






在探索数据科学的道路上,我选择了Python作为我的主要工具,因为其丰富的库和强大的数据处理能力。以下是我学习Python数据分析的详细过程、技巧运用、以及我的总结与收获。
一、学习初衷与动机
随着数据量的不断增长,数据分析的重要性日益凸显。为了在这个信息爆炸的时代中脱颖而出,我决定深入学习Python数据分析,以便更好地理解和利用数据。
二、编程过程与探索
1. Python基础学习
我的学习旅程始于Python的基础语法和编程逻辑。通过练习简单的程序,我逐渐掌握了Python的变量、数据类型、控制流、函数等基本概念。
2. 数据处理库学习
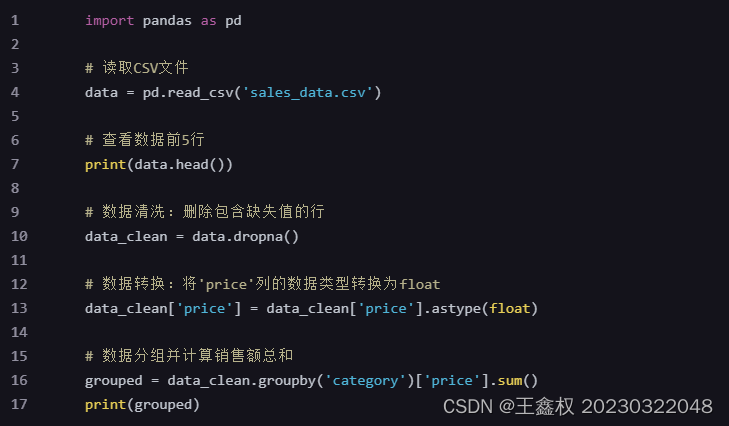
接下来,我深入学习了NumPy和Pandas这两个强大的数据处理库。NumPy提供了高性能的数组和矩阵运算功能,而Pandas则提供了数据清洗、转换、合并等丰富的数据处理功能。
示例代码(Pandas数据处理):
3. 数据可视化
在数据处理之后,我学习了如何使用Matplotlib和Seaborn进行数据可视化。这些库提供了丰富的图表类型和定制选项,使数据呈现更加直观。
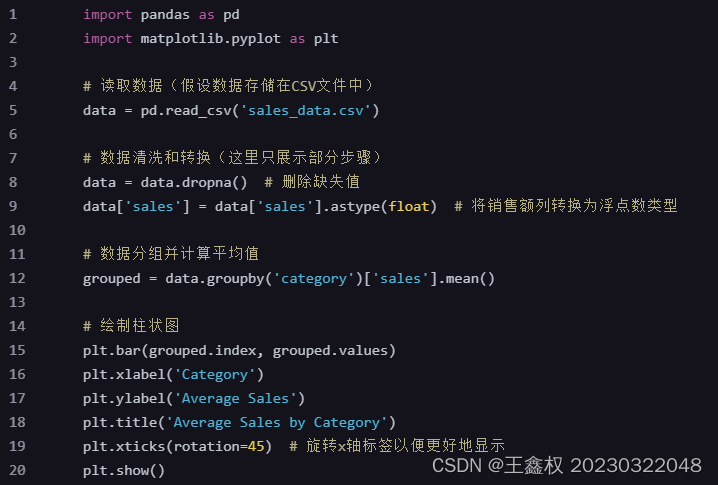
示例代码(Matplotlib绘制柱状图):

三、技巧运用与实战
在学习的过程中,我逐渐掌握了一些实用的技巧。例如,在数据清洗时,我会先对缺失值进行处理,然后再对数据进行类型转换和格式统一。这样可以确保数据的准确性和一致性,为后续的数据分析奠定基础。
在数据可视化方面,我学习了Matplotlib和Seaborn这两个库。Matplotlib提供了丰富的图表类型和定制选项,而Seaborn则提供了更高级别的接口,用于绘制统计图形。我通过实践发现,将Matplotlib和Seaborn结合起来使用,可以绘制出既美观又实用的数据可视化图表。
以下是一个使用Pandas和Matplotlib绘制柱状图的代码示例和结果展示:
1. 批量处理数据
在处理大规模数据时,我学会了使用Pandas的apply函数和Lambda表达式来批量处理数据。这大大提高了数据处理的效率。
2. 数据清洗
数据清洗是数据分析的关键步骤之一。我学会了使用Pandas的fillna、dropna等方法处理缺失值,以及使用正则表达式等方法处理文本数据。
3. 数据可视化优化
在数据可视化方面,我学习了如何调整图表的颜色、字体、大小等属性,以及如何使用Seaborn的内置样式和调色板来美化图表。
四、总结与收获
学习Python数据分析是一段充满挑战与收获的旅程。通过这段学习,我深入理解了数据分析的核心理念,并掌握了使用Python进行数据清洗、处理和可视化的基本方法。
在学习的过程中,我感受到了Python在数据处理方面的强大能力。Pandas库提供了丰富的数据处理函数,让我能够轻松应对各种数据问题。同时,Matplotlib和Seaborn库则帮助我将数据以直观、清晰的方式呈现出来。
然而,学习之路并非一帆风顺。在处理复杂数据时,我遇到了许多难题,如数据缺失、异常值等。但通过不断尝试和探索,我逐渐找到了解决问题的方法。这些经历不仅锻炼了我的思维能力,也让我更加珍惜每一次的学习机会。
总的来说,学习Python数据分析让我更加深刻地认识到数据的重要性,并激发了我对数据科学的兴趣。我相信,在未来的学习和工作中,我会继续深入学习数据分析的知识,不断提高自己的技能水平,为数据驱动决策贡献自己的力量。















 927
927

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









