






安装Spark的过程就是下载和解压的过程。接下来的操作,我们把它上传到集群中的节点,并解压运行。
1.启动虚拟机
2.通过finalshell连接虚拟机,并上传安装文件到 /opt/software下
3.解压spark安装文件到/opt/module下
tar -zxvf spark-3.3.1-bin-hadoop3.tgz -C /opt/module/
4.重命名,把解压后的文件夹改成spark-local。因为后续我们还会使用其他的配置方式,所以这里先重命名一次。mv是linux的命令,
mv spark-3.3.1-bin-hadoop3 spark-local配置环境变量
1.打开etc/profile.d/my_env.sh文件中,补充设置spark的环境变量。
# 省略其他...
# 添加spark 环境变量
export SPARK_HOME=/opt/module/spark-local
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin2.使用 source /etc/profile 命令让环境变量生效
单机模式运行第一个Spark程序
这里使用单机模式快运行第一个Spark程序,让大家有个基本的印象。在安装Spark时,它就提供了一些示例程序,我们可以直接来调用。进入到spark-local,运行命令spark-submit命令。
spark-submit --class org.apache.spark.examples.SparkPi --master local[2] /opt/module/spark-local/examples/jars/spark-examples_2.12-3.1.1.jar 10或者写成
$ cd /opt/module/spark-local
$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[2] \
./examples/jars/spark-examples_2.12-3.3.1.jar \
10该算法是利用蒙特·卡罗算法求PI的值,具体运行效果如下。请注意,它并不会产生新的文件,而是直接在控制台输出结果。
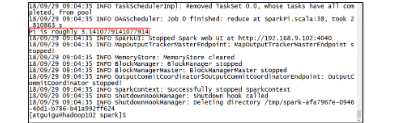
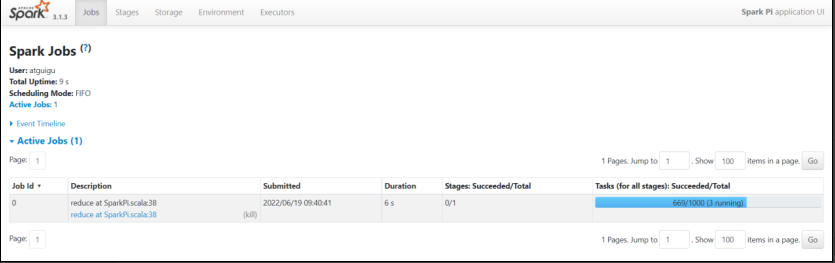
在任务还处于运行状态时,可以通过hadoop100:4040来查看。请注意,一旦任务结束,则这个界面就不可访问了。
Standalone模式介绍
Spark 的 Standalone 模式是一种独立的集群部署模式,自带完整服务,可单独部署到一个集群中,无需依赖任何其他资源管理系统。 一句话理解是:它自带yarn功能。
Standalone模式准备工作
置standalone模式,需要准备多台机器(linux,ip设置,能ping 百度),免密互联。
这里我们就使用上一个阶段学习hadoop时配置的3台机器。
在开始配置之前,请确保三台虚拟机都正确启动了! 具体配置步骤如下。
hadoop100
hadoop101
hadoop1021.上传spark安装包到某一台机器(例如:hadoop100)。 spark.3.1.2-bin-hadoop3.2.tgz。
2.解压。 把第一步上传的安装包解压到/opt/module下(也可以自己决定解压到哪里)。对应的命令是:tar -zxvf spark-3.3.1-bin-hadoop3.tgz -C /opt/module/
3.重命名。进入/opt/module/把解压的内容重命名一下,mv spark-3.1.1-bin-hadoop3.2/ spark-standalone
4.配置环境变量,更新spark路径。/etc/profile.d/my_env.sh。
5.同步环境变量,并使用source命令让它生效。
6.修改workers.template文件。这个文件在spark的安装目录下的conf目录下,先把名字改为workers,然后把内容设置为三台机器的主机名,具体如下。
hadoop100
hadoop101
hadoop102nv.sh.template文件。先把名字改成spark-env.sh,然后修改内容,添加JAVA_HOME环境变量和集群对应的master节点以及通信端口,具体如下。
SPARK_MASTER_HOST=hadoop100
SPARK_MASTER_PORT=7078.同步设置完毕的Spark目录到其他节点。使用我们之前封装的命令:
xsync /opt/module/spark-standalone/9.启动SPARK集群。进入到hadoop100机器,切换目录到/opt/module/spark-standalone/sbin下,运行命令 ./start-all.sh。注意,这里不要省略./,它表示的是当前目录下的start-all命令,如果省略了./,它就会先去环境变量PATH中指定的目录来找这个命令。
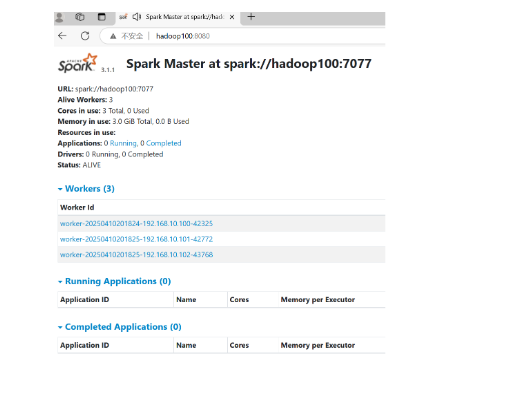
10.验收效果。通过jps命令去每台机器上查看运行的进程。请观察是否在hadoop100上看到了master,worker在hadoop101,hadoop102上看到了worker。
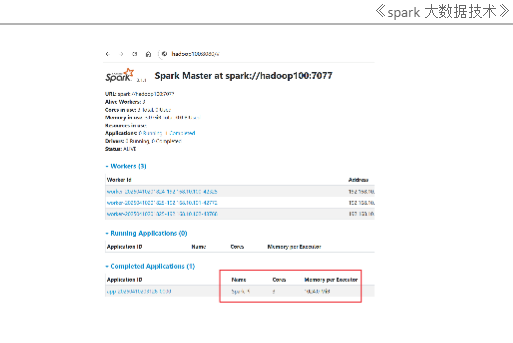
11.查看启动效果。打开浏览器,输入hadoop100:8080。看到效果如下:
提交Spark作业
把spark程序提交给集群执行。切换到目录 /opt/module/spark-standalone/bin下,可以看到有一个spark-submit可执行文件,我们通过它来提交任务。它支持的参数如下:
--class Spark 程序中包含主函数的类
--master Spark 程序运行的模式 (环境)
--deploy-mode master 设为 Yarn 模式之后,使用的模式,可以选择client 和 cluster
--driver-cores master 设为 Yarn 模式之后,设置 driver 端的 cores 个数
--driver-memory master 设为 Yarn 模式之后,用于设置 driver 进程的内存(单位 G 或单位 M)
--num-executors master 设为 Yarn 模式之后,用于设置 Spark 作业总共要用多少个 Executor 进程来执行
--executor-memory 指定每个 executor 可用内存(单位 G 或单位 M)
--total-executor-cores 2 指定所有 executor 使用的 cpu 核数为 2 个
--executor-cores 指定每个 executor 使用的 cpu 核数
application-jar 打好包的应用 jar,包含依赖。这个 URL 在集群中全局可见。比如 hdfs 的共享存储系统,如果是 file://path,那么所有的节点的 path 都包含同样的 jar
application-arguments: 传递给main()方法的参数
spark-submit --class org.apache.spark.examples.SparkPi --master spark://hadoop100:7077 /opt/module/spark-standalone/examples/jars/spark-examples_2.12-3.1.1.jar 10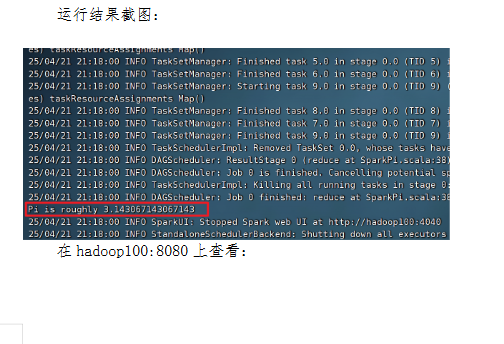
配置历史服务
如果Spark服务重新启动,那么hadoop100:8080这里记录的运行记录就消失了。大家可以通过./stop-all.sh 来停止spark集群,然后再通过start-all来重新启动集群。看看是否还有记录。
我们需要有一个能够查看历史任务的功能。请注意,我们会把历史任务的记录保存在hdfs集群文件中,所以,这里需要hdfs服务的支持。
具体步骤如下:
1.停止任务。进入/opt/module/spark-standalone/sbin, 运行命令 ./stop-all.sh
2.修改/opt/module/spark-standalone/conf/spark-default.conf.temple。修改名字,改成spark-default.conf,再补充两个设置。如下所示。
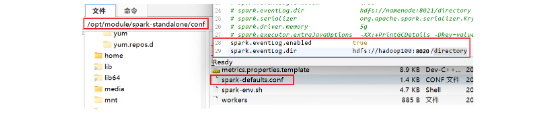
spark.eventlog.enable true
spark.eventlog.dir hdfs://hadoop100:8020/directory
代码说明:这里指定了历史任务相关的信息要保存在集群的/directory文件夹下,所以要确保我们有这个目录,并且hdfs服务时是开启的状态。
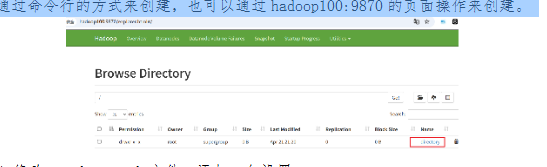
3.启动hadoop的hdfs服务(start-dfs.sh),并在根目录创建目录directory。可以通过命令行的方式来创建,也可以通过hadoop100:9870的页面操作来创建。
4.修改spark-env.sh文件。添加一句设置:
export SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://hadoop100:8020/directory"5.分发修改之后的配置文件到集群的其他机器。
xsync /opt/module/spark-standalone/conf/6.重新启动spark集群。命令是./start-all.sh
7.启动历史服务器:命令是 ./start-history-server.sh
检查spark-standalone/logs
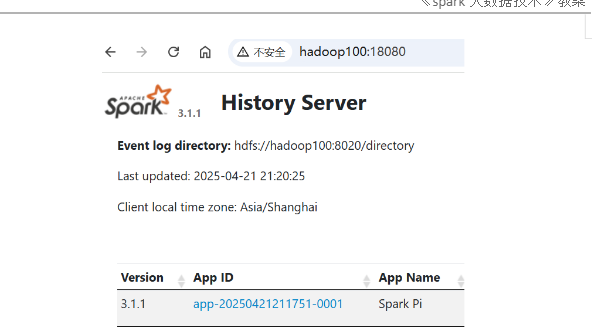
8.在18080端口下看效果。此时应该是没有任务的。
9.重新提交一个新的任务,再次回到18080下,看看是否已经有了任务。

















 4991
4991

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









