







早上收到朋友转发的阿里云公众号推文,阿里云为用户免费提供 1 个月的训练推理等算力额度(上阿里云,免费玩转 Llama 405B 「超大杯」!)。想想上周老牛同学为了制作微调技术教程,演示训练Qwen2-0.5B小尺寸大模型就跑了一个晚上(基于 Qwen2 大模型微调技术详细教程(LoRA 参数高效微调和 SwanLab 可视化监控)),如今阿里云竟然免费提供 1 个月训练推理算力,而且还支持Llama3.1-405B超大尺寸模型,标题和内容确实把老牛同学给够吸住了。
虽然老牛同学非常相信阿里云在中国市场的地位,但还是有那么一点点担心是标题党,因此老牛同学决定验证一下,走一遍完整开通和使用流程,最后给出自己的感受给大家做个参考。
开通阿里云百炼服务
推文写得很清楚,免费额度是为阿里云百炼平台用户提供的,因此先开通注册:https://www.aliyun.com/product/bailian
说实话,取名真的很重要,不仅要好听好记还要切实际功能。比如千问:作为你的人工智能助理,随你问,我都能答;百炼:千锤百炼,大模型训练微调,就是不断打磨和调整优化过程。
阿里云百炼:是基于通义大模型、行业大模型以及三方大模型的一站式大模型开发平台。面向企业客户和个人开发者,提供完整的模型服务工具和全链路应用开发套件,预置丰富的能力插件,提供 API 及 SDK 等便捷的集成方式,高效完成大模型应用构建。
产品定价:阿里云百炼大模型服务平台在调用 API 后将产生计量和计费。各个领域的模型采用不同的计量单元,不同模型单独制定各自的计费单价和免费额度等规则。(特别注意:不同模型是单独计价和单价免费额度规则,算力额度有可能针对不同模型不一样!)
点击“立即开通”橙色大按钮,按照提示,一步一步完成注册即可:

我们可以直接通过支付宝、淘宝等方式登录(老牛同学使用支付宝扫描登录)。登录成功,需要同意“阿里云百炼服务协议”,我们主要是用于学习和研究,肯定不会干那些超纲的事情,无脑点击“同意”按钮就行了。
然后,我们就进入了百炼平台控制台首页:
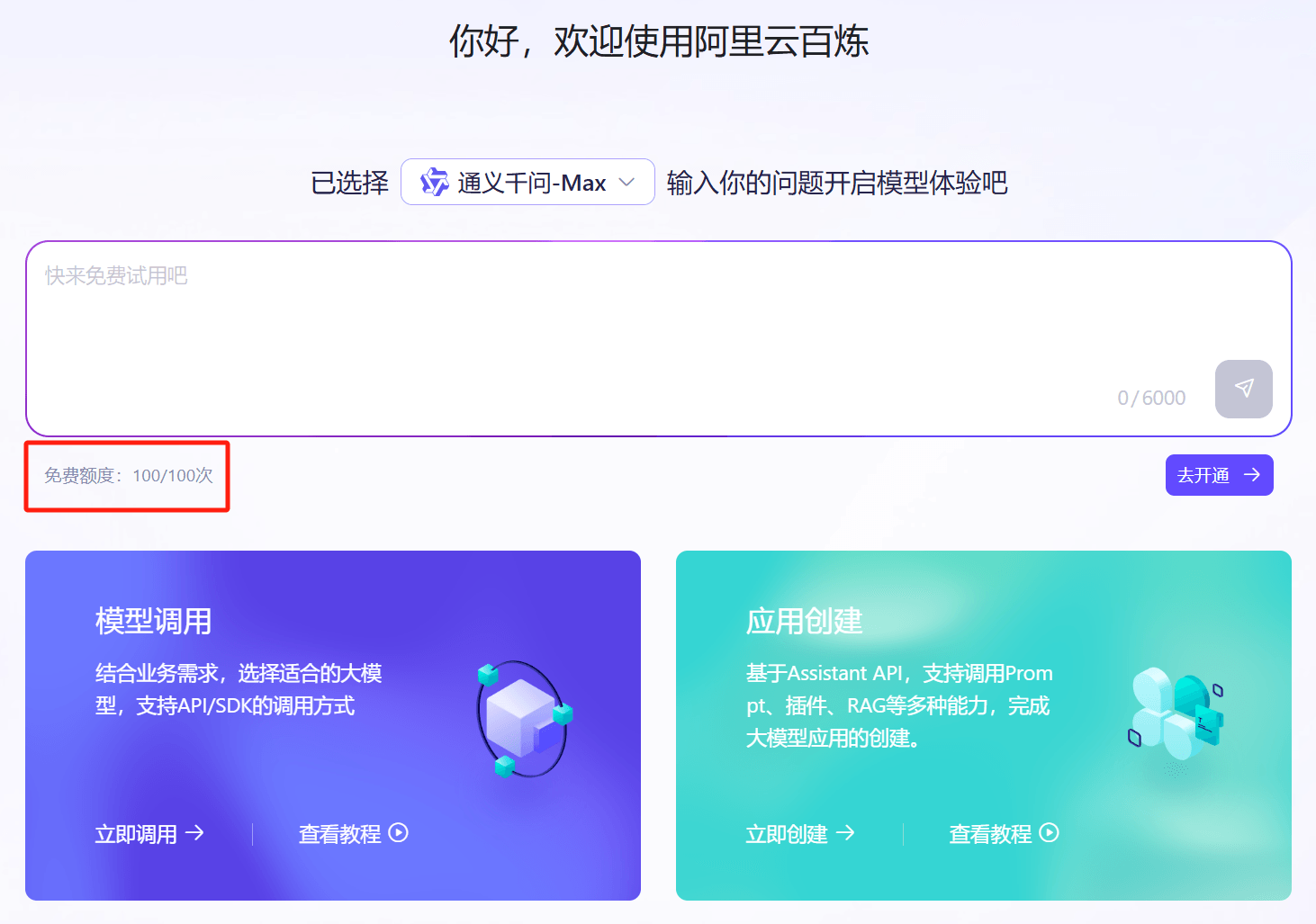
看到“免费额度:100/100 次”小字样,老牛同学之前的担心加重了一点,回头想想还是继续往下看看,毕竟是阿里云,应该是不能随便开玩笑的。
点击“去开通 →”按钮,又来个弹框确认开通。不过支持的模型倒是挺多的,支持 139 个推理(包括 Llama3.1-405B 大模型)、17 个部署和 14 个训练,应该来说我们对学习和研究类需求足够了:

勾选“我已阅读并同意《模型管理服务协议》”,然后点击“确认开通”按钮,整个开通流程就结束了!
使用 API 调用推理服务
首先体验一下大模型的推理服务,选择“模型广场”,选择任意一个模型(如:通义千问-Max),点击“API 调用示例”:
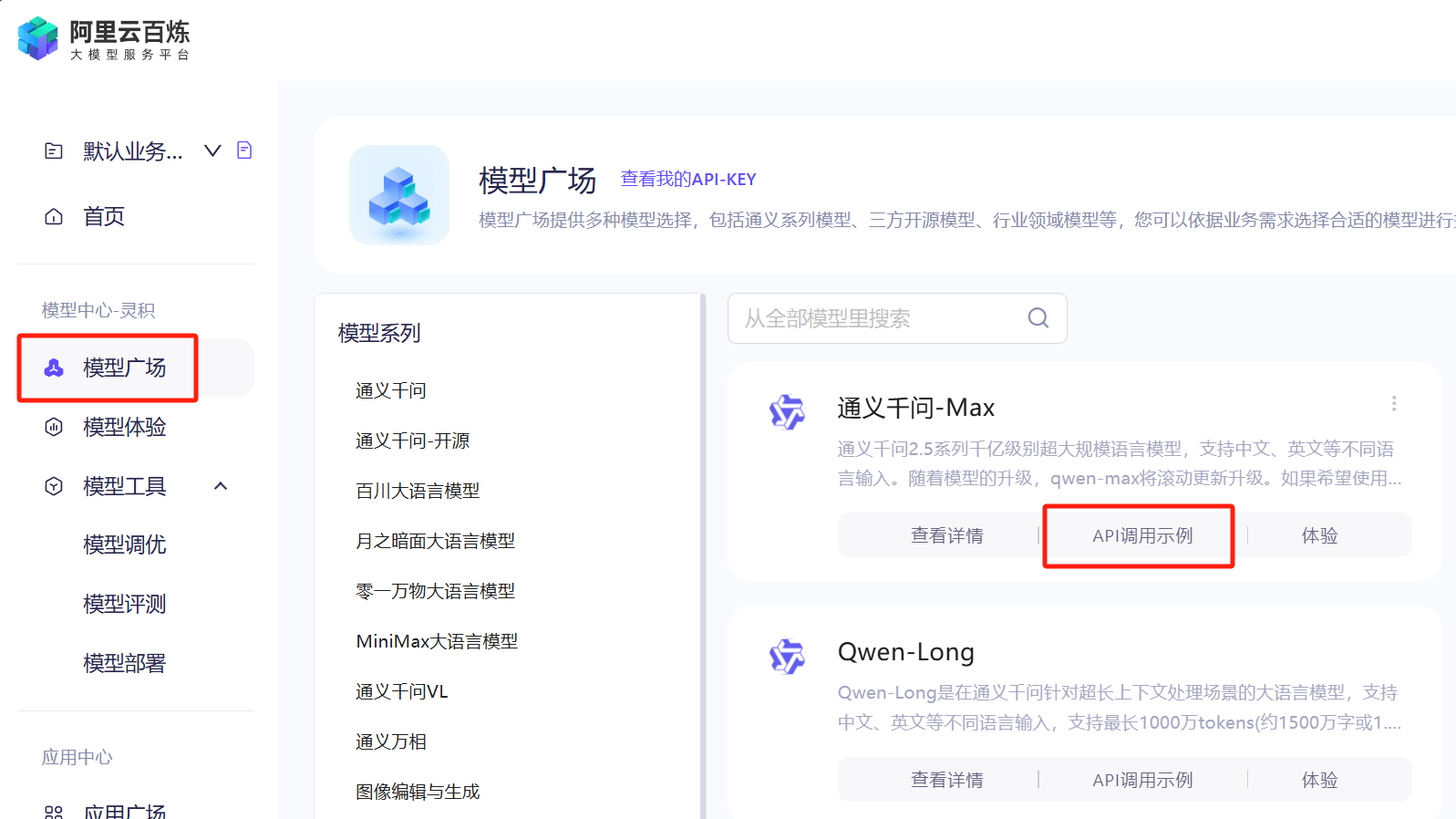
可以看到,API 调用示例提供了Python、Java和Curl共 3 种方式,对于我们来说也应该足够了(老牛同学就不演示了)。
最关键的是,点击“模型详情”,可以看到计费方式和免费额度信息:
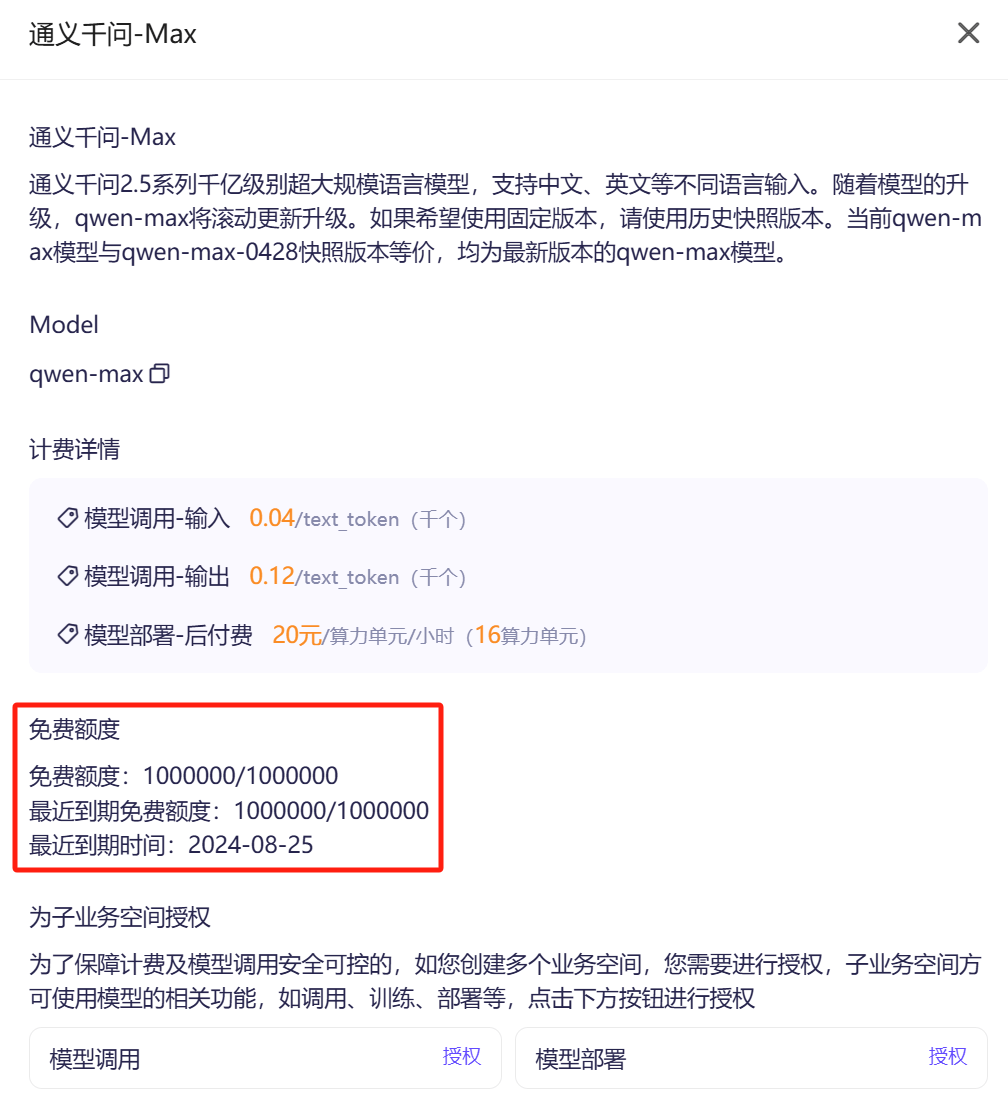
可以看到,免费额度信息如下:
- 免费的 Token 数量有限制(如:通义千问-Max 是 100 万个)
- 之前推文中提到的,免费 1 个月,是指这些免费额度仅 1 个月有效期,不是老牛同学想象的免费使用 1 个月!
到这里,老牛同学感觉有一点点失望了
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 695
695

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









