






过程参考大佬:深度学习:使用UNet做图像语义分割,训练自己制作的数据集并推理测试(详细图文教程)_图像分割训练自己的数据集-CSDN博客
项目目录
一.准备环境和包
- 下载labelme
labelme的安装及使用_labelme安装-CSDN博客
发现错误,降低pyqt5版本
pip install labelme
打开cmd后激活虚拟环境
activate labelme
然后输入打开软件
labelme
寻找环境位置,
conda env list会出现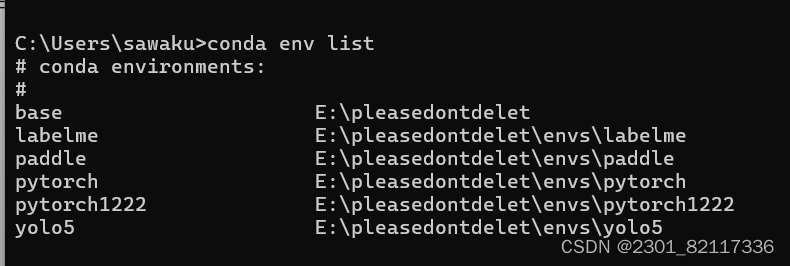
换一个专用于unet的自己的环境,防止不同深度学习算法冲突(后来还是用了labelme)
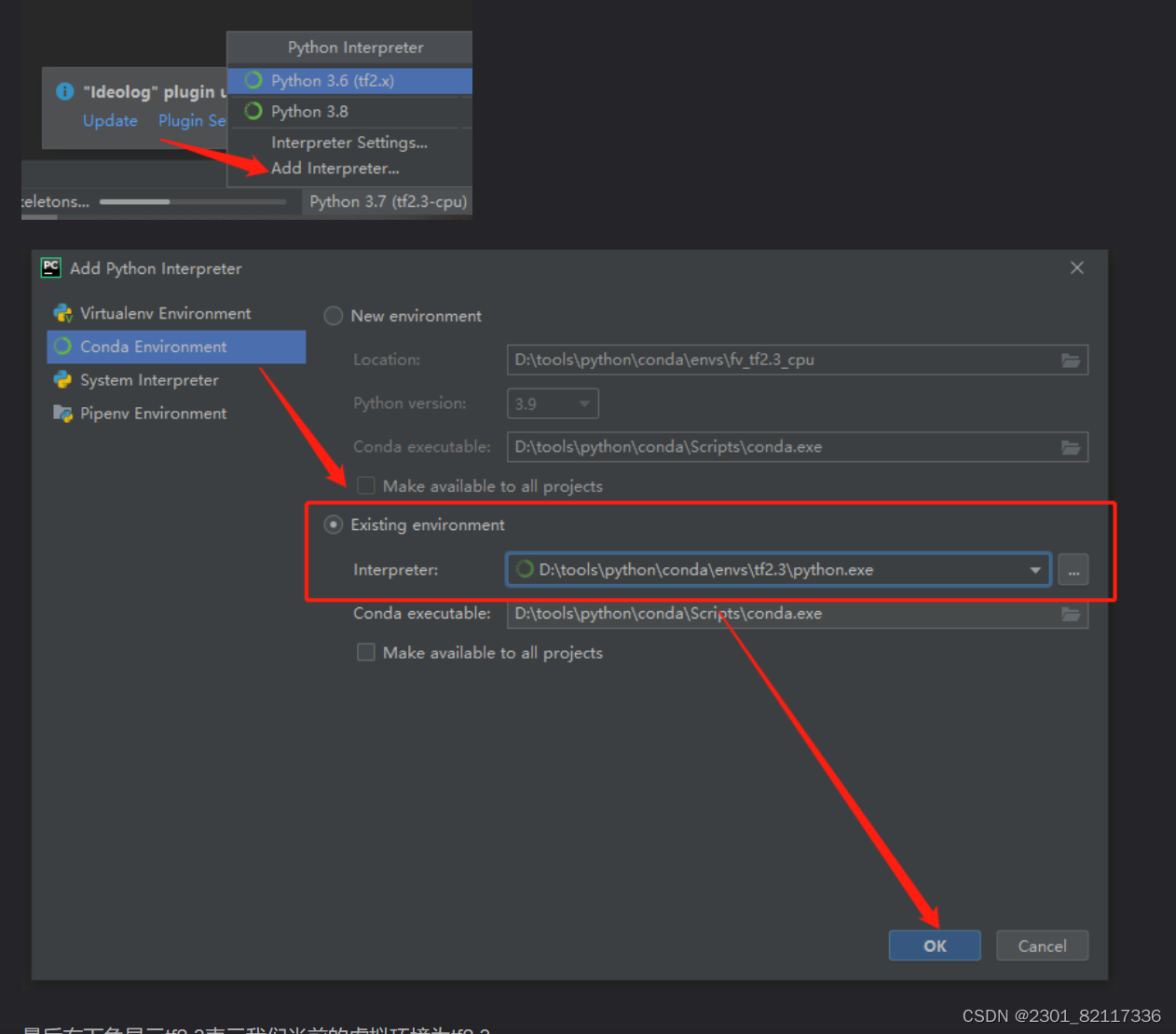
开始打标签,打了三天才十几张,决定数据增强
二.数据增强
数据增强代码:(记得在main改路径)
import os
import numpy as np
from PIL import Image
from imgaug import augmenters as iaa
import imgaug as ia
import shutil
def augment_images_and_masks(image_dir, mask_dir, augmented_image_dir, augmented_mask_dir, num_augments=5):
# 确保输出目录存在
os.makedirs(augmented_image_dir, exist_ok=True)
os.makedirs(augmented_mask_dir, exist_ok=True)
# 定义增强序列
seq = iaa.Sequential([
iaa.Flipud(0.5), # 垂直翻转
iaa.Fliplr(0.5), # 水平翻转
iaa.Affine(
scale={"x": (0.8, 1.2), "y": (0.8, 1.2)},
translate_percent={"x": (-0.2, 0.2), "y": (-0.2, 0.2)},
rotate=(-25, 25),
shear=(-8, 8)
),
iaa.GaussianBlur(sigma=(0, 3.0)) # 高斯模糊
])
for filename in os.listdir(image_dir):
if filename.endswith(".jpg"):
# 读取图片和掩膜
img_path = os.path.join(image_dir, filename)
mask_path = os.path.join(mask_dir, filename.replace('.jpg', '.png'))
img = np.array(Image.open(img_path))
mask = np.array(Image.open(mask_path))
# 对每个图像进行增强
for i in range(num_augments):
seq_det = seq.to_deterministic() # 确保图像和掩膜使用相同的变换
image_aug = seq_det.augment_image(img)
mask_aug = seq_det.augment_image(mask)
# 保存增强后的图像和掩膜
Image.fromarray(image_aug).save(os.path.join(augmented_image_dir, f"aug_{i}_{filename}"))
Image.fromarray(mask_aug).save(os.path.join(augmented_mask_dir, f"aug_{i}_{filename.replace('.jpg', '.png')}"))
if __name__ == "__main__":
IMG_DIR = "E:/UNet_Demo/VOCdevkit/VOC2007/JPEGImages"
MASK_DIR = "E:/UNet_Demo/VOCdevkit/VOC2007/SegmentationClass"
AUG_IMG_DIR = "E:/UNet_Demo/VOCdevkit/VOC2007/Augmented/JPEGImages"
AUG_MASK_DIR = "E:/UNet_Demo/VOCdevkit/VOC2007/Augmented/SegmentationClass"
augment_images_and_masks(IMG_DIR, MASK_DIR, AUG_IMG_DIR, AUG_MASK_DIR)
增强完的png图片是黑色的,要将灰度图改为彩色图(这一步可以不要,做完发现大佬的train文件里面贴心的设置了灰度图转换彩色图) gray2pseudo_color.py
import base64
import json
import os
import os.path as osp
import numpy as np
import PIL.Image
from labelme import utils
'''
制作自己的语义分割数据集需要注意以下几点:
1、我使用的labelme版本是3.16.7,建议使用该版本的labelme,有些版本的labelme会发生错误,
具体错误为:Too many dimensions: 3 > 2
安装方式为命令行pip install labelme==3.16.7
2、此处生成的标签图是8位彩色图,与视频中看起来的数据集格式不太一样。
虽然看起来是彩图,但事实上只有8位,此时每个像素点的值就是这个像素点所属的种类。
所以其实和视频中VOC数据集的格式一样。因此这样制作出来的数据集是可以正常使用的。也是正常的。
'''
if __name__ == '__main__':
jpgs_path = "E:/UNet_Demo/datasets/before"
pngs_path = "E:/UNet_Demo/datasets/SegmentationClass"
classes = ["_background_","leaf", "spots", ]
# classes = ["_background_","cat"]
count = os.listdir("./datasets/before/")
for i in range(0, len(count)):
path = os.path.join("./datasets/before", count[i])
if os.path.isfile(path) and path.endswith('json'):
data = json.load(open(path))
if data['imageData']:
imageData = data['imageData']
else:
imagePath = os.path.join(os.path.dirname(path), data['imagePath'])
with open(imagePath, 'rb') as f:
imageData = f.read()
imageData = base64.b64encode(imageData).decode('utf-8')
img = utils.img_b64_to_arr(imageData)
label_name_to_value = {'_background_': 0}
for shape in data['shapes']:
label_name = shape['label']
if label_name in label_name_to_value:
label_value = label_name_to_value[label_name]
else:
label_value = len(label_name_to_value)
label_name_to_value[label_name] = label_value
# label_values must be dense
label_values, label_names = [], []
for ln, lv in sorted(label_name_to_value.items(), key=lambda x: x[1]):
label_values.append(lv)
label_names.append(ln)
assert label_values == list(range(len(label_values)))
lbl = utils.shapes_to_label(img.shape, data['shapes'], label_name_to_value)
PIL.Image.fromarray(img).save(osp.join(jpgs_path, count[i].split(".")[0]+'.png'))
new = np.zeros([np.shape(img)[0],np.shape(img)[1]])
for name in label_names:
index_json = label_names.index(name)
index_all = classes.index(name)
new = new + index_all*(np.array(lbl) == index_json)
# utils.lblsave(osp.join(pngs_path, count[i].split(".")[0]+'.png'), new)
# print('Saved ' + count[i].split(".")[0] + '.jpg and ' + count[i].split(".")[0] + '.png')
utils.lblsave(osp.join(pngs_path, count[i].split(".")[0] + '.png'), new)
print('Saved ' + count[i].split(".")[0] + '.jpg and ' + count[i].split(".")[0] + '.png')
在终端使用运行即可
python gray2pseudo_color.py E:\UNet_Demo\VOCdevkit\VOC2007\Augmented\SegmentationClass E:\UNet_Demo\VOCdevkit\VOC2007\Augmented\SegmentationClass2
完成后把Segmentation2图片复制到原来Segmentation文件夹下,运行Voc进行划分训练集和测试集
然后开始train,问题来了,我一点击train电脑就卡死,卸载几遍都没用,然后重新找了一个大佬的复现过程,发现其实是同一个包。【语义分割实战(1)】U-Net语义分割:训练自己的数据集_u-net 训练自己的数据集 csdn-CSDN博客
三.训练
最终train采用这个,用的CPU训练,因为用GPU训练报错没有CUDA,不知道怎么解决。
import datetime
import os
from functools import partial
import numpy as np
import torch
import torch.backends.cudnn as cudnn
import torch.distributed as dist
import torch.optim as optim
from torch.utils.data import DataLoader
from nets.unet import Unet
from nets.unet_training import get_lr_scheduler, set_optimizer_lr, weights_init
from utils.callbacks import EvalCallback, LossHistory
from utils.dataloader import UnetDataset, unet_dataset_collate
from utils.utils import (download_weights, seed_everything, show_config,
worker_init_fn)
from utils.utils_fit import fit_one_epoch
'''
训练自己的语义分割模型一定需要注意以下几点:
1、训练前仔细检查自己的格式是否满足要求,该库要求数据集格式为VOC格式,需要准备好的内容有输入图片和标签
输入图片为.jpg图片,无需固定大小,传入训练前会自动进行resize。
灰度图会自动转成RGB图片进行训练,无需自己修改。
输入图片如果后缀非jpg,需要自己批量转成jpg后再开始训练。
标签为png图片,无需固定大小,传入训练前会自动进行resize。
由于许多同学的数据集是网络上下载的,标签格式并不符合,需要再度处理。一定要注意!标签的每个像素点的值就是这个像素点所属的种类。
网上常见的数据集总共对输入图片分两类,背景的像素点值为0,目标的像素点值为255。这样的数据集可以正常运行但是预测是没有效果的!
需要改成,背景的像素点值为0,目标的像素点值为1。
如果格式有误,参考:https://github.com/bubbliiiing/segmentation-format-fix
2、损失值的大小用于判断是否收敛,比较重要的是有收敛的趋势,即验证集损失不断下降,如果验证集损失基本上不改变的话,模型基本上就收敛了。
损失值的具体大小并没有什么意义,大和小只在于损失的计算方式,并不是接近于0才好。如果想要让损失好看点,可以直接到对应的损失函数里面除上10000。
训练过程中的损失值会保存在logs文件夹下的loss_%Y_%m_%d_%H_%M_%S文件夹中
3、训练好的权值文件保存在logs文件夹中,每个训练世代(Epoch)包含若干训练步长(Step),每个训练步长(Step)进行一次梯度下降。
如果只是训练了几个Step是不会保存的,Epoch和Step的概念要捋清楚一下。
'''
if __name__ == "__main__":
#---------------------------------#
# Cuda 是否使用Cuda
# 没有GPU可以设置成False
#---------------------------------#
Cuda = False
#----------------------------------------------#
# Seed 用于固定随机种子
# 使得每次独立训练都可以获得一样的结果
#----------------------------------------------#
seed = 11
#---------------------------------------------------------------------#
# distributed 用于指定是否使用单机多卡分布式运行
# 终端指令仅支持Ubuntu。CUDA_VISIBLE_DEVICES用于在Ubuntu下指定显卡。
# Windows系统下默认使用DP模式调用所有显卡,不支持DDP。
# DP模式:
# 设置 distributed = False
# 在终端中输入 CUDA_VISIBLE_DEVICES=0,1 python train.py
# DDP模式:
# 设置 distributed = True
# 在终端中输入 CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch --nproc_per_node=2 train.py
#---------------------------------------------------------------------#
distributed = False
#---------------------------------------------------------------------#
# sync_bn 是否使用sync_bn,DDP模式多卡可用
#---------------------------------------------------------------------#
sync_bn = False
#---------------------------------------------------------------------#
# fp16 是否使用混合精度训练
# 可减少约一半的显存、需要pytorch1.7.1以上
#---------------------------------------------------------------------#
fp16 = False
#-----------------------------------------------------#
# num_classes 训练自己的数据集必须要修改的
# 自己需要的分类个数+1,如2+1
#-----------------------------------------------------#
num_classes = 3
#-----------------------------------------------------#
# 主干网络选择
# vgg
# resnet50
#-----------------------------------------------------#
backbone = "vgg"
#----------------------------------------------------------------------------------------------------------------------------#
# pretrained 是否使用主干网络的预训练权重,此处使用的是主干的权重,因此是在模型构建的时候进行加载的。
# 如果设置了model_path,则主干的权值无需加载,pretrained的值无意义。
# 如果不设置model_path,pretrained = True,此时仅加载主干开始训练。
# 如果不设置model_path,pretrained = False,Freeze_Train = Fasle,此时从0开始训练,且没有冻结主干的过程。
#----------------------------------------------------------------------------------------------------------------------------#
pretrained = True
#----------------------------------------------------------------------------------------------------------------------------#
# 权值文件的下载请看README,可以通过网盘下载。模型的 预训练权重 对不同数据集是通用的,因为特征是通用的。
# 模型的 预训练权重 比较重要的部分是 主干特征提取网络的权值部分,用于进行特征提取。
# 预训练权重对于99%的情况都必须要用,不用的话主干部分的权值太过随机,特征提取效果不明显,网络训练的结果也不会好
# 训练自己的数据集时提示维度不匹配正常,预测的东西都不一样了自然维度不匹配
#
# 如果训练过程中存在中断训练的操作,可以将model_path设置成logs文件夹下的权值文件,将已经训练了一部分的权值再次载入。
# 同时修改下方的 冻结阶段 或者 解冻阶段 的参数,来保证模型epoch的连续性。
#
# 当model_path = ''的时候不加载整个模型的权值。
#
# 此处使用的是整个模型的权重,因此是在train.py进行加载的,pretrain不影响此处的权值加载。
# 如果想要让模型从主干的预训练权值开始训练,则设置model_path = '',pretrain = True,此时仅加载主干。
# 如果想要让模型从0开始训练,则设置model_path = '',pretrain = Fasle,Freeze_Train = Fasle,此时从0开始训练,且没有冻结主干的过程。
#
# 一般来讲,网络从0开始的训练效果会很差,因为权值太过随机,特征提取效果不明显,因此非常、非常、非常不建议大家从0开始训练!
# 如果一定要从0开始,可以了解imagenet数据集,首先训练分类模型,获得网络的主干部分权值,分类模型的 主干部分 和该模型通用,基于此进行训练。
#----------------------------------------------------------------------------------------------------------------------------#
model_path = ""
#-----------------------------------------------------#
# input_shape 输入图片的大小,32的倍数
#-----------------------------------------------------#
input_shape = [512, 512]
#----------------------------------------------------------------------------------------------------------------------------#
# 训练分为两个阶段,分别是冻结阶段和解冻阶段。设置冻结阶段是为了满足机器性能不足的同学的训练需求。
# 冻结训练需要的显存较小,显卡非常差的情况下,可设置Freeze_Epoch等于UnFreeze_Epoch,此时仅仅进行冻结训练。
#
# 在此提供若干参数设置建议,各位训练者根据自己的需求进行灵活调整:
# (一)从整个模型的预训练权重开始训练:
# Adam:
# Init_Epoch = 0,Freeze_Epoch = 50,UnFreeze_Epoch = 100,Freeze_Train = True,optimizer_type = 'adam',Init_lr = 1e-4,weight_decay = 0。(冻结)
# Init_Epoch = 0,UnFreeze_Epoch = 100,Freeze_Train = False,optimizer_type = 'adam',Init_lr = 1e-4,weight_decay = 0。(不冻结)
# SGD:
# Init_Epoch = 0,Freeze_Epoch = 50,UnFreeze_Epoch = 100,Freeze_Train = True,optimizer_type = 'sgd',Init_lr = 1e-2,weight_decay = 1e-4。(冻结)
# Init_Epoch = 0,UnFreeze_Epoch = 100,Freeze_Train = False,optimizer_type = 'sgd',Init_lr = 1e-2,weight_decay = 1e-4。(不冻结)
# 其中:UnFreeze_Epoch可以在100-300之间调整。
# (二)从主干网络的预训练权重开始训练:
# Adam:
# Init_Epoch = 0,Freeze_Epoch = 50,UnFreeze_Epoch = 100,Freeze_Train = True,optimizer_type = 'adam',Init_lr = 1e-4,weight_decay = 0。(冻结)
# Init_Epoch = 0,UnFreeze_Epoch = 100,Freeze_Train = False,optimizer_type = 'adam',Init_lr = 1e-4,weight_decay = 0。(不冻结)
# SGD:
# Init_Epoch = 0,Freeze_Epoch = 50,UnFreeze_Epoch = 120,Freeze_Train = True,optimizer_type = 'sgd',Init_lr = 1e-2,weight_decay = 1e-4。(冻结)
# Init_Epoch = 0,UnFreeze_Epoch = 120,Freeze_Train = False,optimizer_type = 'sgd',Init_lr = 1e-2,weight_decay = 1e-4。(不冻结)
# 其中:由于从主干网络的预训练权重开始训练,主干的权值不一定适合语义分割,需要更多的训练跳出局部最优解。
# UnFreeze_Epoch可以在120-300之间调整。
# Adam相较于SGD收敛的快一些。因此UnFreeze_Epoch理论上可以小一点,但依然推荐更多的Epoch。
# (三)batch_size的设置:
# 在显卡能够接受的范围内,以大为好。显存不足与数据集大小无关,提示显存不足(OOM或者CUDA out of memory)请调小batch_size。
# 由于resnet50中有BatchNormalization层
# 当主干为resnet50的时候batch_size不可为1
# 正常情况下Freeze_batch_size建议为Unfreeze_batch_size的1-2倍。不建议设置的差距过大,因为关系到学习率的自动调整。
#----------------------------------------------------------------------------------------------------------------------------#
#------------------------------------------------------------------#
# 冻结阶段训练参数
# 此时模型的主干被冻结了,特征提取网络不发生改变
# 占用的显存较小,仅对网络进行微调
# Init_Epoch 模型当前开始的训练世代,其值可以大于Freeze_Epoch,如设置:
# Init_Epoch = 60、Freeze_Epoch = 50、UnFreeze_Epoch = 100
# 会跳过冻结阶段,直接从60代开始,并调整对应的学习率。
# (断点续练时使用)
# Freeze_Epoch 模型冻结训练的Freeze_Epoch
# (当Freeze_Train=False时失效)
# Freeze_batch_size 模型冻结训练的batch_size
# (当Freeze_Train=False时失效)
#------------------------------------------------------------------#
Init_Epoch = 0
Freeze_Epoch = 50
Freeze_batch_size = 2
#------------------------------------------------------------------#
# 解冻阶段训练参数
# 此时模型的主干不被冻结了,特征提取网络会发生改变
# 占用的显存较大,网络所有的参数都会发生改变
# UnFreeze_Epoch 模型总共训练的epoch
# Unfreeze_batch_size 模型在解冻后的batch_size
#------------------------------------------------------------------#
UnFreeze_Epoch = 100
Unfreeze_batch_size = 2
#------------------------------------------------------------------#
# Freeze_Train 是否进行冻结训练
# 默认先冻结主干训练后解冻训练。
#------------------------------------------------------------------#
Freeze_Train = True
#------------------------------------------------------------------#
# 其它训练参数:学习率、优化器、学习率下降有关
#------------------------------------------------------------------#
#------------------------------------------------------------------#
# Init_lr 模型的最大学习率
# 当使用Adam优化器时建议设置 Init_lr=1e-4
# 当使用SGD优化器时建议设置 Init_lr=1e-2
# Min_lr 模型的最小学习率,默认为最大学习率的0.01
#------------------------------------------------------------------#
Init_lr = 1e-4
Min_lr = Init_lr * 0.01
#------------------------------------------------------------------#
# optimizer_type 使用到的优化器种类,可选的有adam、sgd
# 当使用Adam优化器时建议设置 Init_lr=1e-4
# 当使用SGD优化器时建议设置 Init_lr=1e-2
# momentum 优化器内部使用到的momentum参数
# weight_decay 权值衰减,可防止过拟合
# adam会导致weight_decay错误,使用adam时建议设置为0。
#------------------------------------------------------------------#
optimizer_type = "adam"
momentum = 0.9
weight_decay = 0
#------------------------------------------------------------------#
# lr_decay_type 使用到的学习率下降方式,可选的有'step'、'cos'
#------------------------------------------------------------------#
lr_decay_type = 'cos'
#------------------------------------------------------------------#
# save_period 多少个epoch保存一次权值
#------------------------------------------------------------------#
save_period = 5
#------------------------------------------------------------------#
# save_dir 权值与日志文件保存的文件夹
#------------------------------------------------------------------#
save_dir = 'logs'
#------------------------------------------------------------------#
# eval_flag 是否在训练时进行评估,评估对象为验证集
# eval_period 代表多少个epoch评估一次,不建议频繁的评估
# 评估需要消耗较多的时间,频繁评估会导致训练非常慢
# 此处获得的mAP会与get_map.py获得的会有所不同,原因有二:
# (一)此处获得的mAP为验证集的mAP。
# (二)此处设置评估参数较为保守,目的是加快评估速度。
#------------------------------------------------------------------#
eval_flag = True
eval_period = 5
#------------------------------#
# 数据集路径
#------------------------------#
VOCdevkit_path = 'VOCdevkit'
#------------------------------------------------------------------#
# 建议选项:
# 种类少(几类)时,设置为True
# 种类多(十几类)时,如果batch_size比较大(10以上),那么设置为True
# 种类多(十几类)时,如果batch_size比较小(10以下),那么设置为False
#------------------------------------------------------------------#
dice_loss = False
#------------------------------------------------------------------#
# 是否使用focal loss来防止正负样本不平衡
#------------------------------------------------------------------#
focal_loss = False
#------------------------------------------------------------------#
# 是否给不同种类赋予不同的损失权值,默认是平衡的。
# 设置的话,注意设置成numpy形式的,长度和num_classes一样。
# 如:
# num_classes = 3
# cls_weights = np.array([1, 2, 3], np.float32)
#------------------------------------------------------------------#
cls_weights = np.ones([num_classes], np.float32)
#------------------------------------------------------------------#
# num_workers 用于设置是否使用多线程读取数据,1代表关闭多线程
# 开启后会加快数据读取速度,但是会占用更多内存
# keras里开启多线程有些时候速度反而慢了许多
# 在IO为瓶颈的时候再开启多线程,即GPU运算速度远大于读取图片的速度。
#------------------------------------------------------------------#
num_workers = 4
seed_everything(seed)
#------------------------------------------------------#
# 设置用到的显卡
#------------------------------------------------------#
ngpus_per_node = torch.cuda.device_count()
if distributed:
dist.init_process_group(backend="nccl")
local_rank = int(os.environ["LOCAL_RANK"])
rank = int(os.environ["RANK"])
device = torch.device("cuda", local_rank)
if local_rank == 0:
print(f"[{os.getpid()}] (rank = {rank}, local_rank = {local_rank}) training...")
print("Gpu Device Count : ", ngpus_per_node)
else:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
local_rank = 0
rank = 0
#----------------------------------------------------#
# 下载预训练权重
#----------------------------------------------------#
if pretrained:
if distributed:
if local_rank == 0:
download_weights(backbone)
dist.barrier()
else:
download_weights(backbone)
model = Unet(num_classes=num_classes, pretrained=pretrained, backbone=backbone).train()
if not pretrained:
weights_init(model)
if model_path != '':
#------------------------------------------------------#
# 权值文件请看README,百度网盘下载
#------------------------------------------------------#
if local_rank == 0:
print('Load weights {}.'.format(model_path))
#------------------------------------------------------#
# 根据预训练权重的Key和模型的Key进行加载
#------------------------------------------------------#
model_dict = model.state_dict()
pretrained_dict = torch.load(model_path, map_location = device)
load_key, no_load_key, temp_dict = [], [], {}
for k, v in pretrained_dict.items():
if k in model_dict.keys() and np.shape(model_dict[k]) == np.shape(v):
temp_dict[k] = v
load_key.append(k)
else:
no_load_key.append(k)
model_dict.update(temp_dict)
model.load_state_dict(model_dict)
#------------------------------------------------------#
# 显示没有匹配上的Key
#------------------------------------------------------#
if local_rank == 0:
print("\nSuccessful Load Key:", str(load_key)[:500], "……\nSuccessful Load Key Num:", len(load_key))
print("\nFail To Load Key:", str(no_load_key)[:500], "……\nFail To Load Key num:", len(no_load_key))
print("\n\033[1;33;44m温馨提示,head部分没有载入是正常现象,Backbone部分没有载入是错误的。\033[0m")
#----------------------#
# 记录Loss
#----------------------#
if local_rank == 0:
time_str = datetime.datetime.strftime(datetime.datetime.now(),'%Y_%m_%d_%H_%M_%S')
log_dir = os.path.join(save_dir, "loss_" + str(time_str))
loss_history = LossHistory(log_dir, model, input_shape=input_shape)
else:
loss_history = None
#------------------------------------------------------------------#
# torch 1.2不支持amp,建议使用torch 1.7.1及以上正确使用fp16
# 因此torch1.2这里显示"could not be resolve"
#------------------------------------------------------------------#
if fp16:
from torch.cuda.amp import GradScaler as GradScaler
scaler = GradScaler()
else:
scaler = None
model_train = model.train()
#----------------------------#
# 多卡同步Bn
#----------------------------#
if sync_bn and ngpus_per_node > 1 and distributed:
model_train = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model_train)
elif sync_bn:
print("Sync_bn is not support in one gpu or not distributed.")
if Cuda:
if distributed:
#----------------------------#
# 多卡平行运行
#----------------------------#
model_train = model_train.cuda(local_rank)
model_train = torch.nn.parallel.DistributedDataParallel(model_train, device_ids=[local_rank], find_unused_parameters=True)
else:
model_train = torch.nn.DataParallel(model)
cudnn.benchmark = True
model_train = model_train.cuda()
#---------------------------#
# 读取数据集对应的txt
#---------------------------#
with open(os.path.join(VOCdevkit_path, "VOC2007/ImageSets/Segmentation/train.txt"),"r") as f:
train_lines = f.readlines()
with open(os.path.join(VOCdevkit_path, "VOC2007/ImageSets/Segmentation/val.txt"),"r") as f:
val_lines = f.readlines()
num_train = len(train_lines)
num_val = len(val_lines)
if local_rank == 0:
show_config(
num_classes = num_classes, backbone = backbone, model_path = model_path, input_shape = input_shape, \
Init_Epoch = Init_Epoch, Freeze_Epoch = Freeze_Epoch, UnFreeze_Epoch = UnFreeze_Epoch, Freeze_batch_size = Freeze_batch_size, Unfreeze_batch_size = Unfreeze_batch_size, Freeze_Train = Freeze_Train, \
Init_lr = Init_lr, Min_lr = Min_lr, optimizer_type = optimizer_type, momentum = momentum, lr_decay_type = lr_decay_type, \
save_period = save_period, save_dir = save_dir, num_workers = num_workers, num_train = num_train, num_val = num_val
)
#------------------------------------------------------#
# 主干特征提取网络特征通用,冻结训练可以加快训练速度
# 也可以在训练初期防止权值被破坏。
# Init_Epoch为起始世代
# Interval_Epoch为冻结训练的世代
# Epoch总训练世代
# 提示OOM或者显存不足请调小Batch_size
#------------------------------------------------------#
if True:
UnFreeze_flag = False
#------------------------------------#
# 冻结一定部分训练
#------------------------------------#
if Freeze_Train:
model.freeze_backbone()
#-------------------------------------------------------------------#
# 如果不冻结训练的话,直接设置batch_size为Unfreeze_batch_size
#-------------------------------------------------------------------#
batch_size = Freeze_batch_size if Freeze_Train else Unfreeze_batch_size
#-------------------------------------------------------------------#
# 判断当前batch_size,自适应调整学习率
#-------------------------------------------------------------------#
nbs = 16
lr_limit_max = 1e-4 if optimizer_type == 'adam' else 1e-1
lr_limit_min = 1e-4 if optimizer_type == 'adam' else 5e-4
Init_lr_fit = min(max(batch_size / nbs * Init_lr, lr_limit_min), lr_limit_max)
Min_lr_fit = min(max(batch_size / nbs * Min_lr, lr_limit_min * 1e-2), lr_limit_max * 1e-2)
#---------------------------------------#
# 根据optimizer_type选择优化器
#---------------------------------------#
optimizer = {
'adam' : optim.Adam(model.parameters(), Init_lr_fit, betas = (momentum, 0.999), weight_decay = weight_decay),
'sgd' : optim.SGD(model.parameters(), Init_lr_fit, momentum = momentum, nesterov=True, weight_decay = weight_decay)
}[optimizer_type]
#---------------------------------------#
# 获得学习率下降的公式
#---------------------------------------#
lr_scheduler_func = get_lr_scheduler(lr_decay_type, Init_lr_fit, Min_lr_fit, UnFreeze_Epoch)
#---------------------------------------#
# 判断每一个世代的长度
#---------------------------------------#
epoch_step = num_train // batch_size
epoch_step_val = num_val // batch_size
if epoch_step == 0 or epoch_step_val == 0:
raise ValueError("数据集过小,无法继续进行训练,请扩充数据集。")
train_dataset = UnetDataset(train_lines, input_shape, num_classes, True, VOCdevkit_path)
val_dataset = UnetDataset(val_lines, input_shape, num_classes, False, VOCdevkit_path)
if distributed:
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset, shuffle=True,)
val_sampler = torch.utils.data.distributed.DistributedSampler(val_dataset, shuffle=False,)
batch_size = batch_size // ngpus_per_node
shuffle = False
else:
train_sampler = None
val_sampler = None
shuffle = True
gen = DataLoader(train_dataset, shuffle = shuffle, batch_size = batch_size, num_workers = num_workers, pin_memory=True,
drop_last = True, collate_fn = unet_dataset_collate, sampler=train_sampler,
worker_init_fn=partial(worker_init_fn, rank=rank, seed=seed))
gen_val = DataLoader(val_dataset , shuffle = shuffle, batch_size = batch_size, num_workers = num_workers, pin_memory=True,
drop_last = True, collate_fn = unet_dataset_collate, sampler=val_sampler,
worker_init_fn=partial(worker_init_fn, rank=rank, seed=seed))
#----------------------#
# 记录eval的map曲线
#----------------------#
if local_rank == 0:
eval_callback = EvalCallback(model, input_shape, num_classes, val_lines, VOCdevkit_path, log_dir, Cuda, \
eval_flag=eval_flag, period=eval_period)
else:
eval_callback = None
#---------------------------------------#
# 开始模型训练
#---------------------------------------#
for epoch in range(Init_Epoch, UnFreeze_Epoch):
#---------------------------------------#
# 如果模型有冻结学习部分
# 则解冻,并设置参数
#---------------------------------------#
if epoch >= Freeze_Epoch and not UnFreeze_flag and Freeze_Train:
batch_size = Unfreeze_batch_size
#-------------------------------------------------------------------#
# 判断当前batch_size,自适应调整学习率
#-------------------------------------------------------------------#
nbs = 16
lr_limit_max = 1e-4 if optimizer_type == 'adam' else 1e-1
lr_limit_min = 1e-4 if optimizer_type == 'adam' else 5e-4
Init_lr_fit = min(max(batch_size / nbs * Init_lr, lr_limit_min), lr_limit_max)
Min_lr_fit = min(max(batch_size / nbs * Min_lr, lr_limit_min * 1e-2), lr_limit_max * 1e-2)
#---------------------------------------#
# 获得学习率下降的公式
#---------------------------------------#
lr_scheduler_func = get_lr_scheduler(lr_decay_type, Init_lr_fit, Min_lr_fit, UnFreeze_Epoch)
model.unfreeze_backbone()
epoch_step = num_train // batch_size
epoch_step_val = num_val // batch_size
if epoch_step == 0 or epoch_step_val == 0:
raise ValueError("数据集过小,无法继续进行训练,请扩充数据集。")
if distributed:
batch_size = batch_size // ngpus_per_node
gen = DataLoader(train_dataset, shuffle = shuffle, batch_size = batch_size, num_workers = num_workers, pin_memory=True,
drop_last = True, collate_fn = unet_dataset_collate, sampler=train_sampler,
worker_init_fn=partial(worker_init_fn, rank=rank, seed=seed))
gen_val = DataLoader(val_dataset , shuffle = shuffle, batch_size = batch_size, num_workers = num_workers, pin_memory=True,
drop_last = True, collate_fn = unet_dataset_collate, sampler=val_sampler,
worker_init_fn=partial(worker_init_fn, rank=rank, seed=seed))
UnFreeze_flag = True
if distributed:
train_sampler.set_epoch(epoch)
set_optimizer_lr(optimizer, lr_scheduler_func, epoch)
fit_one_epoch(model_train, model, loss_history, eval_callback, optimizer, epoch,
epoch_step, epoch_step_val, gen, gen_val, UnFreeze_Epoch, Cuda, dice_loss, focal_loss, cls_weights, num_classes, fp16, scaler, save_period, save_dir, local_rank)
if distributed:
dist.barrier()
if local_rank == 0:
loss_history.writer.close()
成功训练上了!
四.复现
修改mod=xxx(切换不同模式)

我修改了unet.py里面的def detect_image段落,使得最终面积计算是sopts/leaf。
def detect_image(self, image, count=False, name_classes=None, display_ratio=False):
# 转换图像为RGB格式,防止灰度图在预测时出错
image = cvtColor(image)
old_img = copy.deepcopy(image)
orininal_h, orininal_w = np.array(image).shape[:2]
# 调整图像大小并添加batch维度
image_data, nw, nh = resize_image(image, (self.input_shape[1], self.input_shape[0]))
image_data = np.expand_dims(np.transpose(preprocess_input(np.array(image_data, np.float32)), (2, 0, 1)), 0)
with torch.no_grad():
images = torch.from_numpy(image_data)
if self.cuda:
images = images.cuda()
# 用网络进行预测
pr = self.net(images)[0]
pr = F.softmax(pr.permute(1, 2, 0), dim=-1).cpu().numpy()
pr = pr[int((self.input_shape[0] - nh) // 2): int((self.input_shape[0] - nh) // 2 + nh),
int((self.input_shape[1] - nw) // 2): int((self.input_shape[1] - nw) // 2 + nw)]
pr = cv2.resize(pr, (orininal_w, orininal_h), interpolation=cv2.INTER_LINEAR)
pr = pr.argmax(axis=-1)
# 计算类别像素点数量
if count:
classes_nums = np.zeros([self.num_classes])
total_points_num = orininal_h * orininal_w
leaf_pixels = np.sum(pr == 1)
spots_pixels = np.sum(pr == 2)
if leaf_pixels > 0:
ratio = spots_pixels / leaf_pixels
ratio_text = f"Area ratio of spots to leaf: {ratio:.3f}"
if display_ratio:
cv2.putText(image, ratio_text, (50, 50), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0), 2)
print(ratio_text)
else:
print("No leaf detected, cannot compute ratio.")
# 可视化
if self.mix_type == 0:
seg_img = np.reshape(np.array(self.colors, np.uint8)[np.reshape(pr, [-1])], [orininal_h, orininal_w, -1])
image = Image.fromarray(np.uint8(seg_img))
image = Image.blend(old_img, image, 0.7)
elif self.mix_type == 1:
seg_img = np.reshape(np.array(self.colors, np.uint8)[np.reshape(pr, [-1])], [orininal_h, orininal_w, -1])
image = Image.fromarray(np.uint8(seg_img))
elif self.mix_type == 2:
seg_img = (np.expand_dims(pr != 0, -1) * np.array(old_img, np.float32)).astype('uint8')
image = Image.fromarray(np.uint8(seg_img))
return image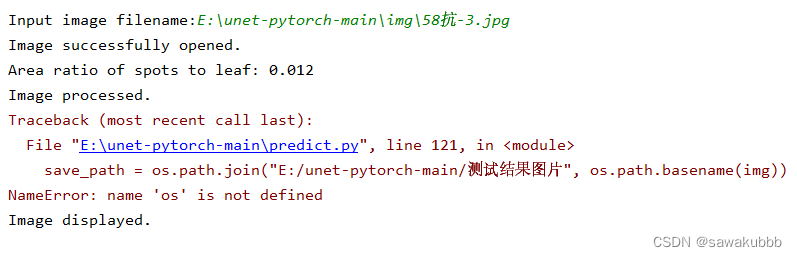















 2281
2281

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









