







论文原文:

- 论文题目:Detecting Voice Cloning Attacks via Timbre Watermarking(通过音色水印技术检测语音克隆攻击)
- 原文链接:https://arxiv.org/abs/2312.03410
目录
一、论文基本信息
1.作者
中国科学技术大学的刘畅、杨曦、张卫明、俞能海;南洋理工大学的张杰、张天威
2.论文发表时间
3.论文发表场合
已被四大安全顶会之一的NDSS’2024 录用。NDSS’2024:Network and Distributed System Security (NDSS) Symposium 2024 , 26 February - 1 March 2024, San Diego, CA, USA
4.简要概括论文
针对声纹克隆攻击的检测问题,提出了一种基于音色水印技术的方法。该方法通过在频域嵌入水印信息,采用短时傅里叶变换(STFT)方案将音频波形转换为频域,并在水印嵌入模块和提取模块之间引入了失真层,以增强水印的鲁棒性和泛化性。
二、论文主要内容
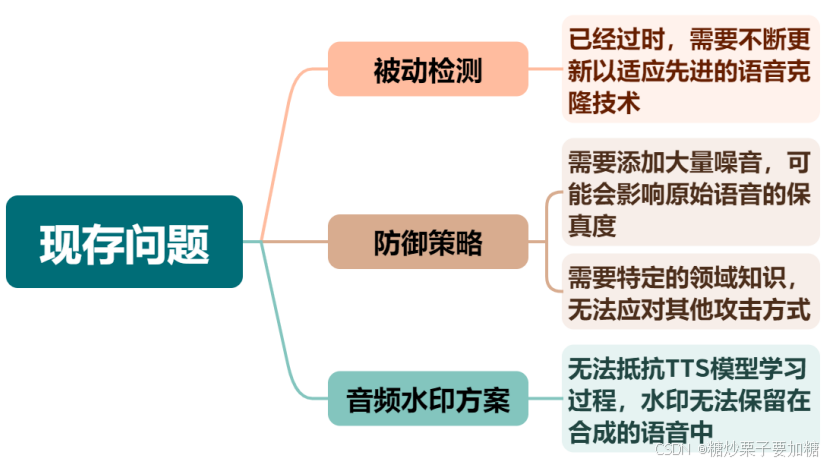
1.现存问题
2.作者的目标是什么,已经实现了什么(贡献)?
(1)目标
目标是保护用户发布的音色免受语音克隆攻击,并提出了一种名为“Timbre Watermarking”的新概念来实现这一目标。
(2)作者已经实现的成果(贡献)
已经实现了在目标语音发布前将水印信息(例如所有权)主动嵌入目标语音的方法。具体贡献如下:
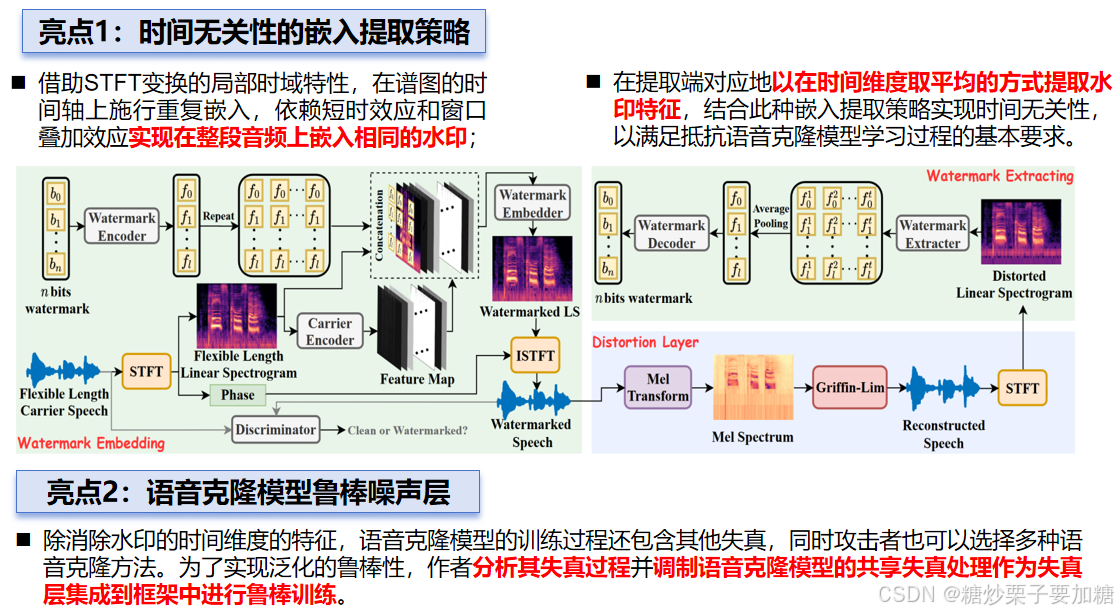
1)提出了一种端到端的抵抗语音克隆的音频水印框架。框架及方法亮点如下图所示:
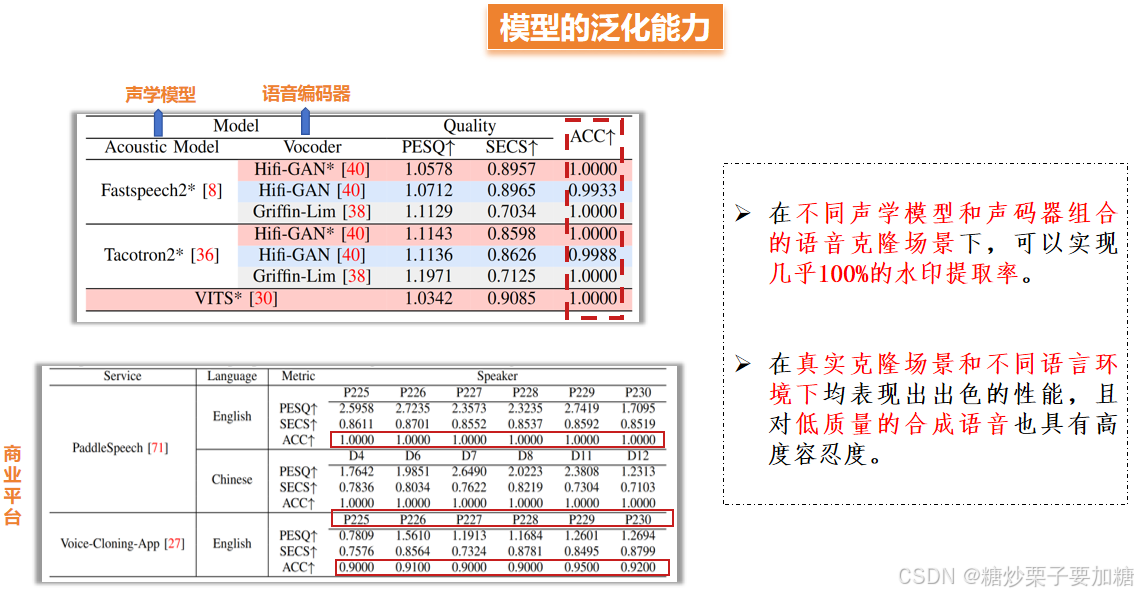
2)大量实验证明了该方法对不同语音克隆攻击(包括自适应攻击)的泛化能力和鲁棒性。此外,其适用于现实世界的服务,如Paddle-Speech、Voice-Cloning-App和so-vits-svc。
3.研究方法/技术
| 介绍 | |
| 频域水印嵌入 | 作者提出将水印信息嵌入到变换域中,采用短时傅里叶变换(STFT)方案将音频波形转换为频域,并沿垂直方向嵌入水印信息,从而增强了水印的鲁棒性。同时,作者还采用了水平方向的重复嵌入策略,进一步增强了水印的鲁棒性。在提取阶段,作者对水平方向提取的水印信息进行了平均处理。 |
| 失真层 | 为增强泛化能力,作者研究了常用的语音克隆策略,并发现了一些常用的处理操作,如比例修改、归一化、相位信息丢弃和波形重构。作者将这些处理操作作为失真层插入到水印嵌入和提取模块之间,并以端到端的方式进行训练。这一失真层使得其他模块能够识别不同处理操作,从而验证水印。 |
| 特征分析 | 作者提到了一些基于特征的方法,如使用短时能量、平均振幅和过零率等指标来区分真实人声和合成人声。此外,还提到了一些基于深度学习的方法,如基于层神经元激活模式的DeepSonar系统,以有效区分真实声音和AI合成声音。 |
4.实验设计、结果及分析
(1)实验设计
| 具体内容 | |||
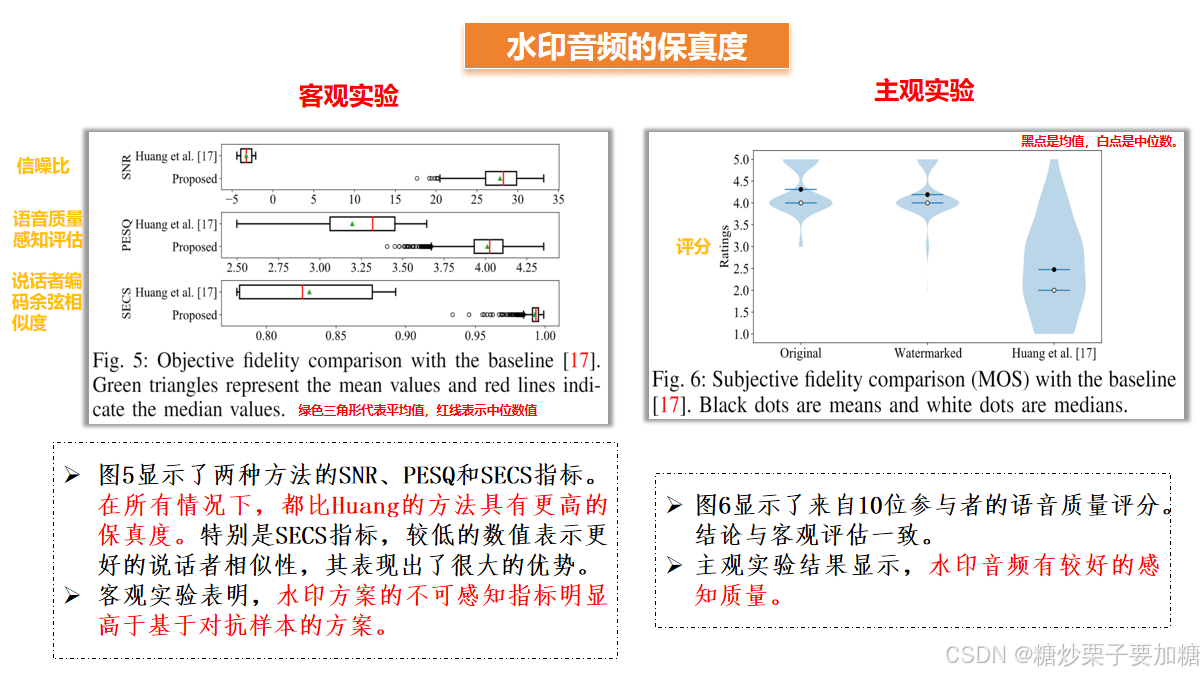
| 度量指标 | 客观指标 | 信噪比 | SNR仅用于衡量水印和音频处理造成的质量损失的大小 |
| 语音质量的感知评价 | PESQ通过考虑人耳听觉系统的特殊性,提供了不可感知性语音质量评估 | ||
| 说话人编码器余弦相似度 | SECS利用说话人相似度来评价保真度,值越大表示相似度越高。 | ||
| 主观指标 | 平均意见分数 | 使用Resemblyzer 包的说话人编码器来计算 | |
| 有效性测试 | 主观评估 | 音频质量的比较 | |
| 客观评估 | 指标的计算 | ||
| 泛化能力测试 | 不同声学模型和声码器组合的语音克隆场景 | ||
| 真实克隆场景和不同语言环境下 | |||
| 鲁棒性测试 | 不同预处理操作 | ||
| 不同裁剪比例 | |||
| 消融实验 | 调整嵌入位数 | ||
| 移除失真层,只联合训练水印嵌入和提取,以获得失真盲水印模型 | |||
(2)实验结果及分析
1)水印音频的保真度
水印音频的保真度实验包括了主观评估和客观评估,通过对音频质量的比较和指标的计算来评估水印的保真度。
2)模型的泛化性能力测试
3)模型的鲁棒性测试
对测试数据集中的音频应用不同的预处理操作(不同预处理操作如裁剪、重采样、幅度缩放、MP3压缩、中值滤波、低通滤波、高通滤波、加性高斯噪声等),然后使用模型进行水印嵌入和提取。记录每种预处理操作下模型的性能指标。
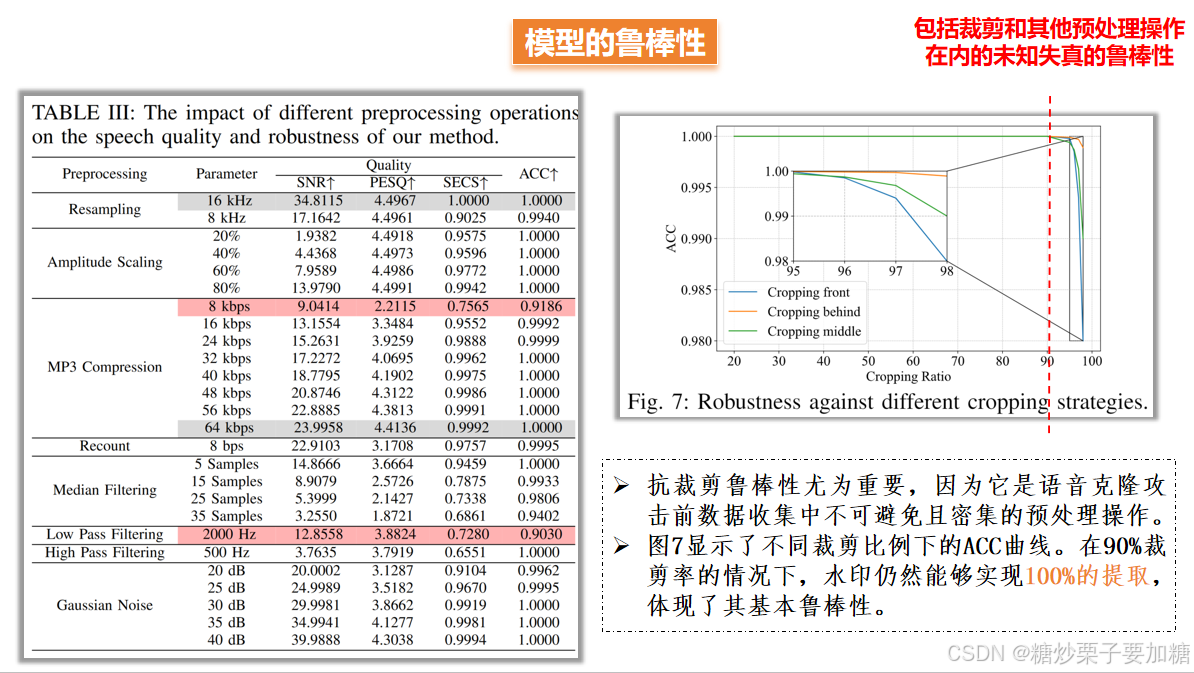
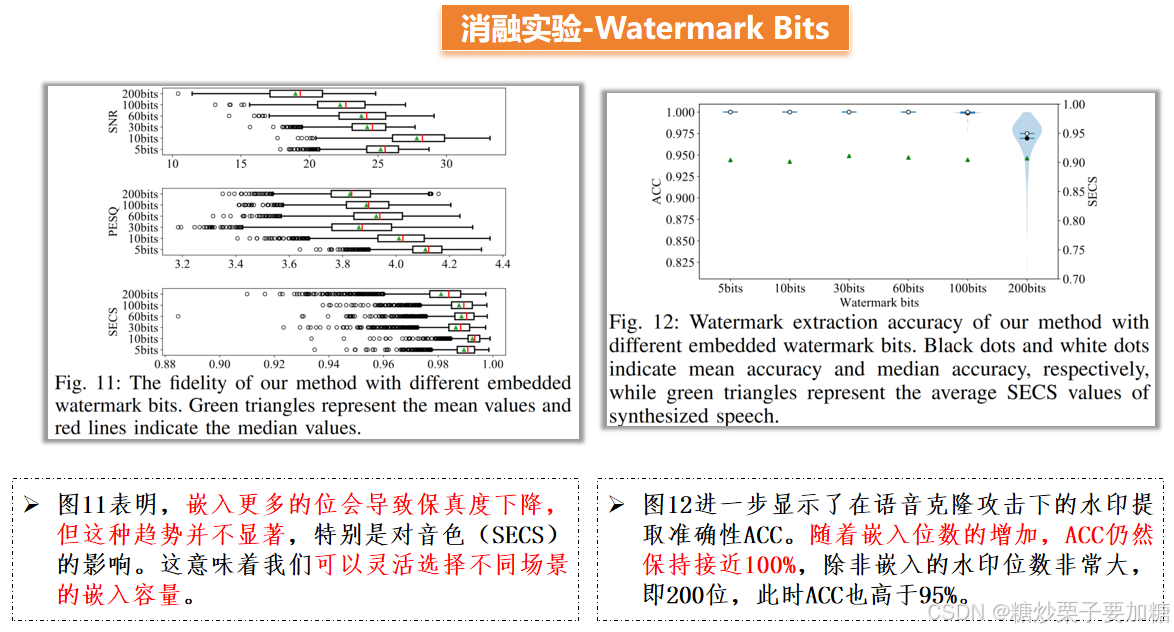
4)消融实验
使用简单的全2D卷积网络作为水印编码器ENc、水印嵌入器EM和水印提取器EX,并逐步消融模型的不同部分。通过逐步消融模型的不同部分,评估每个部分对模型整体性能的影响,包括水印嵌入和提取的准确性、鲁棒性等指标。作者选择水印位、失真层两个关键组件进行实验,结果及分析如下。

三、写作积累
| 专业术语 | 定义 |
| Voice Cloning Attacks | 语音克隆攻击,包括专业、常规和低质量的攻击,用于评估模型对不同攻击的泛化能力 |
| Distortion-Blind Watermarking Model | 失真盲水印模型,用于在载体音频中嵌入水印并对抗失真攻击。 |
| Signal-to-Noise Ratio | 信噪比(SNR),用于衡量由于水印处理和音频处理而导致的质量损失的大小。 |
| Perceptual Evaluation of Speech Quality | 语音质量的感知评估(PESQ),是一种用于电话网络和编解码器的语音质量评估的新方法。 |
| Speaker Encoder Cosine Similarity) | 说话者编码余弦相似度(SECS),利用说话者相似性来评估保真度,较高的数值表示更强的相似性。 |

















 858
858

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









