







一、U-Net图像语义分割原理
UNet最早发表在2015的MICCAI会议上,4年多的时间,论文引用量已经达到了9700多次。
UNet成为了大多做医疗影像语义分割任务的baseline,同时也启发了大量研究者对于U型网络结构的研究,发表了一批基于UNet网络结构的改进方法的论文。
UNet网络结构,最主要的两个特点是:U型网络结构和Skip Connection跳层连接。
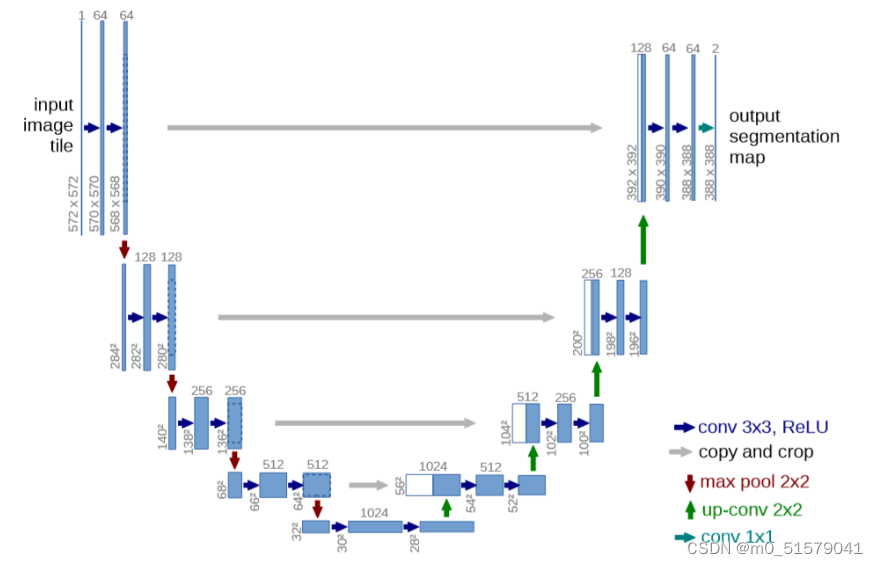
二、U-Net代码及预训练权重下载
2.1 下载unet代码
这里使用的是B站大佬Bubbliiiing复现的unet代码
仓库地址: https://github.com/bubbliiiing/unet-pytorch
2.2 下载模型预训练权重unet_resnet_medical.pth
链接:https://pan.baidu.com/s/1fVrPEgz1bgnUZl7k_1alYw
提取码:wzp2
将下载的权重文件放到model_data文件夹下。
三、labelme图像标注及格式转换
3.1 图像标注
项目代码中,Medical_Datasets文件夹下已经放好了标注并且格式转换好的数据,我这边不再标注,读者可以根据自己的需求自行标注。自己标注的数据的图像和标签文件需求都放在datasets\before文件夹下。
3.2 标签格式转换
运行json_to_dataset.py文件,转换后,会在datasets\JPEGImages文件夹下生成jpg格式图像,在datasets\SegmentationClass文件夹下生成png格式mask标签。Medical_Datasets文件夹下已经放好了标注并且格式转换好的数据,我这边不再标注,
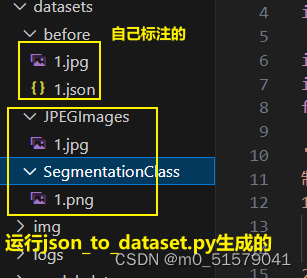
项目中Medical_Datasets文件夹下已经给出了转换好的标签,见下图。
3.3 数据集划分
将上一步的jpg格式图像放到VOCdevkit\VOC2007\JPEGImages文件夹下。
将上一步的png格式mask标签放到VOCdevkit\VOC2007\SegmentationClass文件夹下。
运行voc_annotation.py文件。
查看在VOCdevkit\VOC2007\ImageSets\Segmentation文件夹下生成的txt文件。
Medical_Datasets文件夹下已经放好了划分好的的数据,我这边不再进行数据集划分。
四、U-Net网络训练和测试
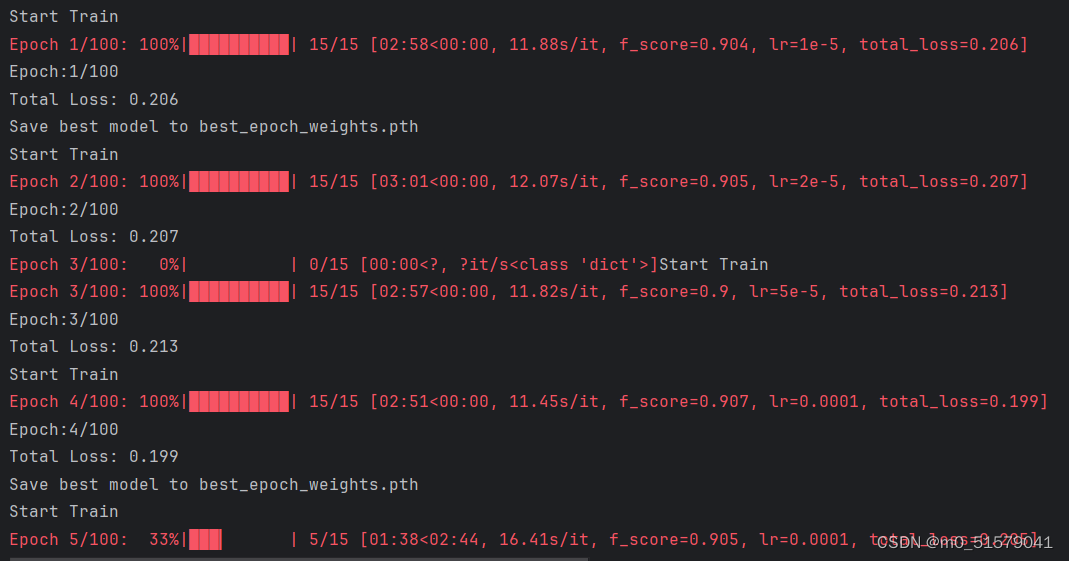
4.1 训练
修改train_medical.py文件中,backbone = “resnet50”和pretrained = False(看代码,其实只是没加载backbone权重,还是加载了model_data文件夹下的unet_resnet_medical.pth权重文件)以及model_path = “model_data/unet_resnet_medical.pth”,读者需要根据自己的情况修改文件中的num_classes,input_shape,Freeze_batch_size,Unfreeze_batch_size以及其他训练参数。然后运行train_medical.py文件。
训练结果保存在logs文件夹下。
4.2 测试
修改unet.py中代码,“model_path” : ‘logs/best_epoch_weights.pth’,和“num_classes”: 2,以及“backbone” : “resnet50”,。
运行predict.py文件。
读者需要根据自己的情况修改模型权重和测试图片的地址。
读者可以通过修改mode参数,实现下面5种模式:
# 'predict' 表示单张图片预测,如果想对预测过程进行修改,如保存图片,截取对象等,可以先看下方详细的注释
# 'video' 表示视频检测,可调用摄像头或者视频进行检测,详情查看下方注释。
# 'fps' 表示测试fps,使用的图片是img里面的street.jpg,详情查看下方注释。
# 'dir_predict' 表示遍历文件夹进行检测并保存。默认遍历img文件夹,保存img_out文件夹,详情查看下方注释。
# 'export_onnx' 表示将模型导出为onnx,需要pytorch1.7.1以上。
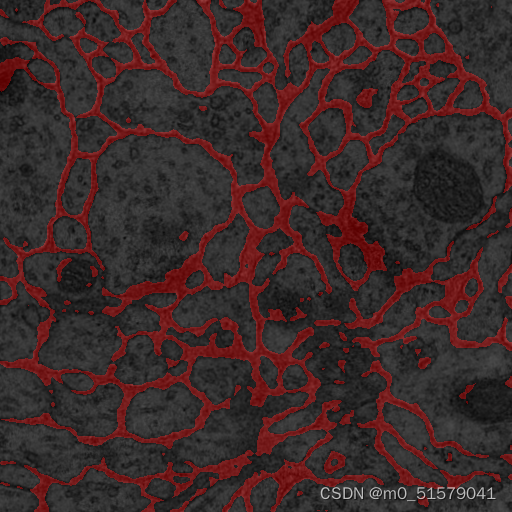
设置mode = “predict”模式,测试一张自己手动输入路径的图像,结果如下
















 2448
2448











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











