







- [8. 部分效果展示](#8__216)
- [9. 全部代码](#9__224)
- * + <center>\*\*👇问题解答 · 源码获取 · 技术交流 · 抱团学习请联系👇\*\*
人生苦短 我用python
啥是原神我也不是很清楚
只知道女朋友最近很喜欢
所以给她整了点表情包还有全角色图+语音包
不过分,一点都不过分
源码资料电子书:点击此处跳转文末名片获取
表情包部分:
1. 素材来自:

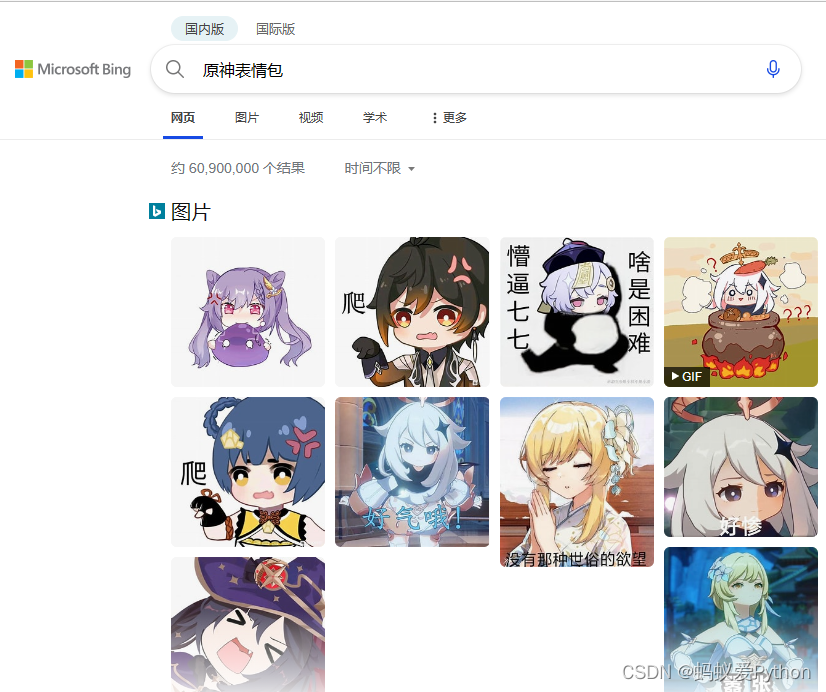
2. 准备模块
import re
from selenium import webdriver
import time
import requests
3. 调用浏览器驱动
driver = webdriver.Chrome()
4. 页面滚动
def drop\_down():
for x in range(1, 27, 3):
time.sleep(1)
j = x / 27 # 1/9 3/9 5/9 9/9
js = 'document.documentElement.scrollTop = document.documentElement.scrollHeight \* %f' % j
driver.execute_script(js)
5. 保存数据
lis = driver.find_elements_by_css_selector('.dgControl\_list li .iuscp')
page = 1
for li in lis:
try:
img_url = li.find_element_by_css_selector('.mimg').get_attribute('src')
title = li.find_element_by_css_selector('.b\_dataList a').get_attribute('title')
title = re.sub(r'[\/"<>\*?|\n]', '', title)
img_content = requests.get(url=img_url).content
with open('img//' + title + str(page) + '.jpg', mode='wb') as f:
f.write(img_content)
print(title, img_url)
page +=1
这里特意留了一个小bug,诶嘿~
5. 效果
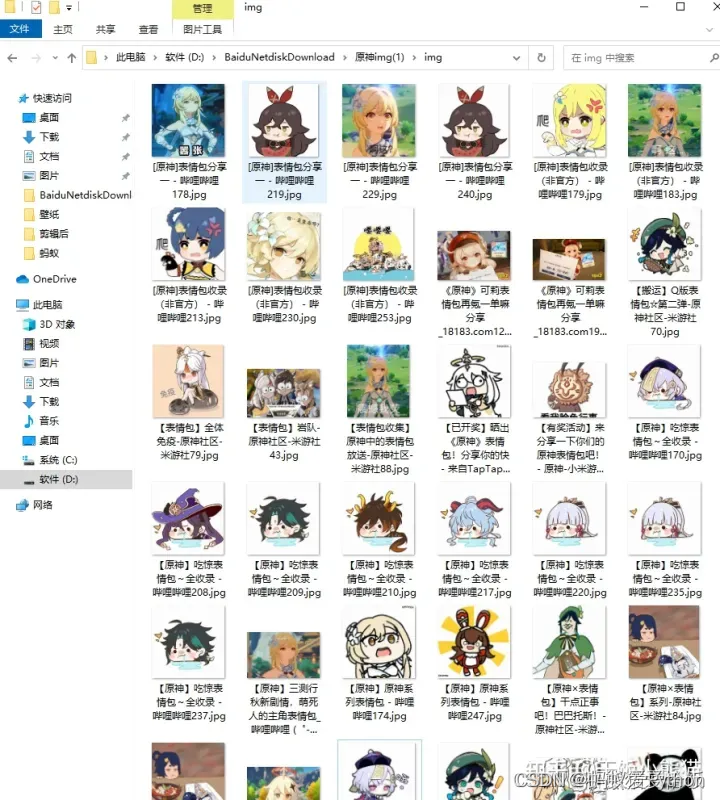
全角色语音+高清彩图部分
1.准备工具

源码资料电子书:点击此处跳转文末名片获取

2. 准备模块
import requests
import re
import execjs
3. 请求链接


4. 本次目标
所有角色的:
- 基础介绍
- 中日语音
- 图片
5. 分析数据来源
1. 右键点击检查(开发者工具)

2.刷新网页,找准对应数据
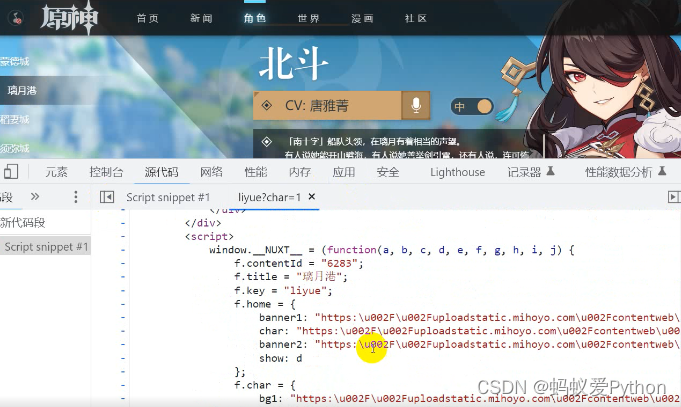
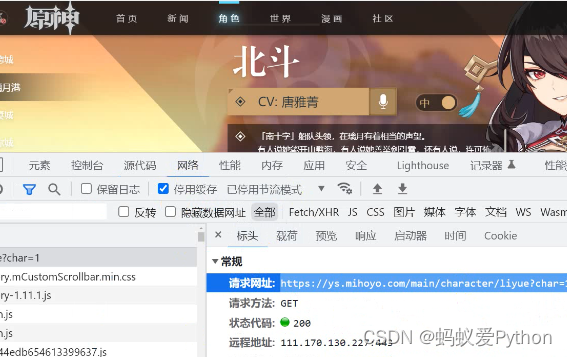
6. 开始代码
url = 'https:///main/character/liyue?char=1'
html_data = requests.get(url).text
print(html_data)
源码资料电子书:点击此处跳转文末名片获取
筛选数据
随便搜索网站内包含内容:“南十字”

使用正则表达式匹配数据内容
现在能在网上找到很多很多的学习资源,有免费的也有收费的,当我拿到1套比较全的学习资源之前,我并没着急去看第1节,我而是去审视这套资源是否值得学习,有时候也会去问一些学长的意见,如果可以之后,我会对这套学习资源做1个学习计划,我的学习计划主要包括规划图和学习进度表。
分享给大家这份我薅到的免费视频资料,质量还不错,大家可以跟着学习

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 3612
3612











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









