







最后
码字不易,觉得有帮助的可以帮忙点个赞,让更多有需要的人看到
又是一年求职季,在这里,我为各位准备了一套Java程序员精选高频面试笔试真题,来帮助大家攻下BAT的offer,题目范围从初级的Java基础到高级的分布式架构等等一系列的面试题和答案,用于给大家作为参考
以下是部分内容截图

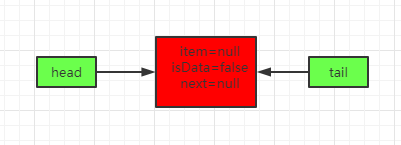
初始化的时候调用上面的构造器TransferQueue(),默认得到一个哨兵节点,里面的元素是空的,这个isData就是说这个节点是不是一个有效数据,只有item!=null才表示一个有效数据:
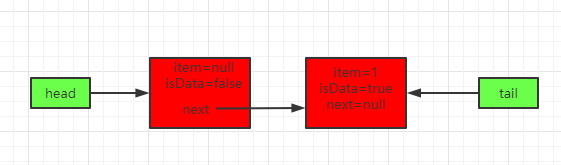
先put(E)再take()
假如先put(E),因为没有对用的take()操作,线程会被阻塞直到有take()出现。
线程t1过来put(1)
这时候h==t走的是第一个if分支,至少在第2次自旋的时候将元素1包装成节点QNode之后假如队列,并会进入方法awaitFulfill阻塞等待传递元素:
Object awaitFulfill(QNode s, E e, boolean timed, long nanos) {
/* Same idea as TransferStack.awaitFulfill */
final long deadline = timed ? System.nanoTime() + nanos : 0L;//获得超时时间
Thread w = Thread.currentThread();//当前执行的线程
int spins = ((head.next == s) ?
(timed ? maxTimedSpins : maxUntimedSpins) : 0);//获得自旋次数
for (;😉 {
if (w.isInterrupted())//如果线程被中断了
s.tryCancel(e);//尝试取消,注意这里取消后,会将s中的item和s替换。即s.item变成了s.QNode
Object x = s.item;//拿到当前节点的item
if (x != e)//不相等说明被取消或者值已经被取走或者已经有值放进来
return x;//直接返回自己
if (timed) {//如果当前方法是计时方法
nanos = deadline - System.nanoTime();//获取剩余时间
if (nanos <= 0L) {//如果已经到时间了
s.tryCancel(e);//尝试取消
continue;
}
}
if (spins > 0)
–spins;//自旋次数>0,则减1后继续自旋
else if (s.waiter == null)
s.waiter = w;
else if (!timed)//非计时方法
LockSupport.park(this);//如果当前方法不是带超时时间的,则直接挂起直到唤醒
else if (nanos > spinForTimeoutThreshold)//如果到了自旋次数,且还没到指定的超时时间,就挂起指定的剩余时间
LockSupport.parkNanos(this, nanos);
}
}
因为调用的put(1)没有带超时时间,所以会被LockSupport.park(this)阻塞,这时候得到了如下队列:
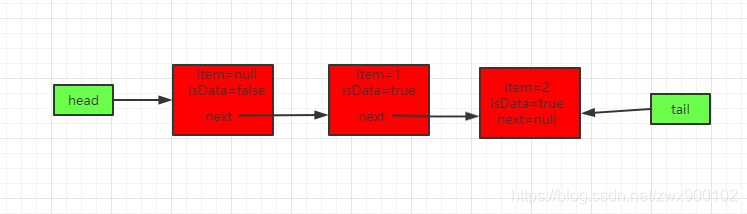
主要经过如下5个步骤:
-
1、将元素初始化成为一个QNode。
-
2、将tail.next指向当前新构建的QNode(CAS操作)。
-
3、将新构建的QNode设置为tail节点(CAS操作)。
-
4、将当前QNode节点中的waiter属性设置为当前线程(awaitFulfill方法)。
-
5、挂起前线程(awaitFulfill方法)。
线程t2过来put(2)
这时候h和t不相等了,但是isData都为true,所以t2过来的流程一样,还是会走if分支,然后会继续将元素2添加到队尾,得到如下队列:
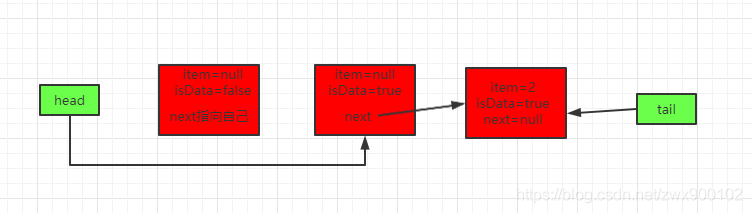
注意,QNode还有一个属性waiter,是用来记录当前节点是哪个线程放进来的,因为后面当节点被take()走了之后,需要知道当前节点是由哪个线程放进来的,然后去唤醒对应线程。
我们可以看到,SynchronousQueue号称是不存储元素的,但是不存储元素并不代表它内部没有队列,内部还是会有一个队列的,只不过每个线程过来put(E)的时候,如果没有对应的take()来匹配,那么线程就一直卡住了,也就是元素不会一直停留在队列,而是会等待被转移(transfer)。
线程t3过来take()
这时候来了一个线程t3过来take(),这时候因为h!=t,且take()的时候isData=false,和tail节点中的isData不一致了,会走else分支。
因为head节点是一个哨兵节点(空元素),而这又是公平模式,也就是必须满足FIFO,所以会从head.next开始转移元素。
最终得到如下最新的队列:
主要经过如下步骤:
-
1、将head.next中的item设置为null(CAS操作)。
-
2、将head.next设置为新的head节点(advanceHead方法)。
-
3、将原head节点的next指向自己(advanceHead方法)。
-
4、通过原节点的waiter属性,将原先线程唤醒。
-
5、返回获取到的元素。
注意,这里将元素1取走之后,原先的线程t1被唤醒,唤醒之后会在方法awaitFulfill继续自旋,这时候执行到if (x != e)条件的时候就会成立了,所以会返回x。然后回到transfer方法,将元素返回,t1线程结束。
线程t4过来take()
这时候的步骤和上面也是一样,最终得到如下队列:
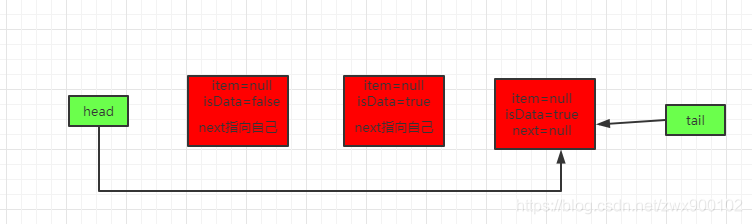
回到了原始的初始化状态,只保留了一个哨兵节点。
先take()再put(E)
假如先take()进来,步骤和上面put(E)基本一致,唯一的区别就是take()会先抢占一个队列的位置,将一个item==null的节点加入队列。
线程t1过来take()
线程t1过来take()因为一开始h==t,还是会走的if逻辑,最终会得到如下队列:
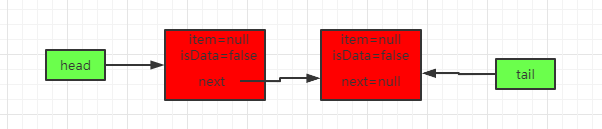
主要经过如下步骤:
-
1、将一个null元素初始化成为一个QNode。
-
2、将tail.next指向当前新构建的QNode(CAS操作)。
-
3、将新构建的QNode设置为tail节点(CAS操作)。
-
4、将当前QNode节点中的waiter属性设置为当前线程(awaitFulfill方法)。
-
5、挂起前线程(awaitFulfill方法)。
除了第1个步骤,其他都和首先进来put(E)的步骤一样
线程t2过来put(1)
这时候因为if条件不满足,会走else分支,先将元素1赋值到之前被线程t1占的位置,最终得到如下队列:
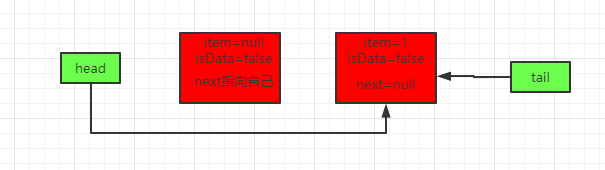
主要经过如下步骤:
-
1、将head.next中的item设置为1(CAS操作)。
-
2、将head.next设置为新的head节点(advanceHead方法)。
-
3、将原head节点的next指向自己(advanceHead方法)。
-
4、通过原节点的waiter属性,将原先线程唤醒。
-
5、返回成功put进去到的元素。
接下来将原先的t1线程唤醒,t1线程唤醒之后会继续将节点中的item设置为自己,然后返回拿到的元素:
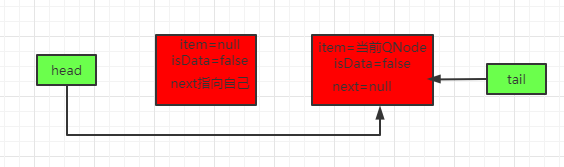
非公平策略是通过其内部类TransferStack来实现的,思想基本和TransferQueue一致,唯一的区别就是TransferStack是非公平的,也就是LIFO模式,在这里就不详细介绍了。
================================================================================
LinkedTransferQueue是一个由链表结构组成的无界阻塞TransferQueue队列。相对于其他阻塞队列,LinkedTransferQueue多了tryTransfer和transfer方法。LinkedTransferQueue和SynchronousQueue中的公平策略使用的算法是一样的,唯一的区别是SynchronousQueue内部不会存储哪怕1个元素,而LinkedTransferQueue内部会存储元素。
================================================================
正常队列中,当移除一个元素的时候,就会同步移动head和tail节点的指针,为了最大程序的保证性能LinkedTransferQueue不会实时去更新head和tail的指针,而是引入了一个松弛度的概念。
**松弛度指的是head值与第一个不匹配节点之间的目标最大距离,反之对tail也是如此。**这个值这一般为1-3(根据经验得出),在LinkedTransferQueue中松弛度定义为2。因为如果太大了会增加缓存丢失的成本或者长遍历链的风险,而较小的话就会增加CAS的开销。
====================================================================================
LinkedTransferQueue内部也是通过CAS和自旋来实现并发控制,所以也是一种效率比较高的队列。
下面还是先来看看LinkedTransferQueue类图:
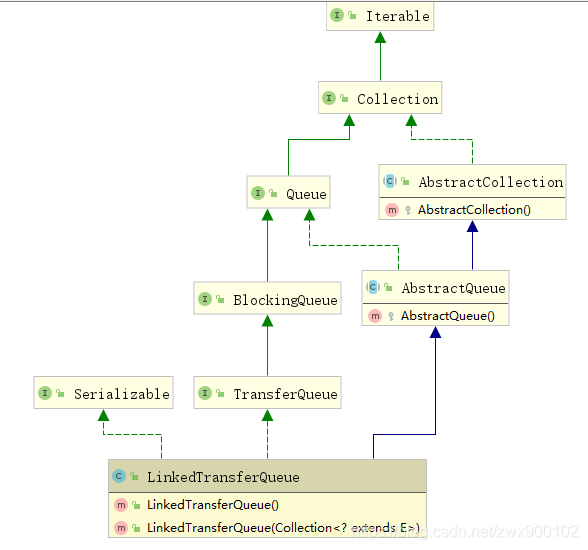
相比较于其他阻塞队列,多了一个TransferQueue接口,我们先来看看TransferQueue接口中核心的几个方法:
| 方法 | 功能 |
| — | — |
| tryTransfer(e) | 传递一个元素给正在等待的消费者,如果没有正在等待的消费者,则返回false |
| transfer(e) | 传递一个元素给正在等待的消费者,如果没有正在等待的消费者,则阻塞等待 |
| tryTransfer(e,time,uint) | 传递一个元素给正在等待的消费者,如果没有正在等待的消费者,则阻塞等待指定时间,过了超时时间之后,仍没有消费者,则直接返回false |
| hasWaitingConsumer() | 至少有一个消费者正在等待接收元素则返回true |
| getWaitingConsumerCount() | 返回正在等待的消费者数量,返回的值是一个近似值,因为消费者可能很快就完成消费或者放弃等待 |
初始化的时候什么也不做,并不会在内部构造一个初始节点,addAll()实际上也是循环调用了add(E)方法:
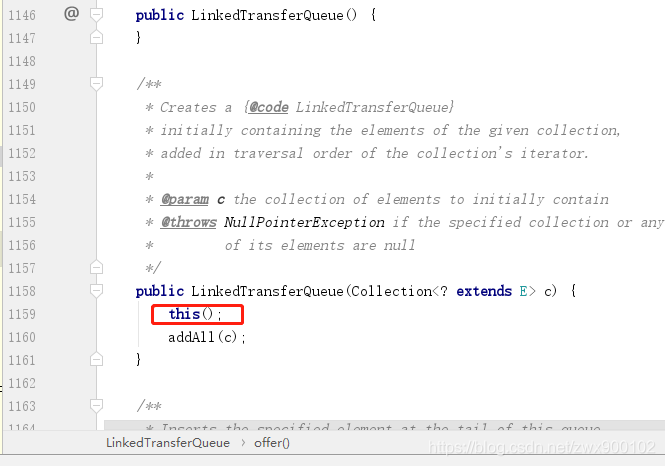
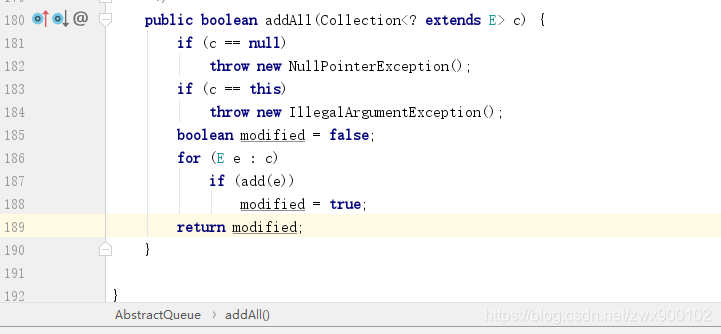
然后我们再看看其他方法,add,put,take,offer等,都是调用了一个共同的方法xfer,只不过通过不同参数来控制。
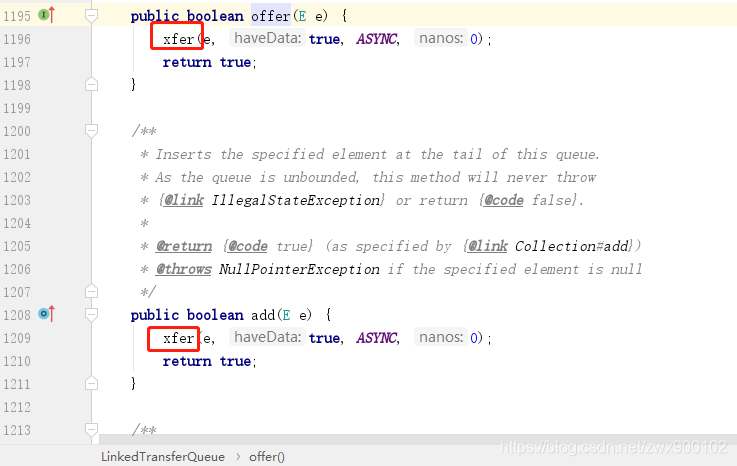
private E xfer(E e, boolean haveData, int how, long nanos) {
if (haveData && (e == null))//如果当前是put操作,且e==null,则抛出异常
throw new NullPointerException();
Node s = null; // the node to append, if needed
retry:
for (;😉 { // restart on append race
//从head开始循环匹配
for (Node h = head, p = h; p != null;) { // find & match first node
boolean isData = p.isData;
Object item = p.item;
//如果元素还没被匹配过,也就是还在队列里
if (item != p && (item != null) == isData) { // unmatched
//如果相等,就说明是两个相同操作,直接不用执行后面了,互补操作才能往后走
if (isData == haveData) // can’t match
break;
//将p中的item替换成e
if (p.casItem(item, e)) { // match
//假如有一个队列是有元素的,第一次被take()的时候,q==h是进不了for循环的,所以会直接返回
//第2次进来会先匹配一次head节点,匹配不上,在匹配第2个节点,这就相当于松弛度=2了,所以
//这时候是满足条件的,可以进入for循环,
for (Node q = p; q != h;) {
Node n = q.next; // update by 2 unless singleton
//移动head指针
if (head == h && casHead(h, n == null ? q : n)) {
h.forgetNext();
break;
} // advance and retry
if ((h = head) == null ||
(q = h.next) == null || !q.isMatched())
break; // unless slack < 2
}
LockSupport.unpark(p.waiter);
return LinkedTransferQueue.cast(item);
}
}
Node n = p.next;
p = (p != n) ? n : (h = head); // Use head if p offlist
}
if (how != NOW) { // No matches available
if (s == null)
s = new Node(e, haveData);//初始化节点
Node pred = tryAppend(s, haveData);
if (pred == null)
continue retry; // lost race vs opposite mode
if (how != ASYNC)//take()或者带超时时间的方法会走这里
return awaitMatch(s, pred, e, (how == TIMED), nanos);
}
return e; // not waiting
}
}
这个方法也要分为两种方式,先put(E)再take()和先take()再put(E)。
先put(E)再take()
put(E)操作不会进行阻塞,成功之后直接返回。
线程t1过来put(1)
因为head和tail都是null(一开始不会初始化队列),所以上面的第2个for循环是进不去的,会走到后面这里初始化node,并加入到队列中,最终得到如下队列:
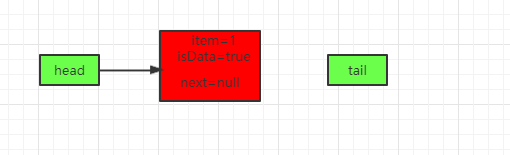
可以看到,这时候tail节点并没有被初始化,这是因为利用了松弛度,松弛度要等于2才会移动tail指针(这是一种性能的优化),我们看看tryAppend方法(主要是看红框部分):
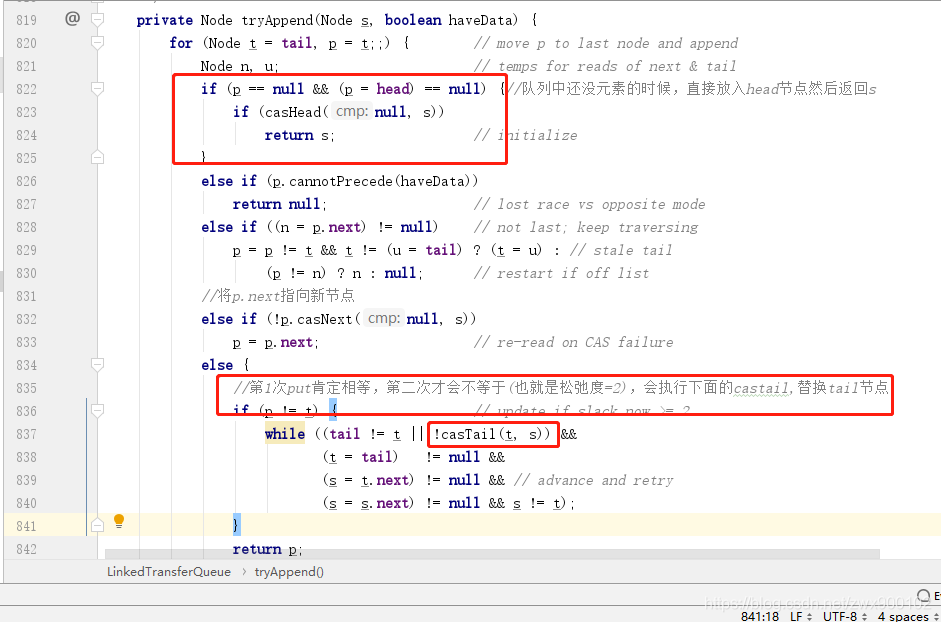
主要分为以下步骤:
-
1、初始化Node节点
-
2、将Node节点设为head节点
线程t2过来put(2)
线程t2再进来put的时候,因为满足松弛度=2了,这时候就会移动tail指针,所以会得到如下队列:
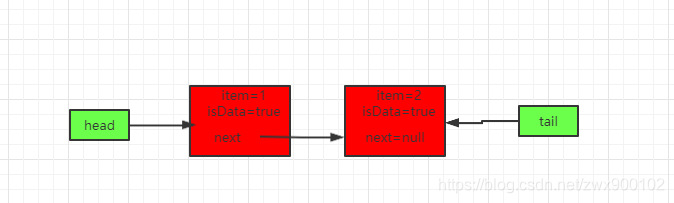
主要分为以下步骤:
-
1、初始化Node节点
-
2、将Node节点设为head.next节点
-
3、达到松弛度,将新Node设置为tail节点
后面如果再有元素过来添加,到第3个元素的时候,tail也是不会移动的,要第3个元素才会移动tail,这里就不再继续举例了。
线程t3过来take()
这时候来take会将head节点的元素设为null,然后直接返回,得到如下队列:
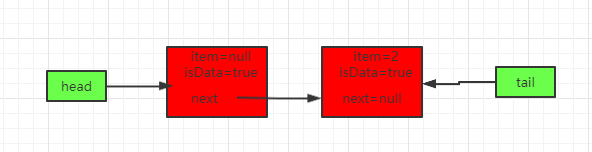
这时候因为松弛度还没达到2,不会移动head指针。
主要经过如下步骤:
-
1、将head节点中的item设置为null。
-
2、返回获取到的item,。
线程t4过来take()
这时候首先会循环head节点,发现不匹配,然后循环到head.next,得到如下队列:
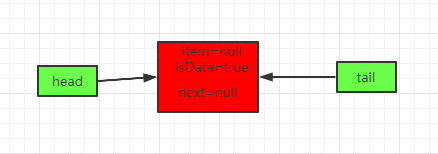
这里因为松弛度达到2,所以会移动head指针。
主要经过如下步骤:
-
1、循环head节点,发现不匹配。
-
2、循环head.next,匹配上,将head.next中item设置为null。
-
3、移动head指针,指向head.next。
先take()再put(E)
先take()的时候,因为队列中还没有元素,所以会先自旋,自旋一定次数之后就阻塞,直到有元素put(E)进来然后唤醒线程。
线程t1过来take()
和上面第一次put(E)一样,上面的第2个for循环进不去,会走到后面这里初始化node,并加入到队列中,最终得到如下队列:
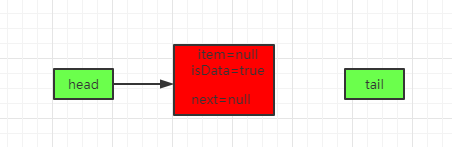
主要经过如下步骤:
-
1、初始化一个item=null的Node节点。
-
2、将Node节点设置为head节点。
-
3、自旋一定次数(awaitMatch方法)。
-
4、达到自旋次数后还没有线程过来take(),执行park挂起线程(awaitMatch方法)。
注意,上面的Node中也有一个waier属性用来存储线程信息,后面唤醒需要获取waiter中的线程
线程t2过来take()
这时候因为松弛度达到2了,会移动tail指针,最终得到如下队列:
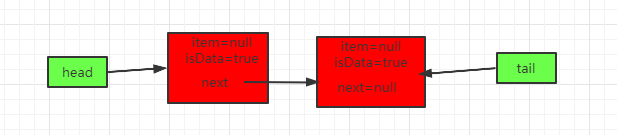
最后
码字不易,觉得有帮助的可以帮忙点个赞,让更多有需要的人看到
又是一年求职季,在这里,我为各位准备了一套Java程序员精选高频面试笔试真题,来帮助大家攻下BAT的offer,题目范围从初级的Java基础到高级的分布式架构等等一系列的面试题和答案,用于给大家作为参考
以下是部分内容截图

中也有一个waier属性用来存储线程信息,后面唤醒需要获取waiter中的线程
线程t2过来take()
这时候因为松弛度达到2了,会移动tail指针,最终得到如下队列:
最后
码字不易,觉得有帮助的可以帮忙点个赞,让更多有需要的人看到
又是一年求职季,在这里,我为各位准备了一套Java程序员精选高频面试笔试真题,来帮助大家攻下BAT的offer,题目范围从初级的Java基础到高级的分布式架构等等一系列的面试题和答案,用于给大家作为参考
以下是部分内容截图
[外链图片转存中…(img-C2UB4QFB-1715483768257)]














 1502
1502











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









