







 本文介绍了线性代数在AI、机器学习和深度学习中的应用,包括基本概念如矩阵、向量、单位矩阵、对角矩阵、对称矩阵和范数,以及矩阵乘法、矩阵的逆、特征值和特征向量等重要概念。此外,还讨论了矩阵在数据表示、线性回归、主成分分析和奇异值分解等常见任务中的作用。
本文介绍了线性代数在AI、机器学习和深度学习中的应用,包括基本概念如矩阵、向量、单位矩阵、对角矩阵、对称矩阵和范数,以及矩阵乘法、矩阵的逆、特征值和特征向量等重要概念。此外,还讨论了矩阵在数据表示、线性回归、主成分分析和奇异值分解等常见任务中的作用。
前言:菜大是一个纯纯的理工男,本科时期学习了线性代数,研究生学习的是矩阵论。相信很多人和菜大一样本科学习线性代数感觉很抽象,学完课程可能脑瓜子嗡嗡的,What?这有啥用?也会有人在信息论或者机器学习的学习和论文中,有很多黑体矢量的微分或者积分,再加上梯度函数,让人眼花缭乱。菜大学习了CS229课程的线代材料,并记录了AI中线性代数学习中用到的知识。
文章目录
- AI|机器学习|深度学习:AI中线性代数知识一览无余
- 1. 基本概念
- 2. 矩阵乘法
- 3. 性质
- 3.1 单位矩阵(Identity Matrix)
- 3.2 对角矩阵(diagonal matrix)
- 3.3 对称矩阵(Symmetric Matrices)
- 3.4 迹(Trace)
- 3.5 范数(Norms)
- 3.6 矩阵转置(Transpose)
- 3.7 矩阵的逆(The Inverse of a Square Matrix)
- 3.8 正交矩阵(Orthogonal Matrices)
- 3.9 行列式(Determinant)
- 3.10 二次型与半正定矩阵
- 3.11 特征值与特征向量(Eigenvalues and Eigenvectors)
- 3.12 对称矩阵的特征值与特征向量(Eigenvalues and Eigenvectors of Symmetric Matrices)
- 4. 矩阵计算
- 5.常见应用
AI|机器学习|深度学习:AI中线性代数知识一览无余
线性代数能够表示以及操作多个线性方程组。例如:考虑下面的方程组:
3
x
1
−
4
x
2
+
2
x
3
=
2
−
5
x
1
+
x
2
−
3
x
3
=
8
2
x
1
−
5
x
2
+
4
x
3
=
10.
\begin{aligned} &3x_1-4x_2+2x_3=2\\ &-5x_1+x_2-3x_3=8\\ &2x_1-5x_2+4x_3=10. \end{aligned}
3x1−4x2+2x3=2−5x1+x2−3x3=82x1−5x2+4x3=10.
在之前的教育经历中,上面的方程组称为三元一次方程组,最终可以分别接出三个变量分别是多少。在线性代数中,可以通过矩阵的乘法描述上面的方程组,如下:
A
x
=
b
w
i
t
h
:
A
=
[
3
−
4
2
−
5
1
−
3
2
−
5
4
]
,
b
=
[
2
8
10
]
\begin{aligned} &Ax=b\\ &with:A=\left[ \begin{array}{cc} 3\quad -4\quad 2\\ &-5\quad 1\quad -3 \\ 2\quad -5 \quad4 \end{array}\right],\quad b=\left[ \begin{array}{cc} 2\\8\\10 \end{array}\right] \end{aligned}
Ax=bwith:A=
3−422−54−51−3
,b=
2810
1. 基本概念
向量是数学中一个重要的概念,把数字排成一行或一列。它是描述空间的重要工具,比如二维向量
[
3
2
]
T
\left[ \begin{array}{cc} 3 \quad 2\end{array}\right]^T
[32]T,第一个成分是3,第2个成分是2。将向量放在二维平面中,x坐标是3,y坐标是2的一个点。也可以看作是以平面原点为起点,目标
(
3
,
2
)
(3, 2)
(3,2)的有向线段。
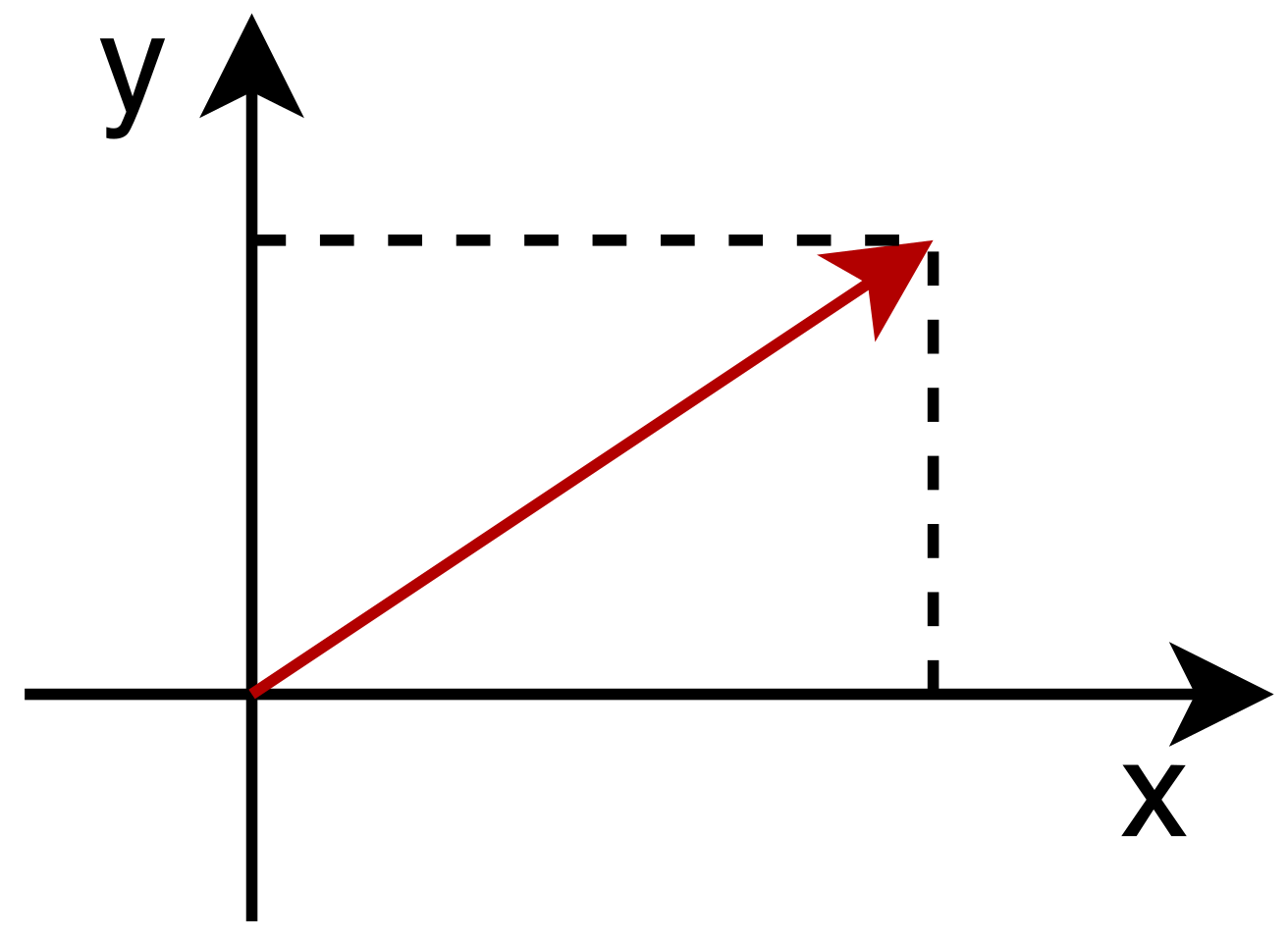
n维向量n个数
a
1
a
2
a
3
.
.
.
a
n
a_1 \quad a_2 \quad a_3...a_n
a1a2a3...an组成n元有序数组,称为n维向量,这n个数称为该向量的n个分量。
行向量n维向量写成一行,称为行向量,记为:
x
=
[
x
1
x
2
⋯
x
n
]
x=\left[ \begin{array}{cc} x_1 \quad x_2\cdots x_n\end{array}\right]
x=[x1x2⋯xn]
列向量n维向量写成一列称为列向量,记为:
x
=
[
x
1
x
2
⋮
x
n
]
x=\left[ \begin{array}{cc} x_1\\ x_2\\\vdots \\x_n\end{array}\right]
x=
x1x2⋮xn
矩阵
A
∈
R
n
×
n
A\in R^{n\times n}
A∈Rn×n,其中
a
i
j
a_{ij}
aij记作矩阵A的第
i
i
i行,第
j
j
j列的元素,记为:
A
=
[
a
11
a
12
⋯
a
1
n
a
21
a
22
⋯
a
2
n
⋮
⋮
⋱
⋮
a
m
1
a
m
2
⋯
a
m
n
]
A=\left[ \begin{array}{cc} a_{11}\quad a_{12}\cdots a_{1n}\\ a_{21}\quad a_{22}\cdots a_{2n}\\ \vdots\quad \vdots \quad \ddots \quad \vdots\\ a_{m1}\quad a_{m2}\cdots a_{mn} \end{array}\right]
A=
a11a12⋯a1na21a22⋯a2n⋮⋮⋱⋮am1am2⋯amn
2. 矩阵乘法
向量的加法
两个维数相同的向量可以加法运算,将相同位置上对应元素相加即可,向量加法保持维数保持不变:
[
u
1
u
2
⋮
u
n
]
+
[
v
1
v
2
⋮
v
n
]
=
[
u
1
+
v
1
u
2
+
v
2
⋮
u
n
+
v
n
]
\left[ \begin{array}{cc} u_1\\ u_2\\\vdots \\u_n\end{array}\right] + \left[ \begin{array}{cc} v_1\\ v_2\\\vdots \\v_n\end{array}\right] = \left[ \begin{array}{cc} u_1+v_1\\ u_2+v_2\\\vdots \\u_n+v_n\end{array}\right]
u1u2⋮un
+
v1v2⋮vn
=
u1+v1u2+v2⋮un+vn
向量数乘
向量的数乘是将参与乘法运算的实数和向量的每个元素分别相乘,结果向量保持维数不变,数乘就是将向量沿着所在直线的方向拉长到相应的倍数,方向和参与运算的数字的正负号相关:
c
[
v
1
v
2
⋮
v
n
]
=
[
c
⋅
v
1
c
⋅
v
2
⋮
c
⋅
v
n
]
c \left[ \begin{array}{cc} v_1\\ v_2\\\vdots \\v_n\end{array}\right] = \left[ \begin{array}{cc} c\cdot v_1\\ c\cdot v_2\\\vdots \\c\cdot v_n\end{array}\right]
c
v1v2⋮vn
=
c⋅v1c⋅v2⋮c⋅vn
向量X向量
x
T
y
x^Ty
xTy称为内积,有时候也称为点积,是一种特殊的矩阵乘法,且
x
T
y
=
y
T
x
x^Ty=y^Tx
xTy=yTx。
x
T
y
∈
R
=
[
x
1
x
2
⋯
x
n
]
[
y
1
y
2
⋮
y
n
]
=
∑
i
=
1
n
x
i
y
j
x^Ty\in R=\left[ \begin{array}{cc} x_1\quad x_2\cdots x_n\end{array}\right]\left[ \begin{array}{cc} y_1\\ y_2\\\vdots \\y_n\end{array}\right]=\sum_{i=1}^n{x_iy_j}
xTy∈R=[x1x2⋯xn]
y1y2⋮yn
=i=1∑nxiyj
x
y
T
xy^T
xyT称为外积。
x
y
T
∈
R
m
×
n
=
[
x
1
x
2
⋮
x
n
]
[
y
1
y
2
⋯
y
n
]
=
[
x
1
y
1
x
1
y
2
⋯
x
1
y
n
x
2
y
1
x
2
y
2
⋯
x
2
y
n
⋮
⋮
⋱
⋮
x
m
y
1
x
m
y
2
⋯
x
m
y
n
]
xy^T\in R^{m\times n}=\left[ \begin{array}{cc} x_1\\ x_2\\ \vdots \\x_n\end{array}\right]\left[ \begin{array}{cc} y_1\quad y_2 \cdots y_n\end{array}\right]= \left[ \begin{array}{cc} x_1y_1\quad x_1y_2\cdots x_1y_n\\ x_2y_1\quad x_2y_2\cdots x_2y_n\\ \vdots\quad \vdots \quad \ddots \quad \vdots\\ x_my_1\quad x_my_2\cdots x_my_n \end{array}\right]
xyT∈Rm×n=
x1x2⋮xn
[y1y2⋯yn]=
x1y1x1y2⋯x1ynx2y1x2y2⋯x2yn⋮⋮⋱⋮xmy1xmy2⋯xmyn
矩阵X向量
矩阵与向量的乘法,可以有多种角度看,若把矩阵看作是n个行向量组成,则记为:
y
=
A
x
=
[
⋯
a
1
T
⋯
⋯
a
2
T
⋯
⋮
⋯
a
n
T
⋯
]
x
=
[
a
1
T
x
a
2
T
x
⋮
a
n
T
x
]
y=Ax=\left[ \begin{array}{cc} \cdots \quad a_1^T\quad \cdots\\ \cdots \quad a_2^T\quad \cdots\\\vdots \\\cdots \quad a_n^T\quad \cdots\end{array}\right]x=\left[ \begin{array}{cc}a_1^Tx\\ a_2^Tx\\\vdots \\ a_n^Tx\end{array}\right]
y=Ax=
⋯a1T⋯⋯a2T⋯⋮⋯anT⋯
x=
a1Txa2Tx⋮anTx
若将矩阵看作是m个列向量,则可记为:
y
=
A
x
=
[
a
1
⋯
a
2
⋯
a
n
]
x
=
[
⋮
a
1
⋮
]
x
+
[
⋮
a
2
⋮
]
x
+
⋯
+
[
⋮
a
n
⋮
]
x
y=Ax=\left[ \begin{array}{cc} a^1\cdots a^2 \cdots a^n\end{array}\right]x=\left[ \begin{array}{cc}\vdots \\ a^1\\ \vdots\end{array}\right]x+\left[ \begin{array}{cc}\vdots \\ a^2\\ \vdots\end{array}\right]x+\cdots+\left[ \begin{array}{cc}\vdots \\ a^n\\ \vdots\end{array}\right]x
y=Ax=[a1⋯a2⋯an]x=
⋮a1⋮
x+
⋮a2⋮
x+⋯+
⋮an⋮
x
矩阵x矩阵
假设有两个矩阵:
A
∈
R
m
×
n
,
B
∈
R
n
×
p
A\in R^{m \times n}, B\in R^{n \times p}
A∈Rm×n,B∈Rn×p,矩阵之间的乘法要求A的列与B的行大小一致且乘法结果为矩阵,记为:
C
=
A
×
B
∈
R
m
×
p
w
h
e
r
e
:
C
i
j
=
∑
k
=
1
n
A
i
k
B
k
j
\begin{aligned} C=A \times B \in R^{m \times p} \quad where:C_{ij}=\sum_{k=1}^nA_{ik}B_{kj} \end{aligned}
C=A×B∈Rm×pwhere:Cij=k=1∑nAikBkj
由上面的知识可以得知,矩阵可以看做是多个行向量或者列向量组成,矩阵乘法可以看作是向量之间的乘法。
- **行向量x列向量。**如果矩阵 A = [ a 1 T a 2 T ⋯ a n T ] , B = [ b 1 b 2 … b n ] A=[a_1^T \quad a_2^T \cdots a_n^T],B=[b^1 \quad b^2 \dots b^n] A=[a1Ta2T⋯anT],B=[b1b2…bn],则:
C = A B = [ ⋯ a 1 T ⋯ ⋯ a 2 T ⋯ ⋮ ⋯ a m T ⋯ ] [ b 1 ⋯ b 2 ⋯ b n ] = [ a 1 T b 1 a 1 T b 2 ⋯ a 1 T b n a 2 T b 1 a 2 T b 2 ⋯ a 2 T b n ⋮ ⋮ ⋱ ⋮ a m T b 1 a m T b 2 ⋯ a m T b n ] C = AB = \left[ \begin{array}{cc} \cdots \quad a_1^T\quad \cdots\\ \cdots \quad a_2^T\quad \cdots\\\vdots \\\cdots \quad a_m^T\quad \cdots\end{array}\right] \left[ \begin{array}{cc} b^1\cdots b^2 \cdots b^n\end{array}\right]= \left[ \begin{array}{cc} a_1^Tb_1\quad a_1^Tb_2\cdots a_1^Tb_n\\ a_2^Tb_1\quad a_2^Tb_2\cdots a_2^Tb_n\\ \vdots\quad \vdots \quad \ddots \quad \vdots\\ a_m^Tb_1\quad a_m^Tb_2\cdots a_m^Tb_n \end{array}\right] C=AB= ⋯a1T⋯⋯a2T⋯⋮⋯amT⋯ [b1⋯b2⋯bn]= a1Tb1a1Tb2⋯a1Tbna2Tb1a2Tb2⋯a2Tbn⋮⋮⋱⋮amTb1amTb2⋯amTbn
- 列向量x行向量。如果矩阵 A = [ a 1 a 2 ⋯ a n ] , B = [ b 1 T b 2 T … b n T ] A=[a^1 \quad a^2 \cdots a^n],B=[b_1^T \quad b_2^T \dots b_n^T] A=[a1a2⋯an],B=[b1Tb2T…bnT],则:
C = A B = [ a 1 ⋯ a 2 ⋯ a n ] [ ⋯ b 1 T ⋯ ⋯ b 2 T ⋯ ⋮ ⋯ b n T ⋯ ] = ∑ i = 1 n a i b j T C = AB = \left[ \begin{array}{cc} a^1\cdots a^2 \cdots a^n\end{array}\right] \left[ \begin{array}{cc} \cdots \quad b_1^T\quad \cdots\\ \cdots \quad b_2^T\quad \cdots\\\vdots \\\cdots \quad b_n^T\quad \cdots\end{array}\right]= \sum_{i=1}^na^ib_j^T C=AB=[a1⋯a2⋯an] ⋯b1T⋯⋯b2T⋯⋮⋯bnT⋯ =i=1∑naibjT
- 矩阵x列向量。如果 B = [ b 1 b 2 ⋯ b n ] B=[b^1 \quad b^2 \cdots b^n] B=[b1b2⋯bn],则:
C = A B = A [ b 1 b 2 ⋯ b n ] = [ A b 1 A b 2 ⋯ A b n ] C=AB=A [b^1 \quad b^2 \cdots b^n]=[Ab^1 \quad Ab^2 \cdots Ab^n] C=AB=A[b1b2⋯bn]=[Ab1Ab2⋯Abn]
- 行向量x矩阵。如果 A = [ a 1 T a 2 T ⋯ a n T ] A=[a^T_1 \quad a^T_2 \cdots a^T_n] A=[a1Ta2T⋯anT],则:
C = A B = [ a 1 T a 2 T ⋯ a n T ] B = [ a 1 T B a 2 T B ⋯ a n T B ] C=AB=[a^T_1 \quad a^T_2 \cdots a^T_n]B=[a^T_1B \quad a^T_2B \cdots a^T_nB] C=AB=[a1Ta2T⋯anT]B=[a1TBa2TB⋯anTB]
不同的角度分解矩阵的乘法的好处是,将矩阵乘法看作是向量维度的操作而不是标量的乘法(标量的乘法是矩阵中一系列元素的乘法求和,乘法的分解对于理解空间转换与线性变化也有极大的帮助)。
3. 性质
3.1 单位矩阵(Identity Matrix)
矩阵
I
I
I为单位矩阵,则对角线元素为1,非对角线为0,记为:
I
=
[
1
0
⋯
0
0
1
⋯
0
⋮
⋮
⋱
⋮
0
0
⋯
1
]
I=\left[ \begin{array}{cc} 1\quad 0\quad \cdots\quad 0\\ 0\quad 1 \quad \cdots \quad 0\\ \vdots\quad \vdots \quad \ddots \quad \vdots\\ 0\quad 0 \quad \cdots \quad 1 \end{array}\right]
I=
10⋯001⋯0⋮⋮⋱⋮00⋯1
对于矩阵
A
∈
R
m
×
n
A \in R^{m \times n}
A∈Rm×n,则有:
A
I
=
A
=
I
A
AI=A=IA
AI=A=IA
3.2 对角矩阵(diagonal matrix)
矩阵
D
D
D为对角矩阵,则对角线元素为
d
i
d_i
di,非对角线元素为0,记为:
D
=
d
i
a
g
(
d
1
,
d
2
,
⋯
,
d
n
)
=
[
d
1
0
⋯
0
0
d
2
⋯
0
⋮
⋮
⋱
⋮
0
0
⋯
d
n
]
D=diag(d_1,d_2,\cdots,d_n)=\left[ \begin{array}{cc} d_1\quad 0\quad \cdots\quad 0\\ 0\quad d_2 \quad \cdots \quad 0\\ \vdots\quad \vdots \quad \ddots \quad \vdots\\ 0\quad 0 \quad \cdots \quad d_n \end{array}\right]
D=diag(d1,d2,⋯,dn)=
d10⋯00d2⋯0⋮⋮⋱⋮00⋯dn
3.3 对称矩阵(Symmetric Matrices)
若 A = A T A=A^T A=AT,则 A ∈ R n × m A\in R^{n\times m} A∈Rn×m为对称矩阵;若 A = − A T A=-A^T A=−AT,则为反对称矩阵。若 A A A为对称矩阵,则 A + A T , A − A T A+A^T,A-A^T A+AT,A−AT也为对称矩阵。对称矩阵关于对角线轴对称对,角阵是对称矩阵。对称矩阵的特性是特征值为i实数,特征向量两两正交。
3.4 迹(Trace)
矩阵对角线元素的和,称为矩阵的迹,记为:
t
r
A
=
∑
i
i
i
=
n
A
i
i
trA= \sum_{ii}^{i=n}A_{ii}
trA=∑iii=nAii。矩阵的迹有以下特性:
t
r
A
=
t
r
A
T
t
r
(
A
+
B
)
=
t
r
A
+
t
r
B
t
r
(
t
A
)
=
t
⋅
t
r
(
A
)
t
r
(
A
B
)
=
t
r
(
B
A
)
t
r
(
A
B
C
)
=
t
r
(
B
A
C
)
=
t
r
(
C
B
A
)
\begin{aligned} &trA=trA^T\\ &tr(A+B)=trA+trB\\ &tr(tA)=t\cdot tr(A)\\ &tr(AB)=tr(BA)\\ &tr(ABC)=tr(BAC)=tr(CBA) \end{aligned}
trA=trATtr(A+B)=trA+trBtr(tA)=t⋅tr(A)tr(AB)=tr(BA)tr(ABC)=tr(BAC)=tr(CBA)
3.5 范数(Norms)
向量的范数是度量向量的长度的方式,最常见的是欧式距离(第二范数),记为:
∥
x
∥
2
=
x
T
x
=
∑
i
=
1
n
x
i
2
\|x\|_2=x^Tx=\sqrt{\sum_{i=1}^n{x_i^2}}
∥x∥2=xTx=i=1∑nxi2
常见的范数还有:
∥
x
∥
1
=
∑
i
=
1
n
∣
x
i
∣
∥
x
∥
∞
=
∑
i
=
1
n
max
x
i
∥
x
∥
p
=
(
∑
i
=
1
n
∣
x
i
∣
p
)
1
/
p
\begin{aligned} &\|x\|_1=\sum_{i=1}^n{|x_i|}\\ &\|x\|_{\infty}=\sum_{i=1}^n{\max{x_i}}\\ &\|x\|_{p}=\left( \sum_{i=1}^n{|x_i|^p}\right)^{1/p} \end{aligned}
∥x∥1=i=1∑n∣xi∣∥x∥∞=i=1∑nmaxxi∥x∥p=(i=1∑n∣xi∣p)1/p
3.6 矩阵转置(Transpose)
转置矩阵为原矩阵的行列互换,给定原矩阵
A
∈
R
m
×
n
A\in R^{m \times n}
A∈Rm×n,则A的转置矩阵记为:
A
T
∈
R
n
×
m
,
(
A
i
j
T
=
A
j
i
)
A^T\in R^{n \times m},(A^T_{ij}=A_{ji})
AT∈Rn×m,(AijT=Aji)。转置矩阵与原矩阵有如下关系:
(
A
T
)
T
=
T
(
A
B
)
T
=
B
T
A
T
(
A
+
B
)
T
=
A
T
+
B
T
\begin{aligned} &(A^T)^T=T\\ &(AB)^T=B^TA^T\\ &(A+B)^T=A^T+B^T \end{aligned}
(AT)T=T(AB)T=BTAT(A+B)T=AT+BT
3.7 矩阵的逆(The Inverse of a Square Matrix)
矩阵
A
=
R
n
×
n
A=R^{n \times n}
A=Rn×n的逆矩阵记为
A
−
1
A^{-1}
A−1,且满足
A
−
1
A
=
I
A^{-1}A=I
A−1A=I,称
A
A
A是可逆矩阵(奇异矩阵),A矩阵的逆矩阵为
A
−
1
A^{-1}
A−1。非方阵没有上述定义的逆矩阵,同时一些方阵的逆也不存在,称这些矩阵不可逆矩阵(非奇异矩阵)。逆矩阵有以下特性:
(
A
−
1
)
−
1
=
A
(
A
B
)
−
1
=
B
−
1
A
−
1
(
A
T
)
−
1
=
(
A
−
1
)
T
\begin{aligned} &(A^{-1})^{-1}=A\\ &(AB)^{-1}=B^{-1}A^{-1}\\ &(A^T)^{-1}=(A^{-1})^T \end{aligned}
(A−1)−1=A(AB)−1=B−1A−1(AT)−1=(A−1)T
3.8 正交矩阵(Orthogonal Matrices)
如果
x
y
T
=
0
xy^T=0
xyT=0,则称两个向量正交,在二维坐标系中直观来看为两个向量垂直。已知矩阵
U
U
U正交,则矩阵中任意两个向量正交,正交矩阵有以下特性:
U
U
T
=
I
=
U
T
U
U
−
1
=
U
T
∥
U
x
∥
2
=
∥
x
∥
2
\begin{aligned} &UU^T=I=U^TU\\ &U^{-1}=U^T\\ &\|Ux\|_2=\|x\|_2 \end{aligned}
UUT=I=UTUU−1=UT∥Ux∥2=∥x∥2
3.9 行列式(Determinant)
若方阵
A
∈
R
m
×
n
A\in\mathbb{R^{m\times n}}
A∈Rm×n的行列式是函数
d
e
t
A
:
x
→
R
detA:x\rightarrow \mathbb{R}
detA:x→R,记为
∣
A
∣
|A|
∣A∣或者det
A
A
A,方阵的行列式是一个数。计算方式如下所示,其中$A_{ij}\in \mathbb{R}^{(m-1)\times(n-1)}
为
为
为a_{ij}$的代数余子式。
∣
A
∣
=
∑
i
=
1
n
(
−
1
)
i
+
j
a
i
j
∣
A
i
j
∣
(
f
o
r
a
n
y
j
∈
1
,
2
,
⋯
n
)
=
∑
j
=
1
n
(
−
1
)
i
+
j
a
i
j
∣
A
i
j
∣
(
f
o
r
a
n
y
i
∈
1
,
2
,
⋯
n
)
\begin{aligned} |A| &=\sum_{i=1}^{n}(-1)^{i+j}a_{ij}|A_{ij}|\quad (for\quad any\quad j\in1,2,\cdots n)\\ &=\sum_{j=1}^{n}(-1)^{i+j}a_{ij}|A_{ij}|\quad (for\quad any\quad i\in1,2,\cdots n) \end{aligned}
∣A∣=i=1∑n(−1)i+jaij∣Aij∣(foranyj∈1,2,⋯n)=j=1∑n(−1)i+jaij∣Aij∣(foranyi∈1,2,⋯n)
常见的三阶方阵的行列式较为简单,如下所示:
∣
[
a
11
]
∣
=
a
11
∣
[
a
11
a
12
a
21
a
22
]
∣
=
a
11
a
22
−
a
12
a
21
∣
[
a
11
a
12
a
13
a
21
a
22
a
23
a
31
a
32
a
33
]
∣
=
a
11
a
22
a
33
+
a
12
a
23
a
31
+
a
13
a
21
a
32
−
a
11
a
23
a
32
+
a
12
a
21
a
33
−
a
13
a
22
a
31
\begin{aligned} & \left| \left[ \begin{array}{cc} a_{11}\end{array}\right] \right|=a_{11}\\ & \left| \left[ \begin{array}{cc} a_{11} \quad a_{12}\\ a_{21} \quad a_{22}\end{array}\right]\right|=a_{11}a_{22}-a_{12}a_{21}\\ & \left| \left[ \begin{array}{cc} a_{11} \quad a_{12} \quad a_{13}\\ a_{21} \quad a_{22} \quad a_{23}\\ a_{31} \quad a_{32} \quad a_{33}\end{array}\right] \right|={a_{11}a_{22}a_{33}+a_{12}a_{23}a_{31}+a_{13}a_{21}a_{32}-a_{11}a_{23}a_{32}+a_{12}a_{21}a_{33}-a_{13}a_{22}a_{31}} \end{aligned}
[a11]
=a11
[a11a12a21a22]
=a11a22−a12a21
a11a12a13a21a22a23a31a32a33
=a11a22a33+a12a23a31+a13a21a32−a11a23a32+a12a21a33−a13a22a31
行列式的出现是为了解线性方程组,它可以简化方程组的求解。行列式的物理意义:矩阵代表的是线性变换,矩阵的行列式是变换时单位面积/单位体积缩放或者拉升的比例。如果一个矩阵的行列式大于1,那么变换后就会放大面积体积;反之就会缩小面积体积;如果行列式等于0,意味着矩阵所代表的线性变换可以降维。
3.10 二次型与半正定矩阵
给定一个矩阵$A\in \mathbb{R}^{m \times n}
,以及向量
,以及向量
,以及向量v\in\mathbb{R}{n}$,标量$x{T}Ax$称为二次型,记为:
x
T
A
x
=
∑
i
=
1
n
x
i
(
A
x
)
i
=
∑
i
=
1
n
x
i
(
∑
j
=
1
n
A
i
j
x
j
)
=
∑
i
=
1
n
(
∑
j
=
1
n
A
i
j
x
i
x
j
)
x
T
A
x
=
(
x
T
A
x
)
T
=
x
T
A
T
x
=
x
T
(
1
2
A
+
1
2
A
T
)
x
\begin{aligned} &x^{T}Ax=\sum_{i=1}^{n}x_i(Ax)_i=\sum_{i=1}^{n}x_i(\sum_{j=1}^{n}A_{ij}x_j)=\sum_{i=1}^{n}(\sum_{j=1}^{n}A_{ij}x_ix_j)\\ &x^TAx=(x_TAx)^T=x^TA^Tx=x^{T}(\frac{1}{2}A+\frac{1}{2}A^{T})x \end{aligned}
xTAx=i=1∑nxi(Ax)i=i=1∑nxi(j=1∑nAijxj)=i=1∑n(j=1∑nAijxixj)xTAx=(xTAx)T=xTATx=xT(21A+21AT)x
正定矩阵设有n元实二次型$ f(x_1,x_2,⋯,x_n)=x^TAx $,
- 如果对于任何非零列向量 x x x ,都有 x T A x x^TAx xTAx>0,则称为正定二次型,称对称矩阵 A A A为正定矩阵。
- 如果对于任何非零列向量 x x x,都有 x T A x x^TAx xTAx⩾0,则称为半正定二次型,称 A A A为半正定矩阵。
- 如果对于 任何非零列向量 x x x,都有 x T A x x^TAx xTAx<0,则称为负定二次型,称 A A A为负定矩阵。
- 如果对于任何非零列量 x x x ,都有 x T A x x^TAx xTAx⩽0,则称为半负定二次型,称 A A A为半负定矩阵。
- 其它的实二次型称为不定二次型,其矩阵称为不定矩阵。
3.11 特征值与特征向量(Eigenvalues and Eigenvectors)
已知矩阵 A ∈ R n × n A \in R^{n \times n} A∈Rn×n,满足 A x = λ x Ax=\lambda x Ax=λx,定义 λ ∈ C \lambda \in C λ∈C是矩阵 A A A特征值,向量 x ∈ C n x\in C^{n} x∈Cn是矩阵 A A A的特征向量。特征值与向量的特性:
-
$trA=\sum_{i=1}^n\lambda_i\$
-
d e t A = ∣ A ∣ = ∏ i = 1 n λ i detA=|A|=\prod_{i=1}^n\lambda_i detA=∣A∣=∏i=1nλi
-
A的秩等于非零特征向量的个数
-
对角矩阵 A = d i a g ( d 1 , d 2 , ⋯ , d n ) A=diag(d_1,d_2,\cdots,d_n) A=diag(d1,d2,⋯,dn)的特征值为对角线元素 d 1 , d 2 , ⋯ , d n ) d_1,d_2,\cdots,d_n) d1,d2,⋯,dn)。
3.12 对称矩阵的特征值与特征向量(Eigenvalues and Eigenvectors of Symmetric Matrices)
假设矩阵 A A A为实对称矩阵,则有以下特性:
-
矩阵 A A A的特征值为实数,记为 λ 1 , λ 2 , ⋯ , λ n \lambda_1,\lambda_2,\cdots,\lambda_n λ1,λ2,⋯,λn。
-
特征值 λ i \lambda_i λi对应的特征向量 u i u_i ui,两两正交。
矩阵 A A A的特征向量 u i u_i ui组成矩阵 U = [ u 1 , u 2 , ⋯ , u n ] U=[u_1,u_2,\cdots,u_n] U=[u1,u2,⋯,un]为正交矩阵,对角线为特征值的对角矩阵$\Lambda 则有 则有 则有AU=Udiag(\lambda_1,\lambda_2,\cdots,\lambda_n)=U\Lambda,A=AUTU=UT\Lambda U$。
4. 矩阵计算
4.1 梯度(Gradient)
向量的梯度:
n
×
1
n×1
n×1向量
x
x
x的梯度算子记作
▽
x
f
(
x
)
\triangledown_x{f(x)}
▽xf(x),定义为:
▽
x
f
(
x
)
=
[
∂
f
(
x
)
∂
x
1
∂
f
(
x
)
∂
x
2
⋯
∂
f
(
x
)
∂
x
n
]
\begin{aligned} & \triangledown_x{f(x)}=\left[ \begin{array}{cc} \frac{\partial{f(x)}}{\partial x_{1}}\quad \frac{\partial{f(x)}}{\partial x_{2}}\quad \cdots \quad \frac{\partial{f(x)}}{\partial x_{n}} \end{array}\right] \end{aligned}
▽xf(x)=[∂x1∂f(x)∂x2∂f(x)⋯∂xn∂f(x)]
矩阵的梯度:函数
f
(
A
)
f(A)
f(A)相对
于
m
×
n
于m×n
于m×n是矩阵
A
A
A的梯度为一
m
×
n
m×n
m×n矩阵,简称梯度矩阵,定义为:
▽
A
f
(
A
)
∈
R
m
×
n
=
[
∂
f
(
A
)
∂
A
11
∂
f
(
A
)
∂
A
12
⋯
∂
f
(
A
)
∂
A
1
n
⋮
⋮
⋱
⋮
∂
f
(
A
)
∂
A
m
1
∂
f
(
A
)
∂
A
m
2
⋯
∂
f
(
A
)
∂
A
m
n
]
(
▽
A
f
(
A
)
)
i
j
=
∂
f
(
A
)
∂
A
i
j
\begin{aligned} & \triangledown_Af(A)\in\mathbb R^{m \times n}=\left[ \begin{array}{cc} \frac{\partial{f(A)}}{\partial A_{11}} \frac{\partial{f(A)}}{\partial A_{12}}\quad \cdots \quad \quad \frac{\partial{f(A)}}{\partial A_{1n}} \\ \vdots \quad \quad \quad \vdots \quad \quad \ddots \quad \quad \vdots \\ \frac{\partial{f(A)}}{\partial A_{m1}}\quad \frac{\partial{f(A)}}{\partial A_{m2}}\quad \cdots \quad \frac{\partial{f(A)}}{\partial A_{mn}} \end{array}\right]\\ & (\triangledown_Af(A))_{ij}=\frac{\partial{f(A)}}{\partial A_{ij}} \end{aligned}
▽Af(A)∈Rm×n=
∂A11∂f(A)∂A12∂f(A)⋯∂A1n∂f(A)⋮⋮⋱⋮∂Am1∂f(A)∂Am2∂f(A)⋯∂Amn∂f(A)
(▽Af(A))ij=∂Aij∂f(A)
4.2 Hessian 矩阵
梯度是一阶导数,矩阵函数的二阶偏导数则是用Hessian 矩阵表示,即梯度的梯度,记为:
▽
x
2
f
(
x
)
∈
R
n
×
m
=
[
∂
2
f
(
x
)
∂
2
x
1
∂
2
f
(
x
)
∂
x
1
∂
x
2
⋯
∂
2
f
(
x
)
∂
x
1
∂
x
n
⋮
⋮
⋱
⋮
∂
2
f
(
x
)
∂
x
m
∂
x
1
∂
2
f
(
x
)
∂
x
m
∂
x
2
⋯
∂
2
f
(
x
)
∂
x
m
∂
x
n
]
(
▽
x
2
f
(
x
)
)
i
j
=
∂
2
f
(
x
)
∂
x
j
∂
x
j
\begin{aligned} &\triangledown_x^{2}f(x)\in \mathbb{R}^{n\times m}=\left[ \begin{array}{cc} \frac{\partial^{2}{f(x)}}{\partial^2 x_{1}}\quad \frac{\partial^{2}{f(x)}}{\partial x_{1}\partial{x_2}}\quad \cdots \quad \frac{\partial^{2}{f(x)}}{\partial x_{1}\partial x_n} \\ \vdots \quad \quad \vdots \quad \quad \ddots \quad \quad \vdots \\ \frac{\partial^{2}{f(x)}}{\partial x_{m} \partial x_{1}}\quad \frac{\partial^{2}{f(x)}}{\partial x_{m}\partial x_{2}}\quad \cdots \quad \frac{\partial^{2}{f(x)}}{\partial x_{m}\partial x_{n}} \end{array}\right]\\ &(\triangledown_x^{2}f(x))_{ij}=\frac{\partial^{2}{f(x)}}{\partial x_{j}\partial x_j} \end{aligned}
▽x2f(x)∈Rn×m=
∂2x1∂2f(x)∂x1∂x2∂2f(x)⋯∂x1∂xn∂2f(x)⋮⋮⋱⋮∂xm∂x1∂2f(x)∂xm∂x2∂2f(x)⋯∂xm∂xn∂2f(x)
(▽x2f(x))ij=∂xj∂xj∂2f(x)
Hessian 矩阵可以通过两个步骤计算得出:
- 求实值函数 f ( x ) f(x) f(x)关于向量变元 x x x的偏导数,得到实值函数的梯度 ∂ f ( x ) ∂ x \frac{\partial{f(x)}}{\partial x} ∂x∂f(x)。
- 再求梯度 ∂ f ( x ) ∂ x \frac{\partial{f(x)}}{\partial x} ∂x∂f(x)相对于 1 × n 1×n 1×n行向量 x T x^T xT的偏导数,得到梯度的梯度即 Hessian 矩阵。
5.常见应用
5.1 数据表示
AI已经深入到各个领域,包括图像视觉、自然语言等,大火的ChatGPT是大模型时代的开始,训练如此大的模型需要海量数据,数据是以那种形式进入到模型中训练呢?计算机将图片、文字、声音等信息转换为矩阵表示。以下是pytorch读取数据集的代码,在pytorch中矩阵或是向量以张量形式存储。张量通常被认为是一个广义矩阵。也就是说,它可以是1-D矩阵(一个向量实际上就是一个张量),3-D矩阵(类似于一个数字的立方),甚至是0-D矩阵(单个数字),或者一个更难形象化的高维结构。
# 设置batch_size
batch_size = 32
train_set = DatasetFolder("food-11/training/labeled", loader=lambda x: Image.open(x), extensions="jpg", transform=train_tfm)
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=False)
for batch in train_loader:
imgs, labels = batch
print(imgs.size())
print(labels)
break
# output 输出显示,一个batch的图片与标签都以矩阵形式存储
# torch.Size([32, 3, 128, 128])
# tensor([ 6, 5, 3, 4, 8, 6, 6, 2, 0, 8, 8, 7, 5, 0, 9, 9, 10, 6,
# 8, 3, 5, 3, 8, 4, 7, 4, 1, 1, 9, 9, 4, 6])
5.2 线性回归(Linear Regression)
线性回归是利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法
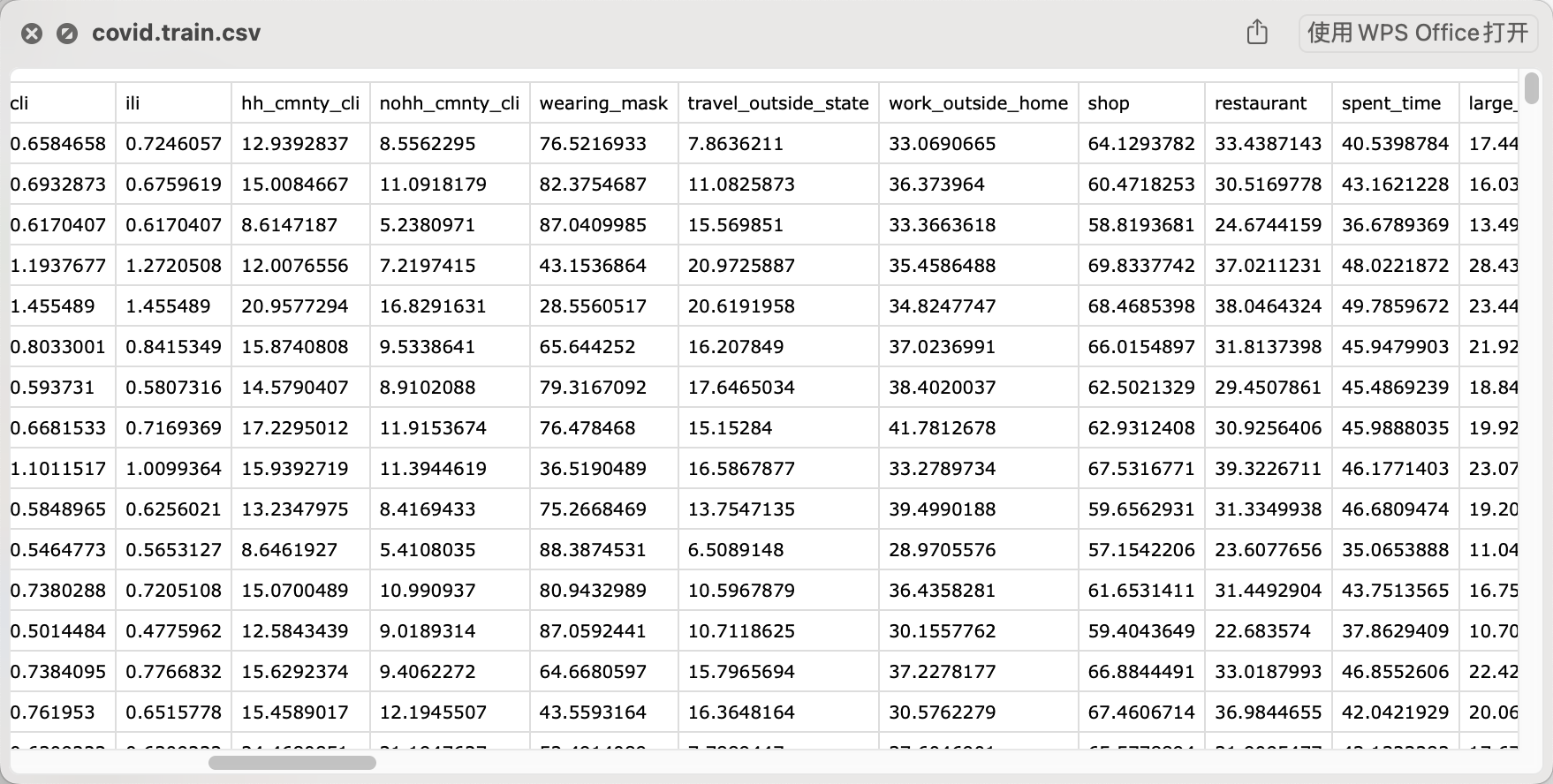
线性回归通常在机器学习中用于预测较简单的回归问题的数值,找到一组系数,用这些系数与每个输入变量相乘并将结果相加,得出最佳的输出变量预测。以预测新冠病毒问题为例,下面的图片训练数据,数据集是以二维数据表的形式存储,读取、训练以及预测以矩阵形式进行。
5.3 独热编码(One-Hot Encoding)
如果用独热编码表示性别,例如:
性别:["男","女"]
男 => 10
女 => 01
使用独热编码(One-Hot Encoding),将离散特征的取值扩展到了欧式空间,离散特征的某个取值就对应欧式空间的某个点。将离散型特征使用独热编码(One-Hot Encoding),会让特征之间的距离计算更加合理。
有时机器学习中要用到分类数据。可能是用于解决分类问题的类别标签,也可能是分类输入变量。对分类变量进行编码以使它们更易于使用并通过某些技术进行学习是很常见的。one-hot 编码可以理解为:创建一个表格,用列表示每个类别,用行表示数据集中每个例子。在列中为给定行的分类值添加一个检查或「1」值,并将「0」值添加到所有其他列。
5.4 主成分分析(Principal Component Analysis )
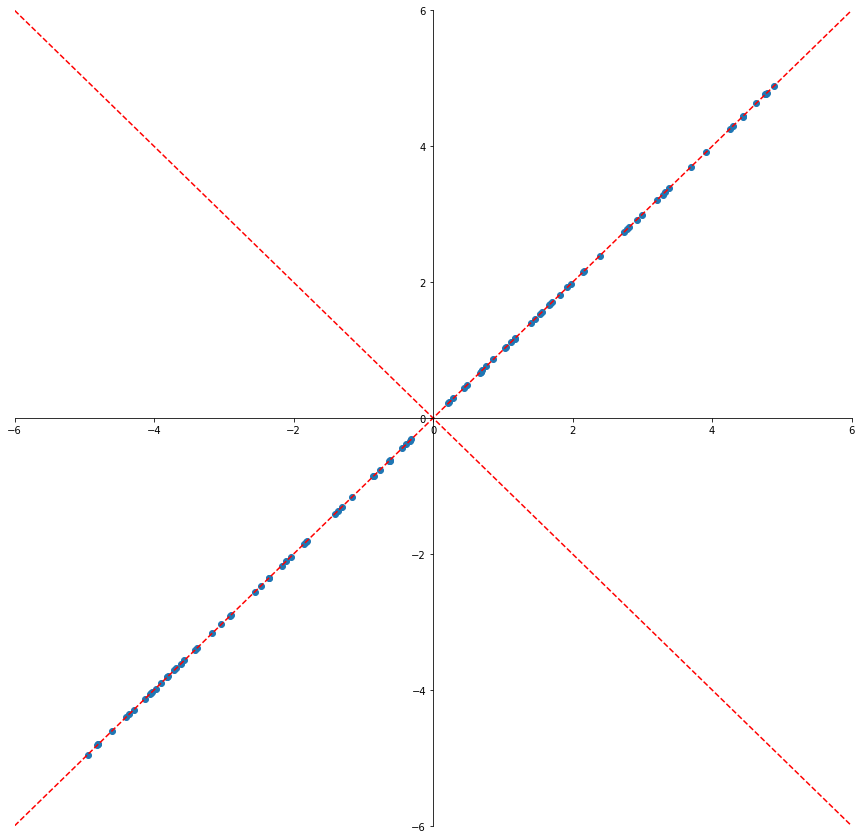
PCA顾名思义是将数据中主要的成分提出来,忽略数据中的冗余信息。在传统机器学习中,训练数据往往有大量的特征,仔细分析数据集,手动特征选取可以一定程度提升训练结果。PCA 方法的核心是线性代数的矩阵分解方法,可能会用到特征分解。以下是一个简单的降维实例,将蓝色的二维点集降维为一维的坐标系上的点。
5.5 奇异值分解(Singular-Value Decomposition)
降维方法是奇异值分解方法,简称 SVD,正如该方法名称所示,它是源自线性代数领域的矩阵分解方法。该方法在线性代数中有广泛的用途,可直接应用于特征选择、可视化、降噪等方面。

















 943
943

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









