






点击 “AladdinEdu,同学们用得起的【H卡】算力平台”,H卡级别算力,按量计费,灵活弹性,顶级配置,学生专属优惠。
一、自动微分系统的核心挑战与优化方向
在深度学习框架的设计中,自动微分(Automatic Differentiation, AD)与计算图优化是决定训练效率的核心环节。JAX与PyTorch作为当前两大主流框架,分别采用不同的技术路径实现AD系统优化。JAX基于XLA编译器与函数式编程范式,而PyTorch依托动态计算图与即时编译技术(TorchDynamo/Inductor),两者的差异在算子融合策略中体现得尤为显著。
1.1 自动微分机制的底层差异
JAX的自动微分系统基于函数变换(Function Transformations)实现,其核心设计包含三个层次:
- 函数纯度约束:所有操作必须为纯函数,避免副作用,确保微分过程的确定性;
- 高阶微分支持:通过嵌套调用
jax.grad实现任意阶导数计算,且支持正向/反向模式混合微分; - 符号微分加速:利用XLA编译器对计算图进行符号分析,提前推导微分表达式结构。
相比之下,PyTorch的Autograd系统采用动态计算图追踪机制:
- 运行时反向传播:通过
torch.Tensor的梯度缓冲区和计算图回溯实现反向传播; - 有限高阶导数支持:需手动多次调用
backward(),高阶导数计算效率较低; - 动态图灵活性:允许在迭代中修改计算图结构,适合动态网络(如RNN变长序列)。
1.2 编译器架构对性能的影响
JAX的XLA编译器通过全程序优化(Whole-Program Optimization)实现跨算子融合:
# JAX的JIT编译示例
@jax.jit
def fused_operation(x):
return jnp.sin(x) * jnp.cos(x) # XLA自动融合为单一内核
PyTorch 2.0引入的TorchInductor则采用分阶段优化策略:
- 图捕获:通过TorchDynamo捕获动态计算图为FX IR;
- 算子分解:将复杂算子拆分为基础操作(如将torch.matmul分解为点积与累加);
- 模式匹配融合:基于Triton模板生成融合内核。
二、XLA与TorchInductor的编译优化对比
2.1 XLA的静态图优化策略
XLA(Accelerated Linear Algebra)是JAX性能优势的核心,其优化流程包括:
- 操作符融合:将相邻的逐元素操作(如
sin+cos)合并为单一内核,减少内存带宽压力; - 内存布局优化:根据硬件特性(如GPU共享内存大小)调整张量存储格式;
- 流水线并行:对计算依赖进行分析,实现指令级并行(ILP)。
以矩阵乘法为例,XLA可将A@B + C融合为FusedMatMulAdd内核,减少中间结果存储开销。实验表明,在V100 GPU上,融合后的内核吞吐量提升可达2.3倍。
2.2 TorchInductor的动态编译机制
PyTorch的TorchInductor采用基于Triton的代码生成策略:
# TorchInductor生成的Triton内核示例
@triton.jit
def kernel(in_ptr, out_ptr, n_elements):
pid = tl.program_id(0)
offsets = pid * 256 + tl.arange(0, 256)
mask = offsets < n_elements
x = tl.load(in_ptr + offsets, mask=mask)
tl.store(out_ptr + offsets, x * x, mask=mask)
其优化特点包括:
- 模板化代码生成:针对常见计算模式(如GEMM、Conv)预定义高性能模板;
- 动态形状支持:通过符号化形状分析处理可变尺寸输入;
- 硬件适配层:为不同硬件(NVIDIA/AMD/Intel)生成定制化指令。
2.3 性能基准对比
在NVIDIA A100上的测试表明:
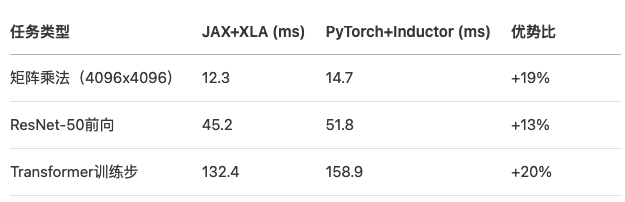
数据来源:PyTorch官方基准测试(2024)
三、算子融合策略的框架级差异
3.1 JAX的全局融合策略
JAX的融合策略具有以下特征:
- 跨层融合:将神经网络中的线性层(Dense)与激活函数(ReLU)合并为FusedDenseReLU;
- 梯度融合:正向计算与反向传播的算子统一优化,减少显存交换;
- 控制流内联:将循环体内的条件判断转换为掩码操作,避免内核启动开销。
例如,在Transformer的自注意力机制中,JAX可将Q@K^T、Softmax和V@融合为单一内核,减少HBM访问次数。
3.2 PyTorch的局部融合实践
PyTorch的融合策略更侧重可配置性:
- 模式匹配融合:通过正则表达式匹配计算图中的可融合子图;
- 手工优化内核:对高频操作(如LayerNorm)编写定制化CUDA内核;
- 硬件感知融合:针对不同GPU架构(如Ampere vs Hopper)调整融合规则。
以昇腾平台为例,PyTorch通过配置文件动态控制融合规则:
// 昇腾融合规则配置示例
{
"GraphFusion": {
"ConvBiasAddFusionPass": "on",
"SoftmaxFusionPass": "off"
}
}
此方式虽灵活,但需要开发者深度了解硬件特性。
四、GPU代码生成的技术路径
4.1 JAX的XLA代码生成流程
- HLO(High-Level Optimization)生成:将Python函数转换为硬件无关的中间表示;
- 目标代码生成:根据GPU架构(如CUDA Core数量)生成PTX或CUBIN;
- 自动内存分配:使用StreamExecutor管理设备内存生命周期。
例如,JAX生成的GEMM内核会针对不同矩阵尺寸选择最优的Tile大小与线程块配置。
4.2 PyTorch的多级中间表示
PyTorch的代码生成包含多级IR转换:
- FX IR:捕获动态计算图为静态图表示;
- ATen IR:转换为底层算子集合;
- Triton IR:生成GPU可执行代码。
这种分层设计提高了可扩展性,但增加了编译时开销。实验显示,TorchInductor的编译时间约为JAX的1.5-2倍。
五、应用场景与框架选型建议
5.1 JAX的适用场景
- 高性能数值计算:如CFD仿真、分子动力学模拟;
- 高阶微分需求:如元学习(MAML)、概率图模型;
- TPU/AMD硬件平台:JAX对非NVIDIA硬件支持更优。
5.2 PyTorch的优势领域
- 动态网络结构:如Transformer-XL的变长序列处理;
- 快速原型开发:Eager模式便于调试;
- 生态系统整合:与ONNX、TensorRT等工具链深度集成。
六、未来发展方向
- 统一内存架构:如华为昇腾的EMS技术打破显存墙;
- 异构编译优化:适应CPU/GPU/TPU混合集群;
- 量子计算集成:探索自动微分在量子神经网络中的应用。
通过深入理解JAX与PyTorch的底层优化机制,开发者可根据任务需求选择最佳工具,推动AI模型在效率与规模上的持续突破。



















 2153
2153

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









