






2024-2025秋季学期第十二周调研技能学习——因果推断(2)
文章目录
一、什么是潜在结果
首先通过两个例子引入这两个概念。
- 假设你现在生病了。而你正在考虑是不是要吃药哪缓解症状。如果你在吃药后痊愈,这是否意味着吃药对你的病情有影响?而如果你没有吃药,你的病同样也痊愈了呢?这种情况下是否吃药就与痊愈没有很强的因果效应。
- 如果你在吃药后痊愈。但是如果你吃药,你的病情没有任何好转。在这种情况下,吃药与痊愈就有很强的因果效应。
用表示结果——是否痊愈,
表示痊愈,
表示为痊愈;用
表示Treatment——是否吃药,
表示吃药,
表示未吃药。
表示如果你吃药,那么会观察到的你吃药后是否痊愈。
表示如果你没吃药,那么会观察到未吃药后是否痊愈。而在例 1中,
,
;在例 2中 ,
,
。这里的 ,
,
就是所说的Potential Outcome。
形式化来说,potential outcome 是指如果你采取treatment
,你的结果会是什么。potential outcome
与observed outcome
不同之处在于,并非所有的potential outcome 都已经被观察到,而是有可能被观察到。
对于单独的个体 i ,individual treatment effect (ITE)独立因果效应被定义为:
只要人口中有一个以上的个体,就是一个随机变量,因为不同的个体会有不同的potential outcome。相比之下,
通常被视为非随机变量,因为下标 i 意味着我们将注意力限制在单个个体(在特定背景下),其potential outcome 是确定性的。
ITE是我们在因果推断中关心的一个主要指标。例如,在上面的情景2中,你会选择吃药,因为吃药对你的健康的因果效应是正的: 。相反,在情景1中,你可能会选择不吃药,因为吃药对你的健康没有因果效应:
。
二、因果推断中的基本问题
因果推断中的基本问题是,如果通过缺失数据来得到因果效应。即我们不能同时观察到 和
,那么我们就不能得到
,就判断不了因果效应。这个问题是因果推断所特有的,因为在因果推断中,我们关心的是如何提出因果claim,而这些claim是以potential outcome来界定的。
平均因果效应
ATE(Average treatment effect),用上述例子理解就是:所有个体中执行t=0和t=1时潜在结果的期望,即
E
[
Y
(
1
)
−
Y
(
0
)
]
E[Y(1)-Y(0)]
E[Y(1)−Y(0)]
利用均值的线性性可以得到
E
[
Y
(
1
)
−
Y
(
0
)
]
=
E
[
Y
(
1
)
]
−
E
[
Y
(
0
)
]
E[Y(1)-Y(0)]=E[Y(1)]-E[Y(0)]
E[Y(1)−Y(0)]=E[Y(1)]−E[Y(0)]
通过观察性实验,我们可能会很容易地认为
E
[
Y
(
1
)
]
−
E
[
Y
(
0
)
]
=
E
[
Y
∣
T
=
1
]
−
E
[
Y
∣
T
=
0
]
E[Y(1)]-E[Y(0)]=E[Y|T=1]-E[Y|T=0]
E[Y(1)]−E[Y(0)]=E[Y∣T=1]−E[Y∣T=0]
其中等式右侧的两项分别为观测数据中,
T
T
T=0和1时结果的均值,两者之差被称为Associational Difference
但大部分情况下,该等式并不成立。原因是后者显示的是关联性的结果,而因果并不等于关联。混杂变量的存在,使得
E
[
Y
∣
T
=
1
]
E[Y|T=1]
E[Y∣T=1]和
E
[
Y
∣
T
=
0
]
E[Y|T=0]
E[Y∣T=0]不可比较(not comperable)。下面用“穿鞋睡觉与睡眠质量”为例,说明可比性的条件。

此时由于左边圆圈中drunk和sober的人数比值高于人群中的比值,而右边圆圈的比值低于人群中的比值,所以二者之差是没有意义的。

此时左右圆圈中drunk和sober的人数比值与人群中的比值相等,观测到的 T = 0 T=0 T=0和 T = 1 T=1 T=1时结果的均值之差就可以作为 t = 0 t=0 t=0和 t = 1 t=1 t=1的潜在结果之差。而这就是随机对照实验(RCTs)的良好性质。
一系列假设
阻碍ATE=associational difference的一个关键问题在于,
T
=
0
T=0
T=0的观察对象的
Y
(
t
)
Y(t)
Y(t)与
T
=
1
T=1
T=1的观察对象的
Y
(
t
)
Y(t)
Y(t)不同。简单地说,就是
Y
(
t
)
Y(t)
Y(t)与
T
T
T不独立。还是以“穿鞋睡觉与睡眠质量”为例,上面的第一张图中,若左圆圈的人群没有进行
T
=
1
T=1
T=1的实验,而进行
T
=
0
T=0
T=0的实验,得到的结果,与右圆圈的人群进行
T
=
0
T=0
T=0的结果不同,这说明
Y
(
t
)
Y(t)
Y(t)与
T
T
T等于1还是0有关。
因此,如果我们假设
Y
(
t
)
Y(t)
Y(t)与
T
T
T独立,就有$$E[Y(1)] - E[Y(0)] = E[Y(1) | T = 1] - E[Y(0) | T = 0]
= E[Y | T = 1] -E[Y | T = 0]$$
其中第一个等号成立的条件就是
Y
(
t
)
Y(t)
Y(t)与
T
T
T独立,第二个等号成立的条件先按下不表。
可忽略和可交换
可忽略(Ignorability)指的是假设
T
=
T=
T= 0和
T
=
1
T=1
T=1 两组的分配过程是无所谓的。
用因果图可以直观的反映这个假设:

可交换(Exchangeablity)指的是假设
T
=
i
T=i
T=i和
T
=
j
T=j
T=j两组的人群如果交换了,得到的结果与不交换的结果相同。
用数学形式表达为:
E
[
Y
(
i
)
∣
T
=
j
]
=
E
[
Y
(
i
)
∣
T
=
i
]
E[Y(i)|T=j]=E[Y(i)|T=i]
E[Y(i)∣T=j]=E[Y(i)∣T=i]
E
[
Y
(
j
)
∣
T
=
i
]
=
E
[
Y
(
j
)
∣
T
=
j
]
E[Y(j)|T=i]=E[Y(j)|T=j]
E[Y(j)∣T=i]=E[Y(j)∣T=j]
以吃药问题为例,不吃药的组若吃药的康复率与吃药组的康复率相同,反之亦然。
上述两种假设都与“
Y
(
t
)
Y(t)
Y(t)和
T
T
T独立”等价,可以看作同一假设的两种表述形式。
条件可交换
很显然,上述的两种假设,可忽略和可交换在实际的观察实验中并不现实。回想上一节里的调整公式,如果我们控制了混杂变量
X
X
X,再考察混杂变量为条件下的
T
∣
X
T|X
T∣X,是否就能实现上述两种假设了呢?
以“睡觉穿鞋与睡眠质量”为例,在混杂变量
X
X
X(drunk or sober)没有得到控制时,由于
X
X
X在
T
=
T=
T= 0和1两组的分布不同,导致两组不可交换。若混杂变量只有
X
X
X,我们控制
X
=
1
X=1
X=1(drunk)时,
T
=
0
T=0
T=0组的人群若与
T
=
1
T=1
T=1的人群交换,得到的结果应该与交换前相同,因为交换前后的人群是完全相同的(都喝醉了)。此时就实现了条件可交换(Conditional exchangeability)。
需要注意的是,只有在所有的混杂变量都被控制时,才能达到独立的效果。
在实际观测实验中,有这样的 W W W存在是大有可能的,因此我们要尽可能地多拟合混杂变量,以达到条件可交换。
正定性与重叠
回顾调整公式
E
[
Y
(
1
)
−
Y
(
0
)
]
=
E
X
[
E
[
Y
∣
T
=
1
,
X
]
−
E
[
Y
∣
T
=
0
,
X
]
]
E[Y(1)−Y(0)]=E_X[E[Y∣T=1,X]−E[Y∣T=0,X]]
E[Y(1)−Y(0)]=EX[E[Y∣T=1,X]−E[Y∣T=0,X]]
后一项可以写作求和形式为:
∑
x
P
(
X
=
x
)
(
∑
y
y
P
(
Y
=
y
∣
T
=
1
,
X
=
x
)
−
∑
y
y
P
(
Y
=
y
∣
T
=
0
,
X
=
x
)
)
\sum_xP(X=x)(\sum_yyP(Y=y∣T=1,X=x)−\sum_yyP(Y=y∣T=0,X=x))
x∑P(X=x)(y∑yP(Y=y∣T=1,X=x)−y∑yP(Y=y∣T=0,X=x))
由贝叶斯公式,可以化为:
∑
x
P
(
X
=
x
)
(
∑
y
y
P
(
Y
=
y
,
T
=
1
,
X
=
x
)
P
(
T
=
1
∣
X
=
x
)
P
(
X
=
x
)
−
∑
y
y
P
(
Y
=
y
,
T
=
0
,
X
=
x
)
P
(
T
=
0
∣
X
=
x
)
P
(
X
=
x
)
)
\sum_x P(X = x) \left( \sum_y y \frac{P(Y = y, T = 1, X = x)}{P(T = 1 \mid X = x) P(X = x)} - \sum_y y \frac{P(Y = y, T = 0, X = x)}{P(T = 0 \mid X = x) P(X = x)} \right)
x∑P(X=x)(y∑yP(T=1∣X=x)P(X=x)P(Y=y,T=1,X=x)−y∑yP(T=0∣X=x)P(X=x)P(Y=y,T=0,X=x))
注意到分母项
P
(
T
=
1
∣
X
=
x
)
P(T = 1 \mid X = x)
P(T=1∣X=x)和
P
(
T
=
0
∣
X
=
x
)
P(T = 0 \mid X = x)
P(T=0∣X=x),正定性(positivity)表述的就是这两项大于0。下面我们用图形的重叠(overlap)揭示这一点。

如图的
x
x
x连续分布,计算时,我们可以把
x
x
x缩小到
(
x
1
,
x
2
)
∪
(
x
3
,
x
4
)
(x_1,x_2)∪ (x_3,x_4)
(x1,x2)∪(x3,x4),然而,在这个分布上,存在
P
(
T
=
1
∣
X
=
x
)
=
0
P(T = 1 \mid X = x)=0
P(T=1∣X=x)=0和
P
(
T
=
0
∣
X
=
x
)
=
0
P(T = 0 \mid X = x)=0
P(T=0∣X=x)=0 的情况,此时调整公式不成立。

这种情况虽然有重叠但不充分,也是违背正定性的。

此时 T = T= T= 0和1的 x x x分布完全重叠,才符合条件。
注意我们考察重叠时,关注的是
P
(
X
∣
T
=
0
)
P(X|T=0)
P(X∣T=0)和
P
(
X
∣
T
=
1
)
P(X|T=1)
P(X∣T=1)在
x
x
x分布上的重叠,且只有所有
T
T
T为条件的
X
X
X的分布相同时,才满足正定性。
上述的混杂变量为一维,可以简化为一条轴(因为我们此时不关注
P
(
x
∣
t
P(x|t
P(x∣t)的大小,只关注其
>
0
>0
>0对应的
x
x
x的分布区间,如图:

当混杂变量不止一维时,如下图显示的二维情形,仍然要求两块完全重合时,才满足正定性的假设。

无干涉
我们上面考虑的所有变量,都发生在一个人身上,而与其他的实验对象无关,实际中,实验对象之间也可能存在相互干涉。例如,要研究养狗对心理健康的影响时,养狗组内的两人由于到同一地方遛狗而有了互相交谈的机会,使二人心理健康有所提升,这就是干涉(interference)。无干涉指的就是实验个体的潜在结果与其他实验对象接受的 T T T无关。
一致性
一致性(Consistency)指的是:
E
[
Y
(
1
)
∣
T
=
1
]
=
E
[
Y
∣
T
=
1
]
E[Y(1)|T=1]=E[Y|T=1]
E[Y(1)∣T=1]=E[Y∣T=1]
乍一看,这个式子貌似显然成立,但让我们来考虑一种情形:实验者要观察是否吃早饭对身体健康的影响,同一个人,如果早餐吃适量的包子和豆浆,得到的
E
[
Y
(
1
)
∣
T
=
1
]
=
1
E[Y(1)|T=1]=1
E[Y(1)∣T=1]=1(健康);如果吃过量的炸鸡汉堡,得到的
E
[
Y
(
1
)
∣
T
=
1
]
=
0
E[Y(1)|T=1]=0
E[Y(1)∣T=1]=0。导致
E
[
Y
(
1
)
∣
T
=
1
≠
E
[
Y
∣
T
=
1
]
E[Y(1)|T=1≠E[Y|T=1]
E[Y(1)∣T=1=E[Y∣T=1] ,而与使
T
=
t
T=t
T=t的过程有关,这是由于
Y
(
1
)
Y(1)
Y(1)没有被定义清楚导致的。
这也就回答了第二个等式为什么成立的问题。
E
[
Y
(
1
)
∣
T
=
1
]
−
E
[
Y
(
0
)
∣
T
=
0
]
=
E
[
Y
∣
T
=
1
]
−
E
[
Y
∣
T
=
0
]
E[Y(1) | T = 1] - E[Y(0) | T = 0] = E[Y | T = 1] -E[Y | T = 0]
E[Y(1)∣T=1]−E[Y(0)∣T=0]=E[Y∣T=1]−E[Y∣T=0]
四、一个包含估计的完整示例
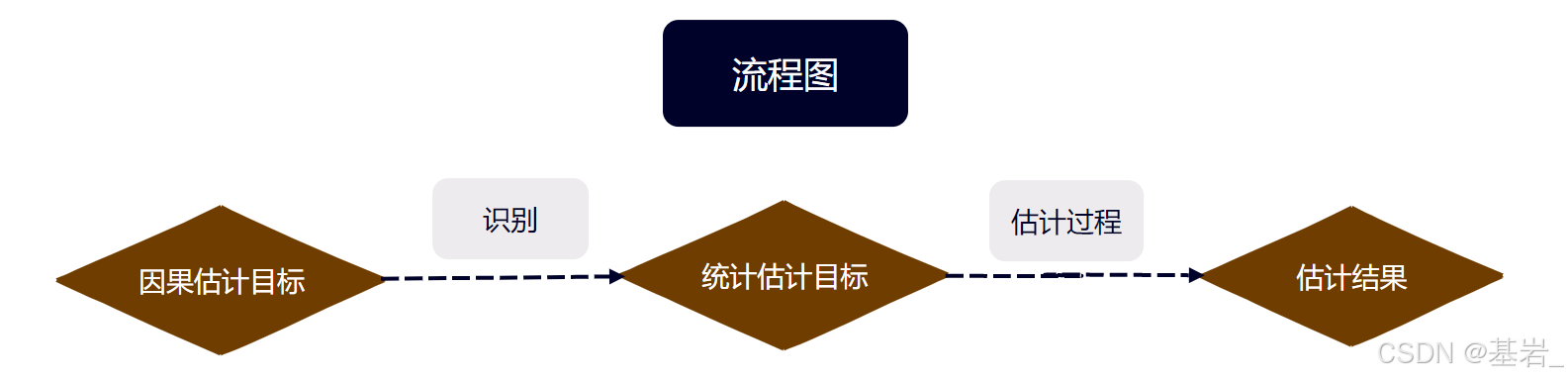
1.因果估计主要流程
-
相关定义:
- 估计目标:任何我们想要估计的量。
- 因果估计目标:例如:E[Y(1) - Y(0)]。
- 统计估计目标:例如:E_x [E[Y | T = 1, X] - E[Y | T = 0, X]]。
- 识别:识别是因果推断中的一个关键步骤,它涉及将因果估计目标转化为可以通过数据进行分析的统计估计目标。识别是关于如何解决因果推断中的混杂因素问题,确保我们能够从观测数据中得出因果结论。
- 估计值:使用数据对某个估计目标的近似。
- 估计:从数据加上估计目标到估计值的过程。估计涉及使用统计方法来计算干预效应的大小。
- 估计目标:任何我们想要估计的量。
-
流程图:
2.关于钠摄入量对血压影响
- 研究问题:探讨钠摄入量对血压的影响。
- 研究动机:鉴于46%的美国人患有高血压,且高血压与增加的死亡率相关,因此研究钠摄入量与血压之间的关系具有重要意义。
- 数据来源与变量:
- 数据来源于Luque-Fernandez等人(2018)的流行病学研究。
- 结果变量 Y:收缩压(连续变量),即研究的主要观测指标。
- 处理变量 T:钠摄入量(高于3.5毫克为1,低于为0),即研究的主要解释变量。
- 协变量 X:年龄和尿中蛋白质排泄量,即研究中需要控制的变量。
- 模拟数据:在研究中模拟了“真实”的平均处理效应(ATE)为1.05,以评估钠摄入量对血压的平均影响。
3.平均处理效应(ATE)的估计过程
-
真实ATE:
- 真实的平均处理效应为:
E [ Y ( 1 ) − Y ( 0 ) ] = 1.05 E[Y(1)−Y(0)]=1.05 E[Y(1)−Y(0)]=1.05
- 真实的平均处理效应为:
-
识别:
-
识别ATE的公式为:
-
E [ Y ( 1 ) − Y ( 0 ) ] = E X [ E [ Y ∣ T = 1 , X ] − E [ Y ∣ T = 0 , X ] ] E[Y(1) - Y(0)] = E_X \left[ E[Y \mid T=1, X] - E[Y \mid T=0, X] \right] E[Y(1)−Y(0)]=EX[E[Y∣T=1,X]−E[Y∣T=0,X]]
-
-
估计:
-
估计ATE的公式为:
1 n ∑ x [ E [ Y ∣ T = 1 , x ] − E [ Y ∣ T = 0 , x ] ] \frac{1}{n} \sum_x \left[ E[Y \mid T=1, x] - E[Y \mid T=0, x] \right] n1x∑[E[Y∣T=1,x]−E[Y∣T=0,x]] -
公式下方标注了“模型(线性回归)”表示使用线性回归模型进行估计。
-
-
估计值:
-
估计值为:0.85
-
计算估计误差:
∣ 0.85 − 1.05 1.05 ∣ × 100 % = 19 % \left| \frac{0.85 - 1.05}{1.05} \right| \times 100\% = 19\% 1.050.85−1.05 ×100%=19%
-
-
朴素估计:
-
朴素估计公式为:
E [ Y ∣ T = 1 ] − E [ Y ∣ T = 0 ] E[Y \mid T=1] - E[Y \mid T=0] E[Y∣T=1]−E[Y∣T=0] -
朴素估计值为:5.33
-
计算朴素估计误差:
∣ 5.33 − 1.05 1.05 ∣ × 100 % = 407 % \left| \frac{5.33 - 1.05}{1.05} \right| \times 100\% = 407\% 1.055.33−1.05 ×100%=407%
-
4.线性回归系数在分析中的使用
-
假设线性参数形式:
Y = α T + β X Y = \alpha T + \beta X Y=αT+βX -
运行线性回归:
Y = α ^ T + β ^ X Y = \hat{\alpha} T + \hat{\beta} X Y=α^T+β^X
其中:
α ^ = 0.85 \hat{\alpha} = 0.85 α^=0.85 -
连续处理:
E [ Y ( t ) ] → α ^ = 0.85 E[Y(t)] \rightarrow \hat{\alpha} = 0.85 E[Y(t)]→α^=0.85 -
严重限制:指出因果效应对于所有个体是相同的。
-
Y i ( t ) = α t + β x i Y_i(t) = \alpha t + \beta x_i Yi(t)=αt+βxi
-
Y i ( 1 ) − Y i ( 0 ) = α ⋅ 1 + β x i − ( α ⋅ 0 − β x i ) = α Y_i(1) - Y_i(0) = \alpha \cdot 1 + \beta x_i - (\alpha \cdot 0 - \beta x_i) = \alpha Yi(1)−Yi(0)=α⋅1+βxi−(α⋅0−βxi)=α
-
-
参考:建议查看 Morgan & Winship (2014) 的第 6.2 和 6.3 节以获得更完整的批评。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









