







※ 这是学习 B站博主霹雳吧啦Wz 的 深度学习-语义分割篇-使用PyTorch搭建U-Net网络并基于DRIVE数据集训练视频 所做的笔记。
前言
1.文件结构
├── src: 搭建U-Net模型代码
├── train_utils: 训练、验证以及多GPU训练相关模块
├── my_dataset.py: 自定义dataset用于读取DRIVE数据集(视网膜血管分割)
├── train.py: 以单GPU为例进行训练
├── train_multi_GPU.py: 针对使用多GPU的用户使用
├── predict.py: 简易的预测脚本,使用训练好的权重进行预测测试
└── compute_mean_std.py: 统计数据集各通道的均值和标准差
2.DRIVE数据集下载地址
- 官网地址: Introduction - Grand Challenge
- 百度云链接: 百度网盘 请输入提取码 密码: 8no8
正文
一、网络的搭建
1. 数据集下载
前言里面给出的两种下载方式,官网需要注册,所以百度云链接下载更加方便。
将数据集放入unet文件夹里面。(unet 文件夹是我自己新建文件夹,重新命名的,你的可能不叫unet)
注意:由于我们的这个训练脚本里默认位置是当前目录,所以如果你把数据集放在了别的位置,记得要把这里 train.py 中的 data path 修改成称自己解压数据集所在的目录。
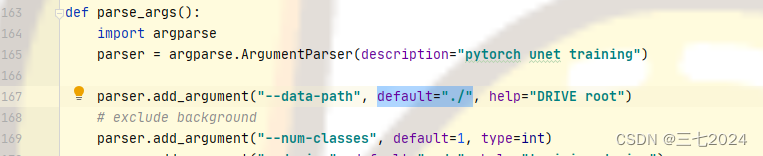
下面我们看一下这个数据集:

在这个数据集里面有训练集和测试集,在训练集里面又有 images 和 mask还有1st_manual。
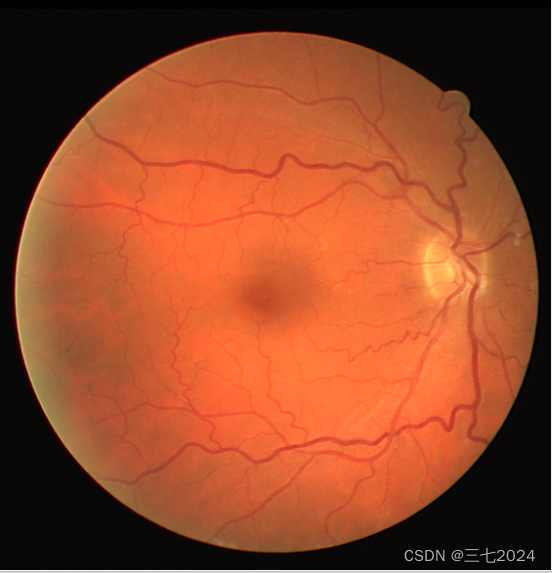
images 中每一张图片就是一个用于分割的原图片,例如下图:
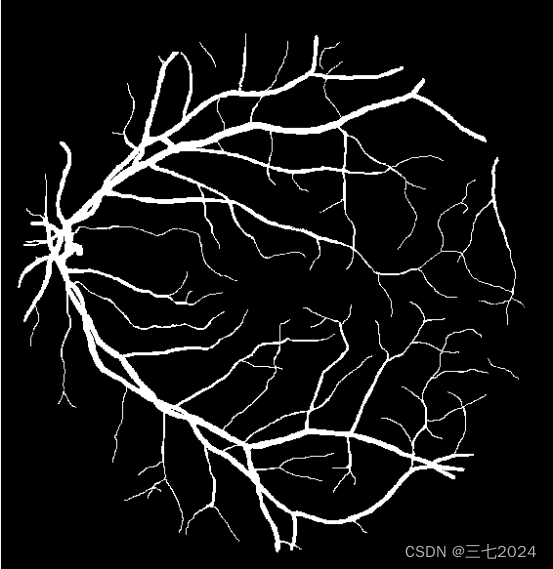
mask 提供的是二值图片,对应的白色区域就是我们要分割的区域。

1st_manual 提供的是人工分割好的一个标签图片。
2. train.py 训练脚本
之前的FCN当中讲过,这里的与之前的差别不大,下面讲几个不同点。
第一点,创建模型create model :

我们这里的训练模型就非常简单,直接调用的 UNet,然后传入相应的参数创建即可,并没有什么预训练权重。
第二点,在 train_and_eval.py 中,我们这里引入了一个叫做 dice_loss,以及在我们的验证当中我们有添加了一个 dice 的一个指标。


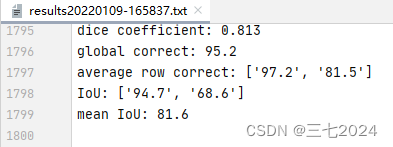
在我们 train.py 运行后,在当前的文件夹里会生成一个result 文件,在这个文件夹里记录的就是我们整个训练过程中,每一个 epoch 训练之后的一个验证结果。训练到最后大概是mean IoU是81.6,那么针对前景也就是我们分割血管的IOU是68.6,correct就是81.5,dice coefficient就是81.3%。
3. unet代码
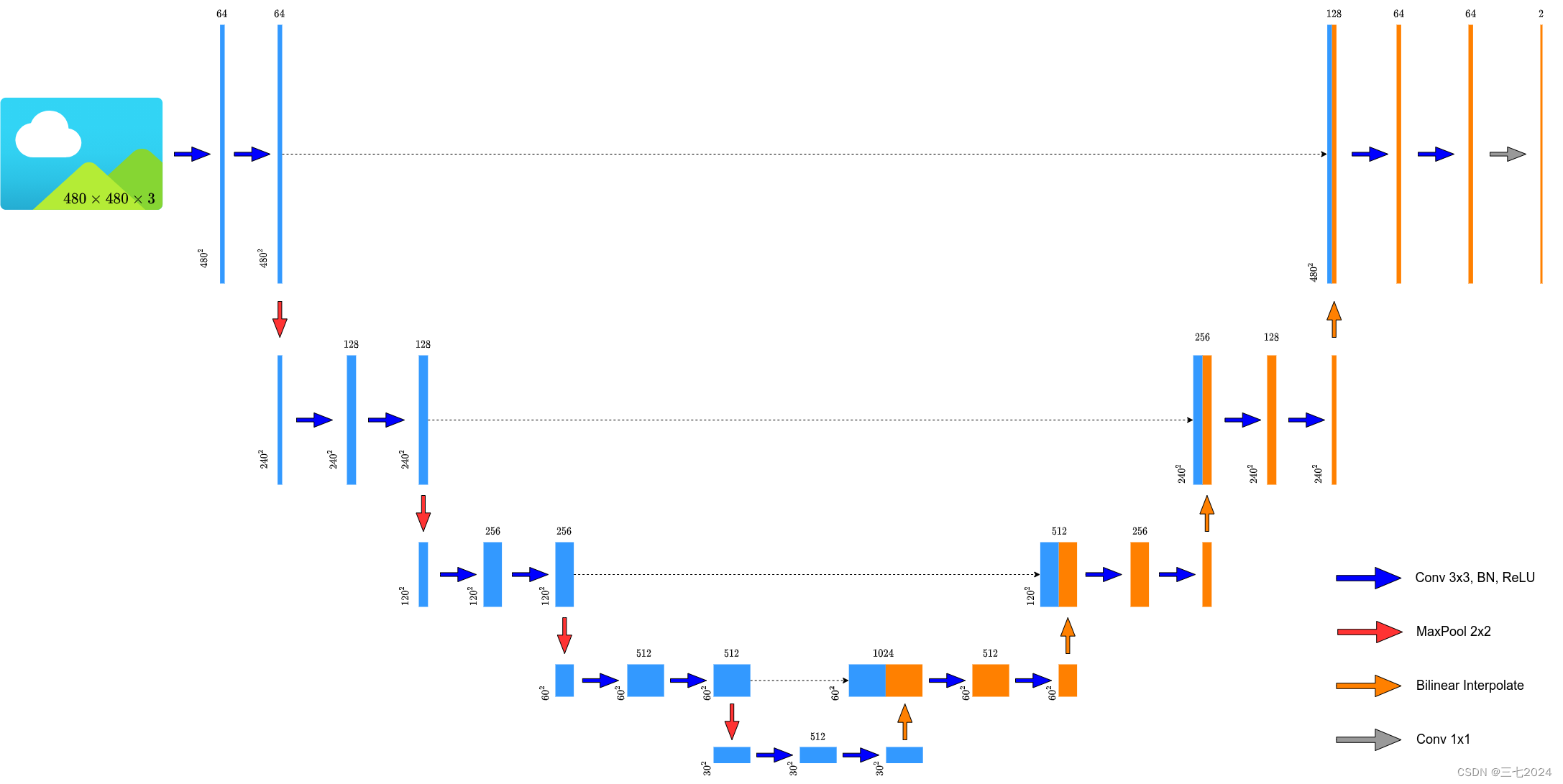
因为我们上一节内容里讲过,我们每经过一次卷积层,都会改变我们特征层的一个高和宽,但是我们现在比较主流的方式是不去改变我们特征层的高和宽,另外现在很多人喜欢将论文中的转置卷积转换成简单的双线性插值下采样,所以我们的图也是双线性插值下采样。
from typing import Dict
import torch
import torch.nn as nn
import torch.nn.functional as F
class DoubleConv(nn.Sequential): # 因为在该网络中我们都是成对使用卷积层,所以这里定义的是 DoubleConv
def __init__(self, in_channels, out_channels, mid_channels=None):
if mid_channels is None:
mid_channels = out_channels
super(DoubleConv, self).__init__(
nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1, bias=False), # 这里加入了padding
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
class Down(nn.Sequential): # 这里是下采样和两个卷积
def __init__(self, in_channels, out_channels):
super(Down, self).__init__(
nn.MaxPool2d(2, stride=2),
DoubleConv(in_channels, out_channels)
)
class Up(nn.Module): # 上采样+拼接+两个卷积
def __init__(self, in_channels, out_channels, bilinear=True): # 这里的in_channels对应的是第一个卷积前输入特征层的channels
super(Up, self).__init__()
if bilinear: # 我们是否采用双线性插值代替转置卷积
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True) # 上采样率设为2
self.conv = DoubleConv(in_channels, out_channels, in_channels // 2)
else:
self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1, x2):
x1 = self.up(x1)
# [N, C, H, W]
diff_y = x2.size()[2] - x1.size()[2]
diff_x = x2.size()[3] - x1.size()[3]
# padding_left, padding_right, padding_top, padding_bottom
x1 = F.pad(x1, [diff_x // 2, diff_x - diff_x // 2,
diff_y // 2, diff_y - diff_y // 2])
x = torch.cat([x2, x1], dim=1)
x = self.conv(x)
return x
class OutConv(nn.Sequential): # 1×1 卷积层
def __init__(self, in_channels, num_classes):
super(OutConv, self).__init__(
nn.Conv2d(in_channels, num_classes, kernel_size=1)
)
class UNet(nn.Module): # 整体搭建
def __init__(self,
in_channels: int = 1,
num_classes: int = 2,
bilinear: bool = True,
base_c: int = 64):
super(UNet, self).__init__()
self.in_channels = in_channels
self.num_classes = num_classes
self.bilinear = bilinear
self.in_conv = DoubleConv(in_channels, base_c)
self.down1 = Down(base_c, base_c * 2)
self.down2 = Down(base_c * 2, base_c * 4)
self.down3 = Down(base_c * 4, base_c * 8)
factor = 2 if bilinear else 1
self.down4 = Down(base_c * 8, base_c * 16 // factor)
self.up1 = Up(base_c * 16, base_c * 8 // factor, bilinear)
self.up2 = Up(base_c * 8, base_c * 4 // factor, bilinear)
self.up3 = Up(base_c * 4, base_c * 2 // factor, bilinear)
self.up4 = Up(base_c * 2, base_c, bilinear)
self.out_conv = OutConv(base_c, num_classes)
def forward(self, x: torch.Tensor) -> Dict[str, torch.Tensor]:
x1 = self.in_conv(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.out_conv(x)
return {"out": logits}
二、自定义数据集的读取
import os
from PIL import Image
import numpy as np
from torch.utils.data import Dataset
class DriveDataset(Dataset):
def __init__(self, root: str, train: bool, transforms=None): # transforms 定义的是我们针对数据的预处理方式
super(DriveDataset, self).__init__()
self.flag = "training" if train else "test"
data_root = os.path.join(root, "DRIVE", self.flag) # 拼接路径
assert os.path.exists(data_root), f"path '{data_root}' does not exists."
self.transforms = transforms
img_names = [i for i in os.listdir(os.path.join(data_root, "images")) if i.endswith(".tif")]
self.img_list = [os.path.join(data_root, "images", i) for i in img_names]
self.manual = [os.path.join(data_root, "1st_manual", i.split("_")[0] + "_manual1.gif")
for i in img_names]
# check files
for i in self.manual:
if os.path.exists(i) is False:
raise FileNotFoundError(f"file {i} does not exists.")
self.roi_mask = [os.path.join(data_root, "mask", i.split("_")[0] + f"_{self.flag}_mask.gif")
for i in img_names]
# check files
for i in self.roi_mask:
if os.path.exists(i) is False:
raise FileNotFoundError(f"file {i} does not exists.")
def __getitem__(self, idx):
img = Image.open(self.img_list[idx]).convert('RGB')
manual = Image.open(self.manual[idx]).convert('L')
manual = np.array(manual) / 255 # 这样我们前景的像素值变为1
roi_mask = Image.open(self.roi_mask[idx]).convert('L')
roi_mask = 255 - np.array(roi_mask)
mask = np.clip(manual + roi_mask, a_min=0, a_max=255)
# 这里转回PIL的原因是,transforms中是对PIL数据进行处理
mask = Image.fromarray(mask)
if self.transforms is not None:
img, mask = self.transforms(img, mask)
return img, mask
def __len__(self):
return len(self.img_list)
@staticmethod
def collate_fn(batch):
images, targets = list(zip(*batch))
batched_imgs = cat_list(images, fill_value=0)
batched_targets = cat_list(targets, fill_value=255)
return batched_imgs, batched_targets
def cat_list(images, fill_value=0):
max_size = tuple(max(s) for s in zip(*[img.shape for img in images]))
batch_shape = (len(images),) + max_size
batched_imgs = images[0].new(*batch_shape).fill_(fill_value)
for img, pad_img in zip(images, batched_imgs):
pad_img[..., :img.shape[-2], :img.shape[-1]].copy_(img)
return batched_imgs
(好难 有一些基础的知识还是要了解一下 霹雳大大把这节前面的代码细讲了 后面的代码说 在之前的内容讲过了 阿巴阿巴 呜呜 没学会)
三、dice损失计算
1. 公式
Dice similarity coefficient 用于度量两个集合的相似性。
在语义分割任务中,X 与 Y 的范围都是[0,1]之间的。
当 X 与 Y 完全相等时,第一个公式的分子和分母都是2|X|,那么Dice=1,Dice Loss=0;
当 X 与 Y 完全不相似时,第一个公式的分子为0,那么Dice=0,Dice Loss=1;
2. 计算
X(预测前景概率):
| 0.1 | 0.2 | 0.1 |
| 0.4 | 0.7 | 0.9 |
| 0.8 | 0.8 | 0.9 |
Y(前景GT标签):
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 1 | 1 |
那么,训练时:
3. 代码
import torch
from torch import nn
import 语义分割篇.UNet.unet.train_utils.distributed_utils as utils
from .dice_coefficient_loss import dice_loss, build_target
def criterion(inputs, target, loss_weight=None, num_classes: int = 2, dice: bool = True, ignore_index: int = -100):
losses = {}
for name, x in inputs.items():
# 忽略target中值为255的像素,255的像素是目标边缘或者padding填充
loss = nn.functional.cross_entropy(x, target, ignore_index=ignore_index, weight=loss_weight)
if dice is True:
dice_target = build_target(target, num_classes, ignore_index)
loss += dice_loss(x, dice_target, multiclass=True, ignore_index=ignore_index)
losses[name] = loss
if len(losses) == 1:
return losses['out']
return losses['out'] + 0.5 * losses['aux']
def evaluate(model, data_loader, device, num_classes):
model.eval()
confmat = utils.ConfusionMatrix(num_classes)
dice = utils.DiceCoefficient(num_classes=num_classes, ignore_index=255)
metric_logger = utils.MetricLogger(delimiter=" ")
header = 'Test:'
with torch.no_grad():
for image, target in metric_logger.log_every(data_loader, 100, header):
image, target = image.to(device), target.to(device)
output = model(image)
output = output['out']
confmat.update(target.flatten(), output.argmax(1).flatten())
dice.update(output, target)
confmat.reduce_from_all_processes()
dice.reduce_from_all_processes()
return confmat, dice.value.item()
def train_one_epoch(model, optimizer, data_loader, device, epoch, num_classes,
lr_scheduler, print_freq=10, scaler=None):
model.train()
metric_logger = utils.MetricLogger(delimiter=" ")
metric_logger.add_meter('lr', utils.SmoothedValue(window_size=1, fmt='{value:.6f}'))
header = 'Epoch: [{}]'.format(epoch)
if num_classes == 2:
# 设置cross_entropy中背景和前景的loss权重(根据自己的数据集进行设置)
loss_weight = torch.as_tensor([1.0, 2.0], device=device)
else:
loss_weight = None
for image, target in metric_logger.log_every(data_loader, print_freq, header):
image, target = image.to(device), target.to(device)
with torch.cuda.amp.autocast(enabled=scaler is not None):
output = model(image)
loss = criterion(output, target, loss_weight, num_classes=num_classes, ignore_index=255)
optimizer.zero_grad()
if scaler is not None:
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
else:
loss.backward()
optimizer.step()
lr_scheduler.step()
lr = optimizer.param_groups[0]["lr"]
metric_logger.update(loss=loss.item(), lr=lr)
return metric_logger.meters["loss"].global_avg, lr
def create_lr_scheduler(optimizer,
num_step: int,
epochs: int,
warmup=True,
warmup_epochs=1,
warmup_factor=1e-3):
assert num_step > 0 and epochs > 0
if warmup is False:
warmup_epochs = 0
def f(x):
"""
根据step数返回一个学习率倍率因子,
注意在训练开始之前,pytorch会提前调用一次lr_scheduler.step()方法
"""
if warmup is True and x <= (warmup_epochs * num_step):
alpha = float(x) / (warmup_epochs * num_step)
# warmup过程中lr倍率因子从warmup_factor -> 1
return warmup_factor * (1 - alpha) + alpha
else:
# warmup后lr倍率因子从1 -> 0
# 参考deeplab_v2: Learning rate policy
return (1 - (x - warmup_epochs * num_step) / ((epochs - warmup_epochs) * num_step)) ** 0.9
return torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=f)
(阿巴巴 不太懂 还得多看看 感觉不如麋了鹿大大的简单,或者maybe有同学可以推荐几个)















 5791
5791











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









