







from sklearn.metrics import classification_report
加载内置iris数据,并保存
dataset = load_iris()
X = dataset.data
y = dataset.target
attribute_means = X.mean(axis=0) # 得到一个列表,列表元素个数为特征值个数,列表值为每个特征的均值
X_d = np.array(X >= attribute_means, dtype=‘int’) # 转bool类型
数据到此已获取完毕,接下来将其划分为训练集和测试集。
==================================================================================
使用默认的0.25作为分割比例。即训练集:测试集=3:1。
X_train, X_test, y_train, y_test = train_test_split(X_d, y, random_state=random_state)
数据描述:
本例中共有四个特征,
原数据集有150个样本,分割后训练集有112个数据,测试集有38个数据。
标签一共分为三类,取值可以是0,1,2。
================================================================================================
首先遍历特征的每一个取值,对于每一个特征值,统计它在各个类别中出现的次数。
定义一个函数,有以下四个参数:
-
X, y_true即 训练集数据和标签
-
feature是特征的索引值,可以是0,1,2,3。
-
value是特征可以有的取值,这里为0,1。
该函数的意义在于,对于训练集数据,对于某个特征,依次遍历样本在该特征的真实取值,判断其是否等于特征的某个可以有的取值 (即value)(以0为例)。如果判定成功,则在字典class_counts中记录,以三个类别(0,1,2)中该样本对应的类别为键值,表示该类别出现的次数加一。
首先得到的字典(class_counts)形如:
{0: x1, 1.0: x2, 2.0:x3}
其中元素不一定是三个
x1:类别0中,某个特征feature的特征值为value(0或1)出现的次数
x2:类别0中,某个特征feature的特征值为value(0或1)出现的次数
x3:类别0中,某个特征feature的特征值为value(0或1)出现的次数
然后将class_counts按照值的大小排序,取出指定特征的特征值出现次数最多的类别:most_frequent_class。
该规则即为:该特征的该特征值出现在其出现次数最多的类别上是合理的,出现在其它类别上是错误的。
最后计算该规则的错误率:error
错误率即 具有该特征的个体在除出现次数最多的类别出现的次数,代表分类规则不适用的个体的数量。
最后返回待预测的个体类别 和 错误率
def train_feature_value(X, y_true, feature, value):
class_counts = defaultdict(int)
for sample, y_t in zip(X, y_true):
if sample[feature] == value:
class_counts[y_t] += 1
sorted_class_counts = sorted(class_counts.items(), key=itemgetter(1), reverse=True) # 降序
most_frequent_class = sorted_class_counts[0][0]
error = sum([class_count for class_value, class_count in class_counts.items()
if class_value != most_frequent_class])
return most_frequent_class, error
返回值most_frequent_class是一个字典, error是一个数字
==================================================================================================
def train(X, y_true, feature):
n_samples, n_features = X.shape
assert 0 <= feature < n_features
获取样本中某特征所有可能的取值
values = set(X[:, feature])
predictors = dict()
errors = []
for current_value in values:
most_frequent_class, error = train_feature_value(X, y_true, feature, current_value)
predictors[current_value] = most_frequent_class
errors.append(error)
total_error = sum(errors)
return predictors, total_error
因为most_frequent_class是一个字典,所以predictors是一个键为特征可以的取值(0和1),值为字典most_frequent_class的 字典。
total_error是一个数字,为每个特征值下的错误率的和。
====================================================================================
all_predictors = {variable: train(X_train, y_train, variable) for variable in range(X_train.shape[1])}
Errors = {variable: error for variable, (mapping, error) in all_predictors.items()}
找到错误率最低的特征
best_variable, best_error = sorted(Errors.items(), key=itemgetter(1))[0] # 升序
print(“The best model is based on feature {0} and has error {1:.2f}”.format(best_variable, best_error))
找到最佳特征值,创建model模型
model = {‘variable’: best_variable,
‘predictor’: all_predictors[best_variable][0]}
print(model)
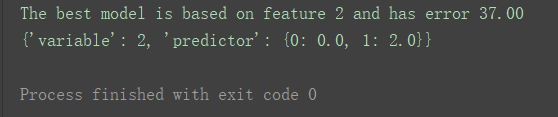
根据代码运行结果,最佳特征值是特征2(索引值为2的feature,即第三个特征)。
对于初学者这里的代码逻辑比较复杂,可以对变量进行逐个打印查看,阅读blog学习时要盯准字眼,细品其逻辑。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!














 576
576











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









