






目录
前言
作者写本篇文章旨在复习自己所学知识,并把我在这个过程中遇到的困难的将解决方法和心得分享给大家。由于作者本人还是一个刚入门的菜鸟,不可避免的会出现一些错误和观点片面的地方,非常感谢读者指正!希望大家能一同进步,成为大牛,拿到好offer。
本系列(初识C语言初阶)只是对C语言的基础知识点过一遍,是为了能让读者和自己对C有一个初步了解。
日志
- 2024.5.19号首发
1.什么是bug?
计算机史上第一个bug:上世纪的计算机科学家,在写程序的时候,发现计算机发生了故障。那时候的计算机还很大,跟个房间似的,可以进入到里面。程序员就去里面找故障的原因,发现在一个晶体二极管上发现一个飞蛾死在了上面。然后把它清理,并替换了零件,计算机就正常工作了。

后来科学家把这个事情记录下来,之后就把计算机发生的错误称为bug(臭虫、飞蛾)。bug就是计算机程序或硬件可能存在的缺陷。
2.调试是什么?有多重要?
简单来说就是通过已经发现的bug,逆推回去找出发生bug的原因,解决发生的bug。这个过程就成为调试。
2.1调试是什么?
调试(英语:Debugging / Debug),又称除错,是发现和减少计算机程序或电子仪器设备中程序
错误的一个过程。
2.2调试的基本步骤
- 发现程序错误的的存在
假设有一天写完代码发给公司的测试人员。测试人员跟你说程序有问题,重新写。而你却觉得想着:我写的程序怎么可能出现问题,是你自己安装的环境错误了、安装包有问题、操作方法不当。这个时候明明程序出问题了,还不承认自己写错了,这就非常尴尬了。要接受自己的错误,才能不断成长。 - 以隔离、和消除等方式对错误进行定位
假设有一天你不是个新手了,写了很多代码,比如一万行。我们就可以先屏蔽一部分你可能觉得会出错的代码,再运行。发现没有问题了,我再把这部分代码放出来。继续找另外可能出现问题的代码,屏蔽掉再尝试运行。
就这样就能很快找到错误的位置,可不要傻乎乎的从第一行f10,一直调试。这是非常浪费时间的。 - 确定错误产生的原因
- 提出纠正错误的解决办法
- 对程序错误予以改成,重新测试
可不要想着改完之后,我觉得一定是对的,就压根不看了。改完之后也存在错误的可能,我们需要保持谦虚的心态。
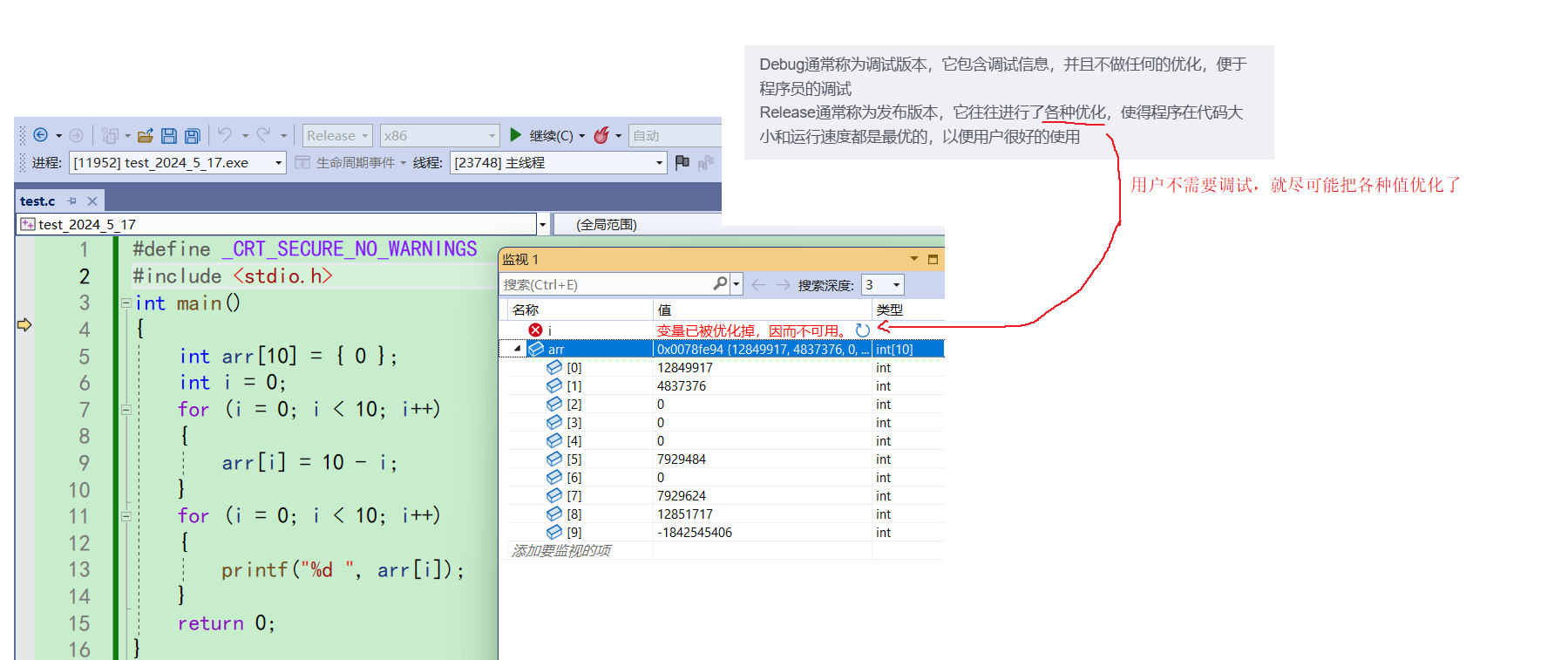
2.3Debug和Release的介绍
Debug通常称为调试版本,它包含调试信息,并且不做任何的优化,便于程序员的调试
Release通常称为发布版本,它往往进行了各种优化,使得程序在代码大小和运行速度都是最优的,以便用户很好的使用
-
在VS的编译器上面也有显示

-
可以随便写一个代码,用来区别Debug和Release

-
先来看Debug版本,使用f10调式,直接进入main函数,箭头来到第4行
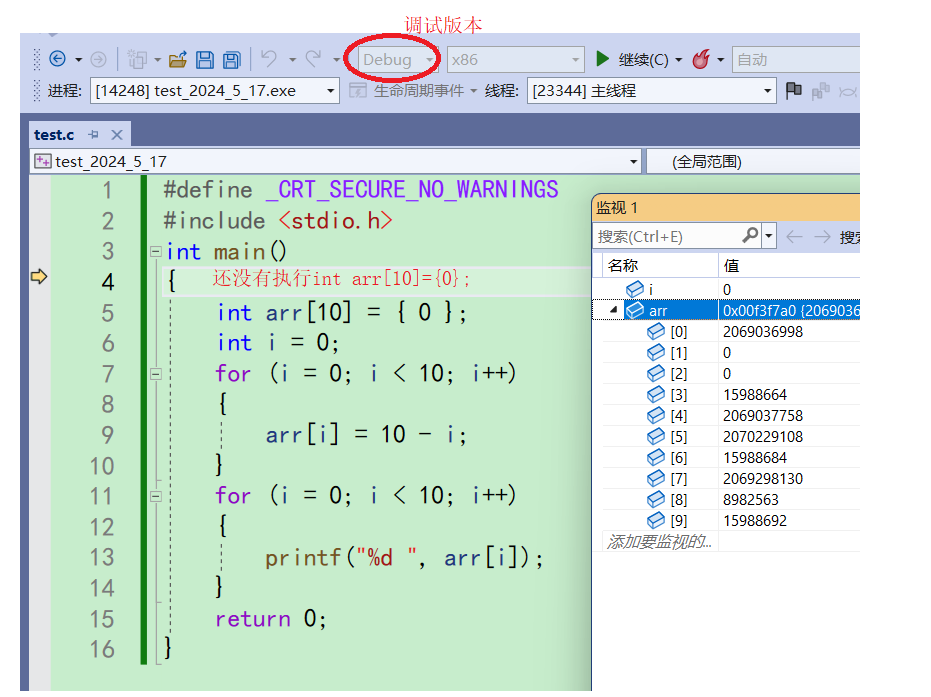
再按一下f10,走到了第5行

再f10,创建arr,可以从监视窗口看到,arr里面的值全部初始化为0了。并且来到第6行

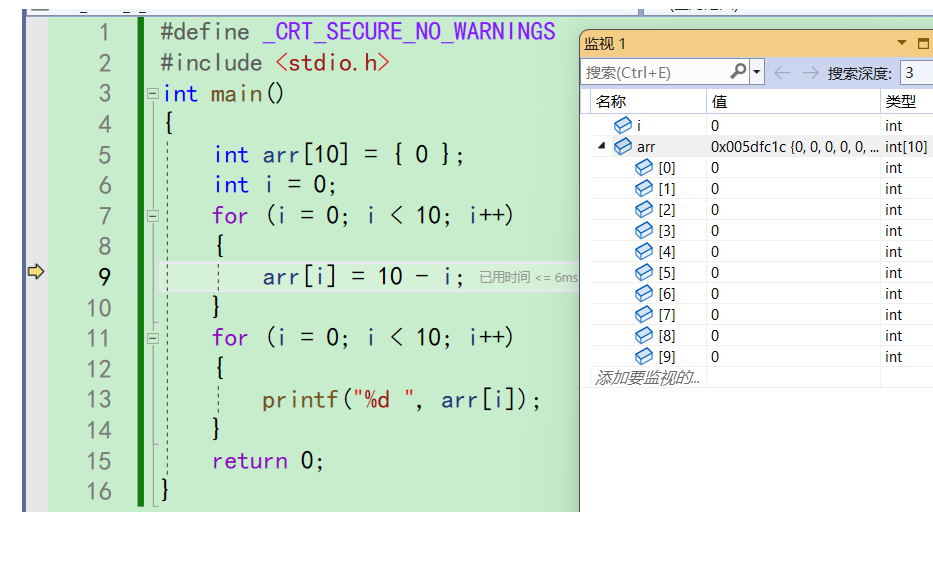
再f10,创建了i,可以看到i的初始值为0。程序来到第7行

这个时候,i为0,小于10成立。按f10就会进入循环,来到第9行
这时i为0,arr[i] = 10 - i;将10赋值给arr[0],所以这个时候按一下f10,就能发现arr[0]的值变成了10,箭头来到第10行

这次循环就结束了。再按f10就会来到第7行,循环的调整和判断部分
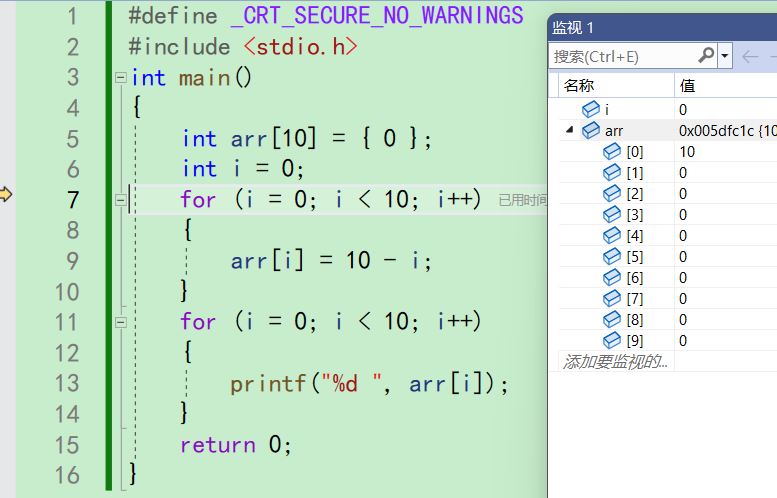
i++,i变成1,1还是小于10。还要进入循环,来到第9行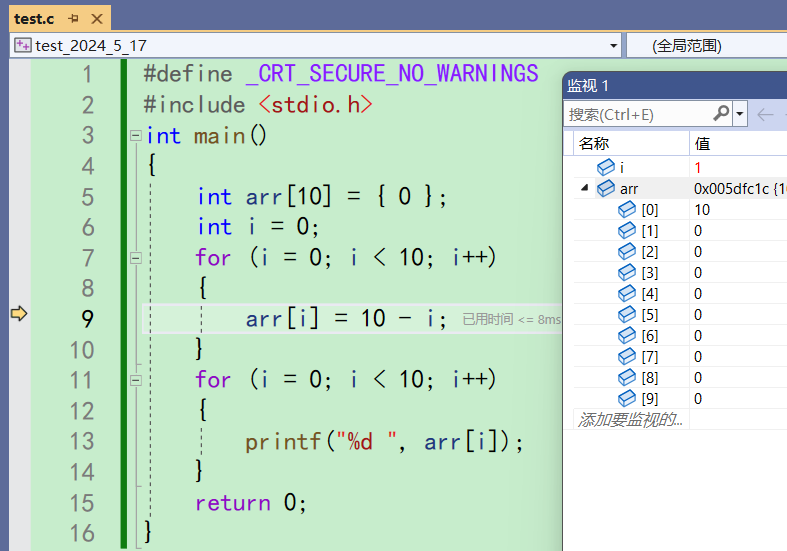
之后一直第7行第9行一直循环到第9次循环结束时候,i为9,arr[8]为0的时候
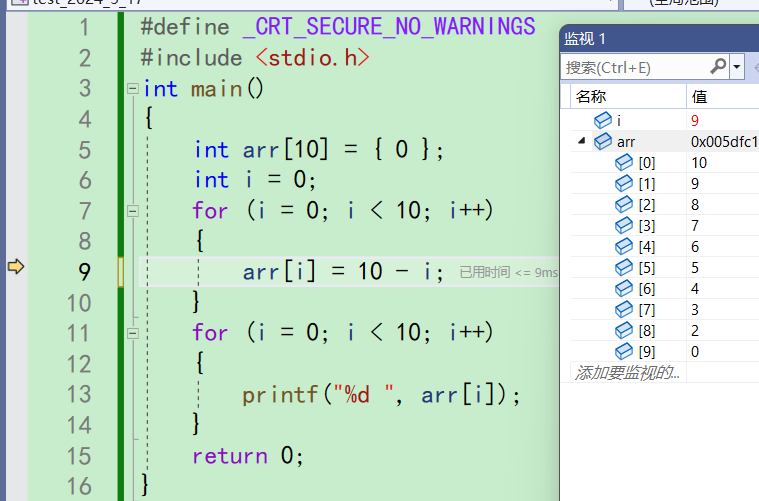
将1赋值给arr[9],之后再来到循环的调整和判断部分
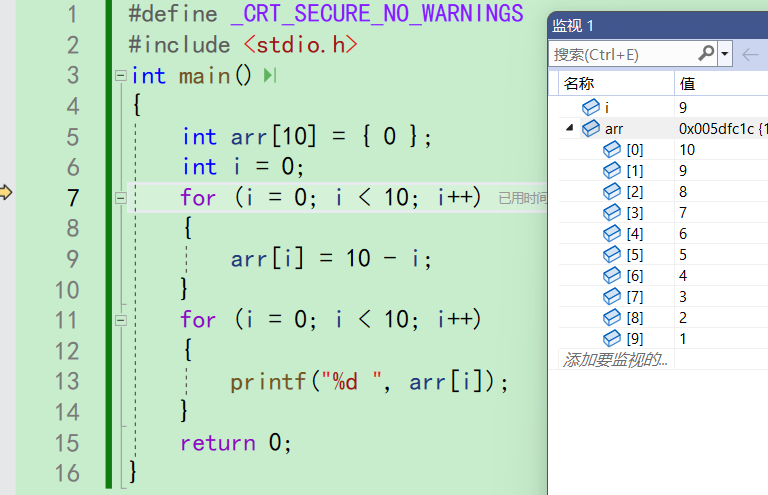
i++,i变成10。10不小于10,判断为假,不再进入循环。再f10,就会来到11行
从这里就可以发现,在Debug版本下,f10能调试每一步。 -
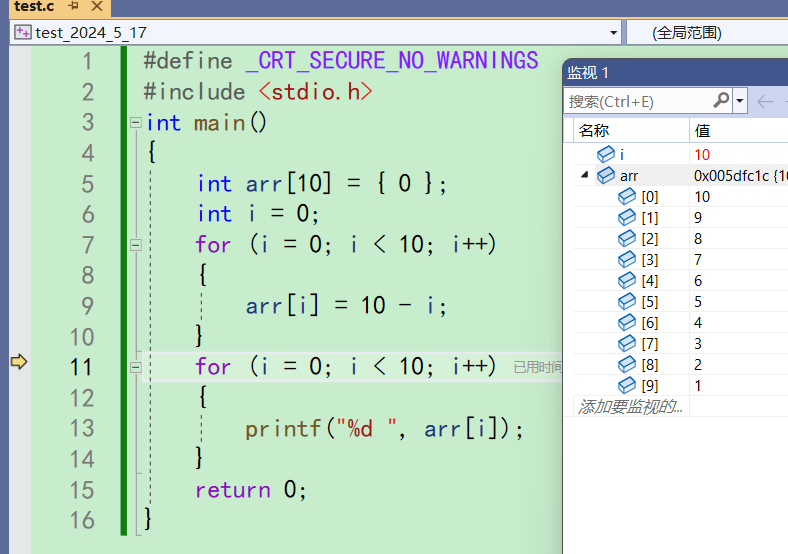
来调试一下Release版本,看看是什么现象
此时此刻箭头还在第4行。按一下f10看看
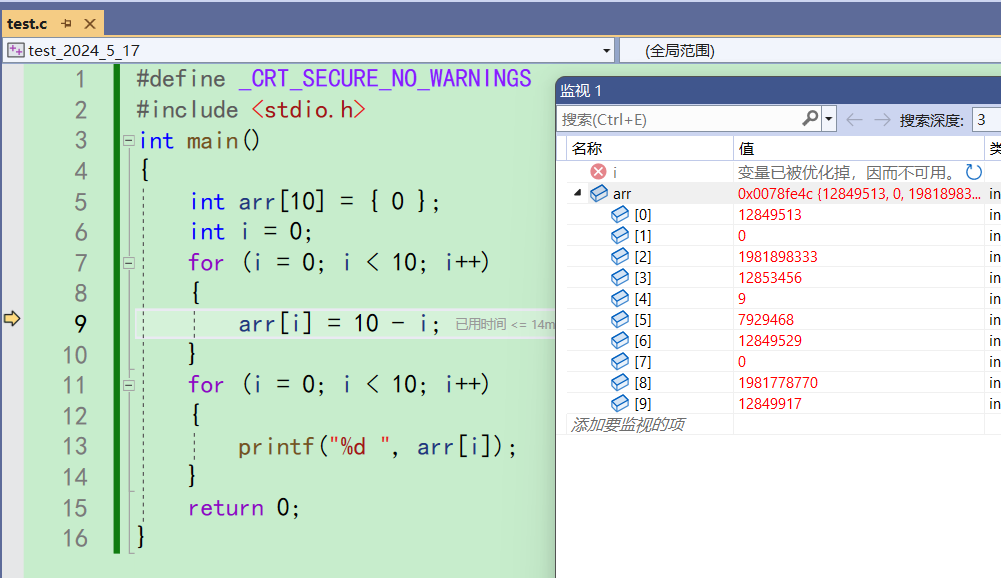
直接来到了第9行,而不是一步步来。再f10

来到11行,第一个for循环都结束了。但是ar都没有完全改完。再f10
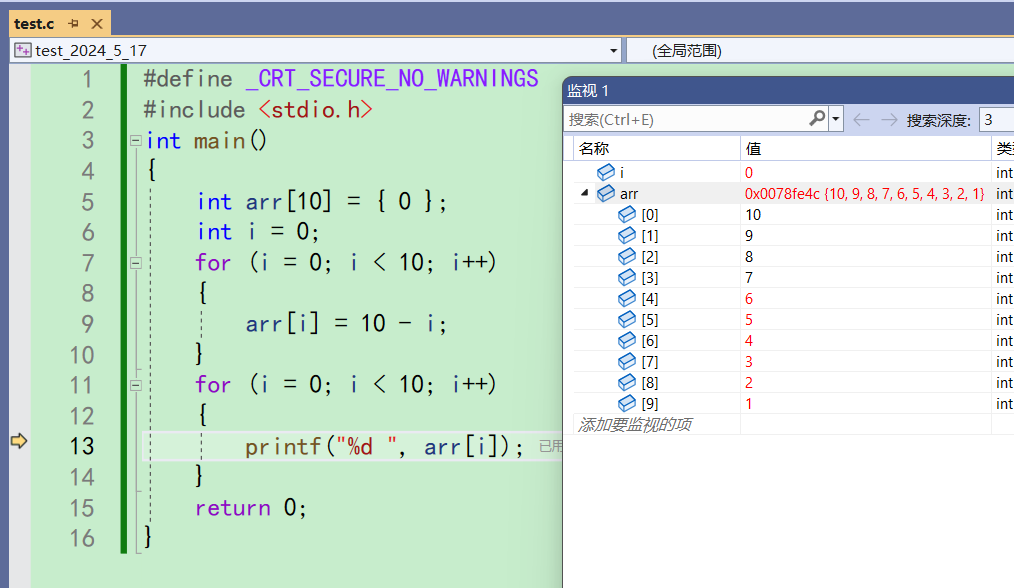
又咔咔一下子改完了arr里的值。就这样你会发现,在Release版本下压根就没办法一步一步调试
所以说Release里面没有包括调试信息,它是不方便调试的。这是因为站在用户的角度看,用户不需要调试,所以Release就没有必要包括调试信息,使得内存更小 -
我们可以在这两个版本下,Ctrl+f5分别生成可执行的exe文件。并且来到这个项目底下就能看到它们各自的文件

所以我们写代码的时候,担心这个程序有问题,就设置成Debug版本。而当你测试过,觉得没有任何问题的时候,就可以设置成Release版本给用户使用。
至于Release版本到底进行了什么优化,后面写的博客介绍
3.Windows环境调试介绍
我们介绍的是Windows环境下的VS
注:linux开发环境调试工具后期是gdb,后期介绍
3.1调试环境的准备
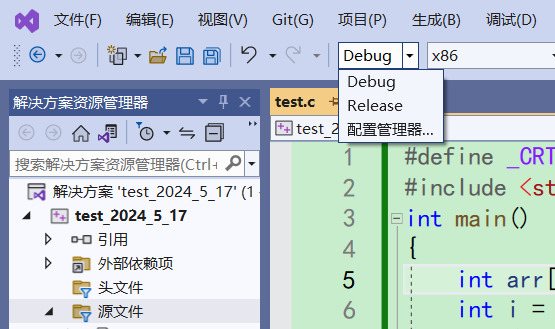
在环境中选择Debug选项,才能进行正常的调试。因为Release已经进行了各种优化,不包含调试信息。
3.2学会快捷键
在Debug环境下,按下f10,进入调试之后可以看到调试里有很多的快捷键

f10和f10
f10:逐过程,通常用来处理一个过程,一个过程可以是一次函数调用,或者是一条语句。
f11:逐语句,就是每次都执行一条语句,但是这个快捷键可以使我们的执行逻辑进入函数内部(这是最长用的)。
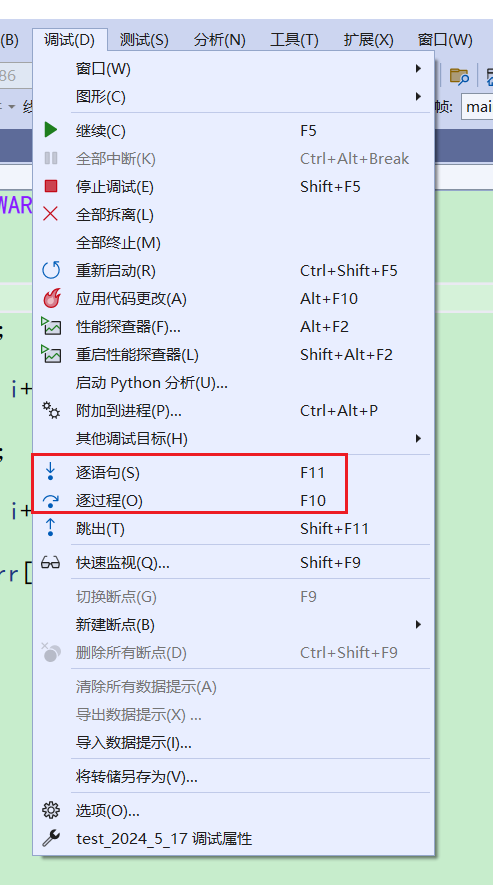
在下面这些普通的雨具f10和f11是没有区别的。都是一条一条代码执行
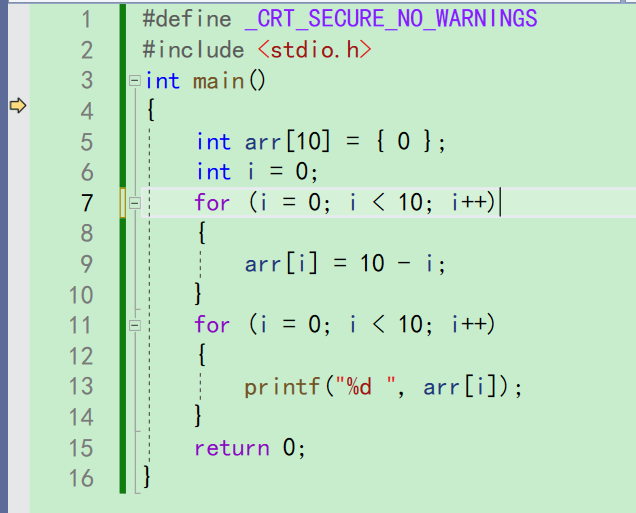
我们加上一个test函数来区别f10和f11
我们直接来到代码的第13行,可以看到控制台什么都没有

这个时候按一下f10,直接来到14行了。没有进入函数,而且屏幕上输出了haha和hello。

这说明按f10是进入不了函数,观察里面的细节的。整个函数被一下f10就走完了。
重新开启一次调试模式,来到第13行的时候按一下f11
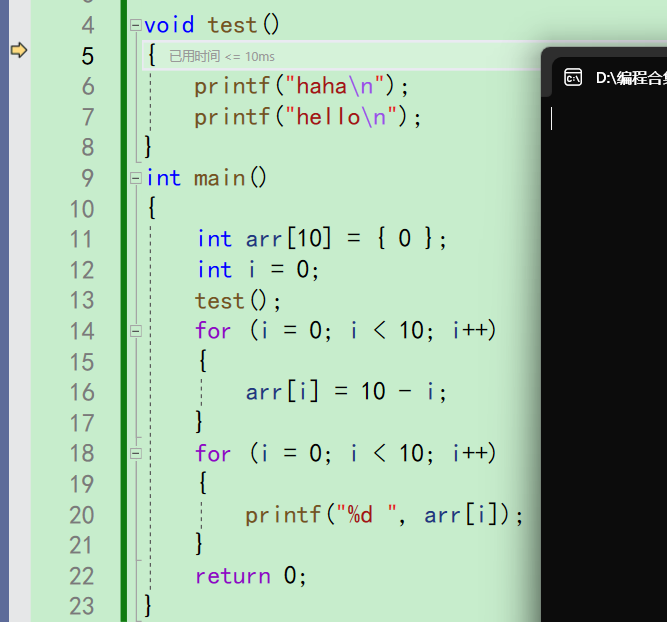
可以看到箭头来到了第5行,进入了test函数。说明f11能够进入函数,观察函数内部的细节。
再按一下f11,什么都没有发生,这是因为还没有执行第6行的打印。
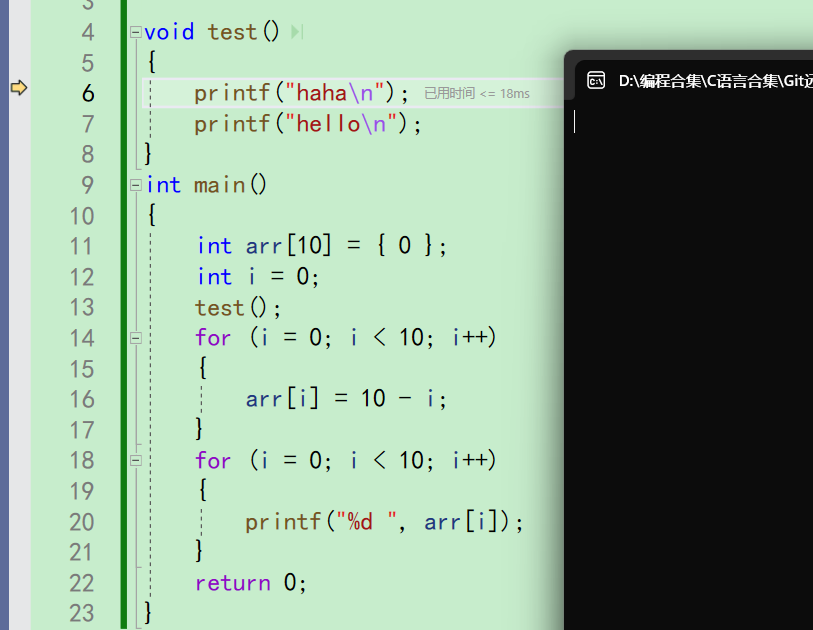
再按一下f11,就可以看到屏幕上打印了haha
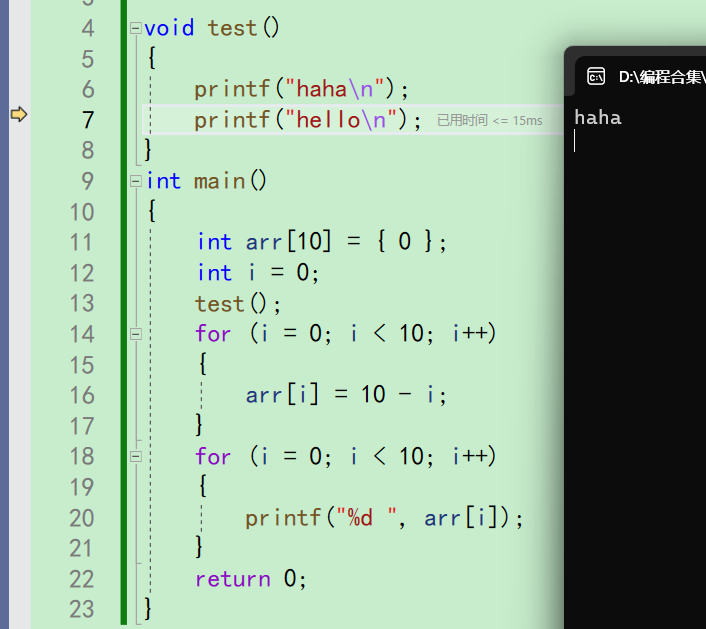
再按下f11,打印hello

再按下f11,就会跳出函数,回到main里。箭头来到14行
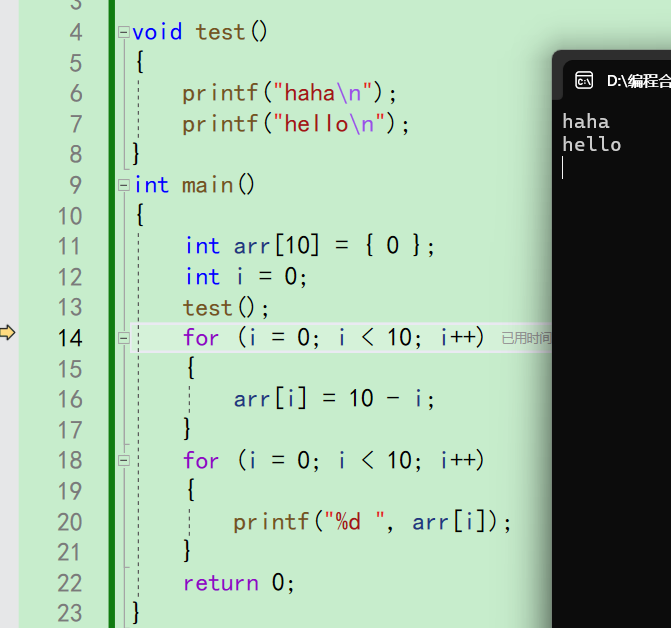
这里就可以看到f10和f11的区别了

所以未来在调试的时候遇到函数,按f10还是f11就看你的需求。不能觉得f11更细致,就一直按f11。比如有一天你写了一万行的代码,要调试一下。但是你大概知道第5000行,出现了错误。然后5000之前的代码里有各种各样的函数,函数里面又有非常多的嵌套循环,执行完成这一个循环要100,1000次乃至更多。这个时候你想要来到5000行,f11都会按冒烟的啊。
f11可以进入函数观察细节,但是如果我觉得这个函数没有问题,那么就按f10不进入这个函数。所以说按哪个要根据需求来定
f5和f9
f5:启动调试,经常用来直接跳到下一个断点处
f9:创建断点和取消断点。断点的重要作用,可以在程序的任意位置设置断点。这样就可以使得程序在想要的位置随意停止执行,继而一步步执行下去。

-
f5和f9是配合使用的
有可能你是直接按f5,结果直接出来了
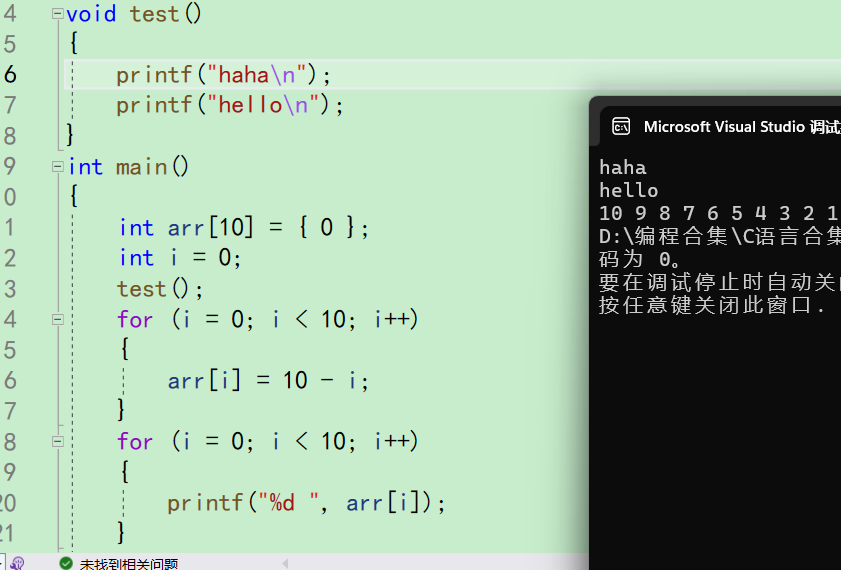
结果直接出来了,没有调试过程 -
f5叫做开始调试,如果中间没有断点拦截它,就会直接执行完代码。f9是新建/切换断点。
比如说现在,你认为20行前面的代码都没有问题,而问题出现在打印上。鼠标点到20行,按一下f9

-
这个时候和f5配合使用。代码会快速执行,直到来到20行,突然停下来。并且进入调试模式

走到这里因为前面20行的代码已经执行完了,右边监视窗口也可以看到数组arr已经赋值好了 -
此时此刻第一次进入循环,i为0。还没有开始打印。

-
现在可以按f10观察里面的细节。f10走一下,来到21行,打印arr[0],也就是10
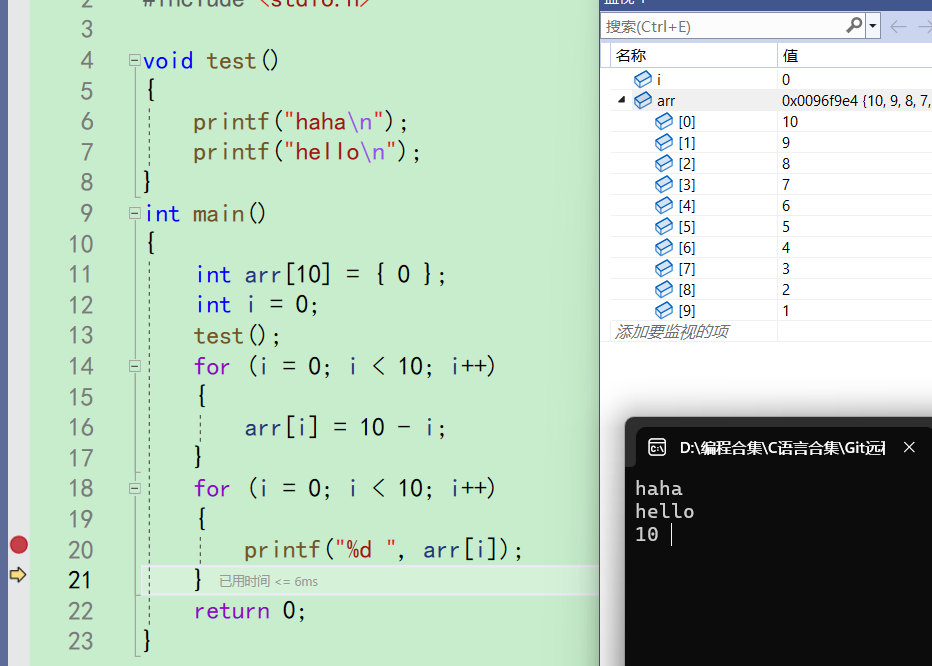
-
f10来到18行,循环的调整和判断部分
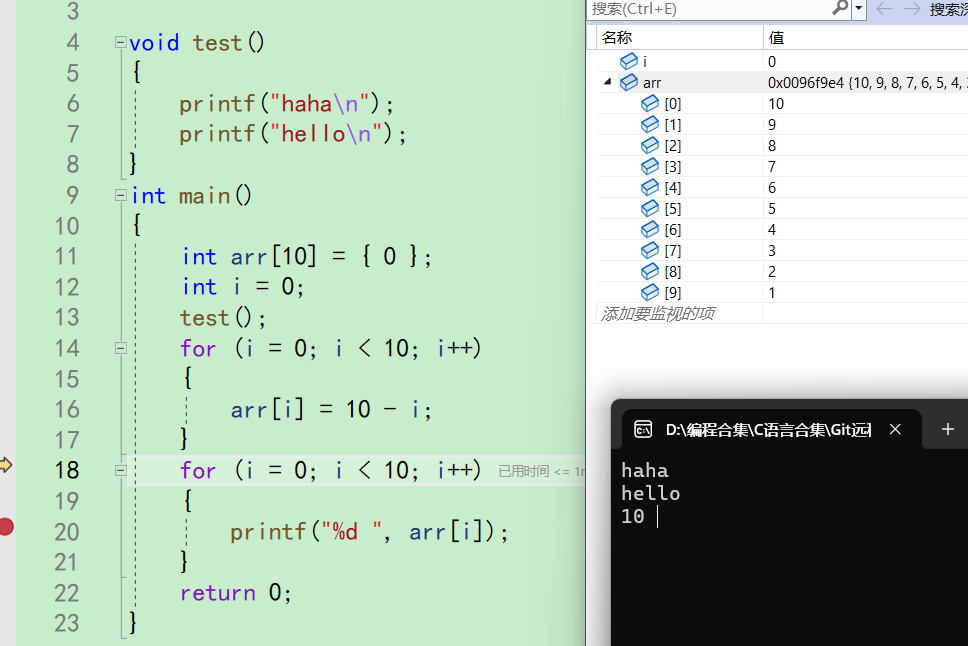
-
i++,i变成1。i<10成立,再次进入循环来到20行
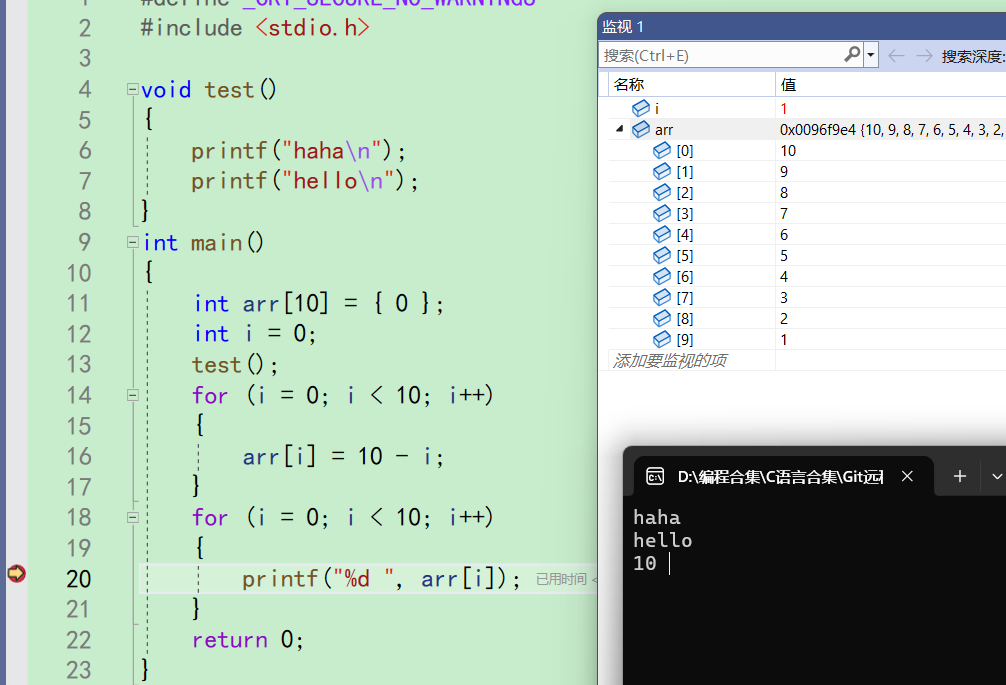
-
f10再走一下,打印arr[1]

之后一直走完。从上面就可以看出f5和f9配合使用起来了。f9设置一个断点,然后f5快速走完断点前的代码,来到断点处。来到断点处再f10,f10往下走。所以说你需要快速来到你认为出现问题的地方,就可以f9设置一个断点,再f5开始调试。断点前的代码就会快速执行,来到断点处停下来。然后就可以f10观察问题的细节。 -
断点是可以设置多个的。比如说你觉得为arr初始化的for循环可能有问题,也可以在16行按f9。再按下第一次f5的时候,就会来到16行,去观察里面的细节。
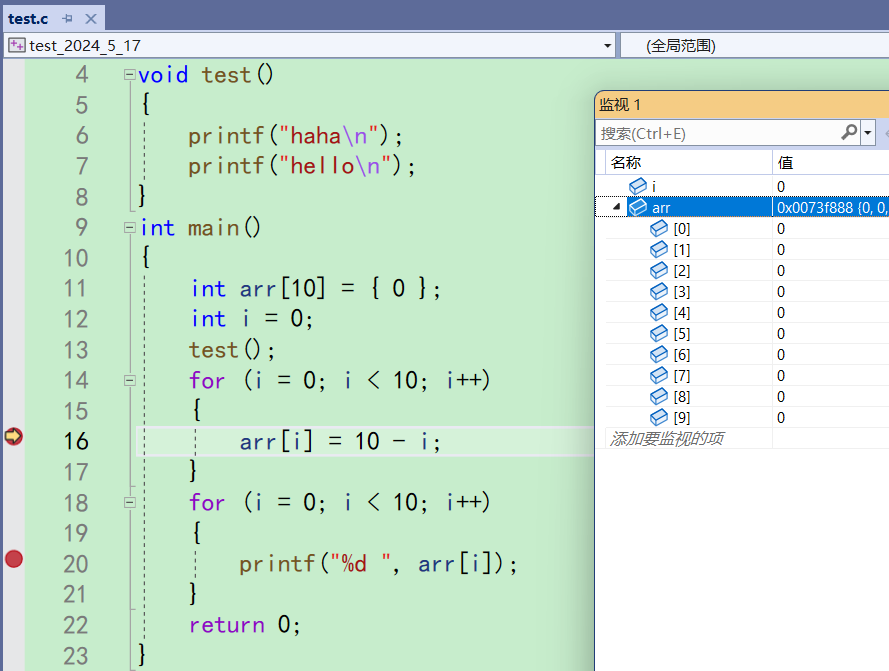
-
当你觉得这个for循环观察完之后,想去到下一个断点。直接按f5是不行的,代码还会来到16行。而且i的值变成了1,,arr[0]变成了10。说明执行了一次循环
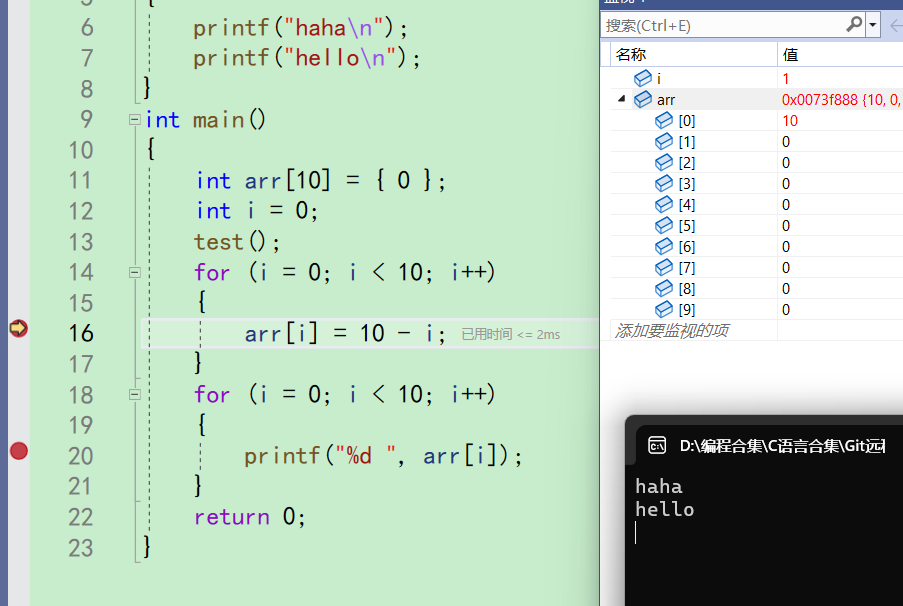
再f5还是来到16行,循环又执行了一次
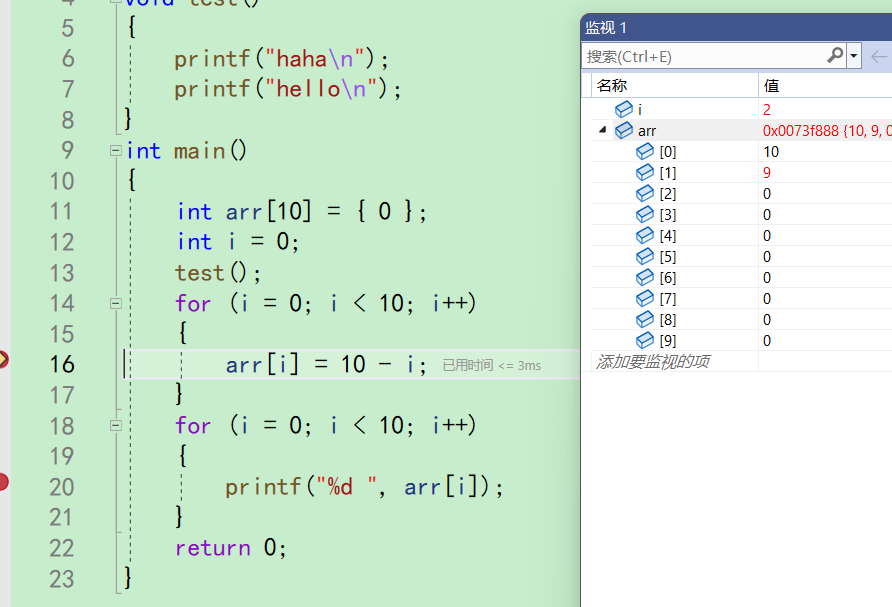
之后f5,会一直来到这个断点处。这是因为循环还没有走完,循环再次执行的时候,遇到这个断点,又停下来了。

其实f5已经在执行代码,往下走了,但是这里是循环。代码从16行按f5后,默默的往17行走,17行走了之后,发现循环还没有结束。又来到14行,发现还要进入循环,默默的来到16行。16行发现有断点啊,所以停下来了。
因此给我们看到的现象是f5一直在16行。所以f5是让我们的代码执行到下一个执行逻辑(实际上要执行的一行的代码的每一次断点处)上的断点上停下来,而不是物理断点(表面看到的断点处)上停下来 -
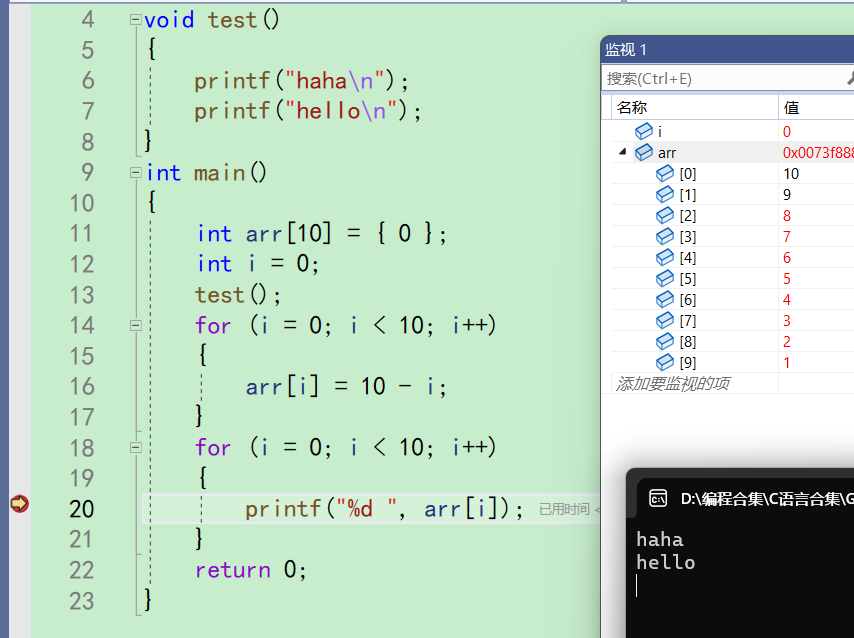
如果说我们觉得第一个断点处,也就是16行,问题已经排查好了。想来到下一个断点处,就可以在16行按一下f9。16行的断点就会取消掉

-
这个时候如果再按一下f5,又会来到20行的断点处
这样使用f5和f9配合调试的速度就会快很多,否则从main函数开始f11来调试,键盘都会按冒烟啊 -
f9还有一个技巧。比如说我们想来到16行里的for循环,但是我不想i从0开始,我想让i是5的时候停下来。就可以鼠标右击设置好的断点上,点条件。条件里面就可以加条件
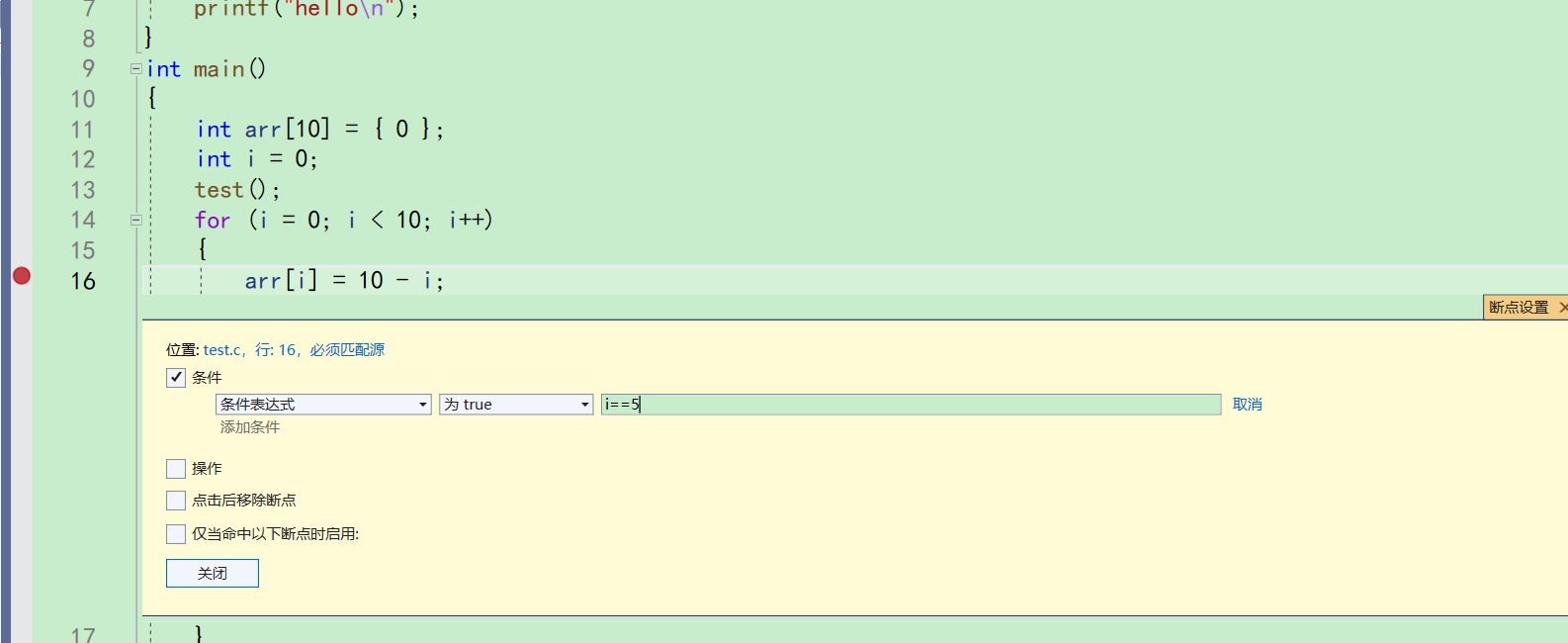
这里的意思是i等于5的时候,才触发这个断点。现在按下f5
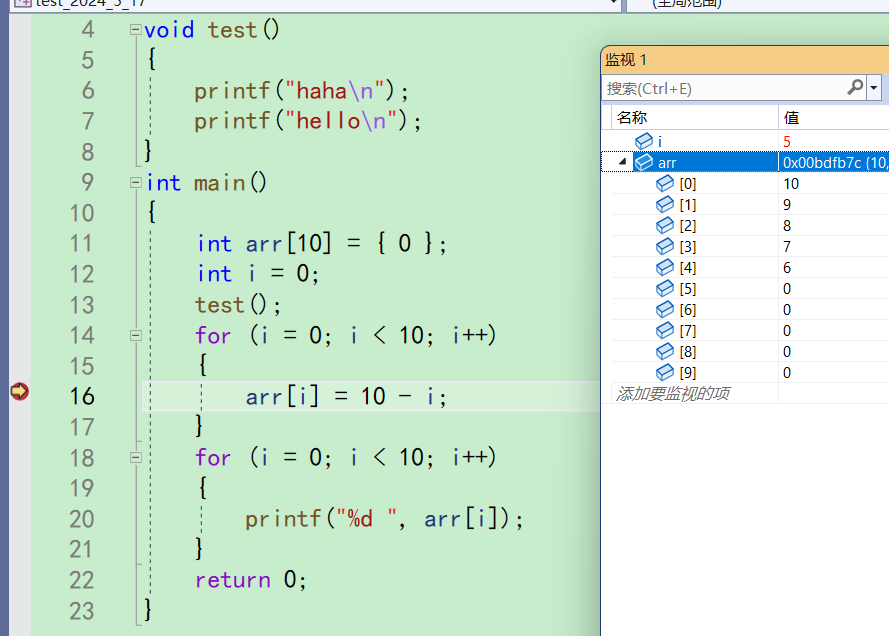
当然这里也可以加其他条件,看你自己的需求
Ctrl+f5
开始执行不调试,如果你想让程序直接运行起来而不调试就可以直接使用
如果现在你设置了一堆断点的话,按Ctrl+f5也不会在断点处停止。因为断点处要调试才停下来,而Ctrl+f5是开始执行不调试,所以不关心断点
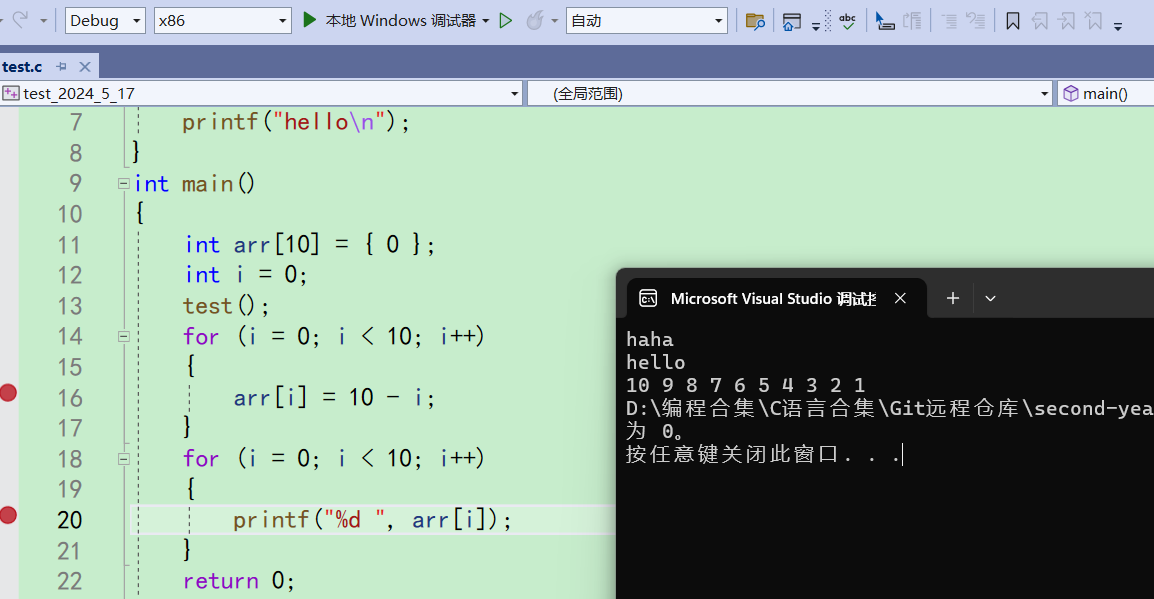
3.3调试的时候查看调试当前信息
3.3.1查看临时变量的值
在调试开始之后,用于观察变量的值
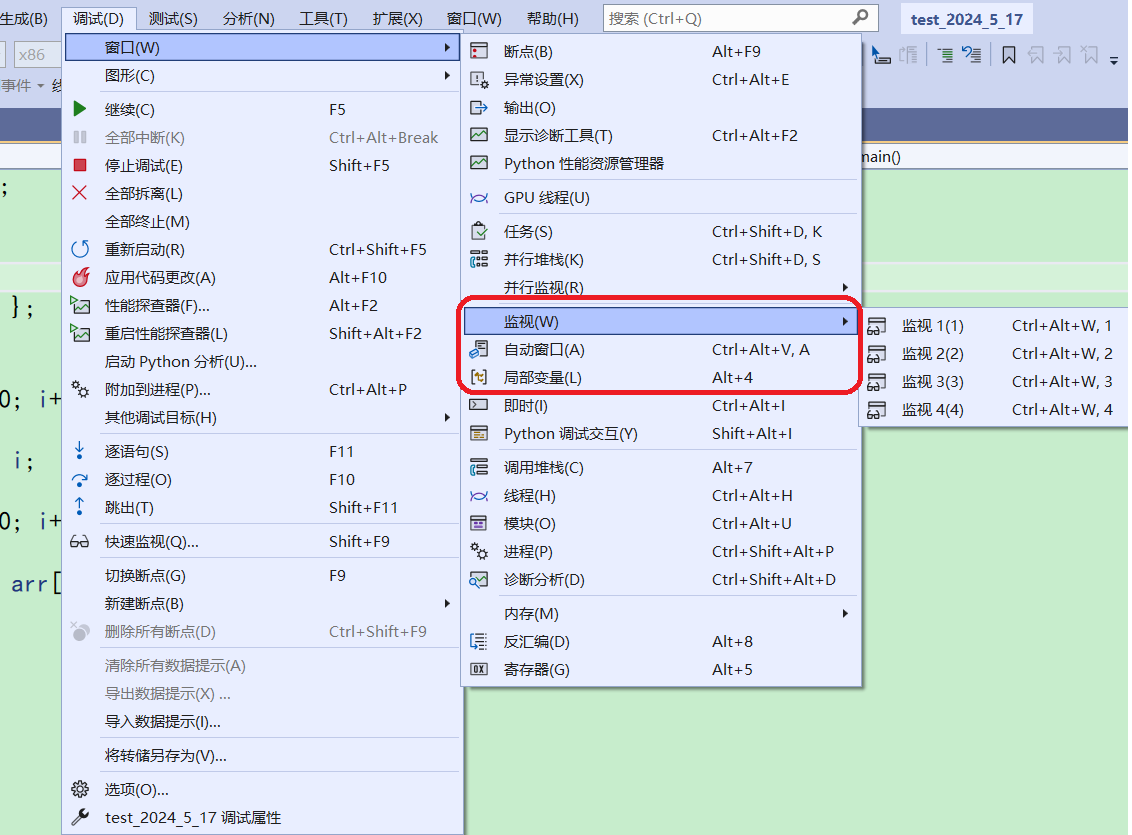
这三个窗口都能观察变量的信息
-
点开自动窗口之后,刚开始什么都没有
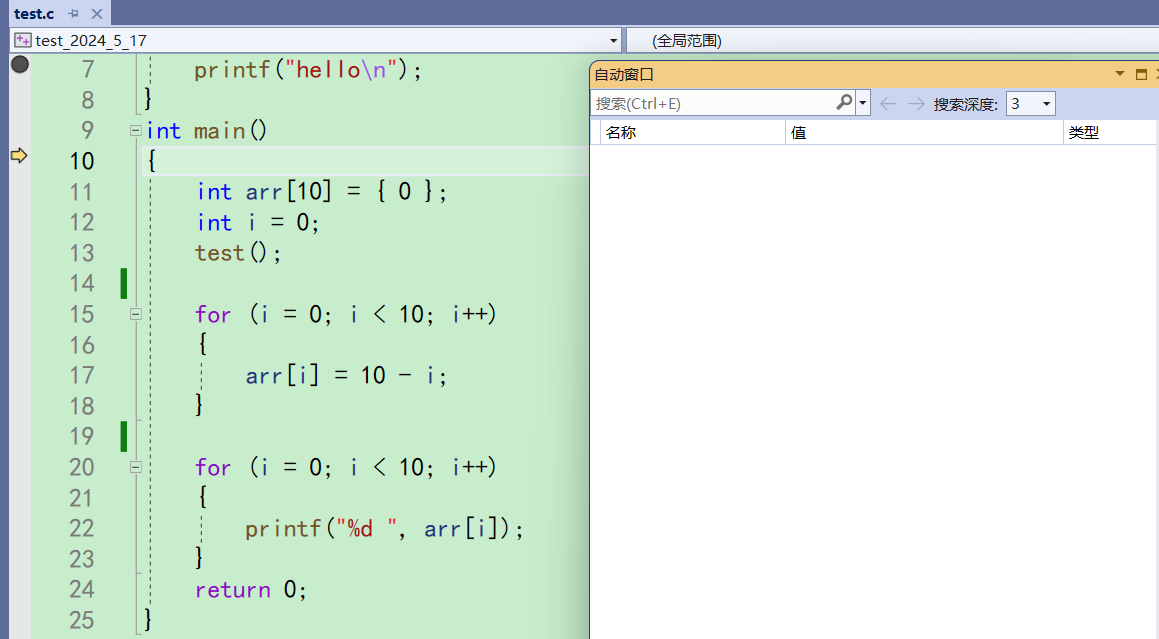
按一下f10来到11行,arr自动出现了。它里面还是随机值,因为在为main函数开辟栈帧的时候,被设置成了CCCCCCCC的随机值。执行完创建代码的时候才会变成0
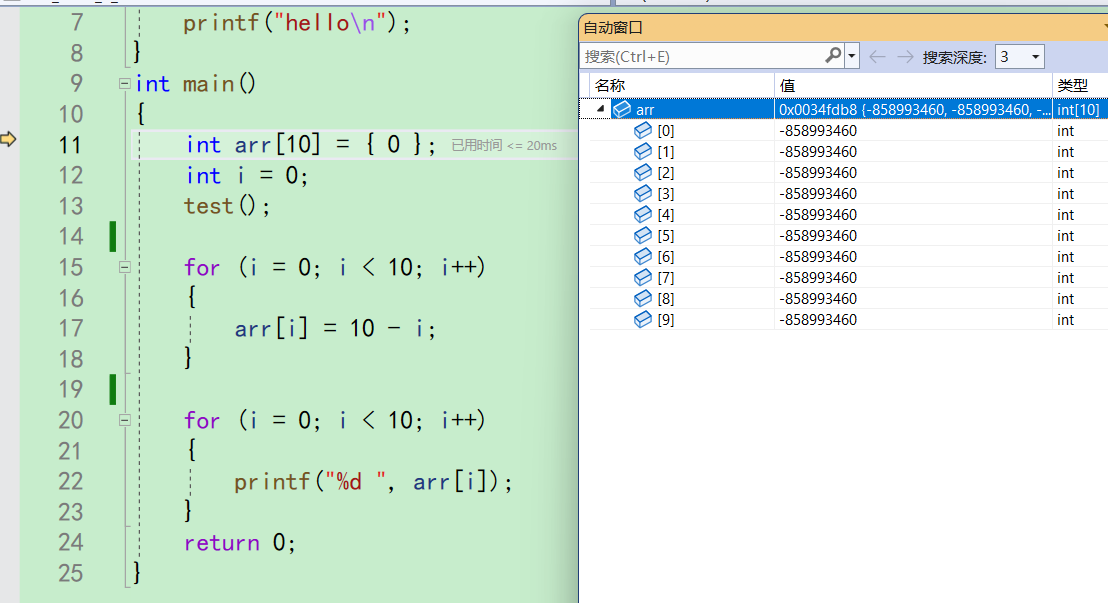
arr里面的内容变成了0,再f10来到12行,i也自动出现了。i同样是随机值。
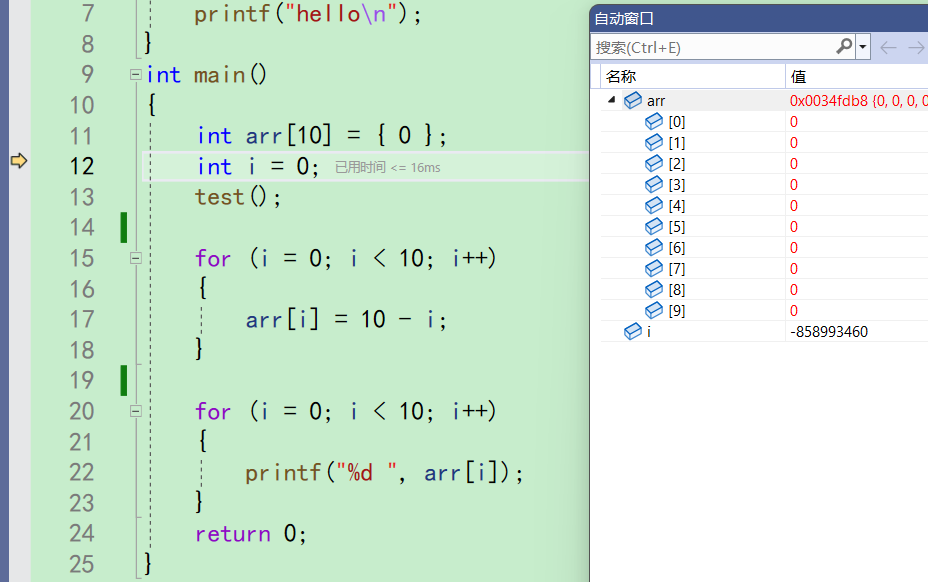
再f10来到13行,i的值初始化为了0。同时屏幕上没有打印

再f10直接来到15行,,跳过了14行,而且arr消失了。
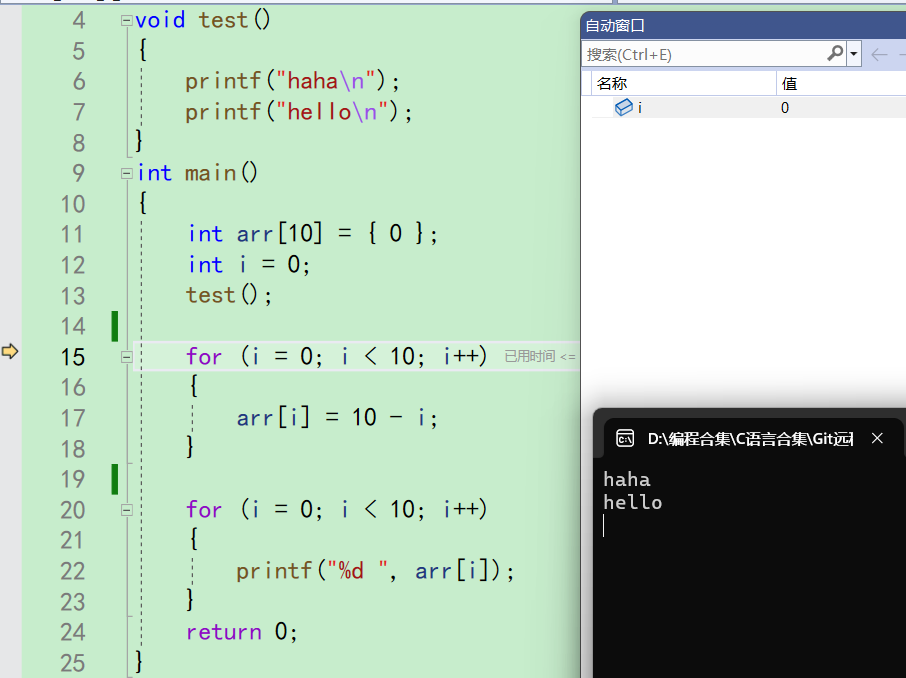
再按f10,arr又出现了。而且多了一个arr[i]

这就是自动窗口,它会根据程序上下文的环境中的信息,自动、默认的加上一些编译器认为重要的变量,自动的去掉你可能不需要的变量。
这个自动窗口不太好,因为如果正在看一个变量,又突然没了,就不方便 -
局部变量跟自动窗口很相似,会监视程序执行过程中上下文环境中的局部变量
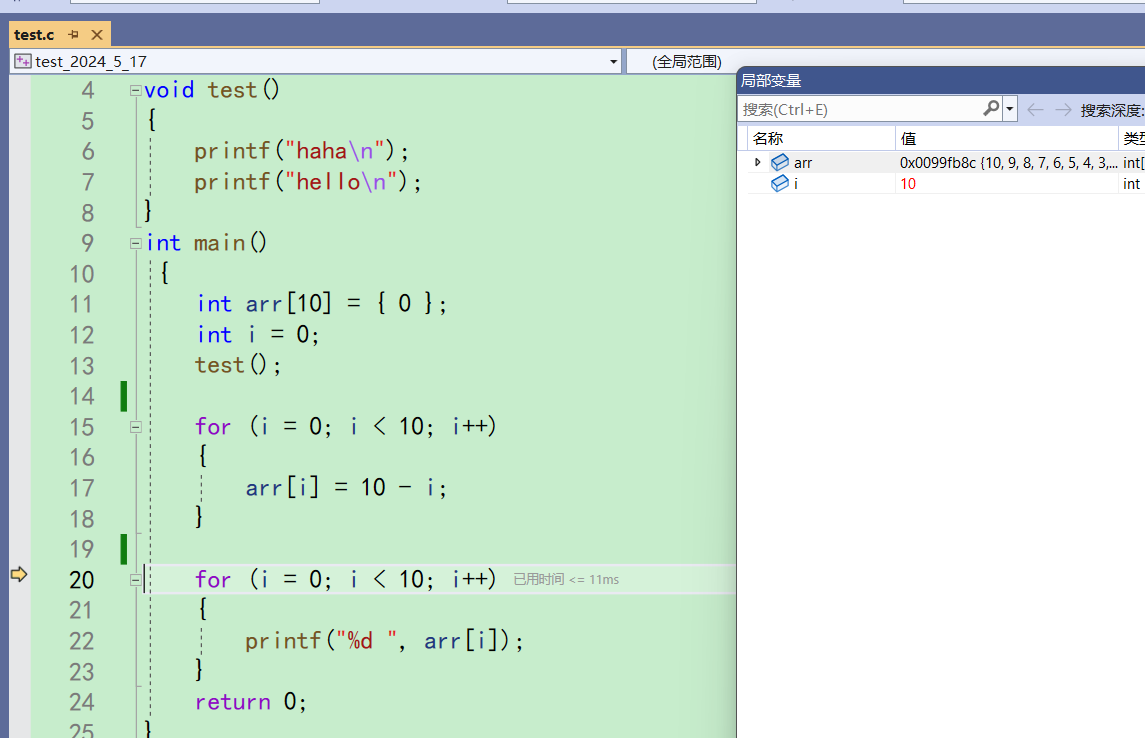
不需要你输入就自动监视了arr和i。但是有一个不好的点,就是不能自己加上想要观察的变量 -
监视窗口,才是我们真正最常用的监视变量的功能。
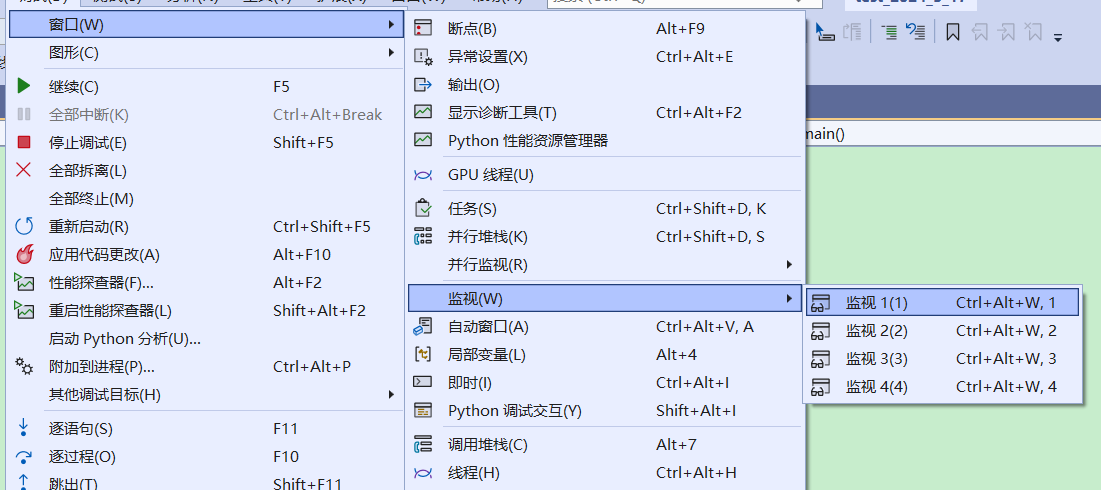
可以看到有很多的监视窗口,这些监视窗口之间相互独立。当你有很大的屏幕的时候,可以都开启,就可以观察到非常多的数据。
最开始点进去之后什么都没有,一片空白。
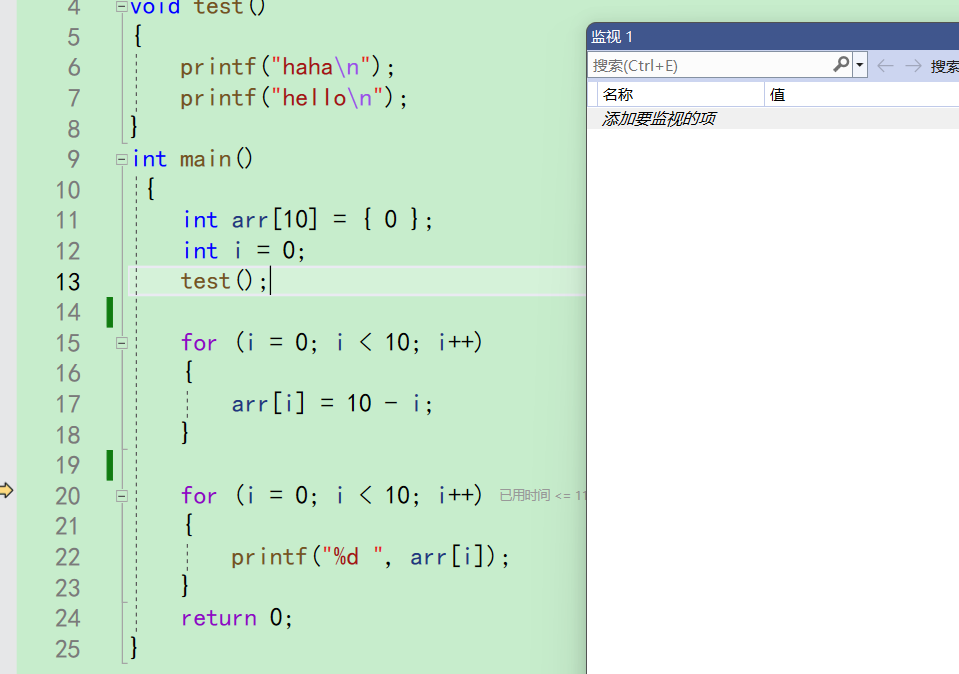
你想监视什么数据,就输入什么数据。而且这些变量并不会随着程序的执行而消失。
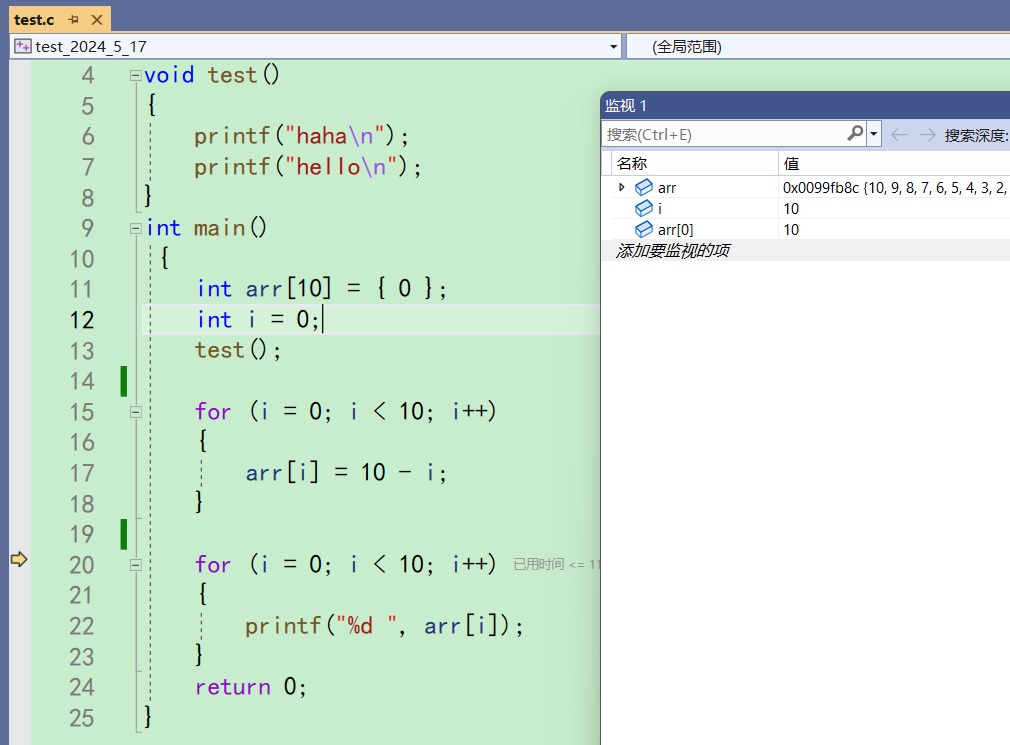
但是监视的最好的是合法的,程序存在的。如果随便输入一个程序没有的bbq,监视也不知道这是什么
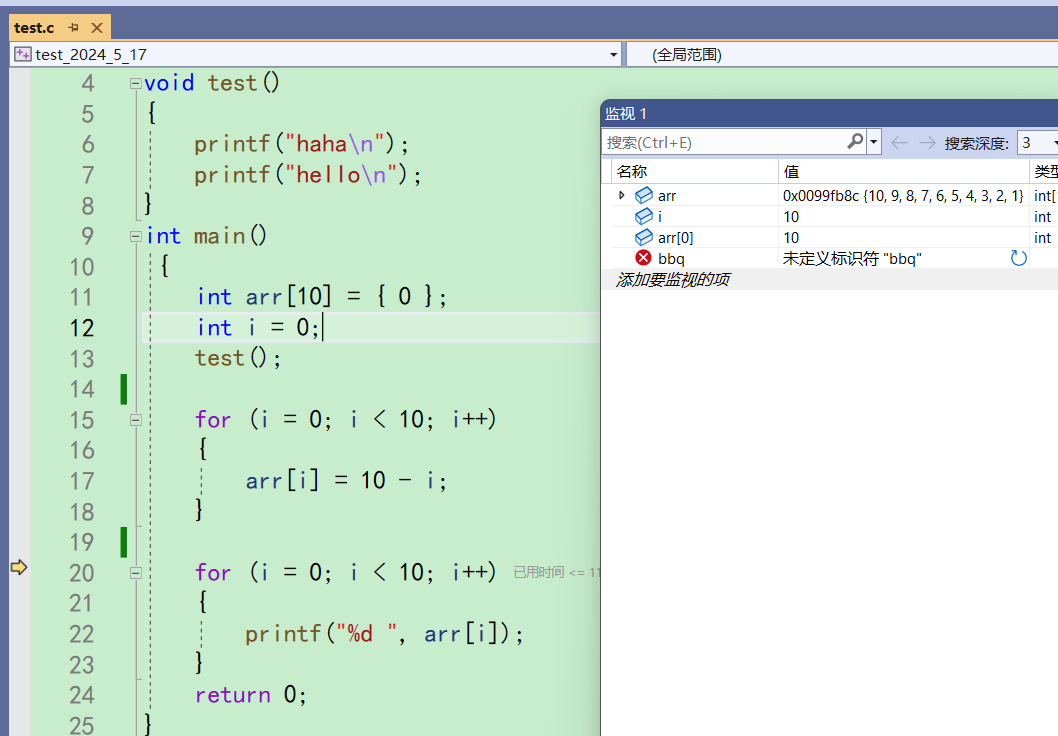
监视窗口想监视什么就监视什么,不想监视就直接删掉。因此我们用的都应该是监视窗口
3.3.2查看内存信息
在调试开始之后,用于查看内存信息
-
比如现在在监视窗口可以观察到arr,也可以打开内存观察arr
打开之后,会显示很多列,一行里的一列代表一个字节,但是这样不便于观察。可以在内存窗口右上角把它调成4列,也就是一行4个字节,这样就方便观察了
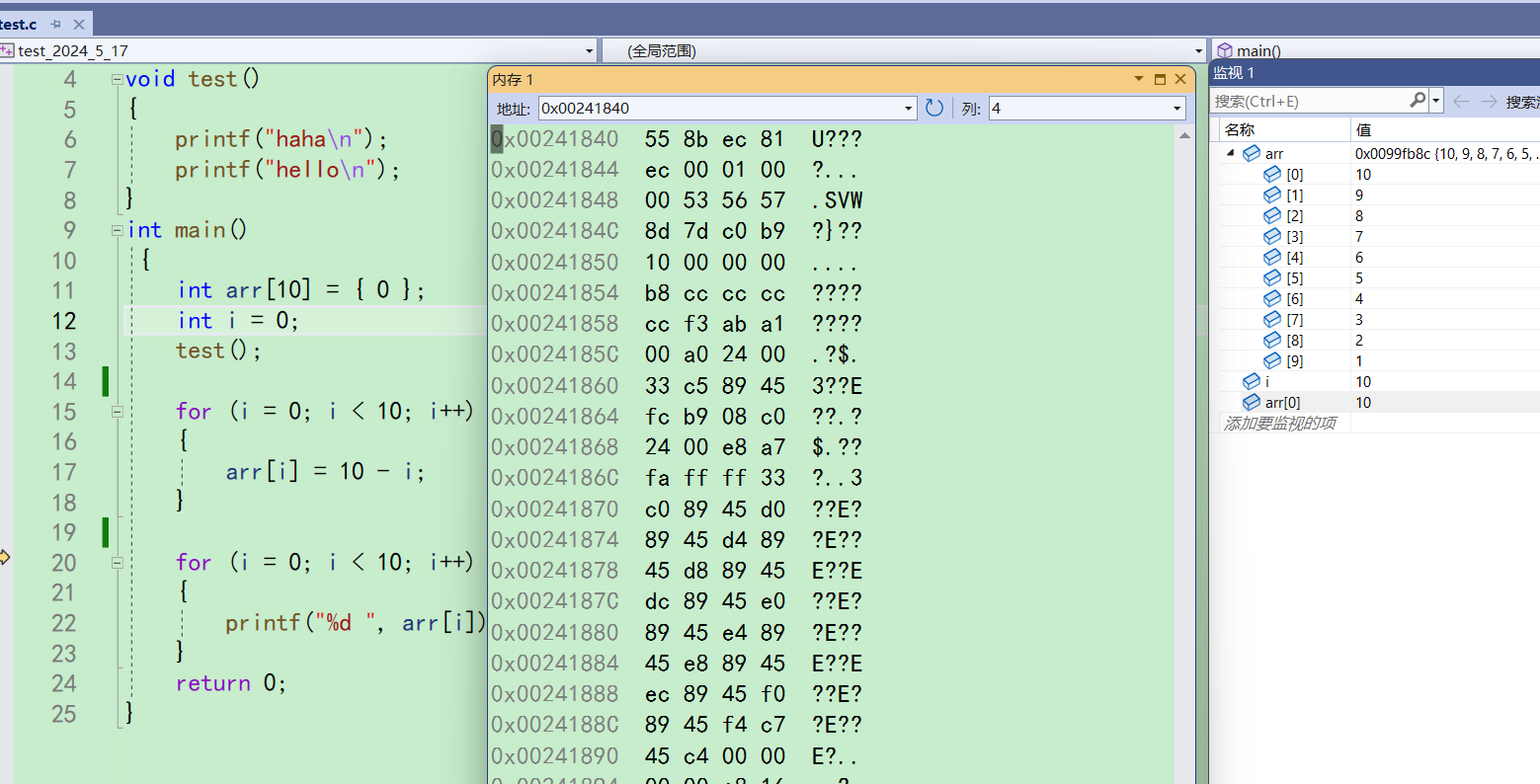
-
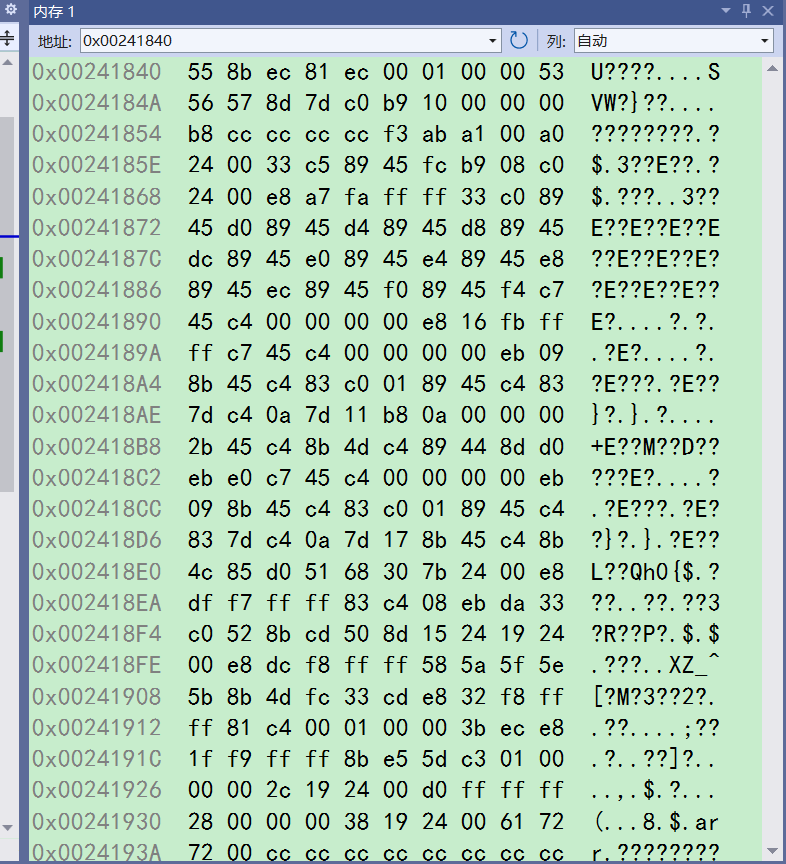
想要观察arr就输入,&arr。这样就能查看arr所在空间的内容了
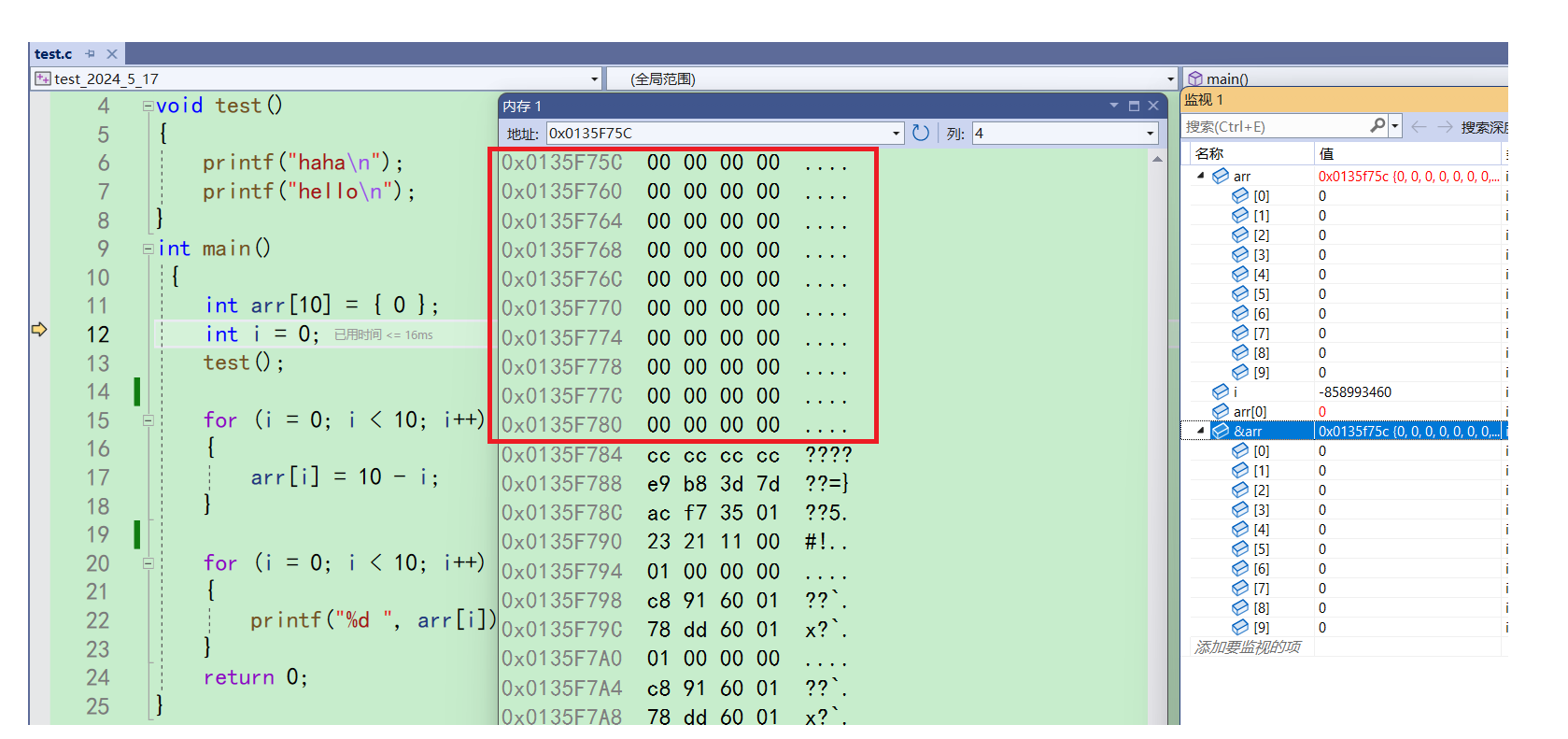
一行4列,4字节,一个int类型。从arr首元素地址0x0135f75c开始,一共10行0,也就是40字节,即10个整型。说明arr的内容确实被初始化为0了 -
按f10,内存窗口的内容也会跟着程序的执行改变的。比如现在第一次进入for循环,来到17行。
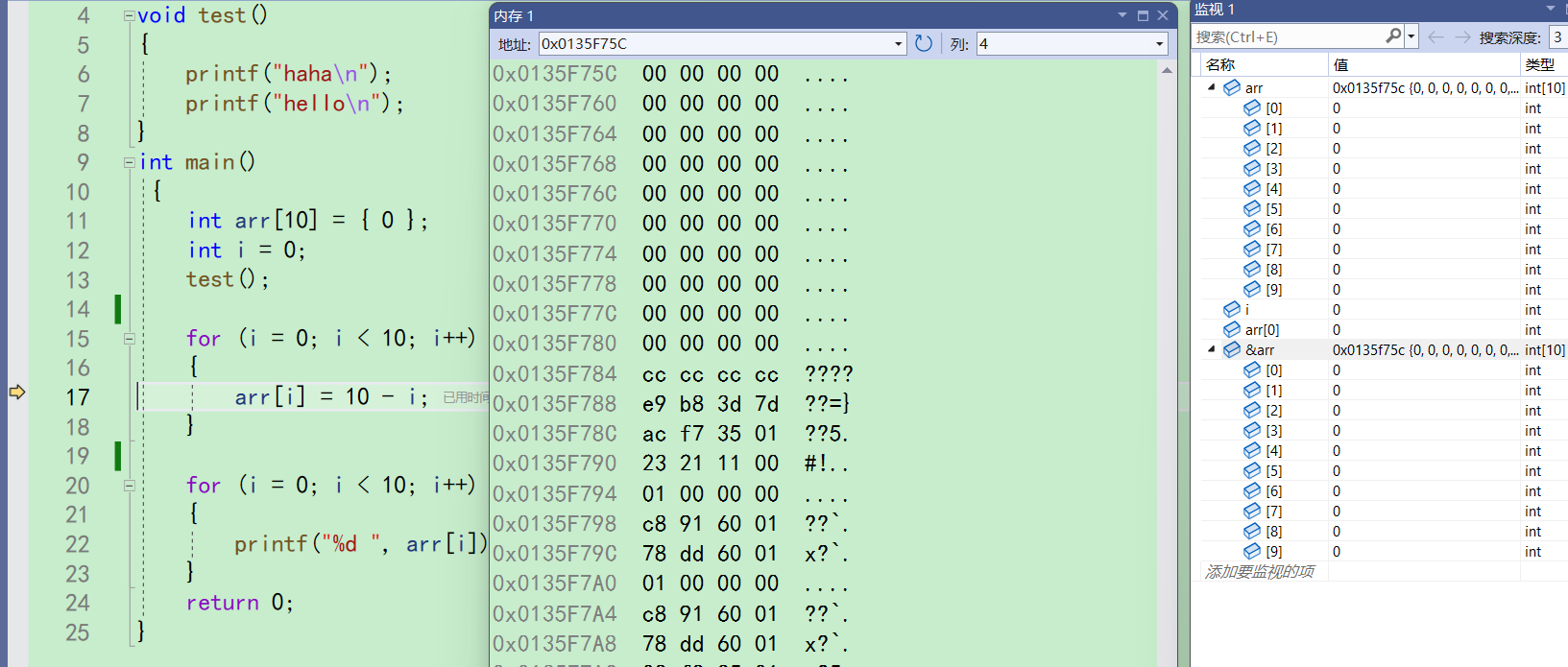
只要走完这一行,arr首元素也就是arr[0],它的地址就是0x0135F75C,会被改成10,在内存中数值是倒着放的,也就会被改成0a 00 00 00。
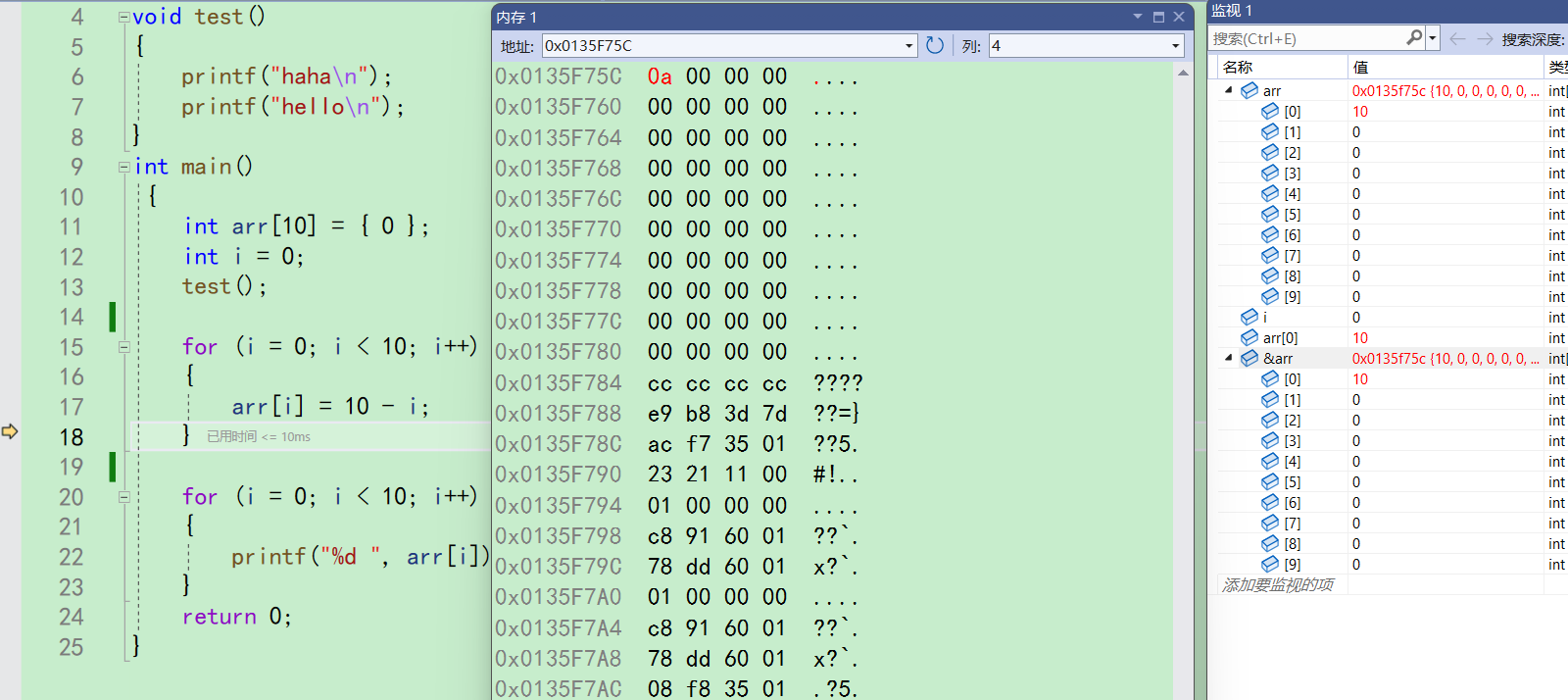
至于为什么倒着放,以后介绍
3.3.3查看调用堆栈
-
现在重新写过一份代码,来解释什么是调用堆栈

这个时候,我们想去看他们的调用关系的时候,可以打开调试窗口的调用堆栈

点开之后,默认是这样子的界面
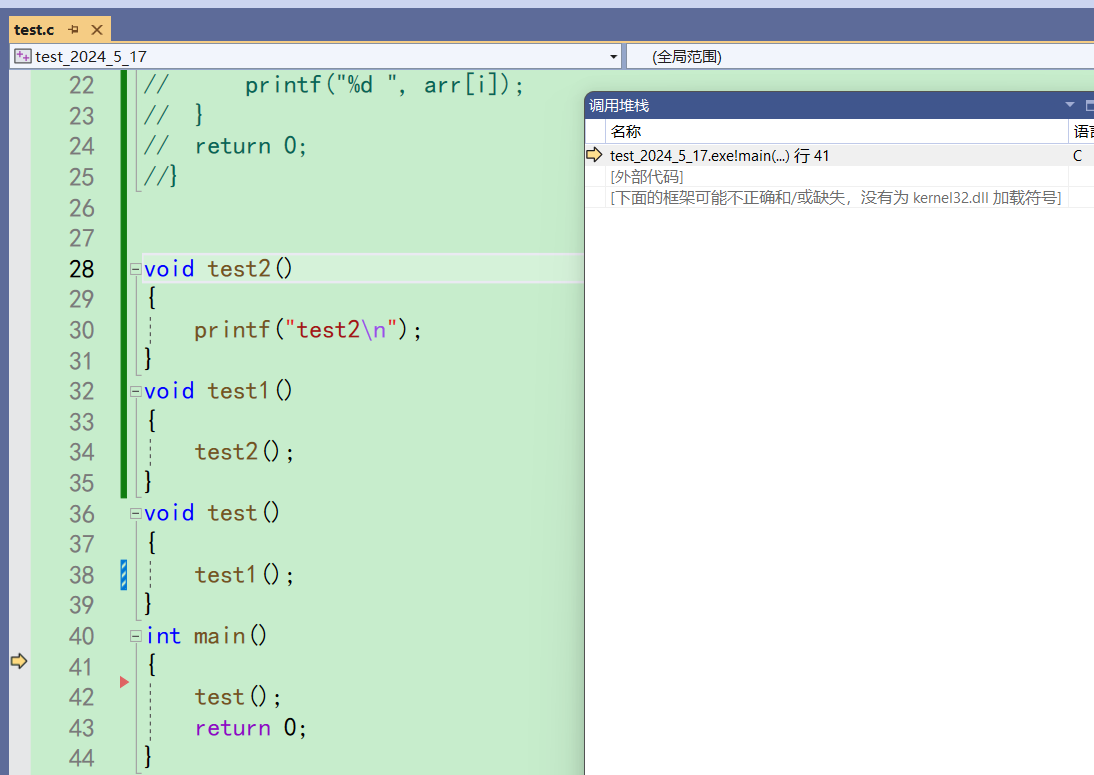
我们按f10来到42行之后,再按下f11进入test函数。调用堆栈窗口又多出来一行
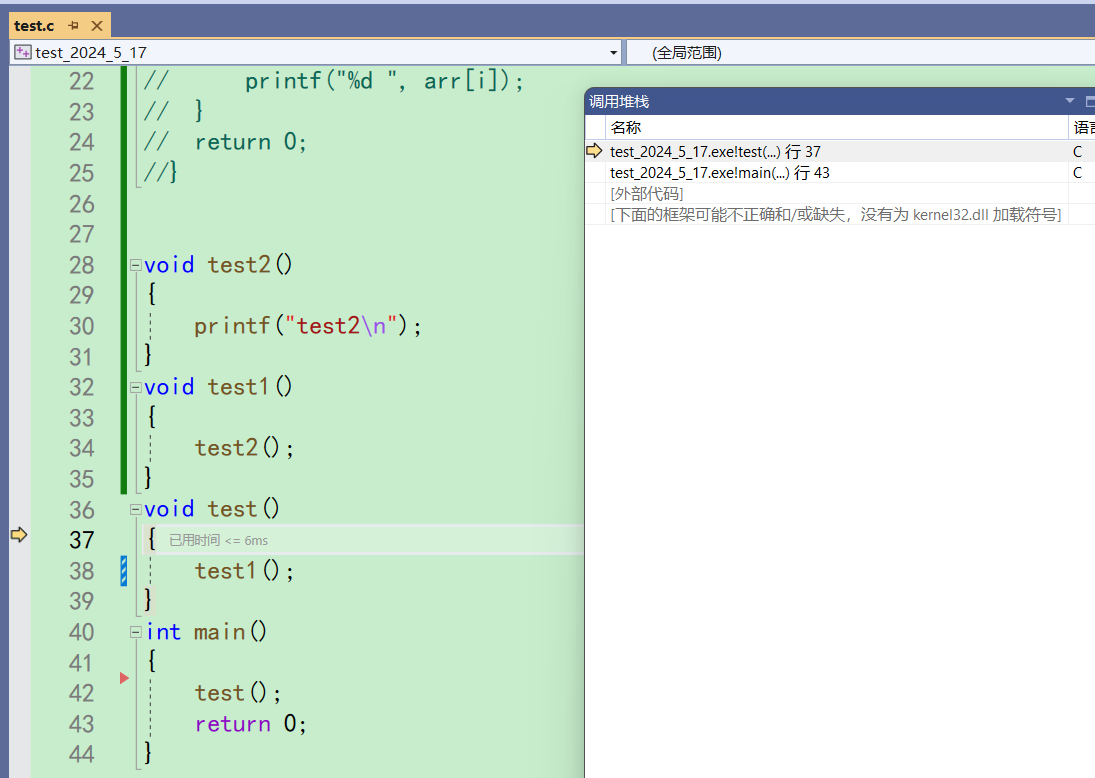
之后一直f11走到test2里,调用堆栈窗口这里就在反馈一个函数调用关系

当代码来到31行的时候,马上就要结束test2

此时按一下f11,test2函数调用结束。调用堆栈的test2就消失了
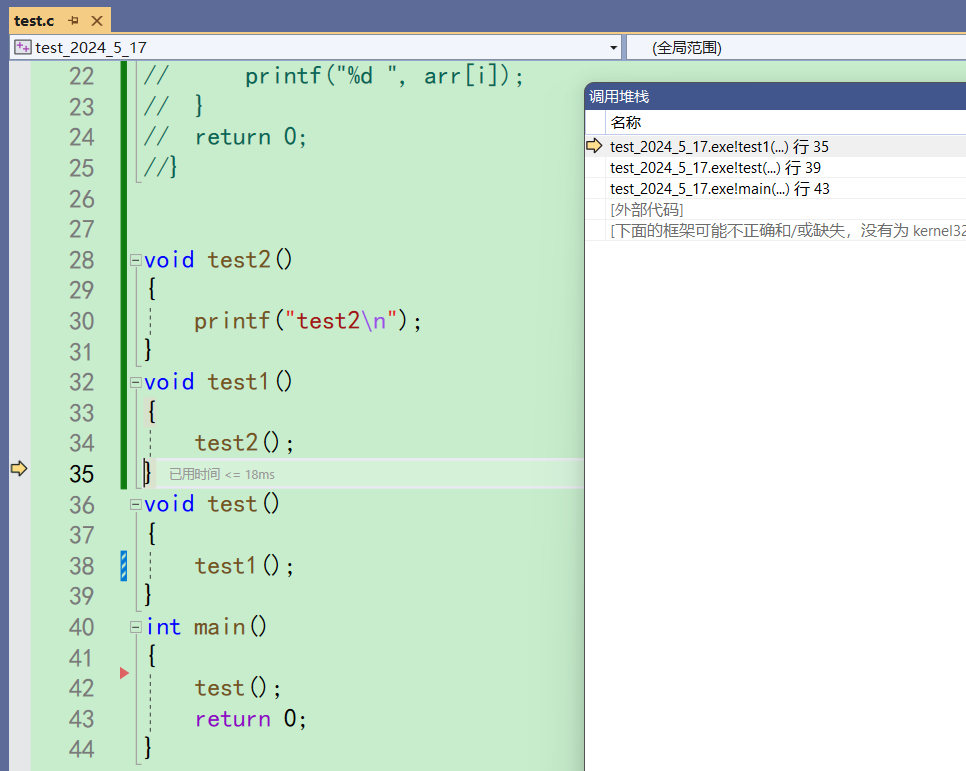
之后test1函数结束,test1的调用堆栈消失。test结束,test的调用堆栈消失。回到main函数
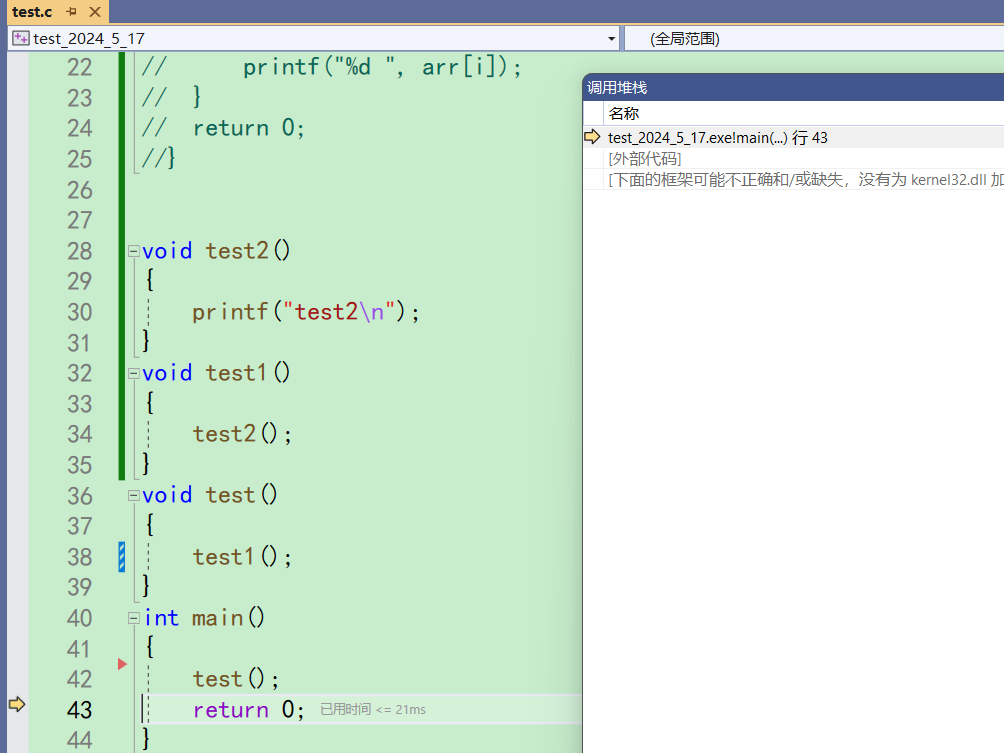
当main函数结束后,main函数的调用堆栈也会消失
这个调用堆栈窗口,就反映了程序在执行过程中函数调用的逻辑 -
什么是调用堆栈
先来看数据结构,数据结构就是数据在内存存储的结构,有栈、队列列表和顺序表等。主要讲的是栈和队列,只讲概念,不讲细节
队列就好比在食堂买饭吃,要排队

只能从队尾进,队头出。这种维护数据的方式就叫做队列
数据结构还有一种叫栈
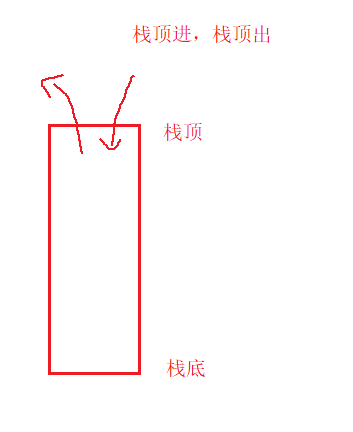
比如你要存个1,再存个2,再存3,再存4。就先从栈顶放进去1,再放2,再放3,再放4。就像是往空弹夹里填充子弹
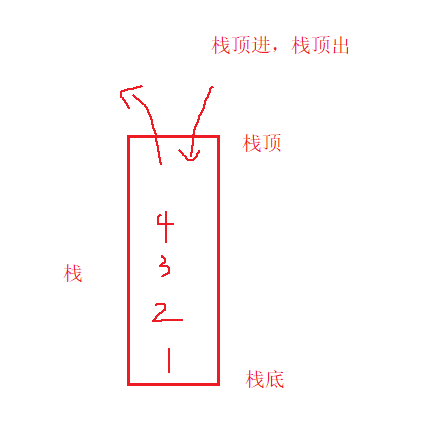
删的时候,也不能先把1删了,只能先删4,再删3,2,1。就像满弹夹,总是打最上面的子弹。这种数据结果叫做栈 -
函数的调用逻辑也是采用了栈的结构,函数从栈顶放进去,栈顶出。所以这个东西叫做调用堆栈
-
之前在函数栈帧的创建和销毁那节课,也说过main函数也是被别的函数调用的。可以在调用堆栈右击,勾选显示外部代码
这些东西都是隐藏起来了,我们关注到的只有main函数。(不同的编译器调用逻辑可能不一样)
3.3.4查看汇编信息
任何一段C语言代码调试起来后,都可以观察汇编代码
就可以看到C语言所对应的汇编代码
也可以在调试窗口打开汇编代码
3.3.5查看寄存器信息
CPU上还集成有寄存器,如果想去观察这些寄存器,就可以再调试模式下,打开寄存器窗口
点击去之后,就能看到一堆的寄存器
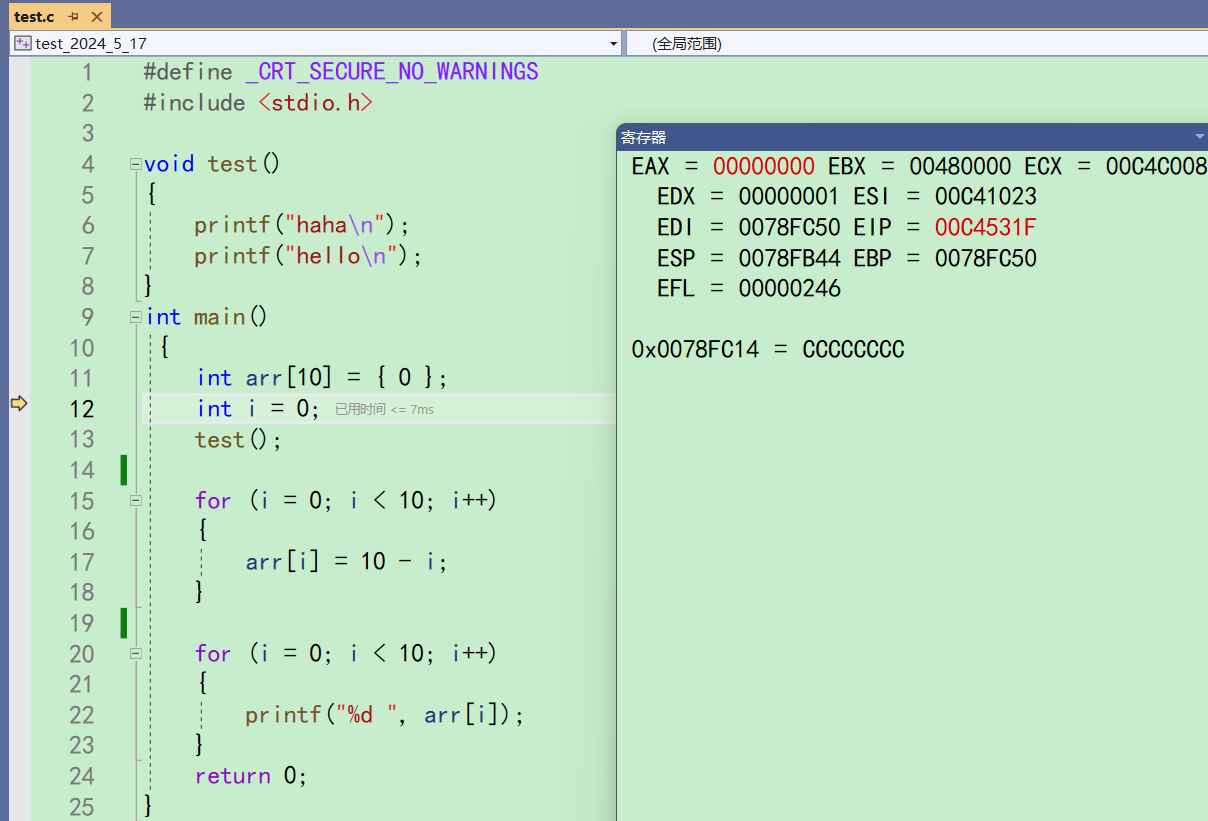
红色是说明这些寄存器的值在变化。而如果记住寄存器的名字,在监视窗口,也可以通过输入寄存器的名字来观察寄存器的变化
4.多多动手,尝试调试,才能有进步。
当我们学了这些快捷键和他们的使用方法之后,我们一定要多动手去调试,你会调试的过程中不断进步,并且加深自己对代码的理解。
我们初学者当前大部分的时间都是在写代码,很少调试。但越到后期,各种语法问题对我们来说会越简单,只需要很少的时间就能写完代码了,而大部分的时间都是在调试。
因此我们要熟悉快捷键,提升效率
5.一些调试的示例
5.1实例1
实现代码:求 1!+2!+3! …+ n! ;不考虑溢出
int main()
{
int i = 0;
int sum = 0;//保存最终结果
int n = 0;
int ret = 1;//保存n的阶乘
scanf("%d", &n);
for(i=1; i<=n; i++)
{
int j = 0;
for(j=1; j<=i; j++)
{
ret *= j;
}
sum += ret;
}
printf("%d\n", sum);
return 0;
}
这个时候我们输入3,预期输出的结果是9,但实际输出确实15

这就发现代码有问题了,就叫做发现问题的存在。接下来就要找问题
我们先要有一个清楚的思路,对代码心中有数。

我们现在是这样想,去调试的时候,看代码是不是这样走。如果不是就能找打问题。
-
f10调试,直接来到scanf输入
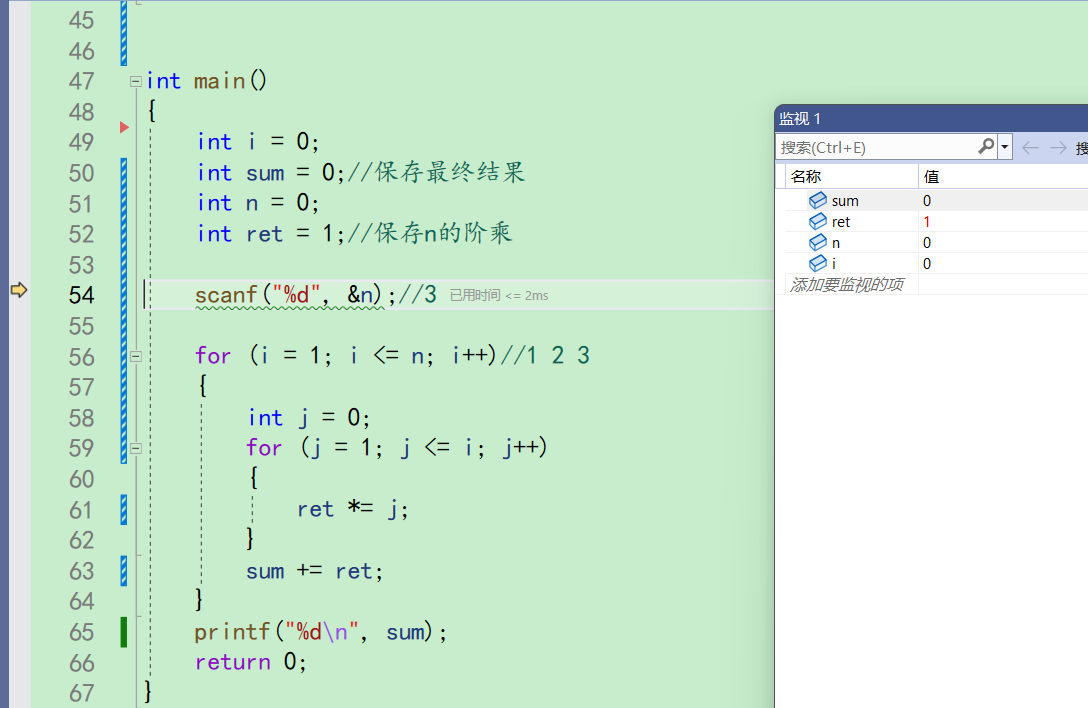
输入3。因为输入3,结果已经错了。再用太大的数据去调试,不好观察
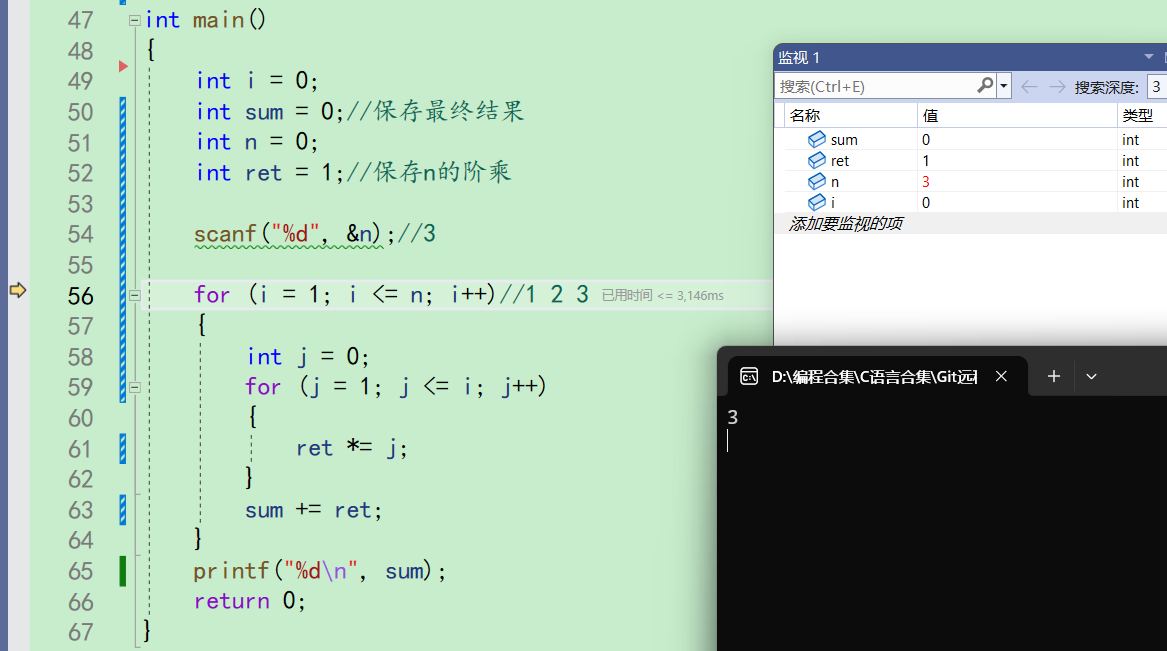
发现n果然是3,和我们预想的一样。说明前面的代码都没有什么问题。 -
f10进入循环,循环最开始i为1,再监视窗口看到i确实为1,没有问题
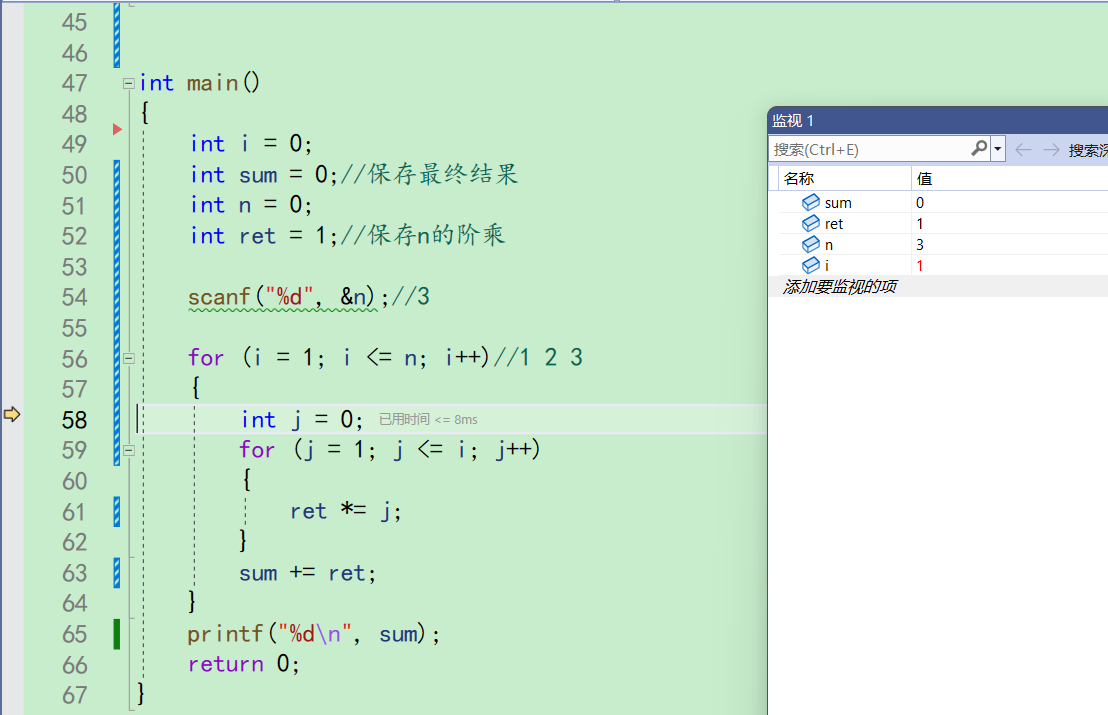
j初始化为0,来到第二层for循环

在59行这里,j又被赋值为1。此时的i为1。所以j<=i成立,进入循环。

进入之后ret\*\=j;,ret最开始为1,所以是1*1,ret得到的是1。监视一看ret果然是1

之后来到59行,循环的调整和判断部分。j++,j变成了2。j<=i不成立,为假,不再进入循环。之后sum+\=ret;,sum最开始是0,ret为1。所以加上去之后sum为1
-
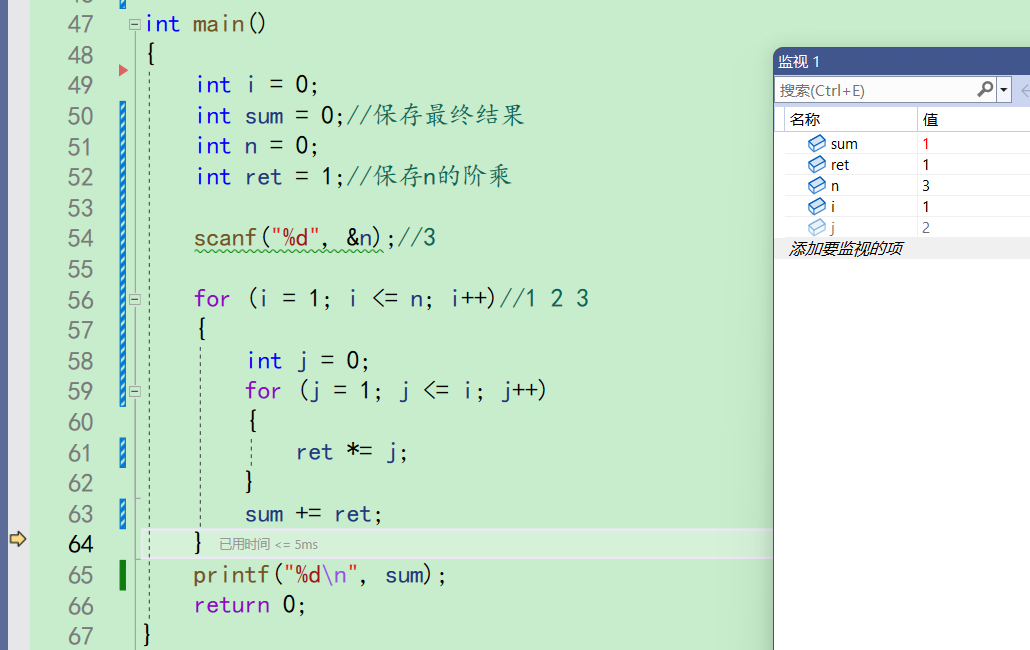
此时第一层的for结束了,来到56行,i++,i变成2
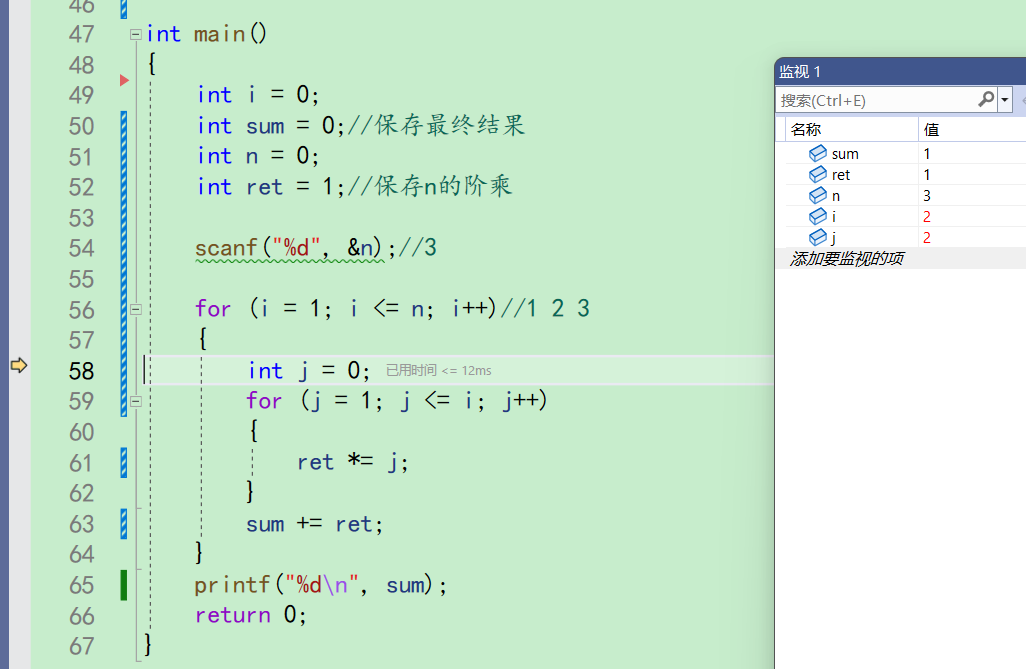
走下去,j又创建为0。来到59行,j被赋值为1,i此时是2,j<=i成立。进入循环。ret *= j;,ret最开始得是1才是计算阶乘啊,一看监视,ret果然是1
之后1*1,ret还是等于1。这时第二层for循环的第一次循环结束,来到59行,循环的调整和判断部分。
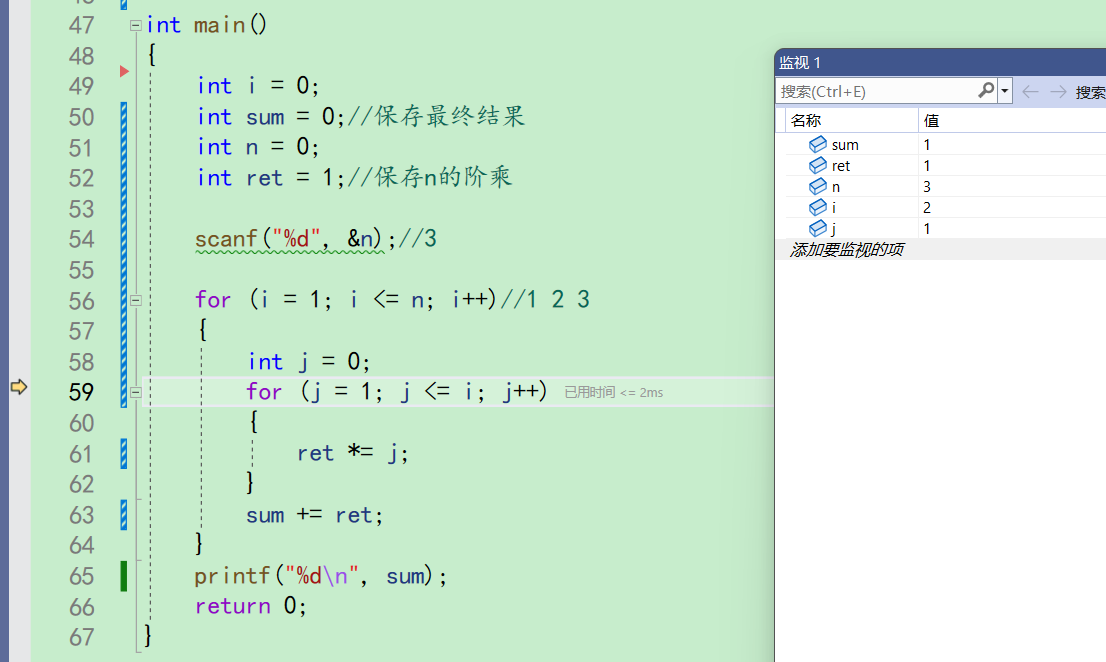
j++,j变成2。此时i还是2,所以j<=i成立。进入循环

此时ret为1,j为2,所以走完61行,ret为2
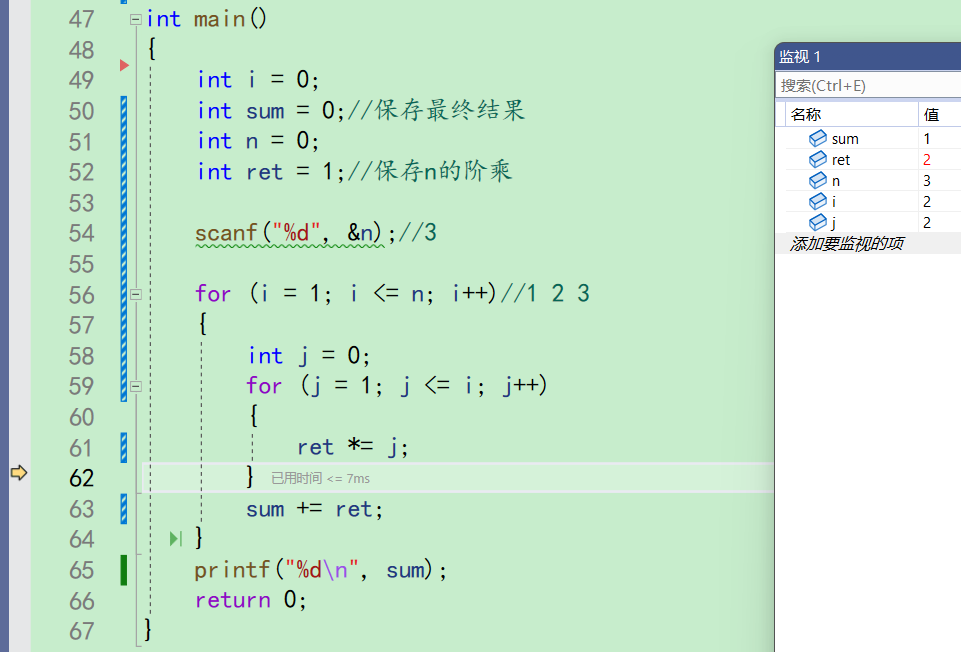
之后来到59行
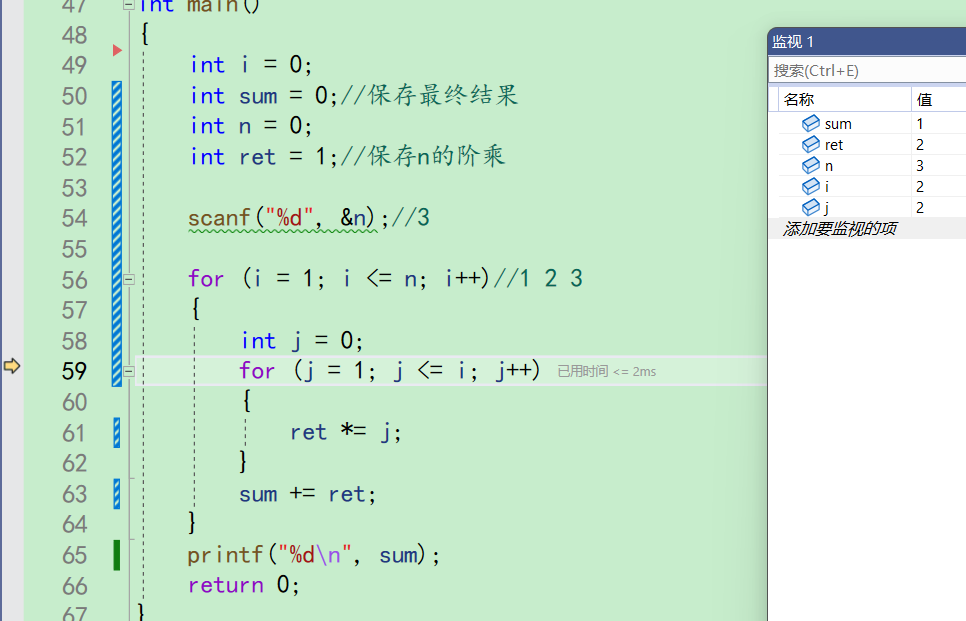
j++,j变成了3,i此时为2。所以j<=i不成立,为假,不再进入循环。来到63行
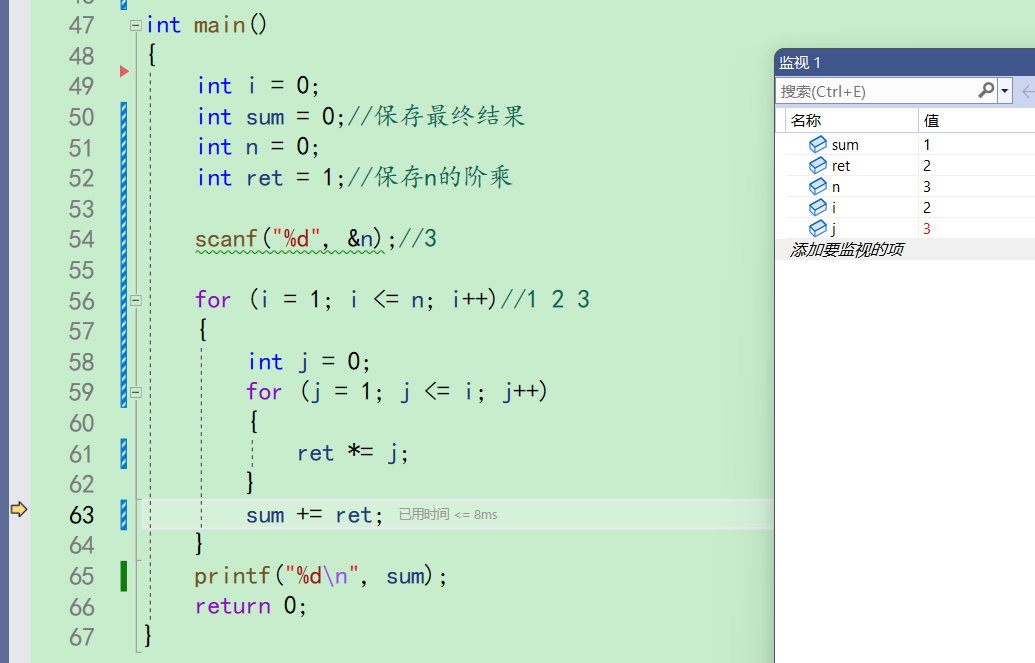
sum为1,ret为2,所以sum+ret之后为3。并且来到56行

发现sum果然还是3,也没有问题。 -
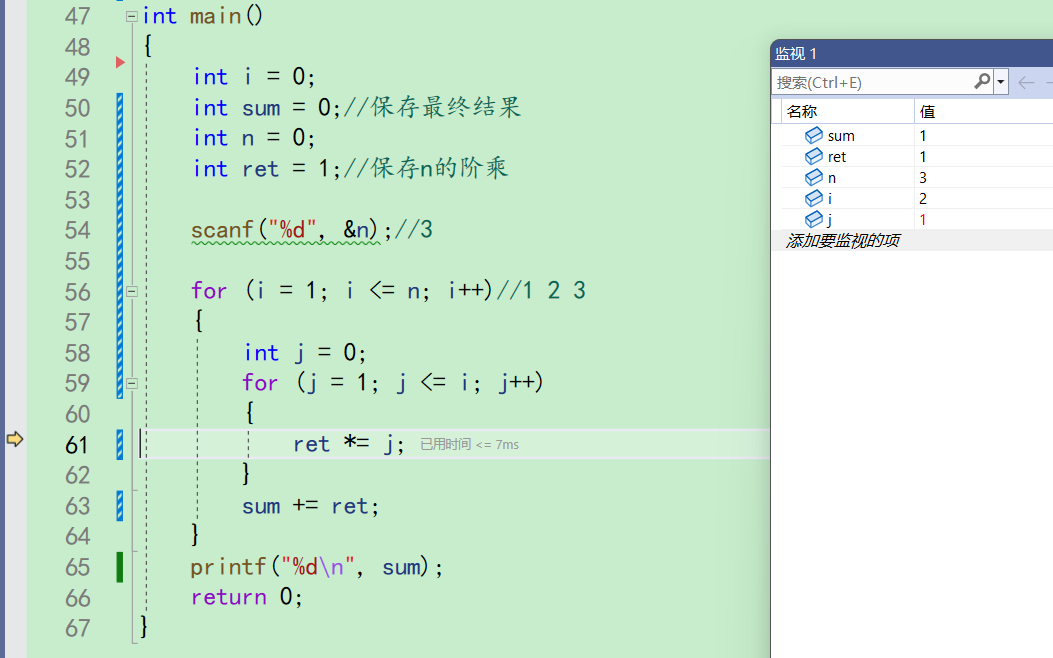
i++,i变成3。j又初始化为0。
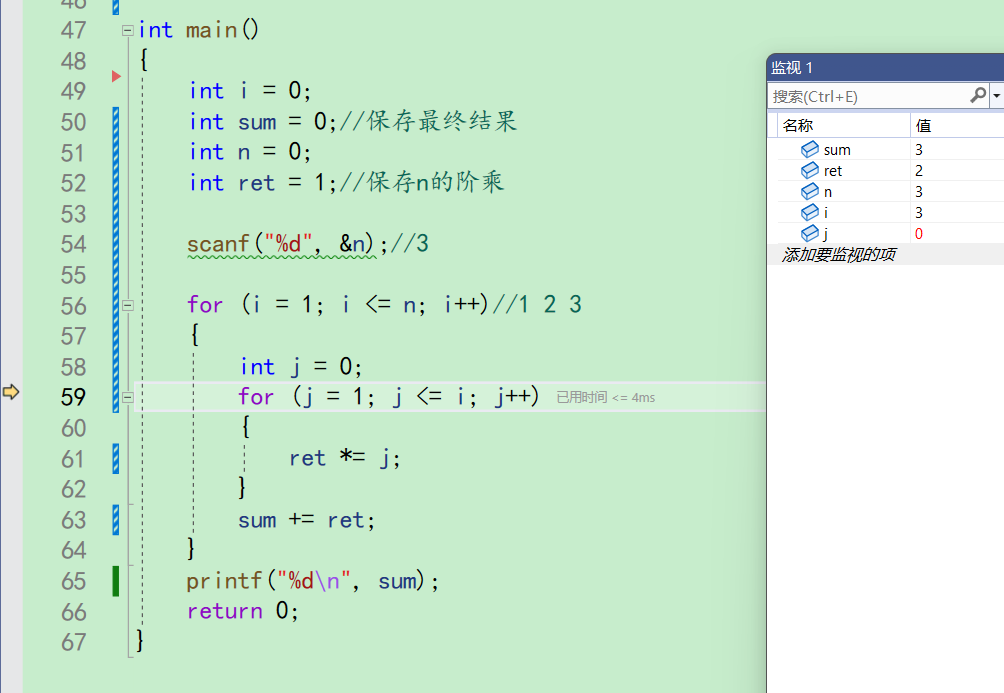
来到59行,j被赋值为1,j<=i成立。
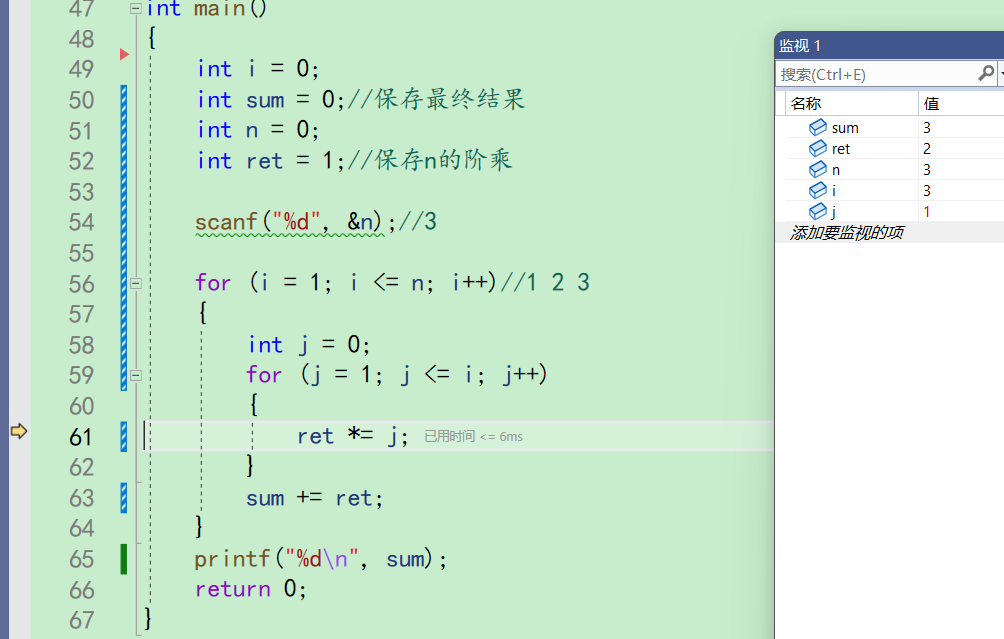
ret此时此刻应该是1,第二层for计算的结果才是i的阶乘。但是此时去瞄了一眼ret,居然是2啊。和我们预想的不一样,所以问题出现在ret身上。这就是对错误进行定位
我们接着调试下去,ret为2,j为1。ret\*\=j;ret为2
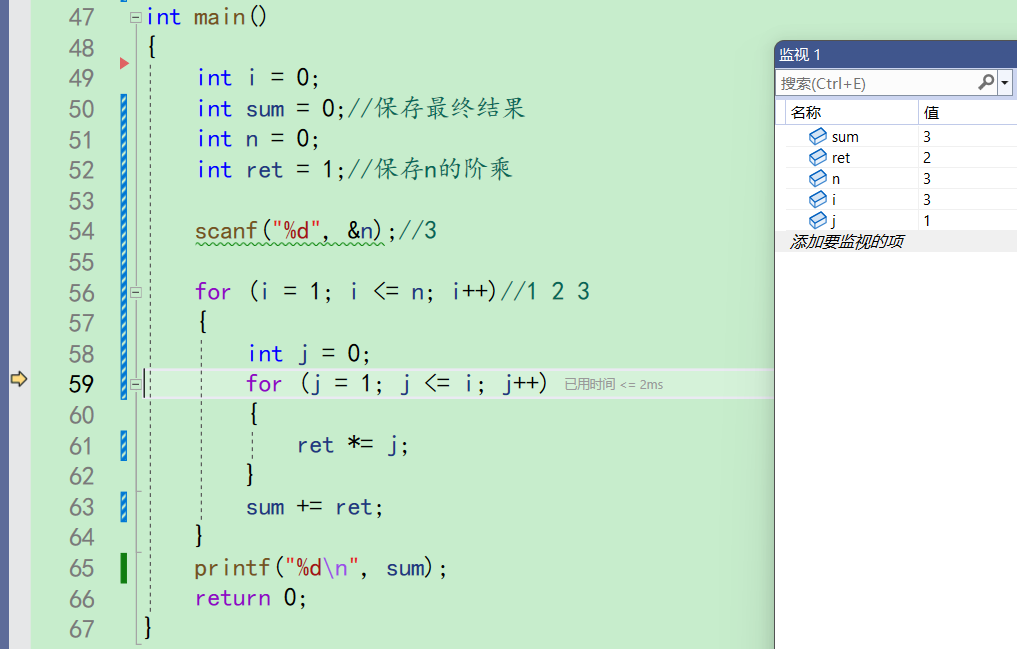
再来到59行,j++,j变成2。此时i为3,j<=i成立,进入。
进入之后ret为2,j为2,所以走完61行,ret为4
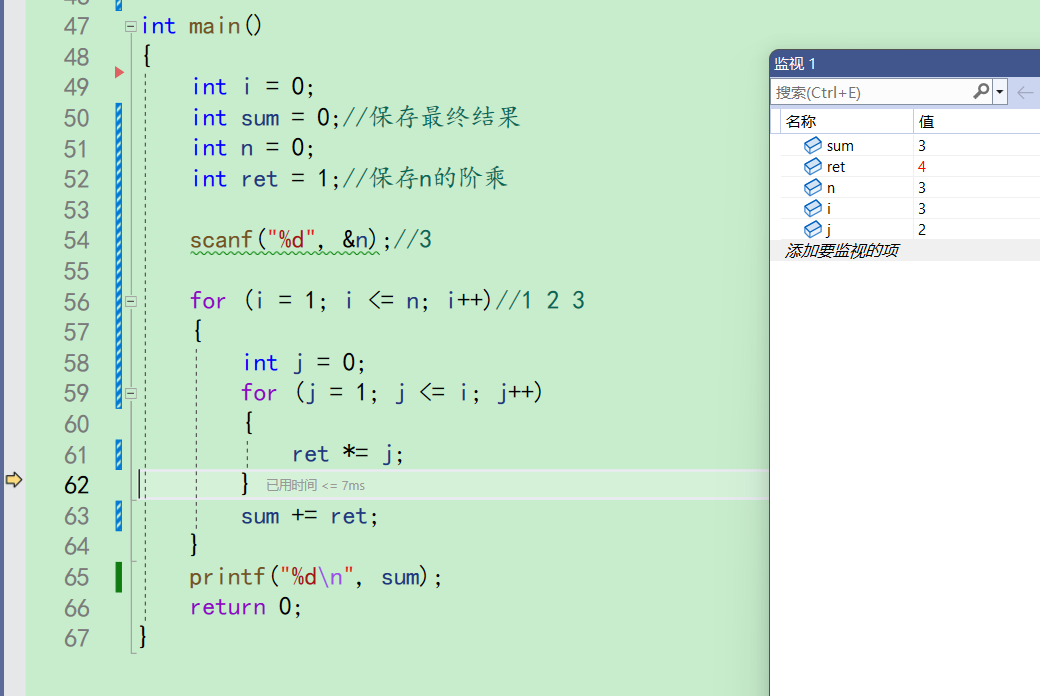
再次来到59行,j++,j变成3,i此时还是3。j<=i成立,进入

ret为4,j为3,所以61行之后,ret为12
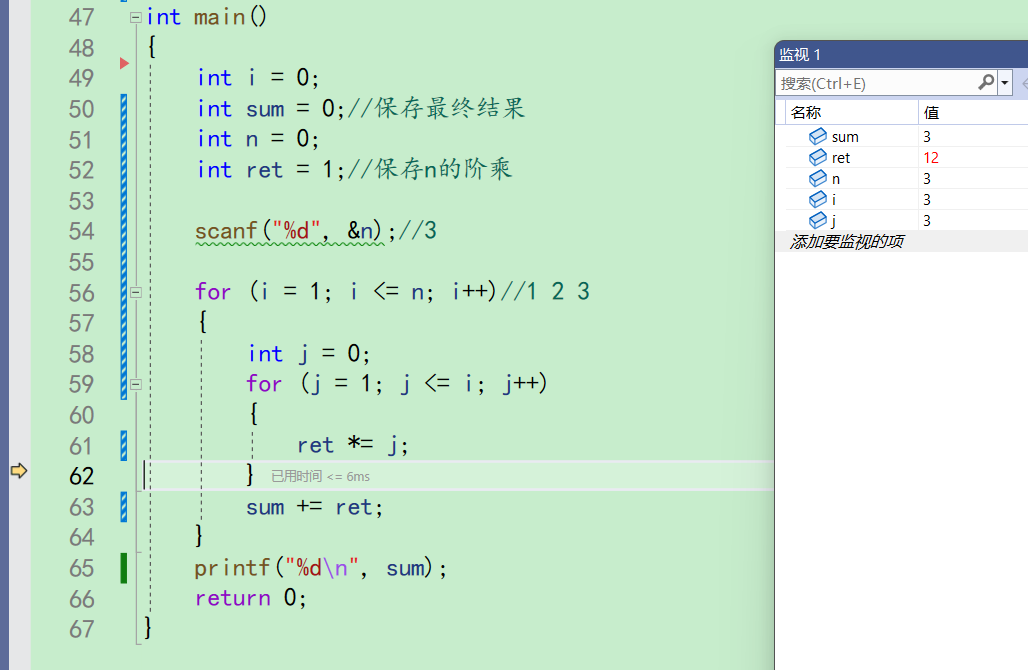
再来到59行,j++,j变成4,j<=i不成立,不进入循环。第二层for结束,来到63行。
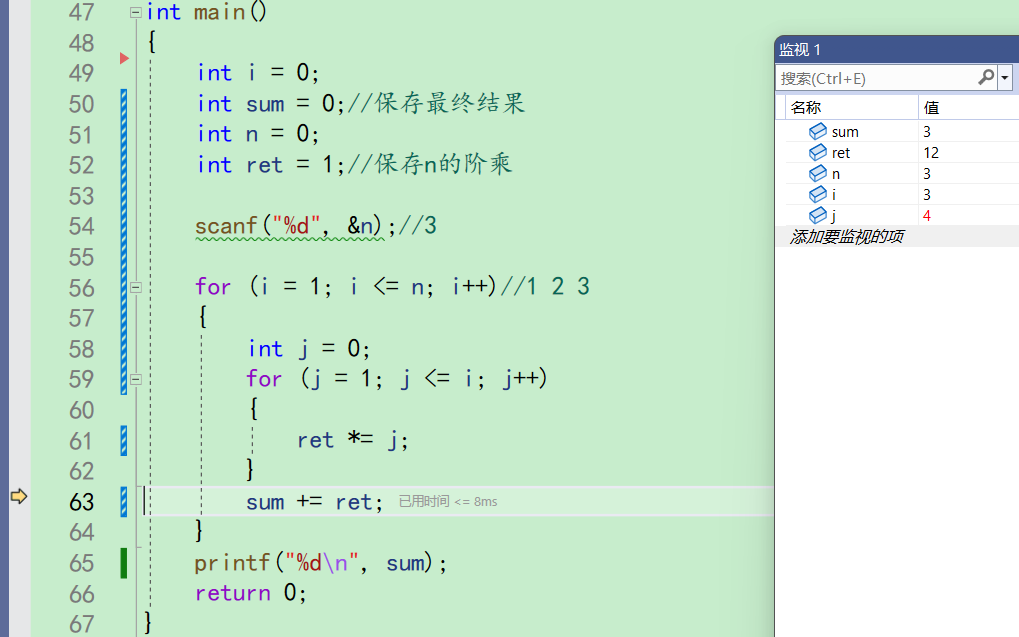
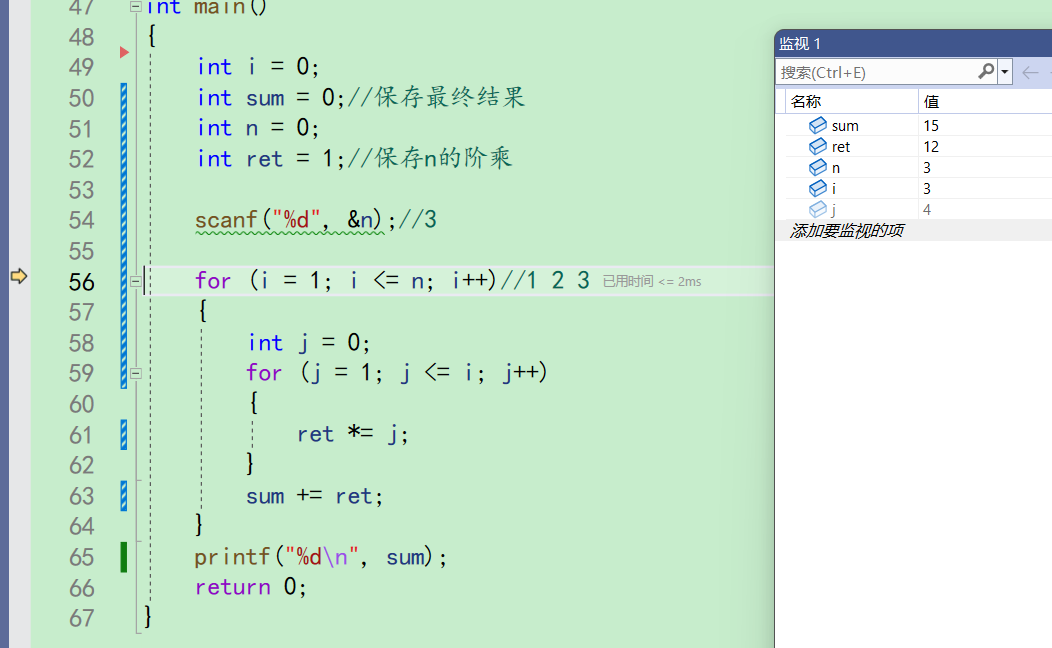
sum此时为3,ret为12,sum+ret后变成15。并且来到56行
-
i++,i变成4,n是3。i<=n不成立,不再执行循环,至此两层for执行完毕,结束,最后输入sum的值15
-
最后我们发现,程序出错的原因是因为ret在第二层for计算阶乘开始的值,不是我们预想的1,导致后面3!的阶乘被错位计算成了12,使得我们看到的sum是15。因此可以发现到问题是ret的值在计算完2!阶乘后,ret的值是2!,也就是2,被保留了下来。等到计算3!的时候,因为ret的初始值不是1,这就确定了错误产生的原因
-
因此通过上面的分析,我们可以在进入第一层for循环之后,把ret的值设置成1,使得上一次计算出的阶乘的值不会影响,下一次的阶乘。这就是纠正错误的解决办法
-
此时此刻再次去运行我们的代码,发现程序正常输出了
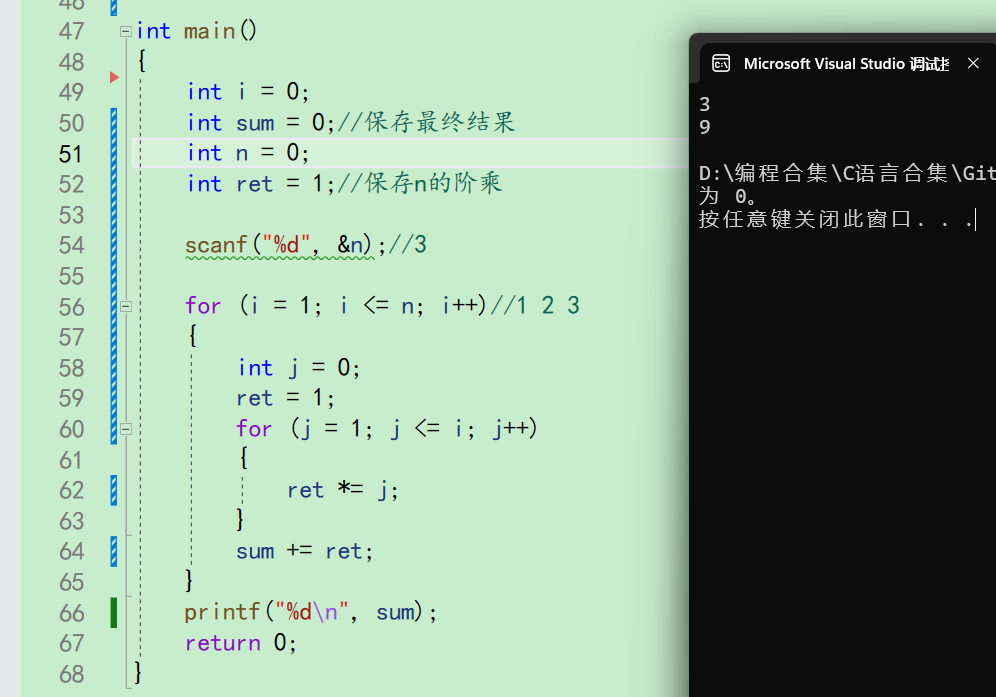
这就是对程序错误予以改成,重新测试。测试结果通过,说明我们就对不过完成了了一次调试
5.2实例二(【nice公司的笔试题)
注意此代码是在VS2022的Debug版本下的x86环境调试的,不同编译环境下发生的结果可能不同
int main()
{
int i = 0;
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
for (i = 0; i <= 12; i++)
{
arr[i] = 0;
printf("hehe\n");
}
return 0;
}

研究程序死循环的原因
-
先来简单分析一下这个代码
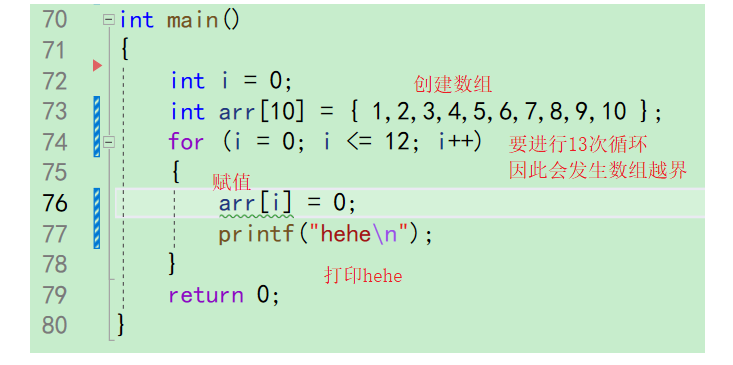
所以这个代码就是从首元素开始,循环将数组元素赋值成0,并且每次循环打印一次hehe。但是数组arr的下标最大时9,而循环的条件是i<=12。因此循环里面的arr[i]=0;肯定会发生数组越界 -
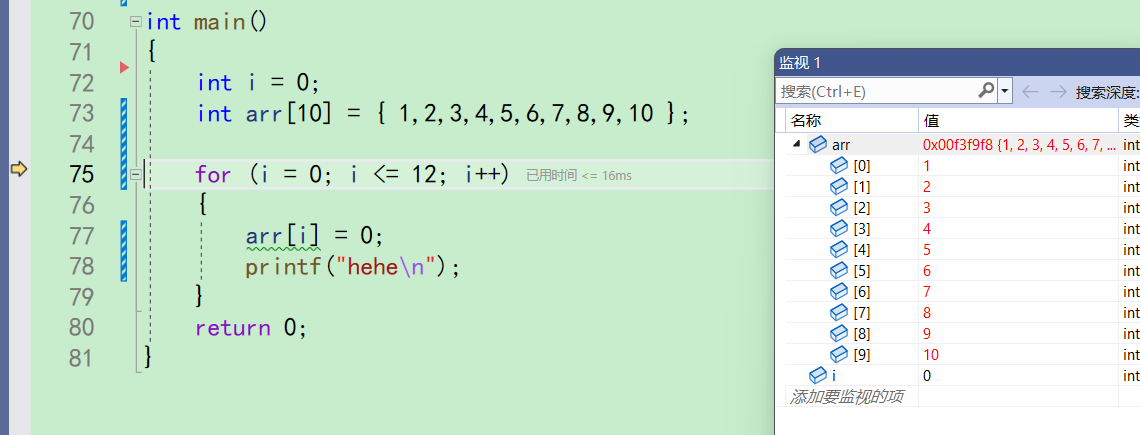
f10调试代码,直接来到75行
-
在第一次来到75行的时候,i被赋值为0,i<=12成立,进入循环
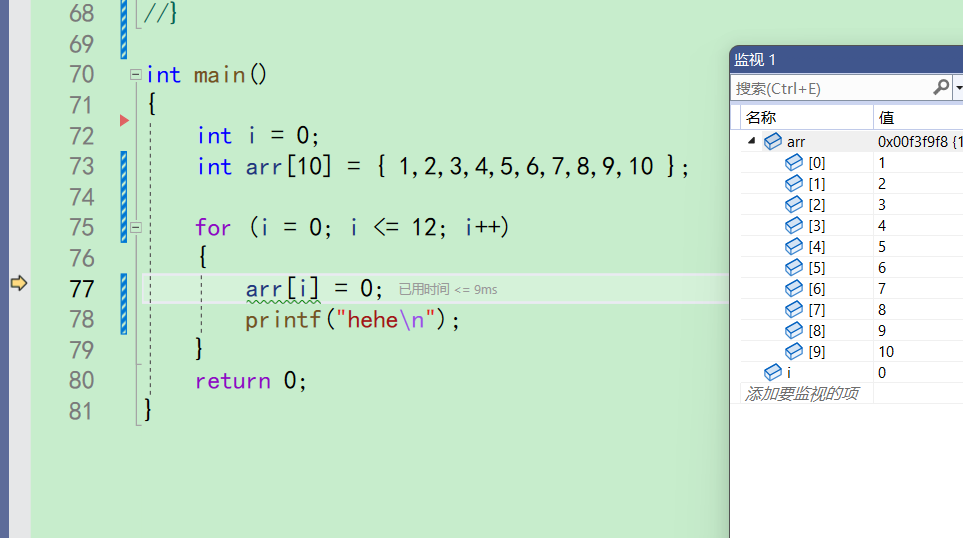
-
执行
arr[0]=0;,arr首元素被改0。并且这个时候的屏幕上没有打印
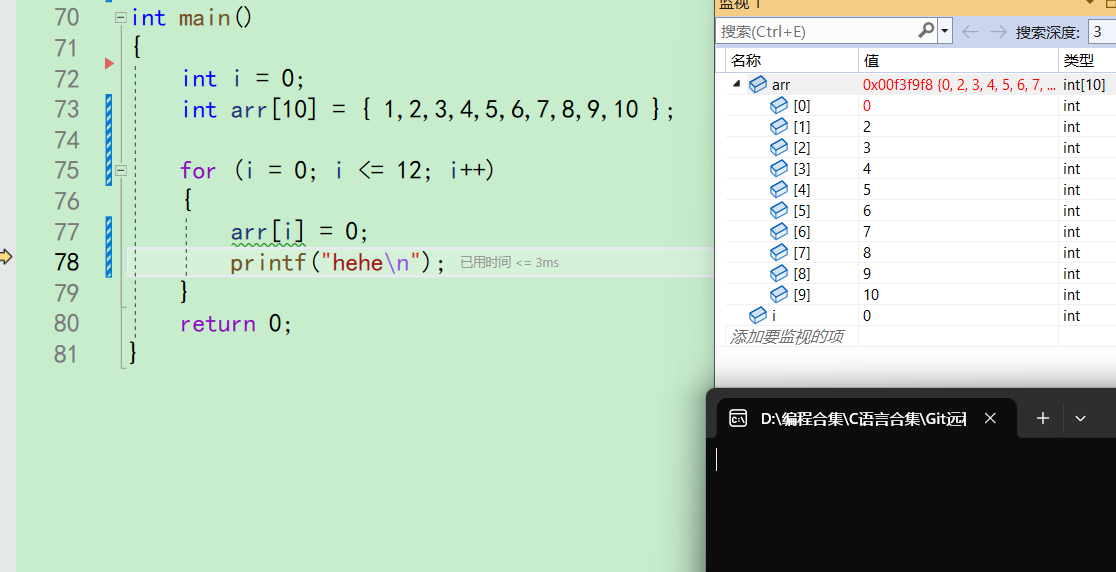
-
执行78行的打印之后,屏幕输出了hehe。

-
来到75行,i++,i变成1。i<=12成立,再次进入循环
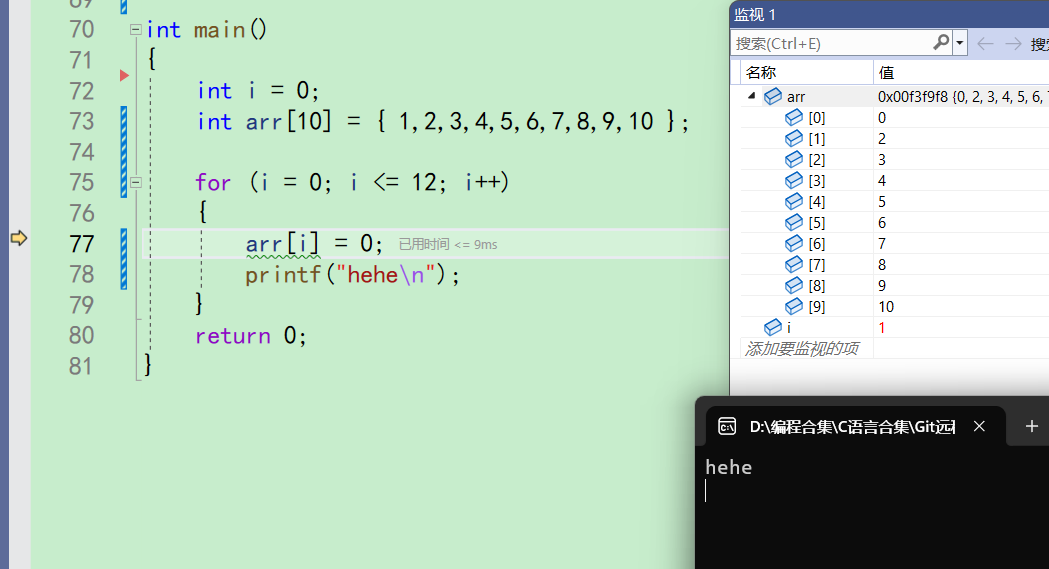
-
之后arr[1]被改成0,打印hehe
-
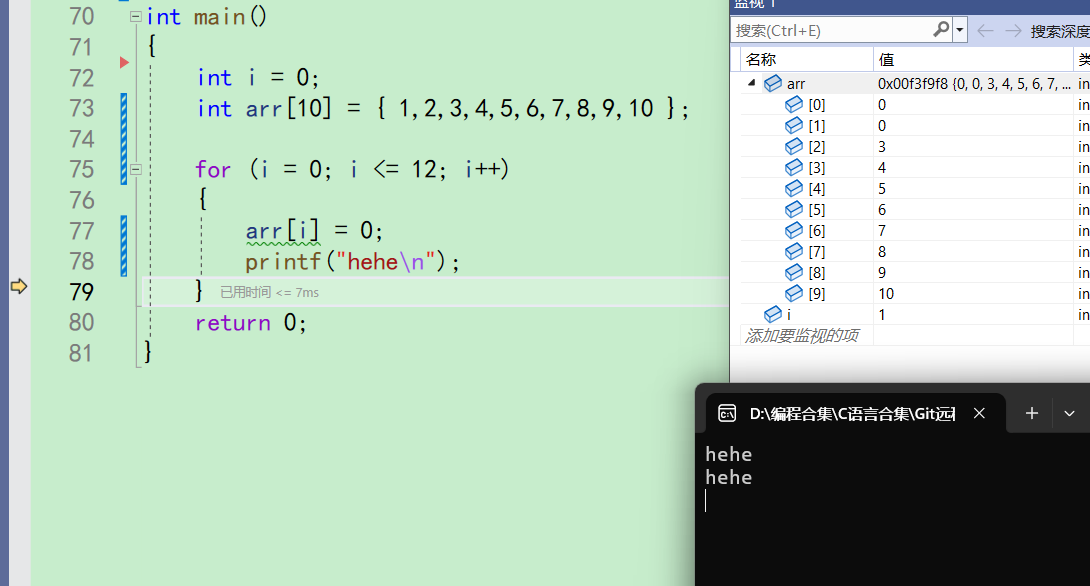
就这样一直修改arr的值,再打印。直到i为9,数组内所有元素都被改成了0,打印10次hehe

-
来到75行,i++,i变成10。i<=12成立,还要进入循环
-
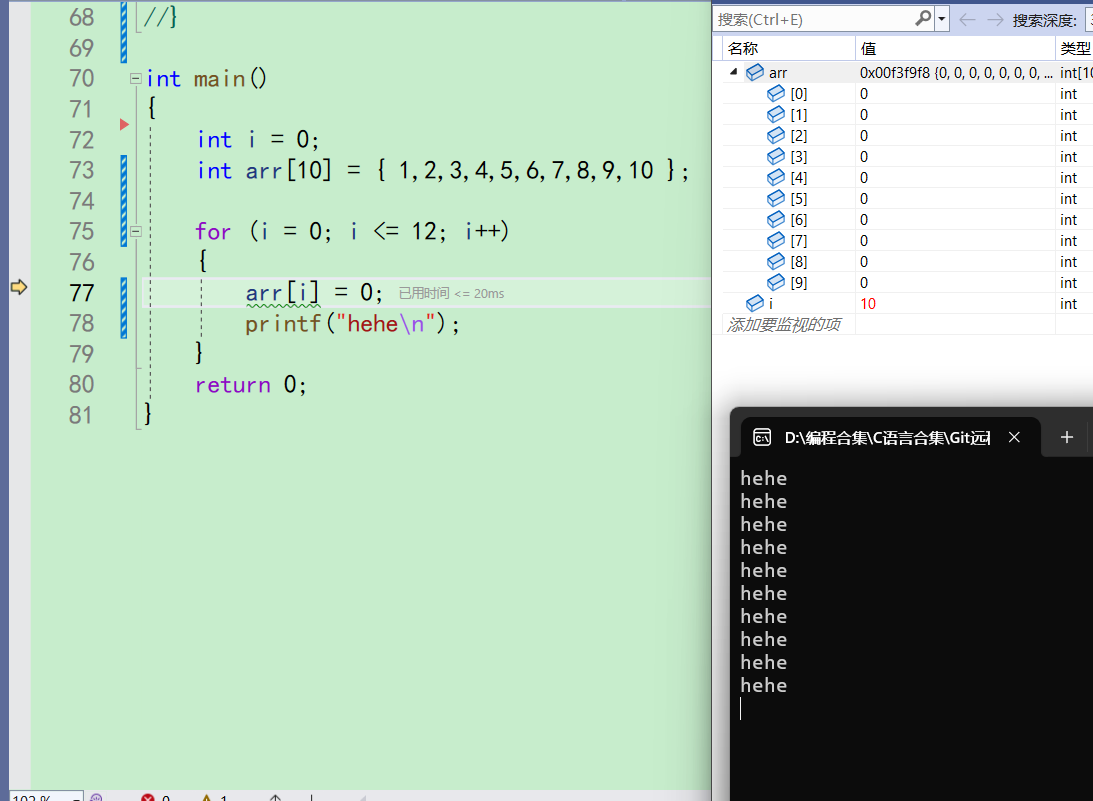
当i等于10的时候,已经不再arr的下标范围内了。此时
arr[i]=0;必然越界访问,我们可以在监视加上arr[10],是个CCCCCCCC的随机值
-
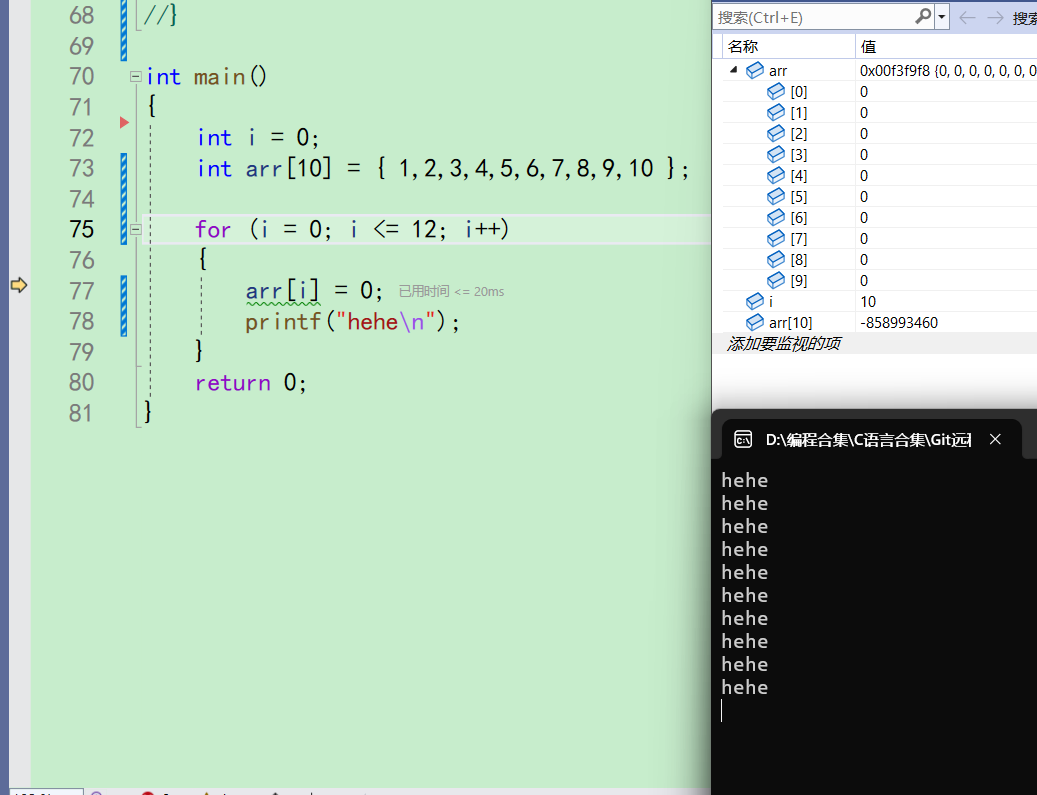
执行75后,发现arr[10]的值被修改成了0了
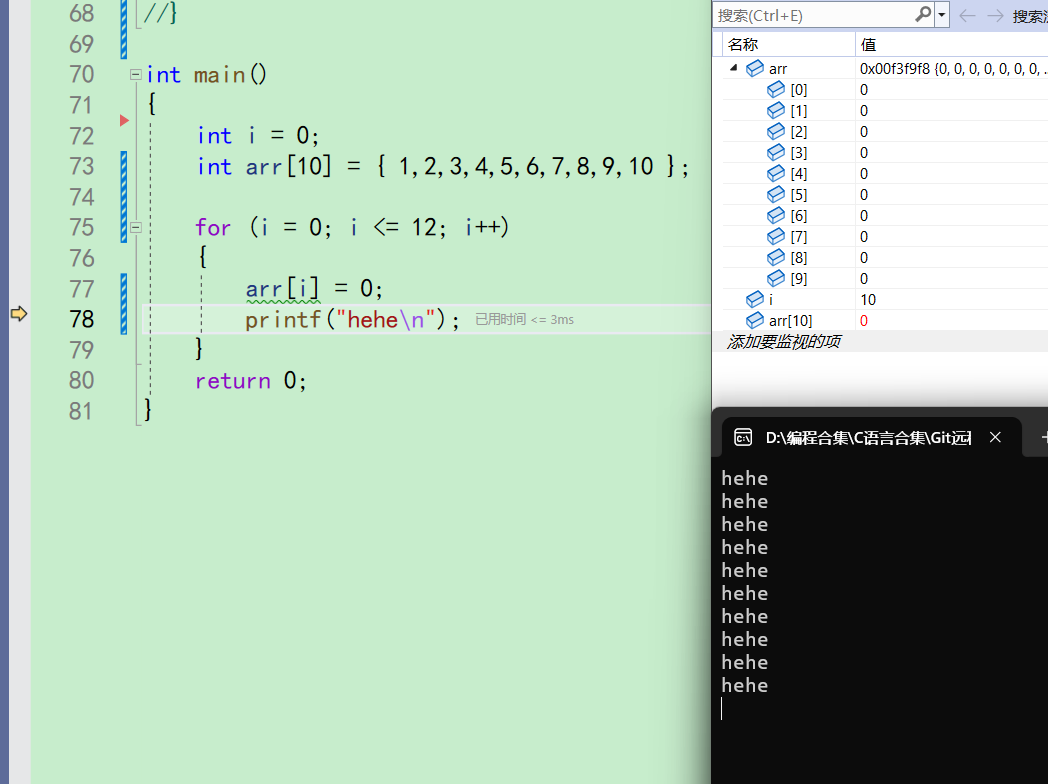
此时的arr[10]这块空间,不是我们申请的变量创建的空间,越界访问了。这是非法的 -
再走78行,发现也会打印hehe
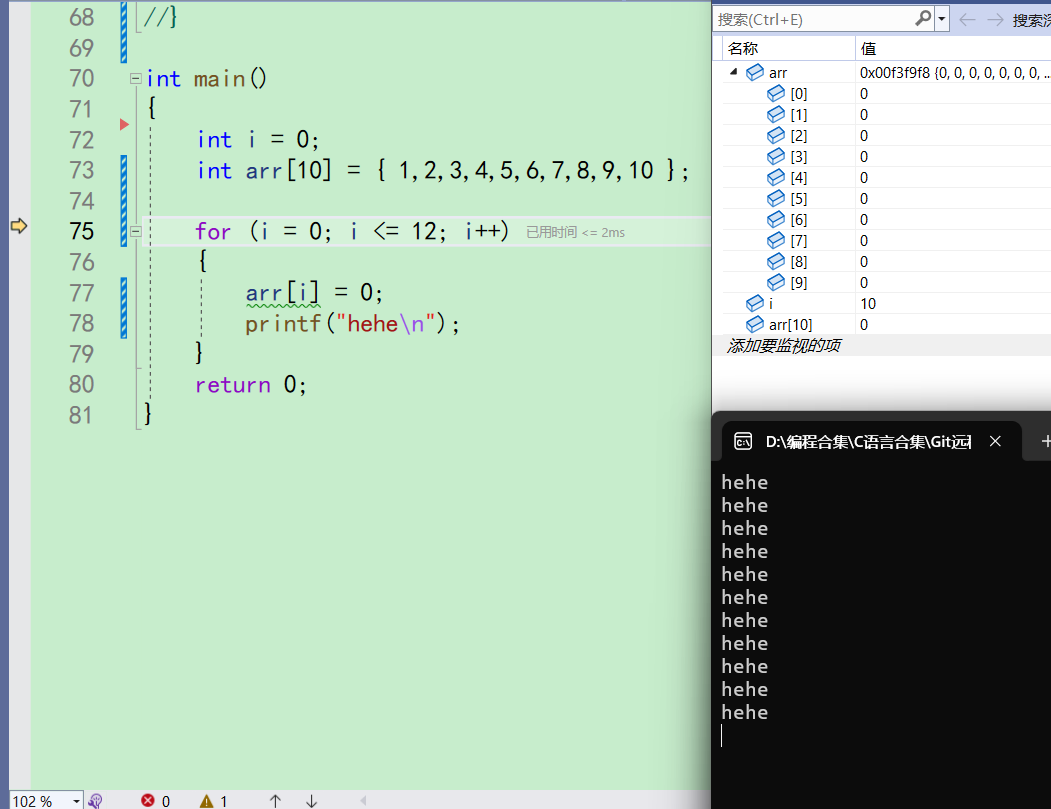
-
再次来到75行,i++,i变成11。进入循环,看看是否会访问下标11的元素。同时在监视里加上arr[11],发现还是个随机值

-
走完77行和78行,arr[11]的值确实被修改成了0,也打印了一个hehe
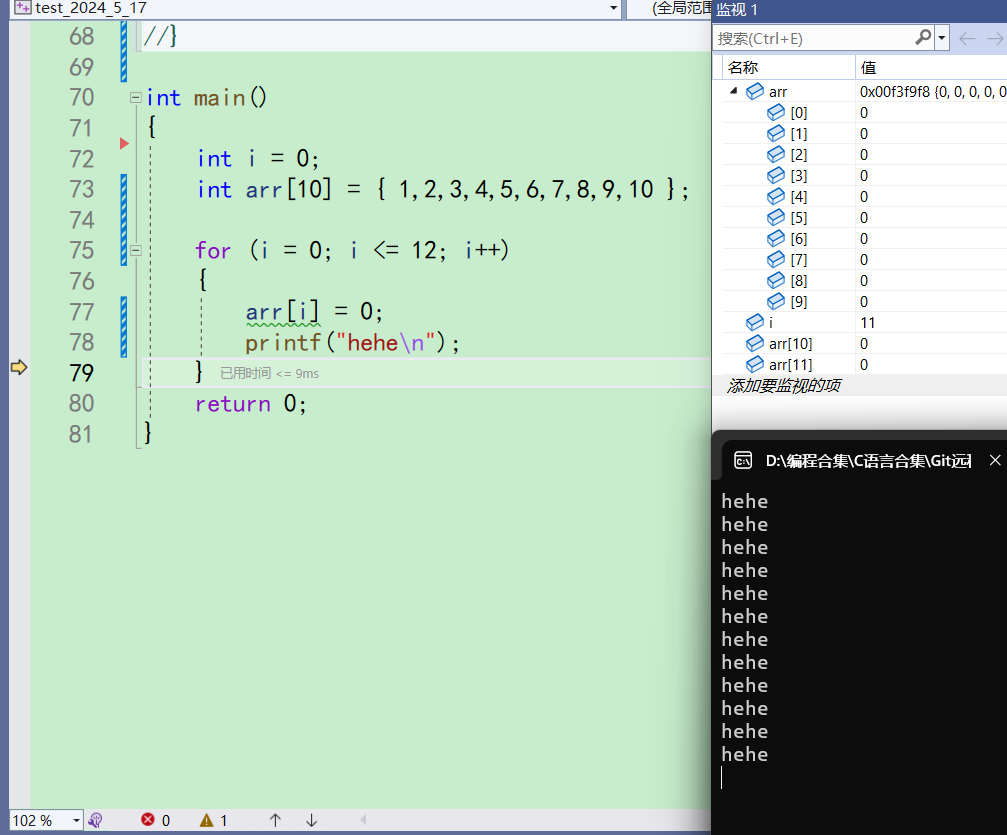
-
来到75行,监视再加上一个arr[12]
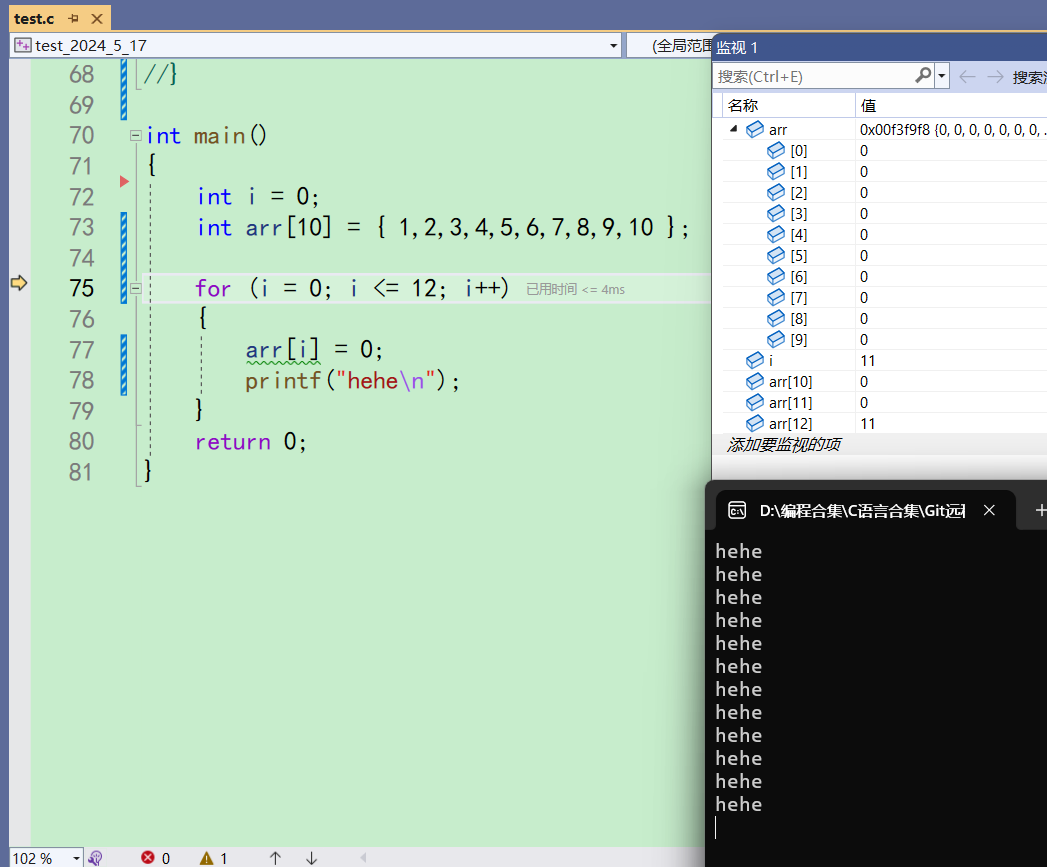
这个时候往右边一看,arr[12]的值不是随机值了,而是11。i此时还没有i++,因此i还是11。为什么这两个的值一样?难道是同一块空间吗?接下来再看看 -
i++,i变成12,i<=12成立,进入循环。而arr[12]的值也跟着变成了12
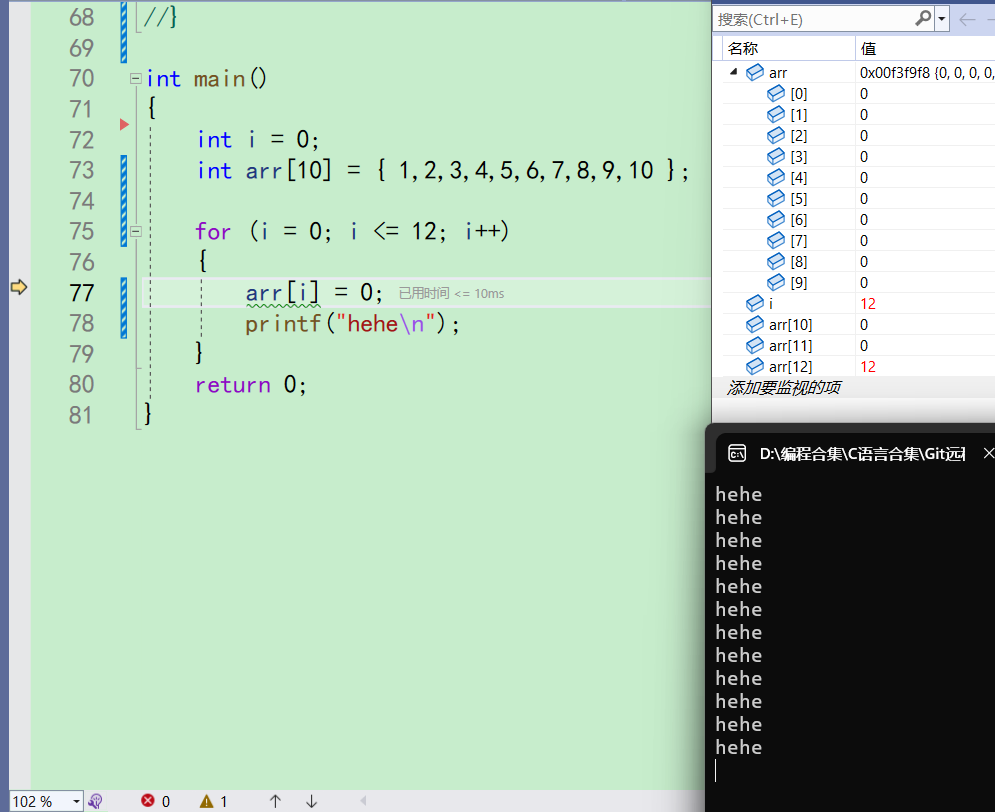
-
i此时为12,
arr[i]=0;也就是arr[12]会被改成0。执行完之后一看果然改成了0,但是i的值也变成了0
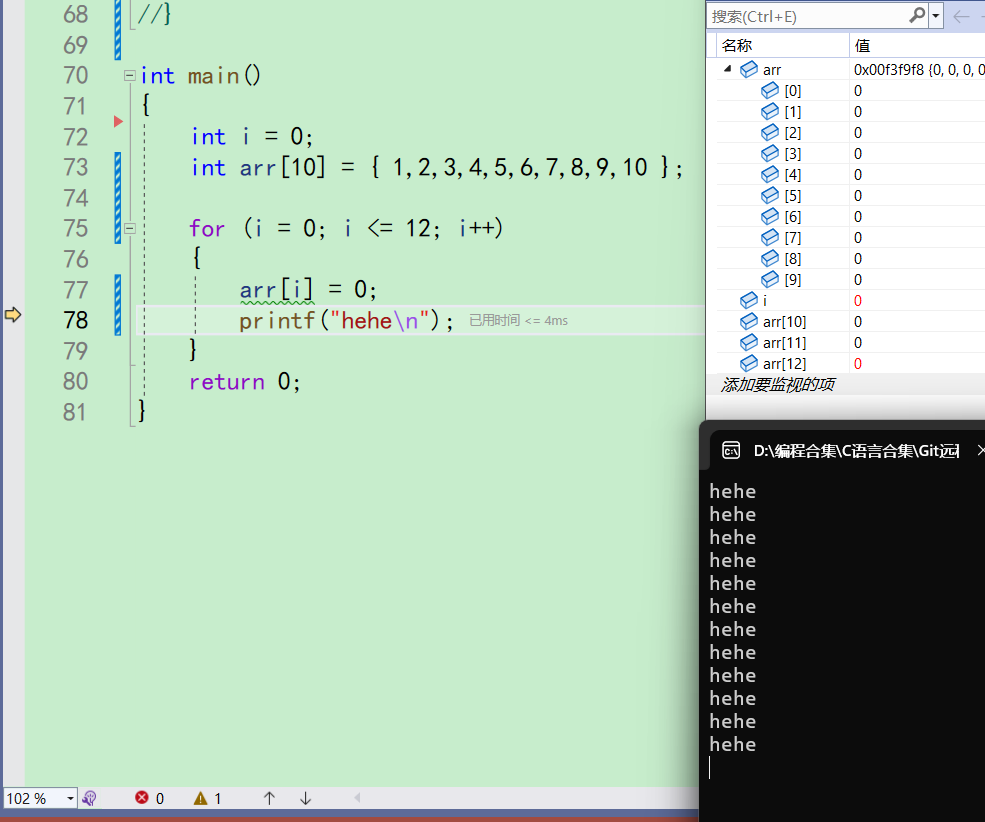
从这里我们就可以推测出,i和arr[12]好像真的是同一块空间。 -
在监视观察i和arr[12]的地址

地址相同说明,它们是同一块空间。所以说当我们越界访问,走着走着就访问到i去了。而我们不小心把i改了,后果非常严重。
i改成0,来到75行i++,i变成1,i<=12成立,又会进入循环,之后i++又走了一遍,打印hehe。在i加到12,进入循环又把i改成了0。再次回到起点,i最大就是12,永远没有机会大于12。循环的判断部分一直成立,这就是死循环打印hehe的原因 -
i和arr[12]为什么地址一样?这是因为内存布局的原因,这些变量在创建的时候就是这样放的

-
我们刚刚创建的这些i、arr都是局部变量,局部变量是在栈区创建的。所以i和arr都放在栈区
栈区内存的使用习惯是先使用高地址的空间,再使用低地址的空间(不一定上面就是高地址,下面就是低地址。反着写也可以,只要保证从高地址到低地址使用就可以了)

-
i是先开辟的,所以i在上面,地址是0x00f3fa28。而arr是后开辟,而栈区的使用习惯,先使用高地址,再使用低地址。所以arr的空间要在i的下面,地址是0x00f3f9f8
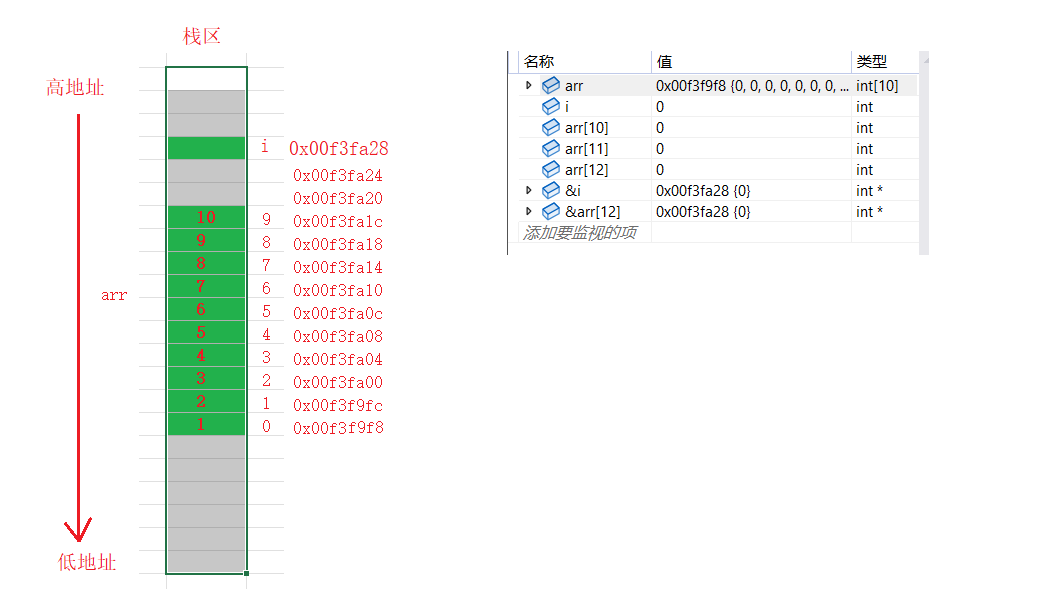
-
当我们把下标为i的元素改成0的时候,从下面开始往上改
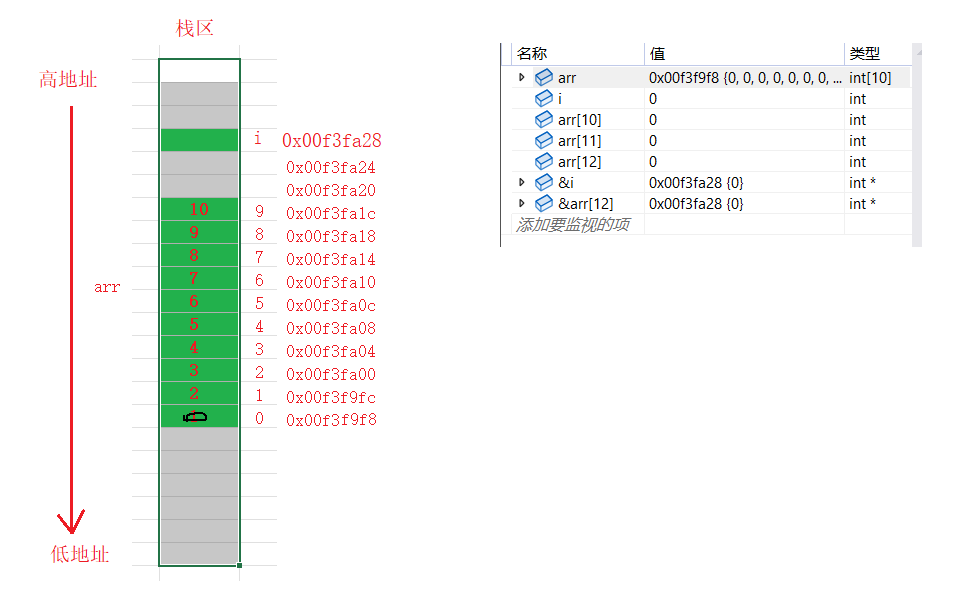

-
假设下标为9后面的空间的下标是10、11、12
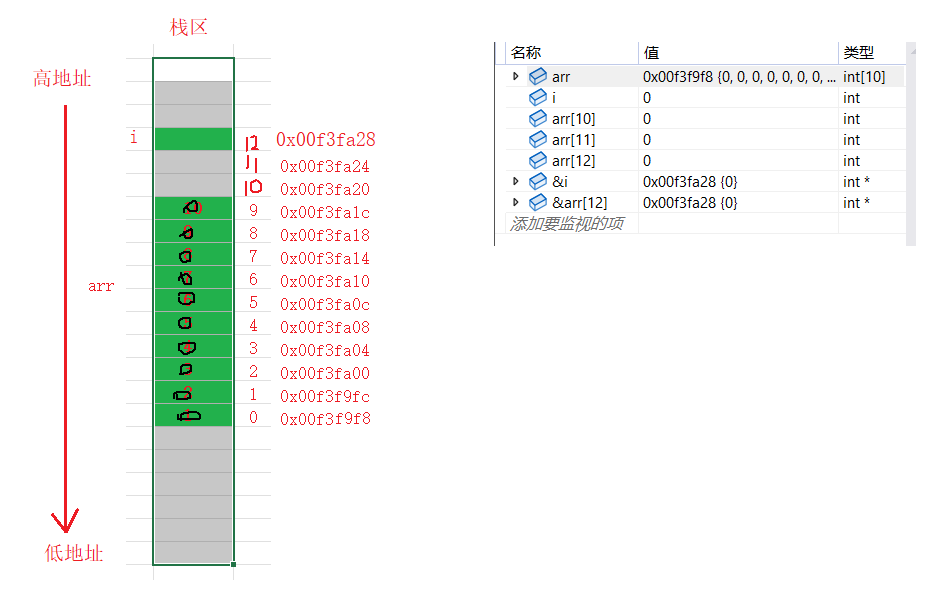
继续把下标为10和11的空间改了
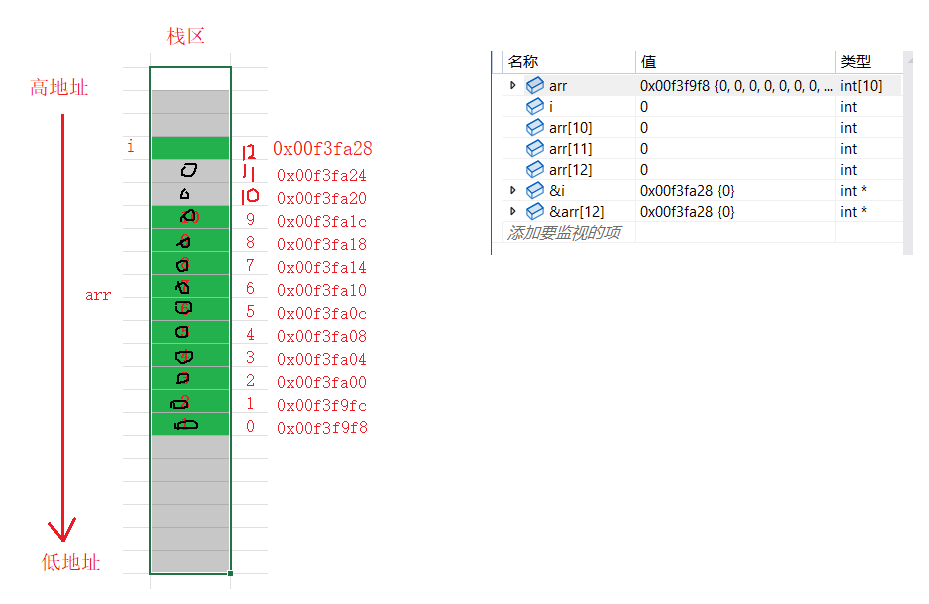
-
当来到下标为12的空间的时候,12和i就恰好遇到了一起。改arr[12]的时候,其实就是在操作0x00f3fa28这块空间,i也是这块空间。因此改arr[12]也就改了i。

-
总结来说就是因为栈区的使用习惯,使得变量i的地址大于arr[9],又因为数组随着下标的增长,地址由低到高。当arr向后越界访问的时候,就有可能遇到i
-
注意这是针对VS2022的Debug版本下的x86环境特地设计出来的,有些编译器可能i和arr[9]之间空一个整型,或者没空。但原理都是一样的。至于为什么空,我也不知道。
5.3Release版本会对代码进行优化
用实例二的代码说明这个问题
-
在Debug版本下的x86下
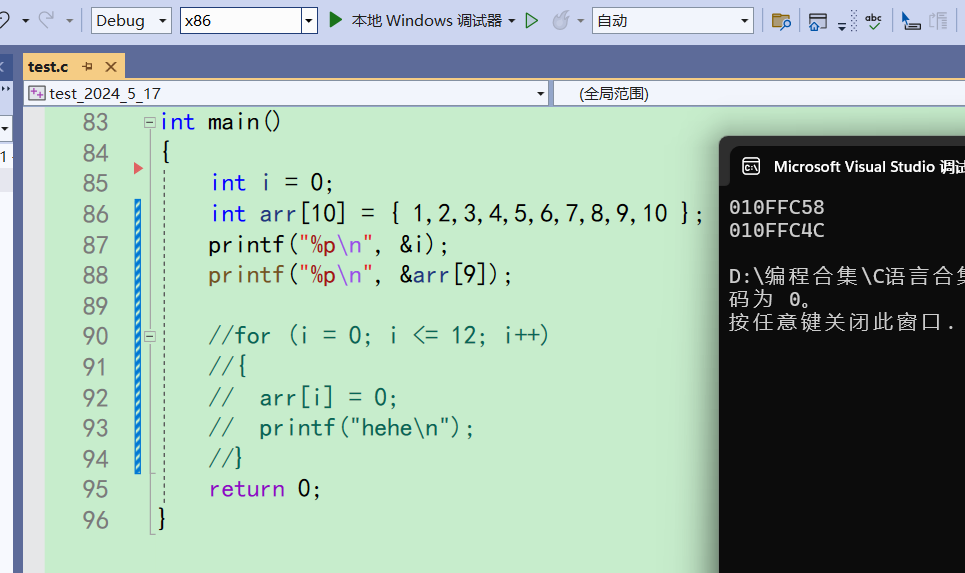
上面就说过了,i的地址要大于数组arr每个元素的地址。而数组随着下标的增长,地址从低到高,所以随着数组向后访问的时候,是有可能访问到i的。 -
我们换成Release版本,把下面的代码放开
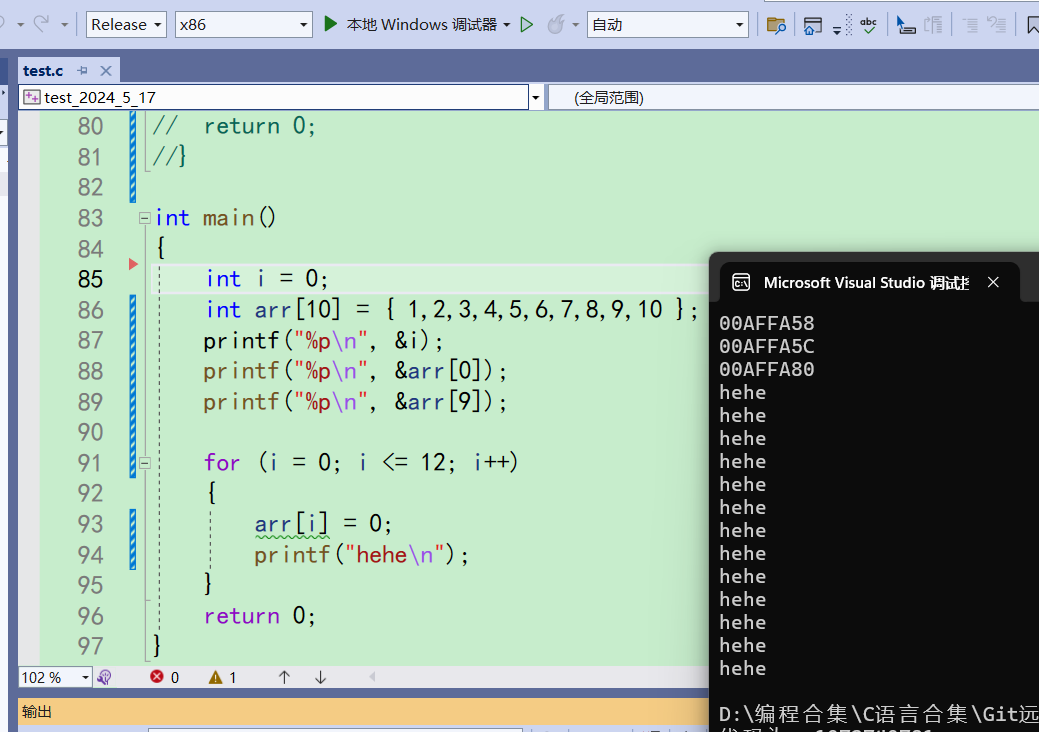
并没有死循环,这是因为编译器帮我们做了优化处理 -
可以通过地址看到i和arr的顺序发生了变化

-
说明Release版本下,编译器对我们的代码做过优化,内存布局都变了。编译器认为应该把i和arr的顺序颠倒过来。具体优化我也不知道,也不需要纠结。
6.如何写出好(易于调试)的代码
我们作为程序员,不能指望说写出一个有bug的代码,然后再去调试改bug。这是不合适的,我们应该写出好的代码,易于调试的代码
6.1优秀的代码
- 代码运行正常
- bug很少
- 效率高
- 可读性高
- 可维护性高
- 注释清晰
- 文档齐全
6.2常见的coding(编码)技巧
- 使用assert
- 尽量使用const
- 养成良好的代码风格
- 添加必要的注释
- 避免编码的陷阱
6.3示范
模拟实现strcpy库函数
6.3.1strcpy函数的用法
- strcpy的介绍
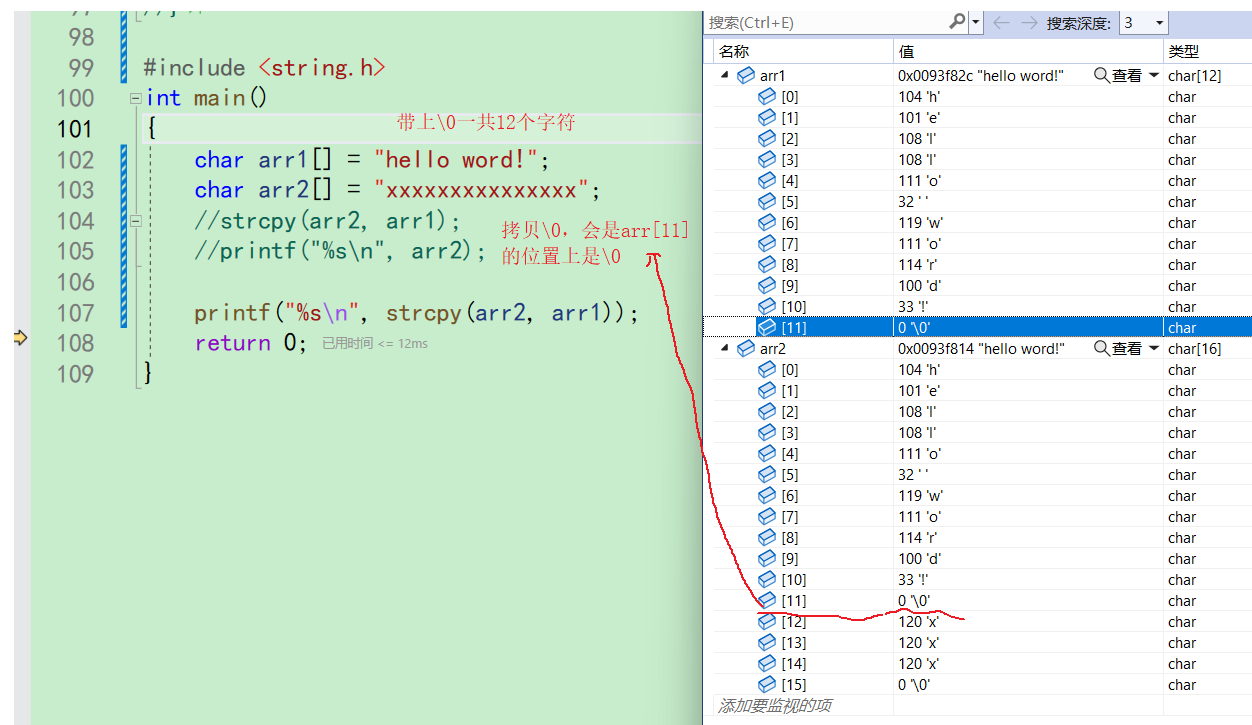
- 用两个数组来演示一下(world单词不会,懒得改了。就当时这个吧)

- strcpy返回的是目的地的地址,在这里也就是返回arr2的地址,而打印字符串需要的就是地址。因此我们可以这样打印

- strcpy会把源字符串的\0也拷贝过去
6.3.2模拟strcpy
6.3.2.1版本1
-
我们先只关心将源字符串拷贝到目的地字符串。而不考虑返回目的地地址的问题,返回类型可以设置成void

相应的,我们先用前面的代码来打拷贝

-
arr1和arr2都是一块连续的空间

-
我们要实现strcpy,那就是arr1内容拷贝到arr2。第一个先拷贝arr1的h,把h拷贝到arr2

-
拷贝完成了,需要把arr1的第二个字符e拷贝到arr2。所以需要指针src向后移动一步,找到e。同样为了对应起来,dest也需要往后走一步

-
当src指向e,要拷贝e到arr2的时候,又要指向
\*dest=\*src。当拷贝完e之后,src、dest又要往下走。往下走之后又要拷贝内容,所以这是个循环

-
当拷贝完成\0之后,循环停止

-
这个时候来写我们的代码

-
循环拷贝完\0,则停止。那就是找到用*src找到\0。

-
当src指向\0的时候,循环就没有继续拷贝了。但是\0还要拷贝,因此可以在循环后这么写

因为当src停下来的时候,src指向的就是\0,而dest因为也++了,所以指向的是\0的对应位置 -
我们来测试一下
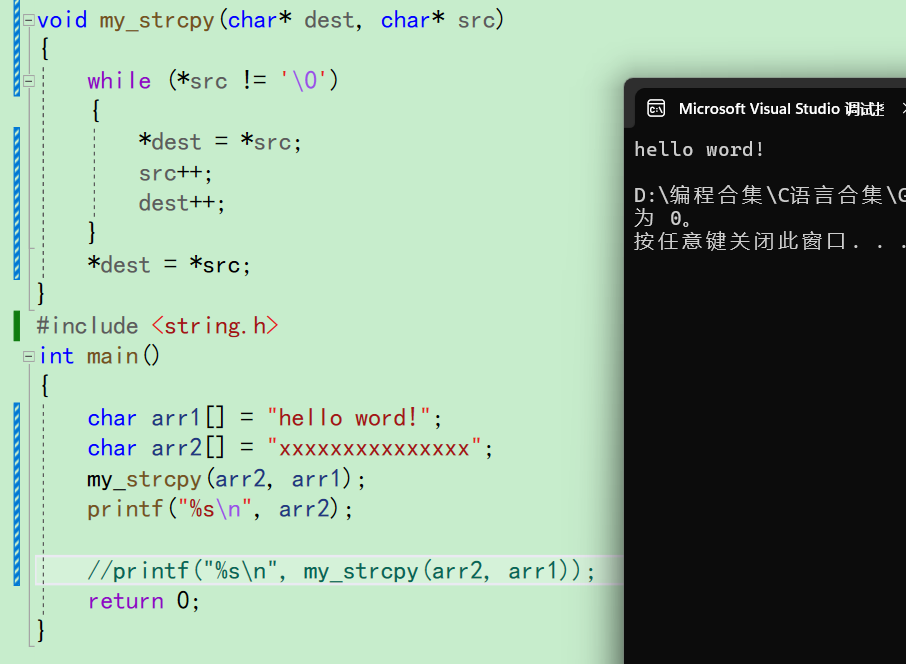
确实做到了拷贝。当我们写到这里的时候,这个函数只是在一定程度上完成了任务。但是还不够好,我们可以优化它 -
比如说我们传参的时候,传了一个指针p,但是p恰好被改成了空指针NULL
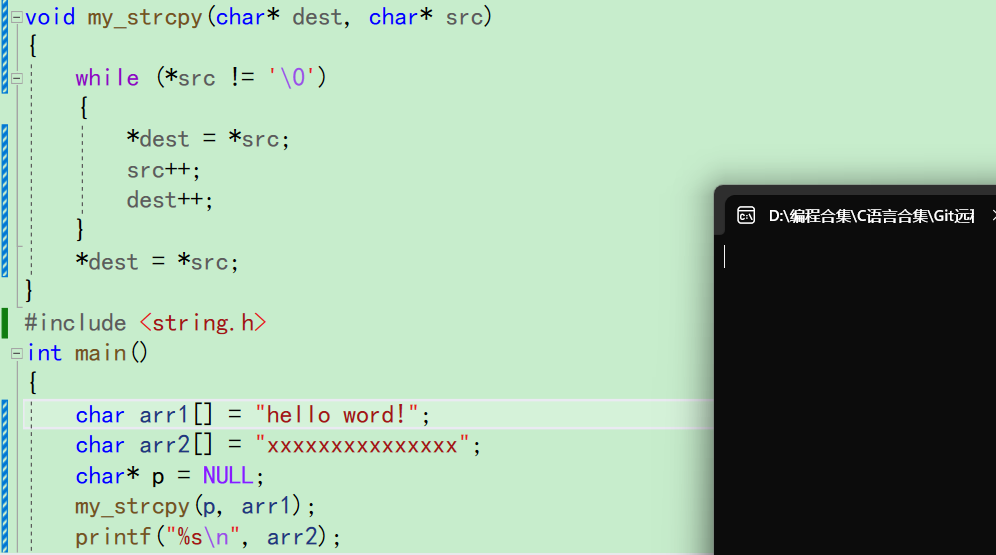
什么都没发生,但是程序已经崩了。因为把空指针传过去给dest,*dest就对空指针解引用了,就出现问题了。 -
如果dest和src这里我们不小心传过来的是NULL,而下面没有做任何防护。这个时候对NULL解引用就很危险。程序崩了的时候,我们都不知道哪里出现了问题,还要一点点去调试。
6.3.2.2版本2
-
我们可以做一个断言来优化版本1,用assert这个宏来断言。需要包含<assert.h>

这个时候屏幕上的报错是非常有意义的,直接告诉我们第几行出错。出错的原因是什么,省了调试的时间。 -
所以这个断言是一个很好的东西,在里面输入输入期望发生的表达式,表达式为真,就啥也不干。表达式为假,就断言,报错。这相当于预判程序可能会出错的问题
比如这里我希望dest != NULL,意思就是我希望dest不是NULL。但当dest是NULL的时候就停下来,报错
6.3.2.3版本3
- 前面说\0,和hello word!没有放在循环那里拷贝。那就把都放在一起拷贝

- 当然也可以这样写

6.3.2.4版本4
- 写到这里的my_strcpy函数,还是和strcpy函数有差别。那就那就是strcpy函数返回了目标空间的的起始地址

- 我们要返回目标空间的起始地址,也就需要保存dest在++之前的地址。之后返回就行了
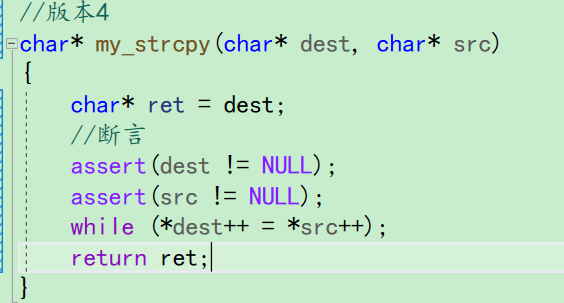
6.3.3.5版本5
-
此时此刻my_strcpy函数和strcpy库函数已经很相似了,但是还是有一点小小的不同

-
少写const,然后再写代码的时候,又错写把
*dest++ = *src++,写成了
*src++ = *dest++。一去运行就出错了

相当于arr2的内容往里arr1里拷贝,放都放不下 -
如果加上了const的话,这里就直接报错了。

这样就逼着你去修改你的错误
6.3.6使用strcpy拷贝要保证目标空间大于或等于源字符串
strcpy函数只关心拷贝,它不管目的地放不放得下来自源字符串的内容。我们作为程序员,在写代码的时候也要保证目的地空间大于或等于源头空间

6.4const的作用
6.4.1const修饰变量
-
我们想改一个变量的值,现在有两种办法
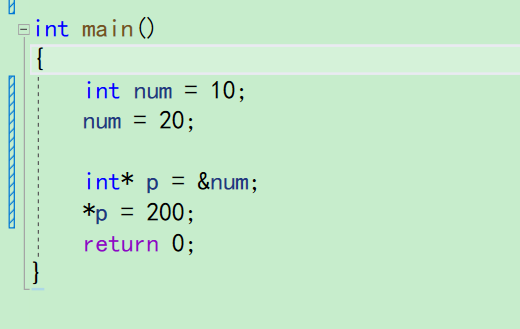
-
当有这样一个基础后,加上const

我们说const修饰变量n,使变量获得了常属性,不能再被修改 -
当直接用变量n改不了的时候,采用指针来改
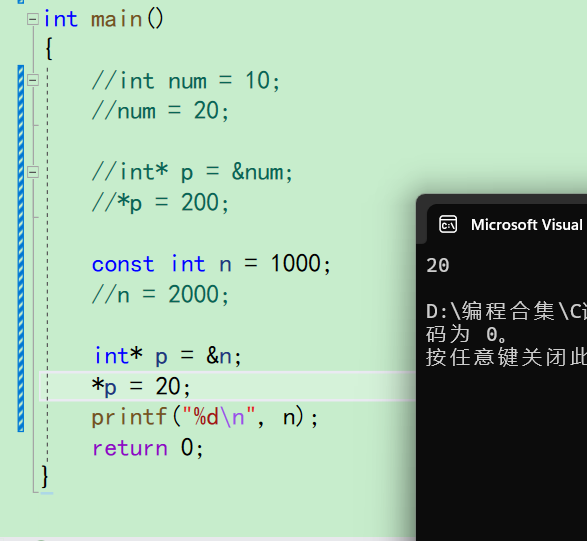
发现居然能改。我们说const修饰n的时候,语法限制n不能改了,当你这样改了之后语法编不故去。但是可以却可以用指针改,其实这也是有问题的。就像狂飙里高启强不方便做一些事情,就告诉老默我想吃鱼了,老默就去做了这些事。
这里的n不能改了,高启强不方便出手,就把n的地址交给老默,让老默去改。但是老默做这个事情也是违法的。
现在n不能改,改就触犯语法规则。但是把n的地址交给p,p就把n改了。p这样改其实本质上也是违背规则的。造出const关键字就是为了不让你改n,而你却千方百计的去找其他方式改,本身就是有为规则的。 -
所以我们为了补齐规则的漏洞,给p也加上了const。你想通过指针p改,那我就给p加上限制,加上const。这个时候就编不过去了

这里就可以看出const是可以修饰指针的
6.4.2const修饰指针
-
正常情况下

-
const int* p = &n;之后
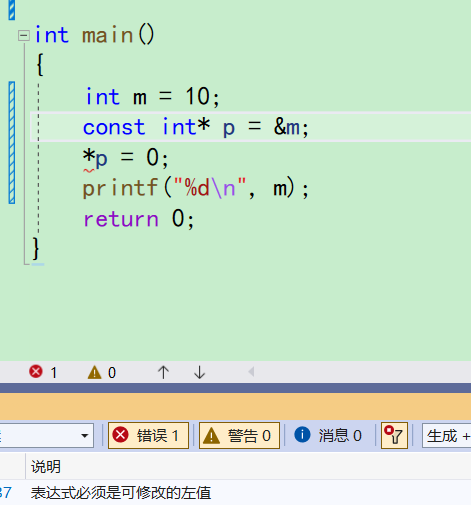
*p这个动作就非法了 -
改p的值,发现能改

所以当const在这个位置的时候,*p改变它所指向的内容不可行,但是改变p的指向可行。 -
将const换一个位置

发现还是不能改*p所指向内容,但是能改p的指向 -
再换一个位置
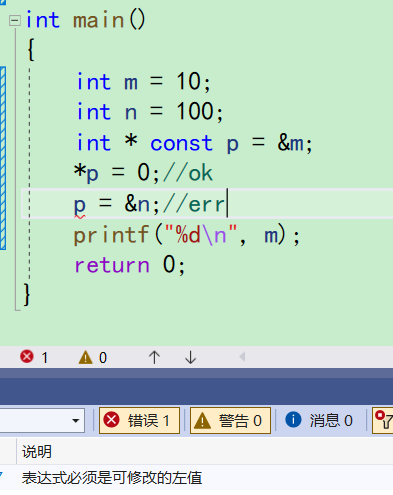
发现能改*p所指向内容,但是不能改p的指向 -
当const放在*左边的时候,限制的是指针指向的内容,不能通过指针改变指针所指向内容,也就是不能通过p改变m的内容。但是指针变量是能改变的,也就是可以改变p的指向。
-
当const在*右边的时候,限制的是指针变量本身,能通过指针改变制作所指向内容,也就是能通过*p改变m。但是不能改变指针变量本身,也就是不能改变p的指向。
-
如果在*两边都加上const,指针指向内容和指针本身都被限制了。都不能改变

-
可以看出const有一种保护的作用。const放在左边保护*p,p指向内容不能被修改。const放在*右边保护p本身,p的指向不能被修改。
-
回头看my_strcpy函数

6.5模拟实现strlen函数
-
之前我们就写过这个函数的循环版本和递归版本

-
现在用assert断言和const优化它

我们只是数一下这个字符串的长度,并不想这个字符串被修改,所以形参加上const限制

-
这个str是指针,万一是空指针就很危险,可以断言
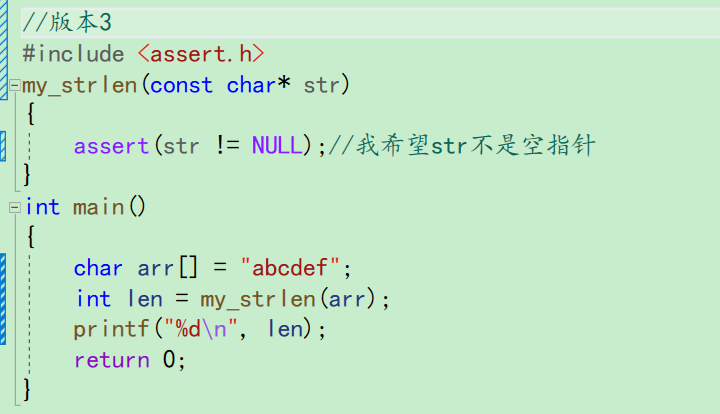
当str不是空指针,str!=NULL成立,继续往下走。当str为空指针时,str!=NULL不成立,断言报错 -
最后写成这样
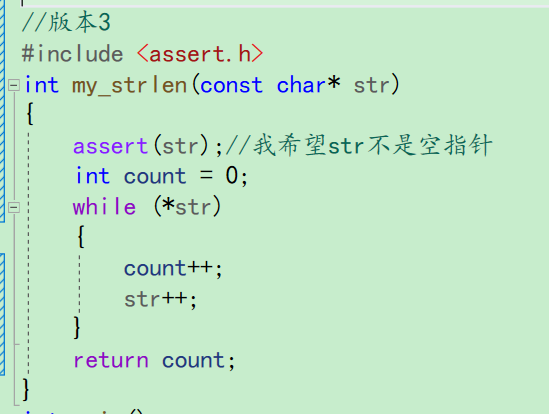
-
my_strlen和strlen库函数还是有点差异

-
我们可以把它的返回类型设置成size_t。紧跟着count,还有接受的len,打印的类型都要变。就严格对应起来了
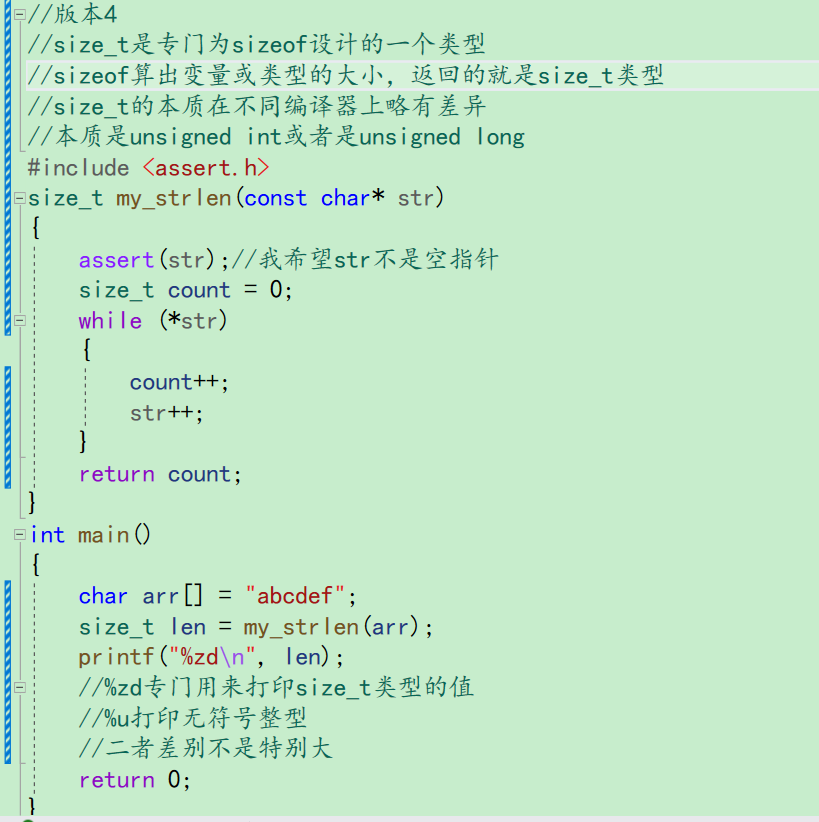
7.编程常见的错误
7.1编译型错误
在编译期间产生的错误。直接看错误提示信息(双击),解决问题。或者凭借经验就可以搞定。相对来说简单
比如说我们现在忘写分号了

这些错误信息有提示作用,当然偶尔有可能是没有用的提示信息。而且不管你在哪一行代码,只要双击就会来到错误的地方。这种编译型错误一般找到的都是语法错误。
7.2 链接型错误
链接期间发生的错误。看错误提示信息,主要在代码中找到错误信息中的标识符,然后定位问题所在。一般是标识符名不存在或者拼写错误

而且双击这种错误,是不会跳到错误代码位置的。相对来说难解决,主要是看符号在不在。你调用了,但是定义的时候,实际不是这个符号,就找到了问题所在
7.3运行时错误
代码运行起来了,但结果不是我们想要的。借助调试,逐步定位问题。最难搞
比如说我们这里Add要实现的是相加,但是不小心把+写成了-号就出现问题了。但是代码也能编译链接过去
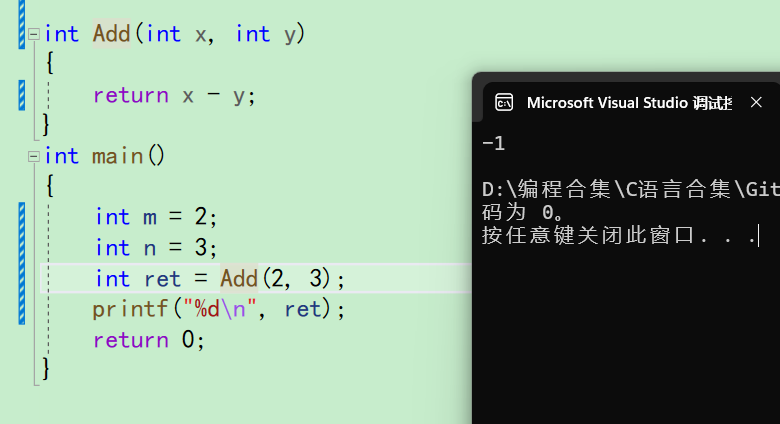
这个就是因为疏忽写错了符号,当我们还是新手的时候,需要花大量的时间去调试找问题。
前期我们出现最多的错误就是编译型错误和连接型错误,但我们熟练了各种语法之后,慢慢都会变成运行时错误。
8.总结
还没想好















 2963
2963











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









