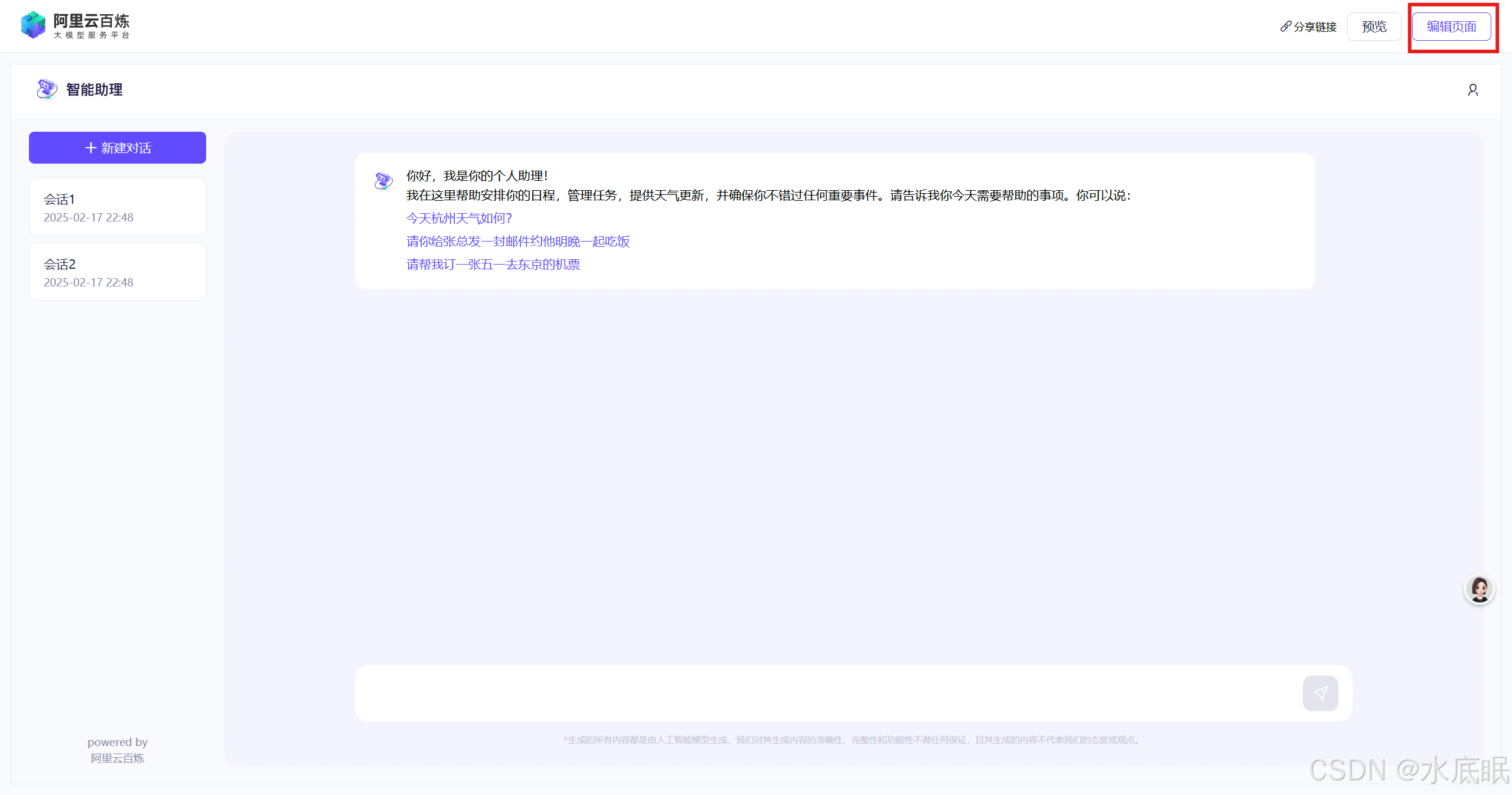
-
编辑右侧配置信息,可以在配置时关注左侧对话框中的内容,两者是互相关联的;配置完毕点击右下角更新;
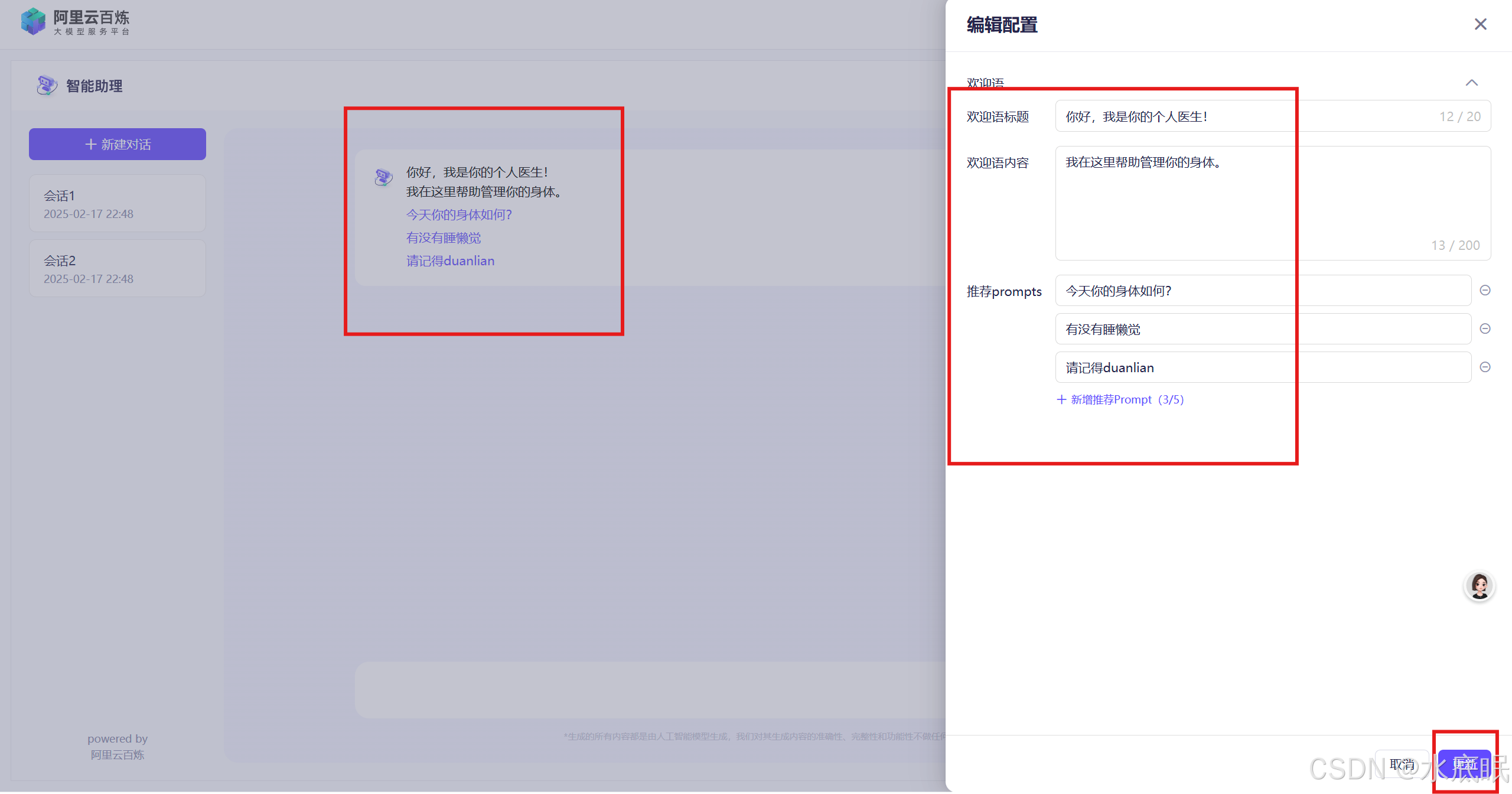
-
编辑完毕点击右上角预览,开启对话;
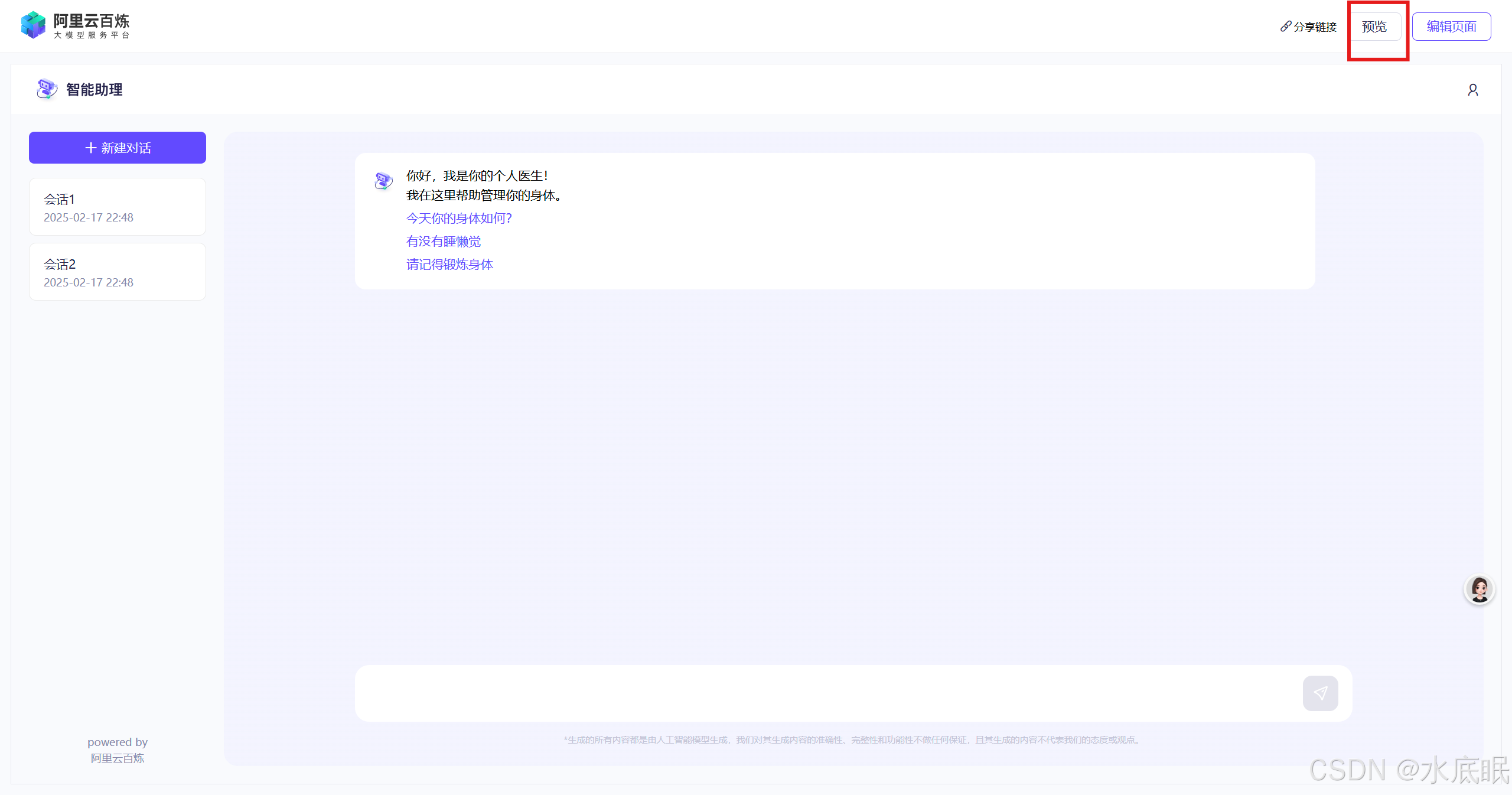
-
可以直接点击之前编辑的问题或对话,也可以直接在对话框中输入问题与现象;同时注意右上角的分享链接、预览、编辑页面消失(右上角的小人图标只是一个图标,不能点击,一路搞下来还是能发现一些Bug和体验问题的);
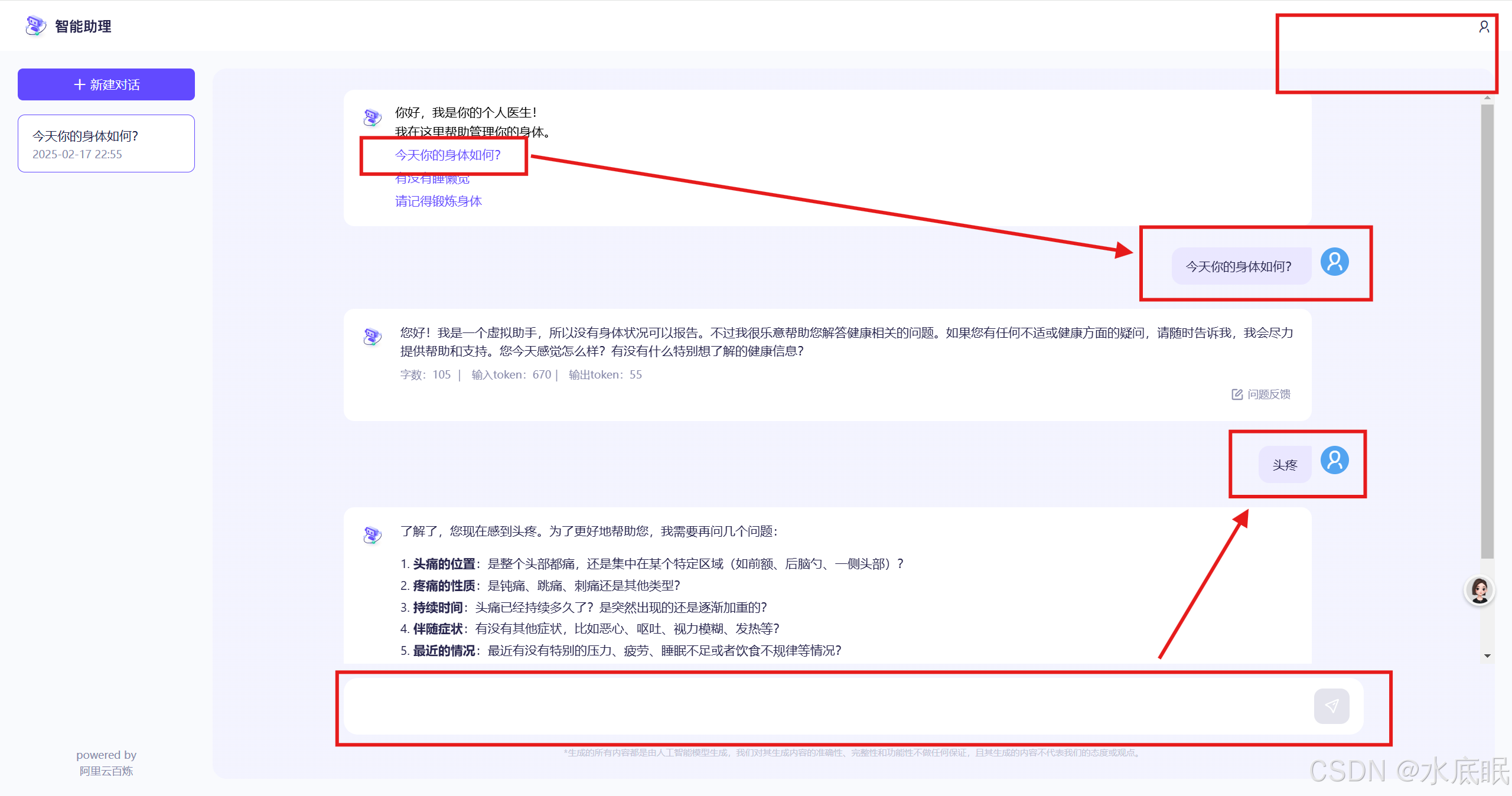
-
回到发布渠道界面可以发现之前的创建变成了配置,下方增加了预览链接,点击配置进入调试界面可以分享链接;
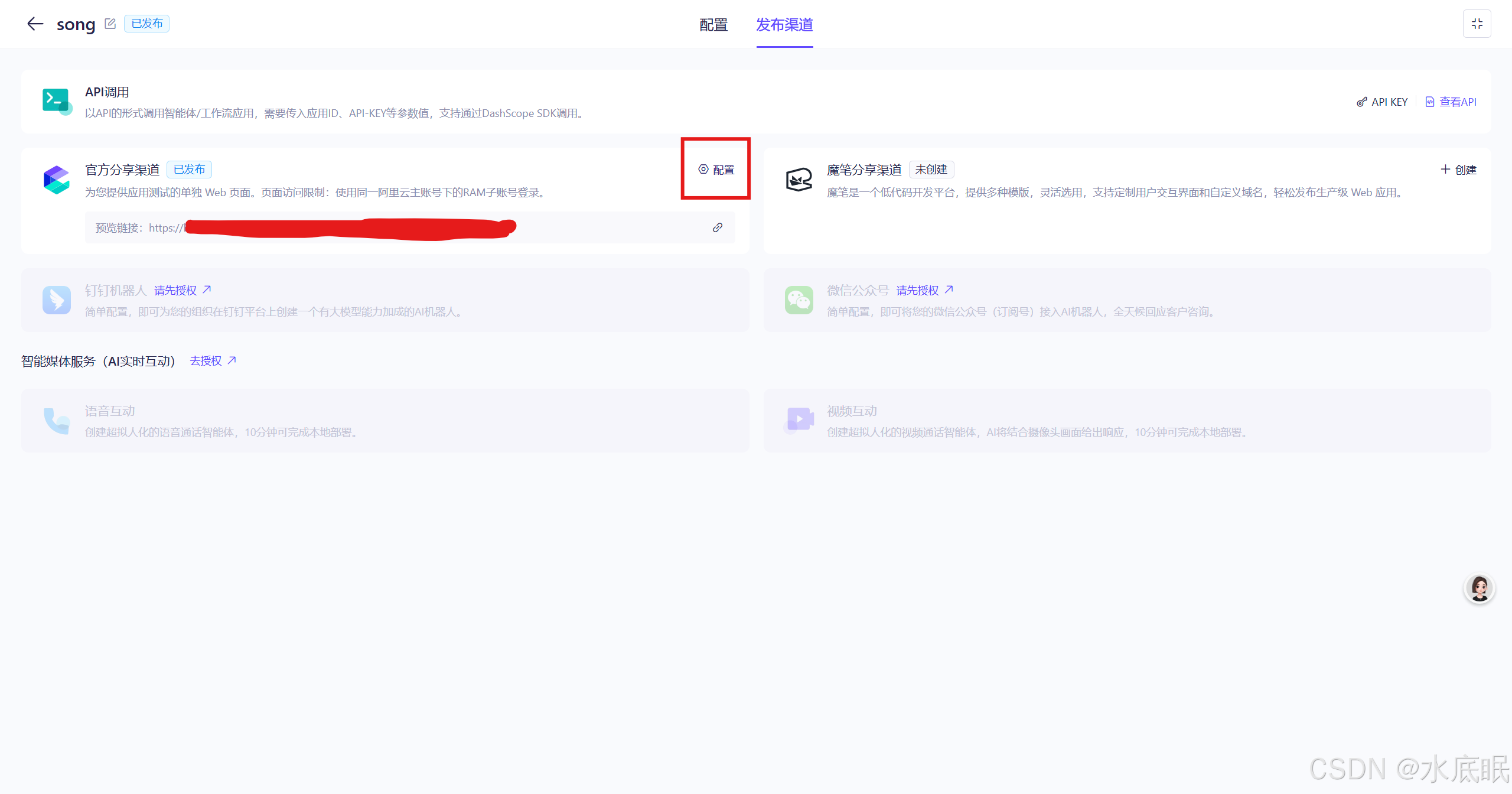
五、其他调用方法——API调用
-
再介绍第二种调用方法——API调用;点击右侧查看API;
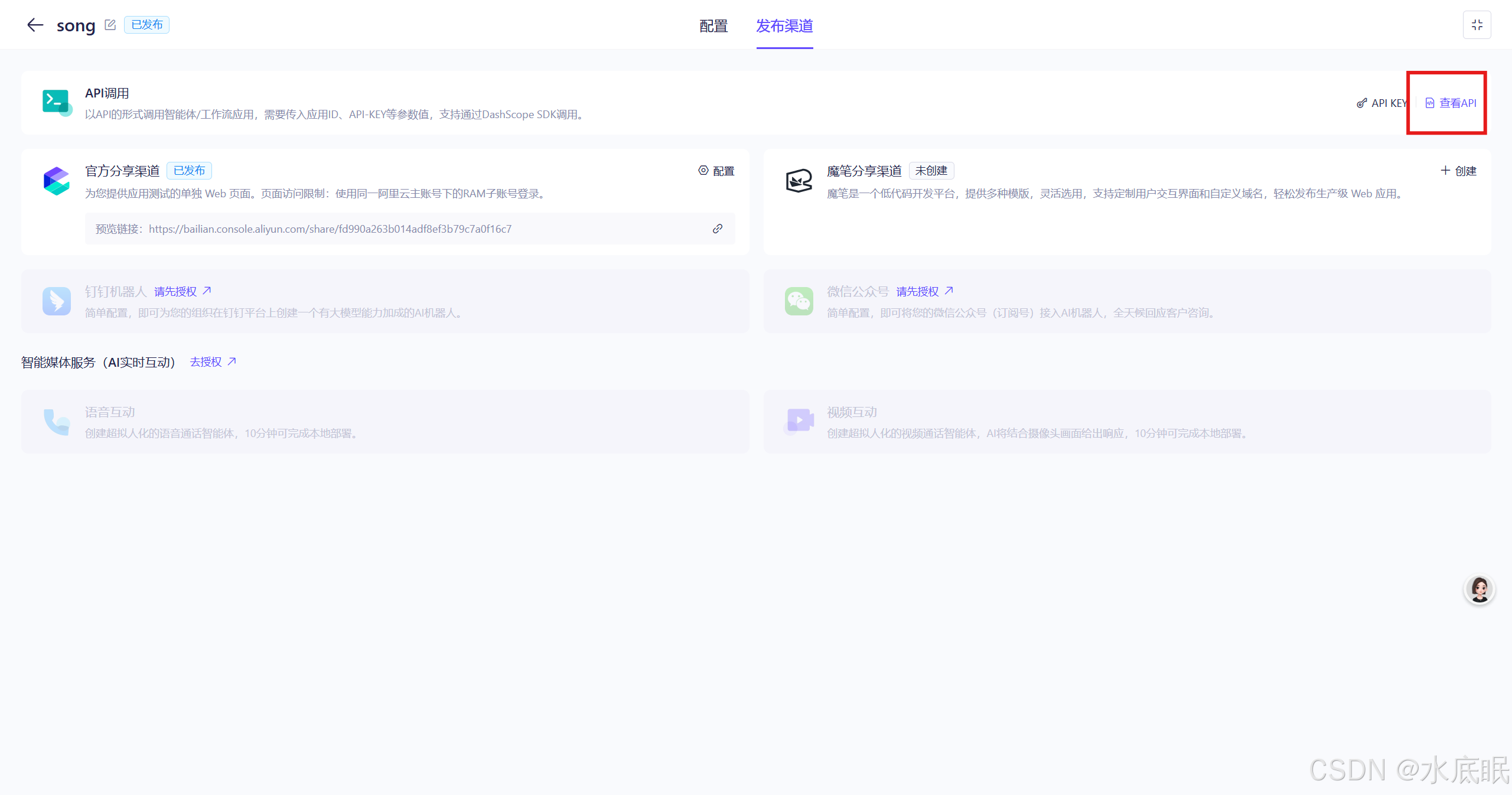
-
滑动滚轮,在右侧找到Python代码,点击复制,复制到Python程序中;
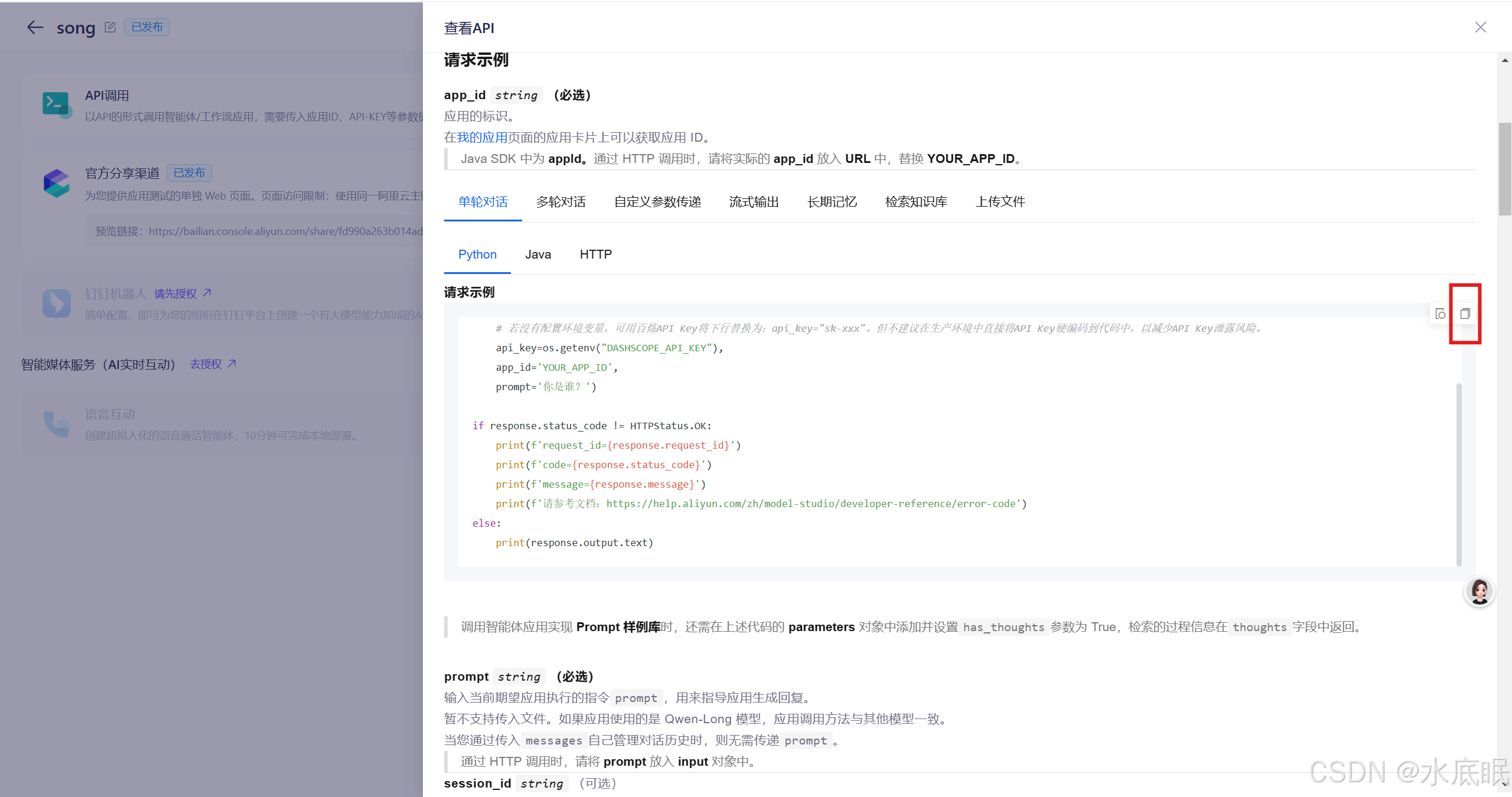
-
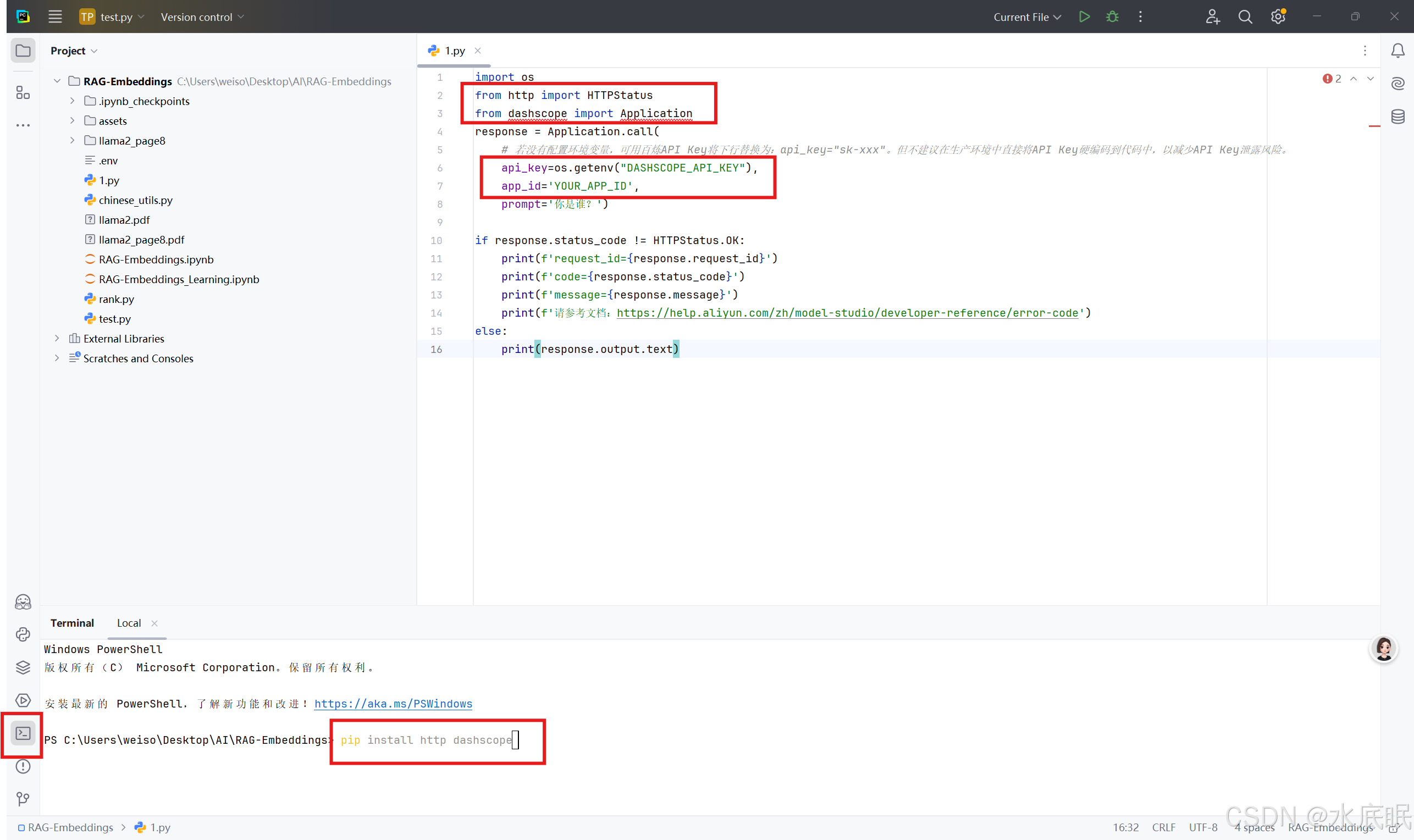
注意安装 http 和 dashscope ;api_key 和 app_id 需要修改;
-
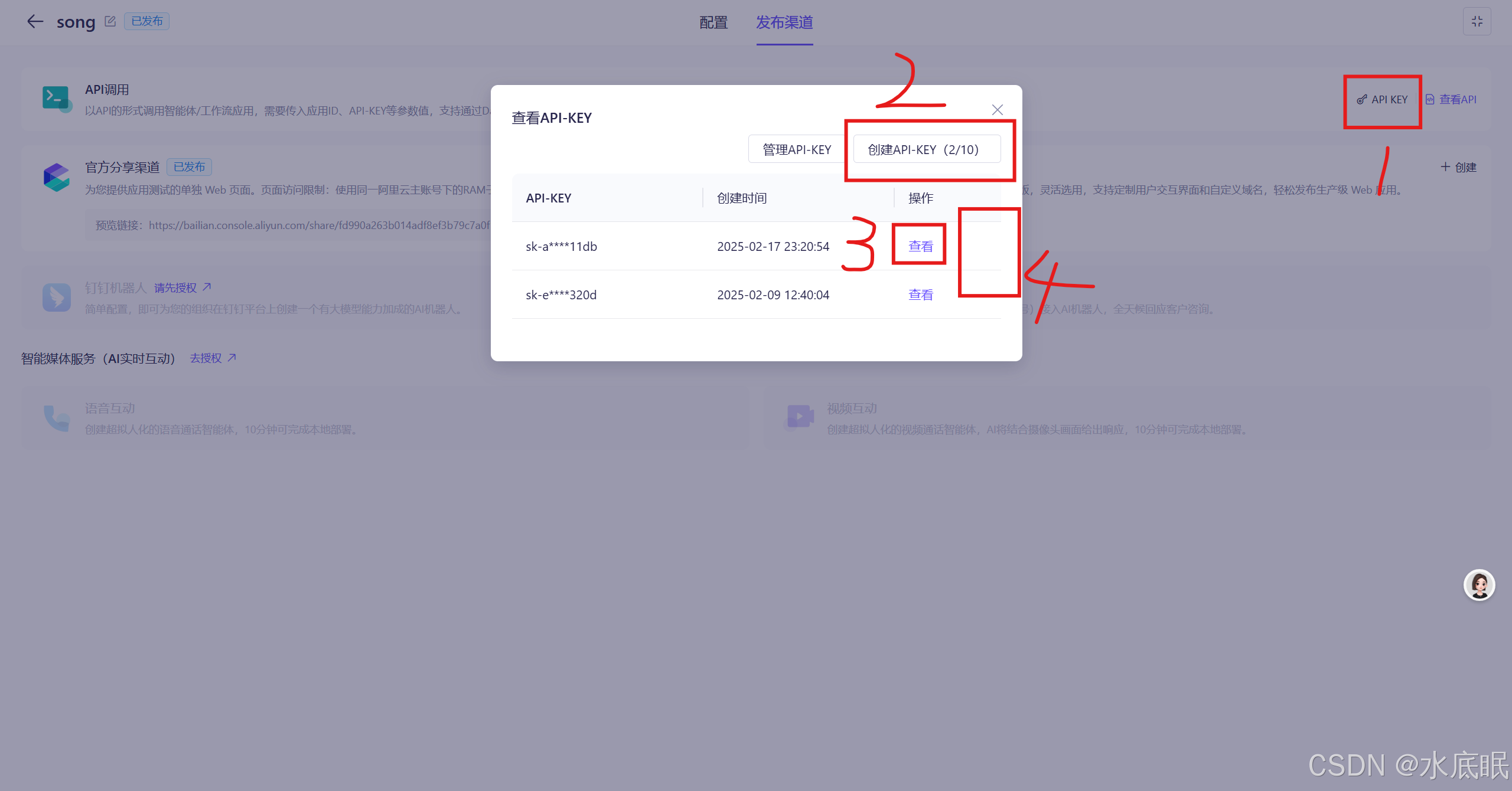
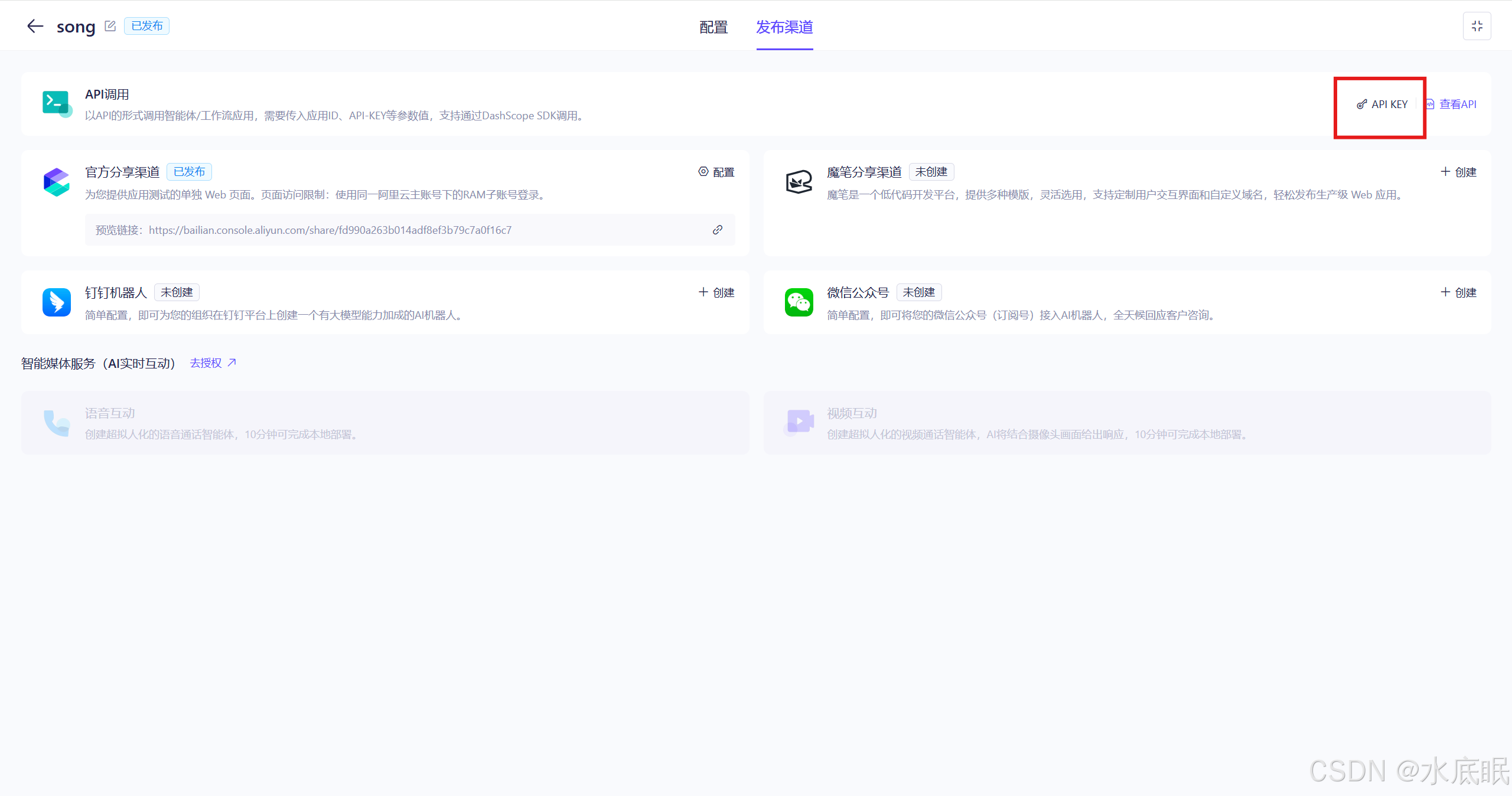
获取api_key:进入发布渠道界面,点击右侧 API KEY;
- 如果没有 API KEY 则点击红框2创建API-KEY,在弹框中添加描述,再点击确定;
- 如果有 API KEY 则点击查看,随后在红框4处会出现复制字样;
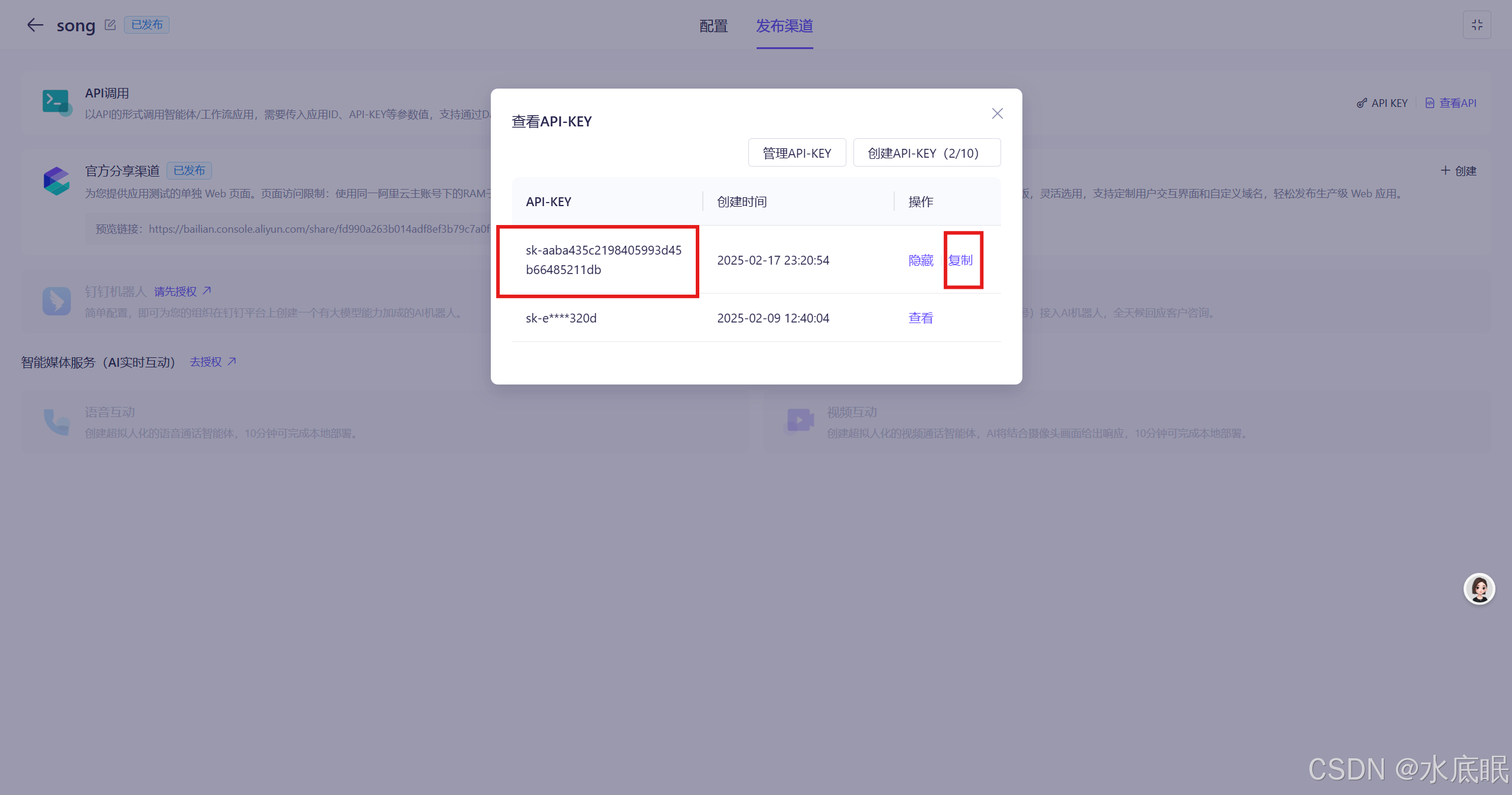
-
点击复制将以 sk 开头的 API-KEY 复制到 Python 程序的 api_key 中;
-
在阿里云百炼控制台我的应用中找到应用ID,将 ID 复制到 Python 程序的 app_id 中;
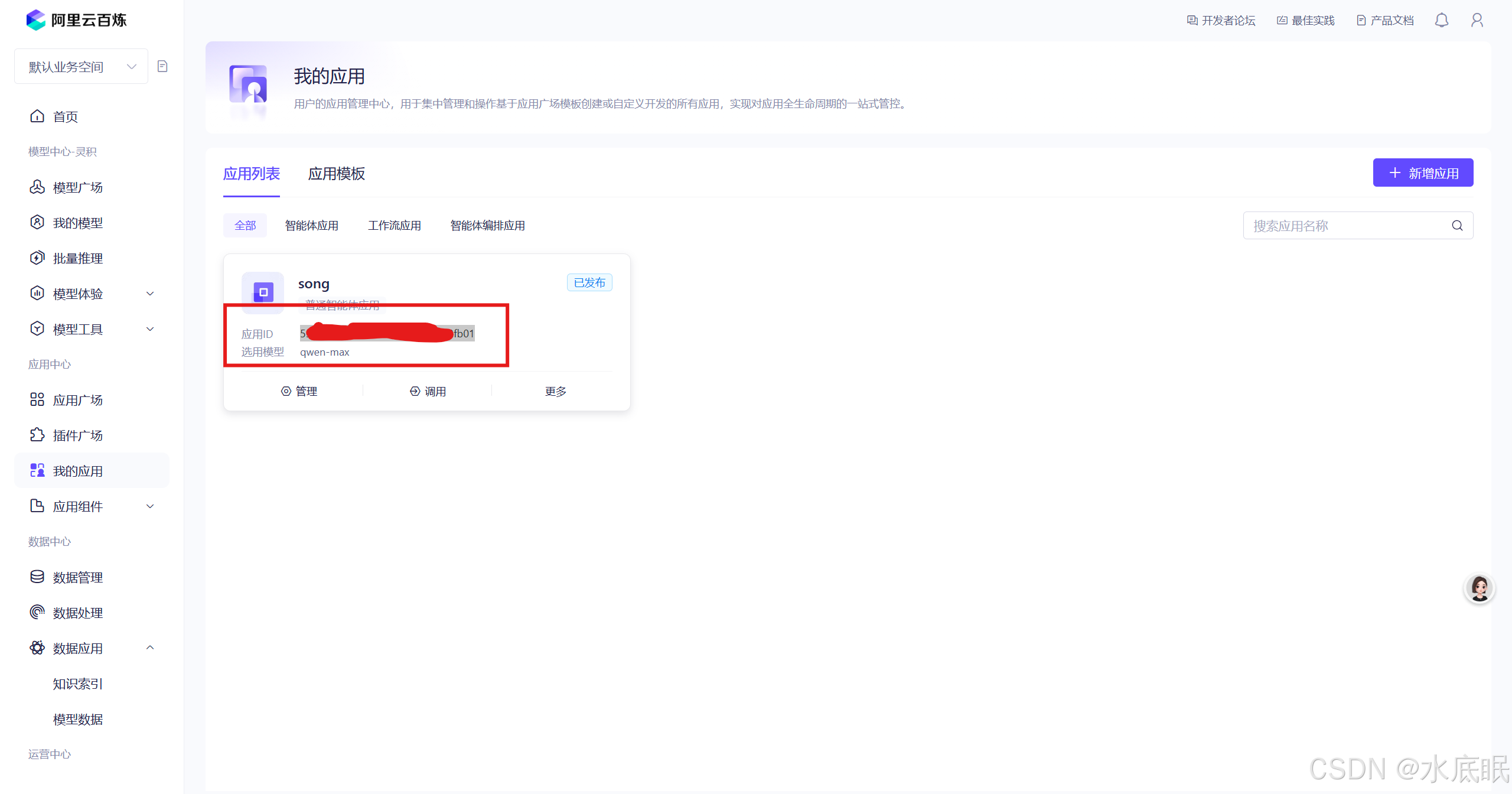
-
如下图所示,将 API-KEY 、应用ID 分别复制到 Python程序的 api_key 、app_id 中,再将 prompt 填写成想要问的问题,运行程序可以看到图片下方的回答;此外需要注意 api_key 与 app_id 的保密,请勿出示给他人,最好配置在系统变量或 .env 文件中;
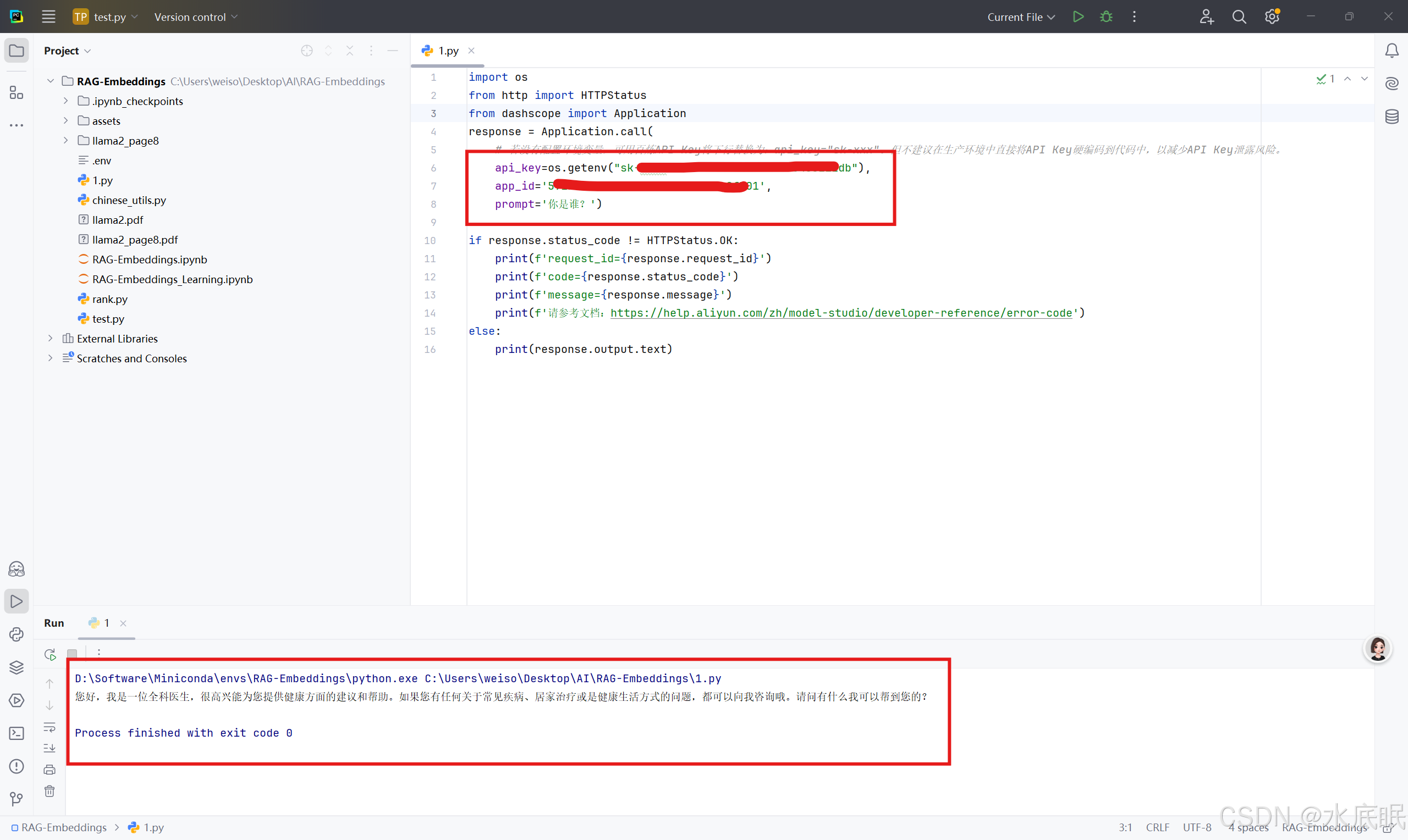
-
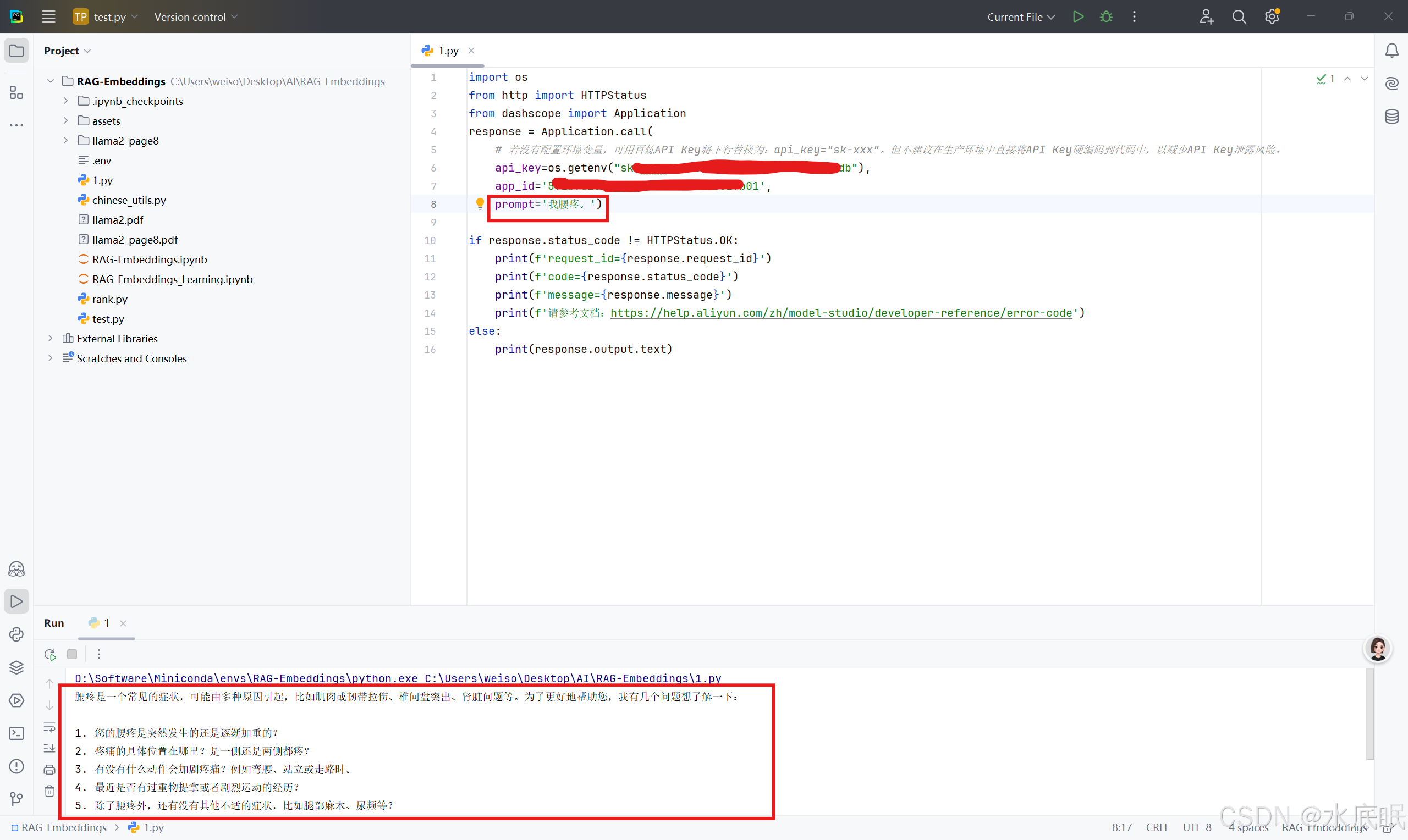
更换问题为”我腰疼“,运行程序可正常回答;
六、删除API-KEY
-
如果 API-KEY 不再使用可以删除,但是务必谨慎,删除后不可恢复;
-
在发布渠道界面选择 API KEY ;或在阿里云百炼控制台右上角选择 API-KEY ;
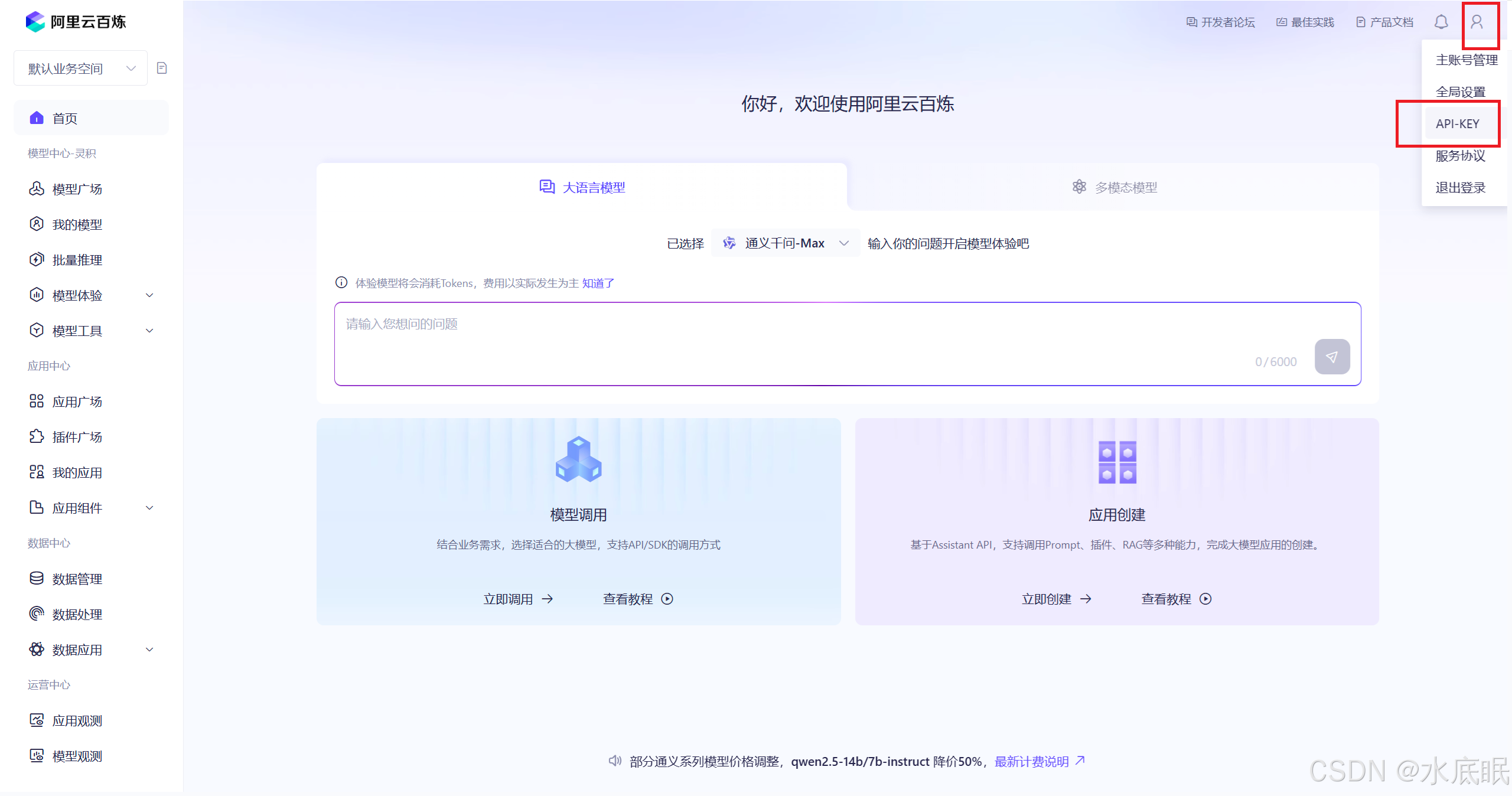
-
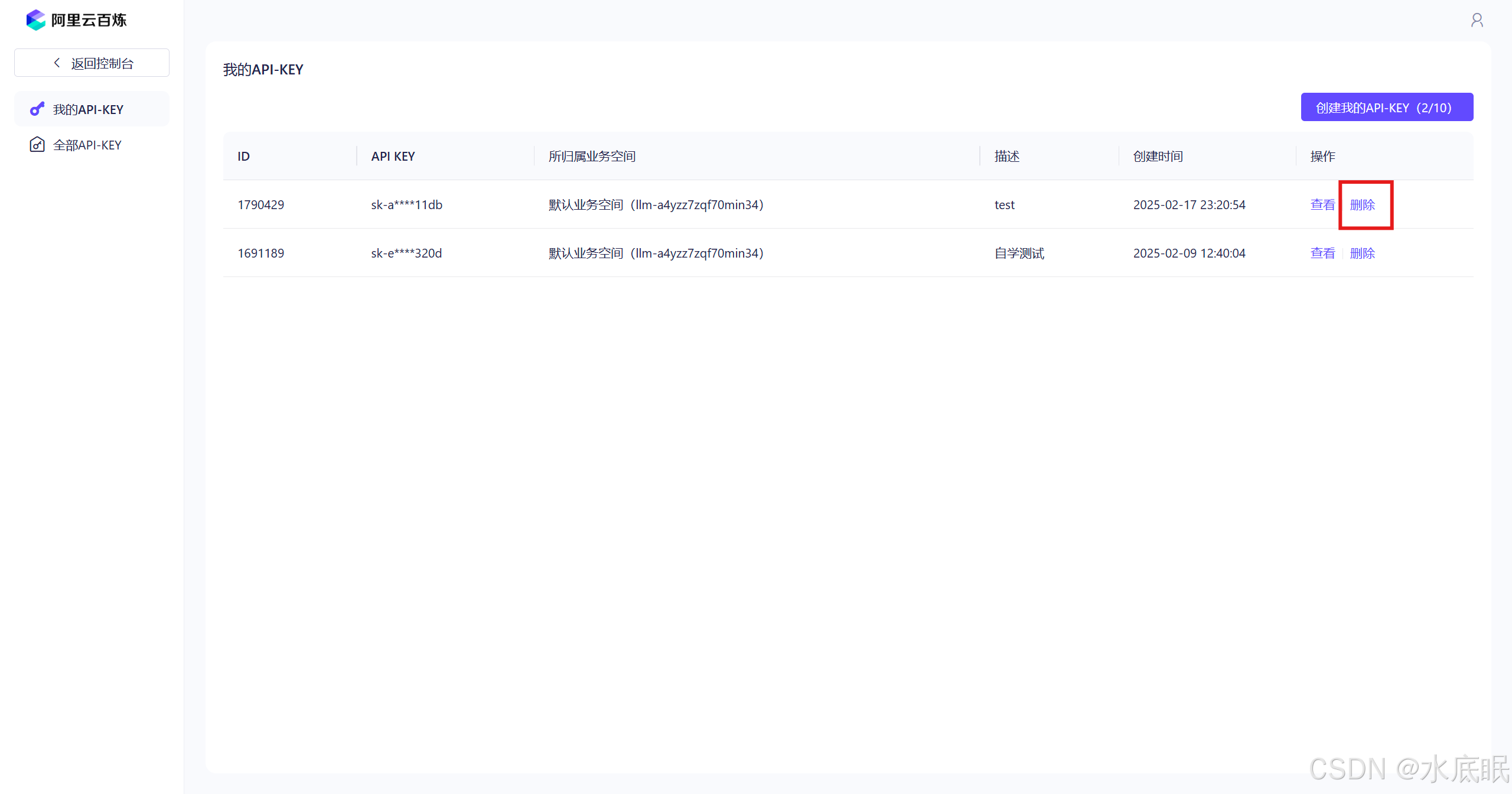
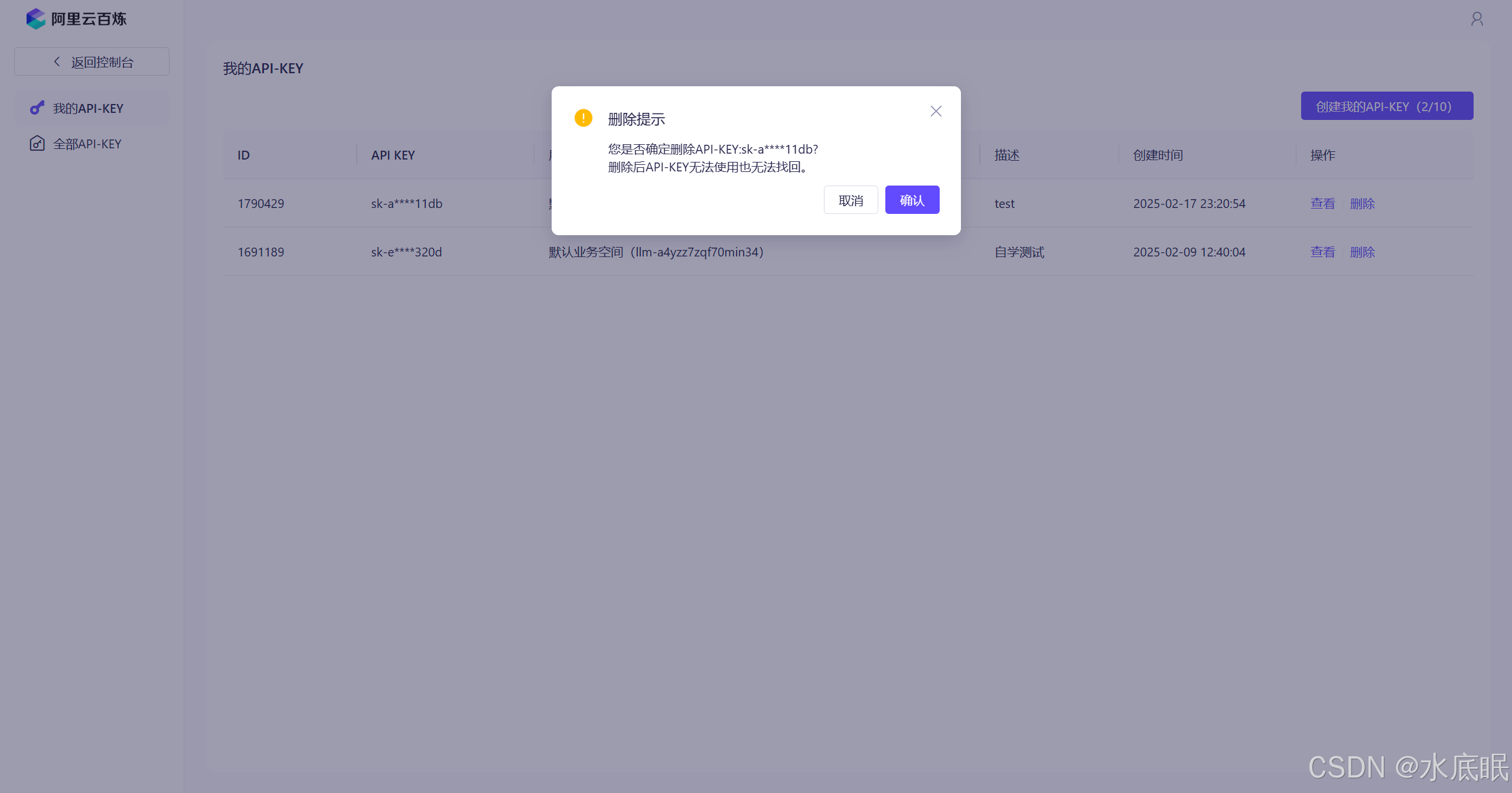
点击删除,再在弹框中点击确认;
七、删除应用
-
在阿里云百炼控制台选择我的应用,找到欲删除的应用后点击右下角更多,选择删除应用;
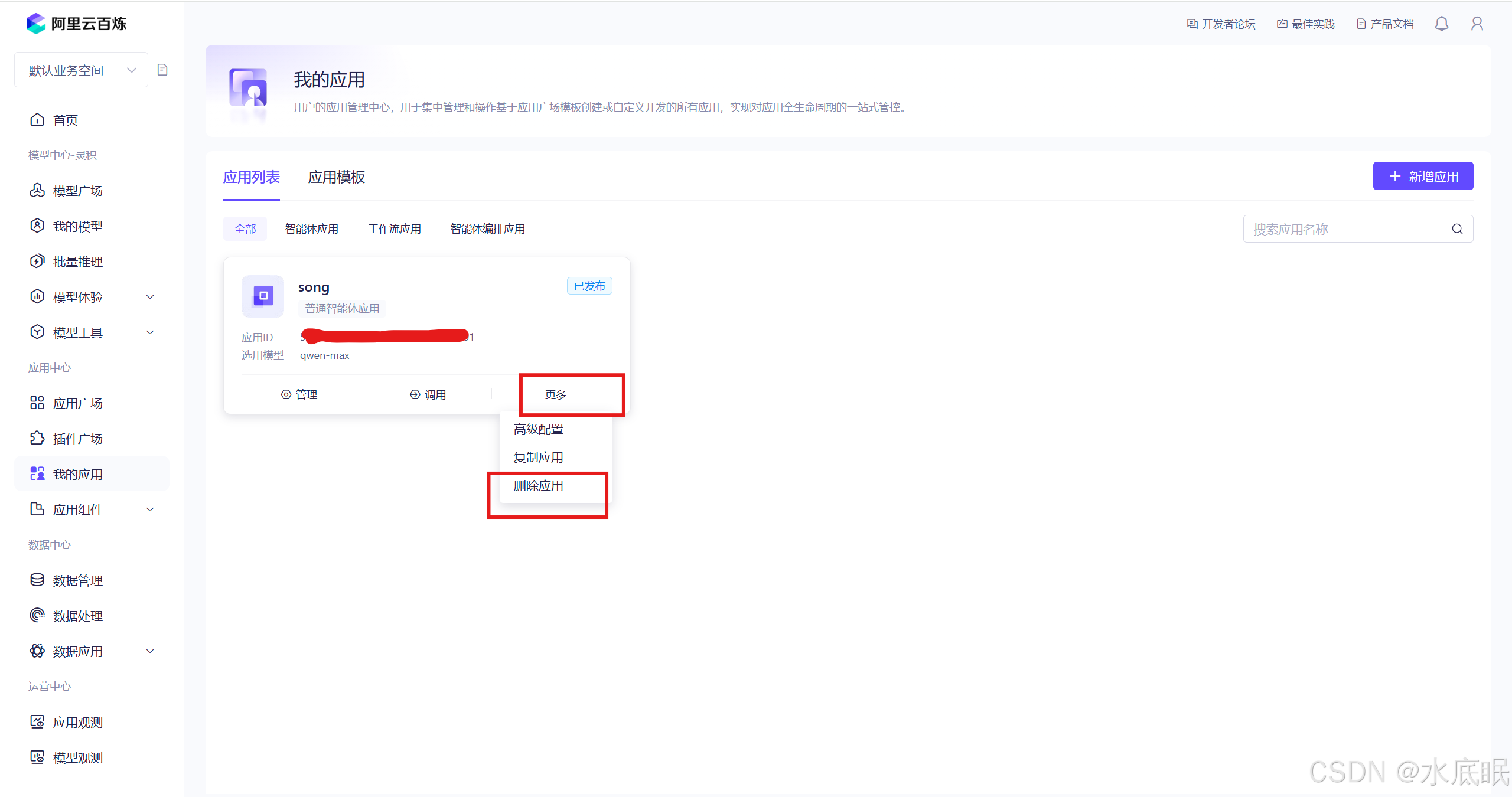
-
弹框中选择确认删除即可;

















 416
416

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









