






名词解释区
一、基础单元
1.位(Bit)
计算机存储最小单位,仅存0或1两种状态
2.字节(Byte)
这个是最基本的概念了,字节是计算存储容量的一种计量单位。我们知道计算机只能识别1和0组成的二进制位。一个数就是1位(bit),为了方便计算,我们规定8位就是一个字节。
例如 :01000001(二进制)→ 十进制65 → 代表字母"A"
3.字符(Character)
字符和字节不太一样,任何一个文字或符号都是一个字符,但所占字节不一定,不同的编码导致一个字符所占的内存不同。
例如:标点符号"+"是一个字符,汉字是一个字符,在GBK编码中一个汉字占2个字节,在UTF-8编码中一个汉字占3个字节。
随着时代的发展,程序员们希望在计算机中显示字符,但计算机只能识别0和1的二进制数。于是就有了编码规范。
二、关键体系
字符集(Character Set)
定义字符与唯一编号(Code Point)(直译为码点)的映射表,作用是规定哪些字符可以被表示,并为每个字符分配一个唯一的编号。
示例:
ASCII字符集:定义了128个字符(如字母、数字、标点符号)。
Unicode字符集:定义了超过14万个字符(涵盖全球所有语言和符号)。
拓展说明:
码点是字符集中为每个字符分配的唯一编号,它是一个逻辑概念,与具体的编码方式无关。
示例:码点到编码的转换(下面的UTF-8和UTF-16是Unicode字符集的编码规范)
以汉字"汉"为例:
码点:
U+6C49
UTF-8编码:
码点
U+6C49位于0800-FFFF范围 → 使用3字节模板。二进制拆分:
0110 1100 0100 1001。编码结果:
11100110 10110001 10001001→ 十六进制E6 B1 89。UTF-16编码:
码点
U+6C49在基本多文种平面(BMP)内 → 直接使用2字节。编码结果:
01101100 01001001→ 十六进制6C 49。
编码规范(Encoding)
所谓字符集其实是一套编码规范中的子概念,为了显示字符,国际组织就制定了编码规范,希望使用不同的二进制数来表示代表不同的字符,这样电脑就可以根据二进制数来显示其对应的字符。我们通常就称呼其为XX编码,XX字符集。
上面是我学习时看的一个大佬的博客给出的解释,链接在最后,其实概括点讲,编码规范就是将字符集中的码点转换为计算机可以存储和传输的字节序列的规则,作用是解决字符如何在计算机中存储和传输的问题。
例如:GBK 编码规范,根据这套编码规范,计算机就可以在中文字符和二进制数之间相互转换。而使用GBK编码就可以使计算机显示中文字符。
变长字节(Variable-length Encoding)
也叫可变长字节编码,是一种用于表示数据的编码方式,其中每个数据元素所占用的字节数不是固定的,而是根据数据的具体值或特征来动态确定
这里说明一下字符集和编码规范的区别,我刚开始学的时候对这两个名词概念很模糊,不知道你们会不会这样。
字符集像一本字典,列出了所有字符及其对应的编号(码点)。
示例:ASCII字符集:定义了128个字符(如字母、数字、标点符号)。
编码规范像一种书写规则,规定了如何将这些编号(码点)转换成实际的存储形式(字节序列)。
示例:UTF-8:将Unicode码点编码为1-4个字节。
1 各字符集的优缺点和差异
1.1 简单介绍(按时间顺序)
注意:下面的ASCII、GB系列有双重身份,既是字符集又是编码规范,我会把这两个部分分开介绍
1. ASCII(美国信息交换标准代码)
-
时间:1960年代制定,成为计算机字符编码的基石
-
目的:统一英语字符的数字化表示,解决早期设备间通信乱码问题
-
局限性:仅支持基础英语,无法表示带音标字符(如ç、ñ)
-
应用场景:早期命令行界面、纯文本文件(如.txt)、网络协议(如HTTP头)
(1)ASCII字符集
-
定义:ASCII字符集定义了128个字符,包括:
-
英文字母(A-Z, a-z)。
-
数字(0-9)。
-
标点符号(如
!、?、,等)。 -
控制字符(如换行符
\n、回车符\r等)。
-
-
码点范围:
0x00到0x7F(即0到127)。
(2)ASCII编码规范
-
定义:ASCII编码规范规定了如何将字符集中的字符编码为字节序列。
-
规则:
-
每个字符占用1个字节(8位)。
-
实际只使用7位(最高位为0),因此ASCII字符的字节范围是
0x00到0x7F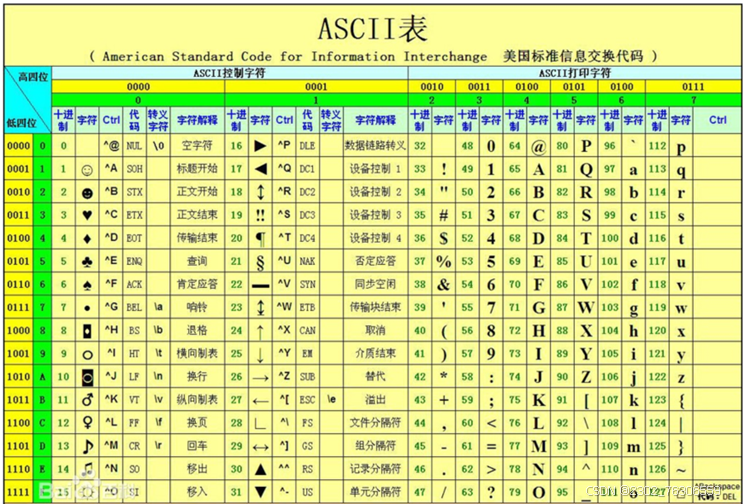
-
2. GB2312(信息交换用汉字编码字符集·基本集)
-
时间:1980年发布,中国首个针对简体中文的编码标准
-
目的:解决ASCII无法处理中文的问题,实现计算机中文化
-
应用场景:早期中文DOS系统(如UCDOS)、WPS文字处理软件
(1)GB2312字符集
-
码点范围:双字节编码(
0xA1A1-0xF7FE) -
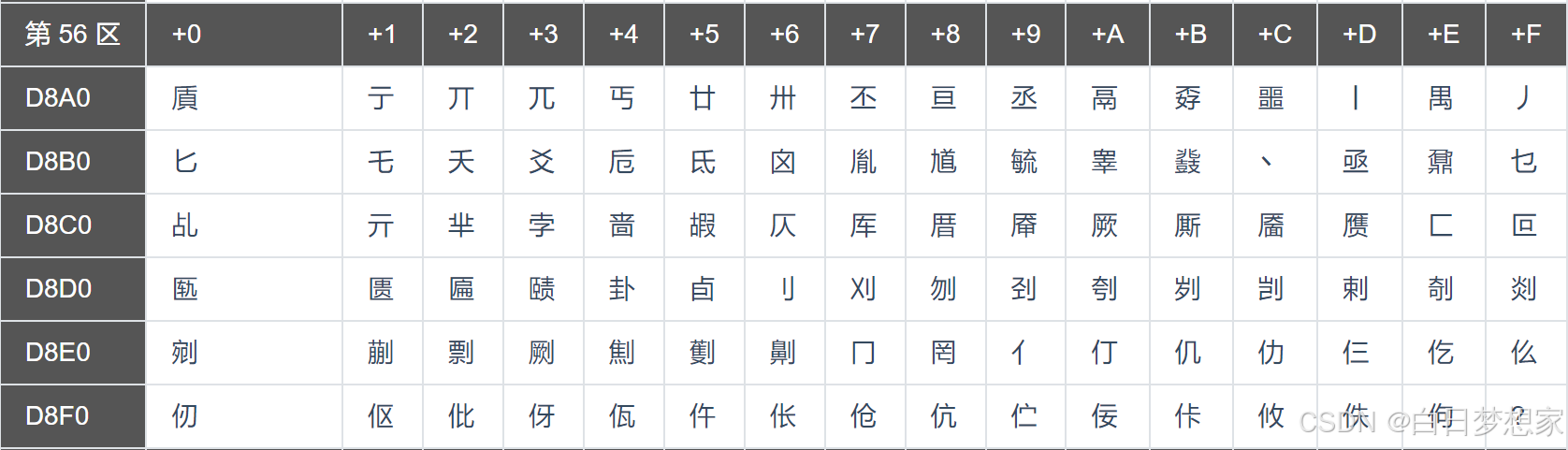
94×94矩阵:将编码空间划分为94个区(0xA1-0xFE),每区94个位,分别对应第一字节和第二字节,这种表示方式也称为区位码。
-
字符分布:
-
01-09 区为特殊符号
-
10-15 区为用户自定义符号区(未编码)
-
16-55 区为一级汉字,按拼音排序,共 3755 个
-
56-87 区为二级汉字,按部首/笔画排序,共 3008 个
-
88-94 区为用户自定义汉字区(未编码)
-
(2)GB2312编码规范:
-
编码方式:双字节编码,每个字节最高位固定为1(即首字节≥0xA1)。也就是两个字节表示一个字符,为了兼容ASCII码,规定每个字节的首bit位固定为1(当程序读取一个字节时:如果最高位为 0,则认为是 ASCII 字符。如果最高位为 1,则认为是 GB2312 字符的一部分(需要再读取下一个字节,组合成双字节字符))。这样也避免和ASCII冲突。
-
字节结构:
-
首字节范围
0xA1-0xF7,次字节0xA1-0xFE -
示例:"啊" →
B0A1
-
-
兼容性:向下兼容ASCII(单字节部分)
3. GBK(汉字内码扩展规范)
-
时间:1995年发布,非强制标准,但被微软Windows 95/98广泛采用
-
目的:扩展GB2312,兼容繁体字、生僻字及符号
-
应用场景:Windows系统默认编码(直至XP时代)、繁体中文游戏与网页
(1)GBK字符集:
-
码位计算:
-
理论空间:126×190=23,940个码位
-
实际收录:21,886个字符(含中日韩汉字、竖排标点、注音符号等)
-
(2)GBK编码规范
-
扩展编码范围:
-
首字节:0x81-0xFE(兼容GB2312的0xA1-0xF7)
-
次字节:0x40-0x7E和0x80-0xFE(移除GB2312次字节的"首bit为1"限制)
-
兼容性:完全兼容GB2312和ASCII
-
4. GB18030(信息技术·中文编码字符集)
-
时间:2000年发布,中国强制性国家标准(最新版2022)
-
目的:支持多民族语言、全面兼容Unicode,满足国际化需求
-
应用场景:中国政府办公系统、金融行业、支持少数民族语言的软件
(1)GB18030字符集:
- 码点范围:理论最多支持1,587,600个码位(远超Unicode的17平面)
- 支持字符:
-
强制支持生僻字(如"䶮"、"龘")
-
全部Unicode字符(包括少数民族文字和Emoji)
-
(2)GB18030编码规范
-
变长编码:
-
单字节(0x00-0x7F):完全兼容ASCII
-
双字节(0x81-0xFE + 0x30-0x39):覆盖GBK字符
-
四字节(0x81-0xFE + 0x30-0x39 + 0x81-0xFE + 0x30-0x39):扩展支持Unicode全字符集
-
兼容性:兼容GBK、GB2312、ASCII和Unicode
-
5. Unicode(统一码/万国码)
-
时间:1991年发布,持续更新(2023年版本15.1)
-
目的:终结"编码割裂",为全球所有文字提供唯一标识
-
核心设计:
-
码点(Code Point):逻辑编号,范围U+0000至U+10FFFF(共1,114,112个)
-
编码方案:
-
UTF-8:变长1-4字节,兼容ASCII,互联网占比超97%(2023统计),适合网络传输(如"汉"→
E6B189) -
UTF-16:2或4字节(代理对),Java/C#内部存储格式(如"汉"→
6C49) -
UTF-32:定长4字节,空间效率低但处理简单,用于内存对齐场景(如"汉"→
00006C49)
-
-
16的意思是,UTF-16的编码单位是16位,即两个字节,也就是说,编码结果的长度是以两字节为单位的,即2字节,4字节,可以类比的到UTF-8和UTF-32
然后我们来感受一下他们的不同
这张图展示了同一字符串
Hello world!在不同编码规范下的存储差异,ASCII为一字节存储,UTF-32是四字节,通过补0方式完成存储。而因为UTF-8 编码规则如下:
ASCII字符(0x00-0x7F):直接使用单字节编码,与 ASCII 完全兼容。
非ASCII字符:需使用多字节编码(例如中文、Emoji 等)。
所以在
Hello world!中,UTF-8 的编码结果与 ASCII 完全一致

-
字符覆盖:
-
现代语言:涵盖全球所有官方文字(如阿拉伯文、泰米尔文)
-
历史字符:古埃及象形文字、西夏文
-
符号体系:数学符号、盲文、绘文字、交通图标
-
-
应用场景:操作系统内核(Linux/Windows/macOS)、全球化网站(如维基百科)、跨语言数据库
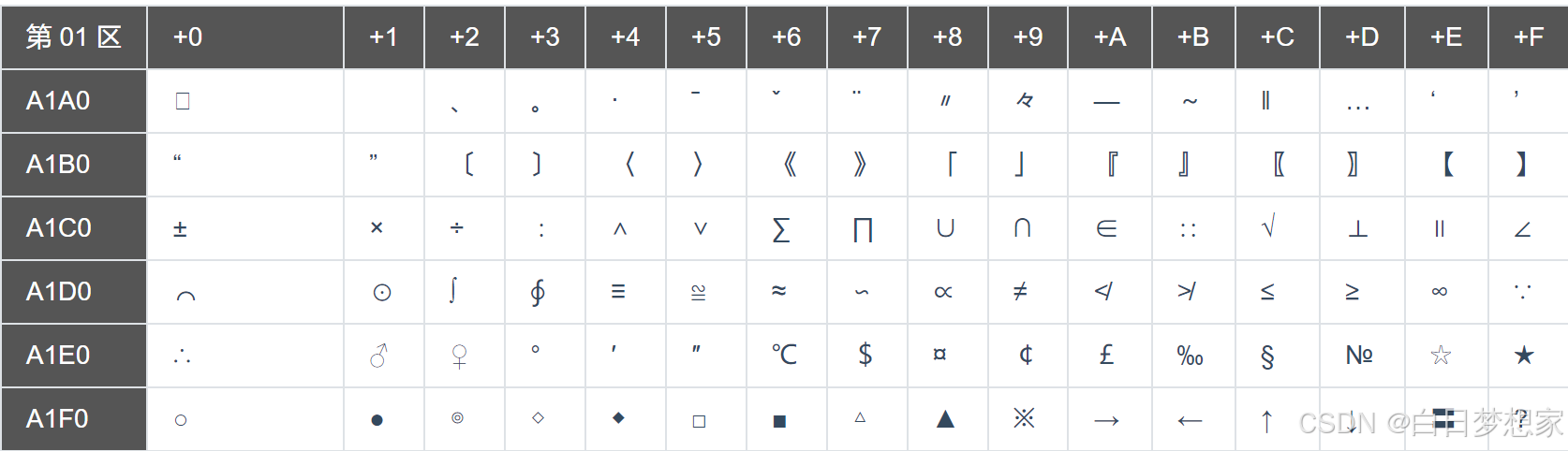
这里介绍一下Unicode的平面结构
Unicode 字符集按编码空间划分为 17 个平面(Planes),每个平面包含 65536 个码位(范围:0x0000 ~ 0xFFFF)。
其中:0号平面(BMP) 是最核心的基本多文种平面,覆盖了全球绝大多数常用字符(如拉丁字母、汉字、符号等)。
具体字符排布如左表所示,按区块划分(如 00~0F 为拉丁文字,60~6F 为东亚文字,70~7F 为中日韩汉字

1.2各字符集的差异
1.2.1 字符表示方式
| 字符集 | 编码方式 | 核心限制 |
|---|---|---|
| ASCII | 单字节(7 位) | 仅支持英文,无法表示非英语字符 |
| GB2312 | 双字节(固定首 bit 为 1) | 不支持繁体字,码位空间有限 |
| GBK | 双字节(次字节范围扩展) | 非国际标准,多语言混排困难 |
| GB18030 | 变长(1/2/4 字节) | 编码复杂度高,主要面向中国市场 |
| Unicode | 逻辑码点 + UTF 编码方案 | 存储效率因语言而异(如中文需 3 字节) |
1.2.2编码空间容量
| 字符集 | 理论码位 | 实际收录字符数 | 扩展性 |
|---|---|---|---|
| ASCII | 128 | 128 | 无扩展空间 |
| GB2312 | 8,836 | 7,445 | 仅限简体中文 |
| GBK | 23,940 | 21,886 | 支持繁体字,但无国际化 |
| GB18030 | 1,611,668 | 覆盖 Unicode 全量 | 支持超百万字符 |
| Unicode | 1,114,112 | 149,813+(持续更新) | 全球通用,无限扩展 |
1.2.3 多民族语言字符兼容性
| 字符集 | 支持语言范围 | 典型多语言场景支持 |
|---|---|---|
| ASCII | 仅英语 | 无 |
| GB2312 | 简体中文 | 无 |
| GBK | 简体中文 + 繁体中文 | 有限(如中文 - 日文混合文本) |
| GB18030 | 中文 + 少数民族文字 + Unicode | 中国多民族地区 |
| Unicode | 全球所有语言及符号 | 跨语言文本混排(如中英日文) |
1.2.4便捷性
| 维度 | ASCII | GB2312/GBK | GB18030 | Unicode**(UTF-8)** |
|---|---|---|---|---|
| 存储效率 | 高 | 中(双字节) | 变长 | 高(兼容 ASCII**)** |
| 处理复杂度 | 简单 | 需双字节处理 | 复杂 | 需编解码算法 |
| 国际化支持 | 无 | 无 | 有限 | 全面 |
| 系统兼容性 | 全平台 | 仅中文环境 | 中国本地化 | 全平台通用 |
1.3 各字符集的优缺点
| 字符集 | 优点 | 缺点 |
|---|---|---|
| ASCII | 简单高效、易于理解实现,在纯英文环境广泛应用 | 字符集过小,无法满足多语言需求 |
| GB2312 | 是中文信息处理基础标准,在简体中文处理有优势,与早期中文系统兼容性好 | 字符覆盖范围有限,不支持繁体和少数民族文字,难以适应全球化多语言环境 |
| GBK | 扩展了 GB2312,能处理更多中文内容,在中文环境表现较好 | 不是全球化字符集,对多民族语言和国际字符支持不足 |
| GB18030 | 是中国国家标准,支持多种少数民族语言,能满足国内多语言处理需求,与 GB2312、GBK 兼容利于过渡升级 | 相对 Unicode,国际通用性稍弱,在国际交流中可能存在兼容性问题 |
| Unicode | 全球通用,能表示所有语言字符,为跨语言、跨平台信息处理提供统一标准,利于全球信息共享交流 | 编码方式复杂,不同编码方式(如 UTF - 8、UTF - 16、UTF - 32)在存储和传输时需根据情况选择,否则影响效率,在部分旧系统可能存在兼容性问题 |
1.4 各字符集之间的关系
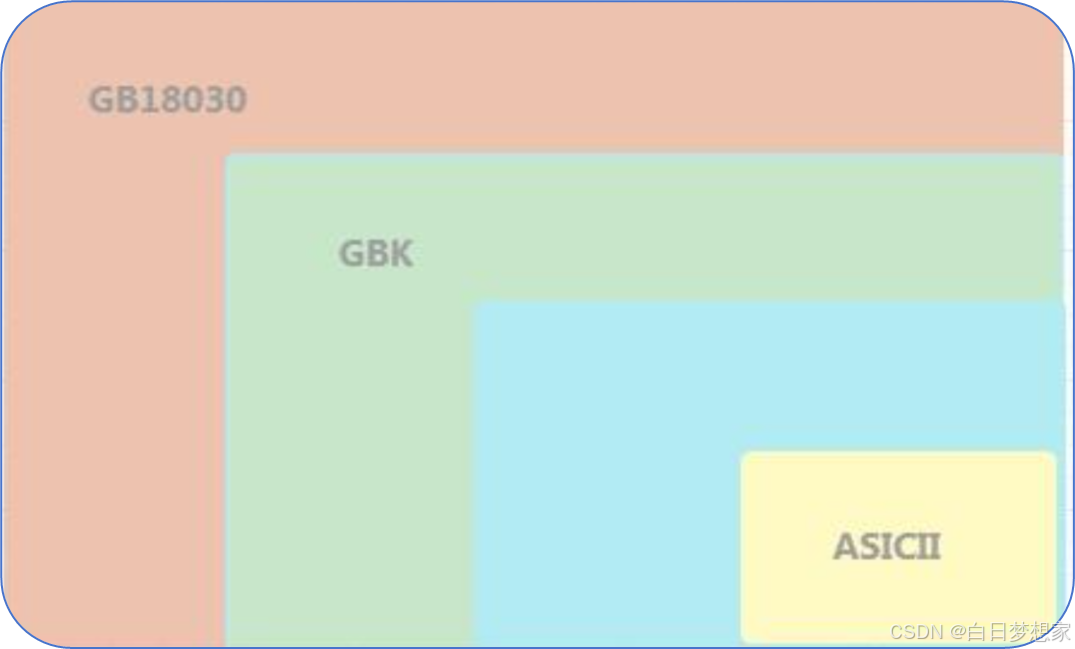
GB2312 兼容 ASICII 编码, GBK 兼容 GB2312 编码,GB18030 兼容 GB2312 编码 和 GBK 编码,简单地说就是大鱼吃小鱼关系
感觉内容还是不全面,但看完做到初步了解还是可以的,以后有空再补!
名词解释参考文章:https://blog.csdn.net/qq_42068856/article/details/83792174

















 299
299

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









