






Pytorch框架-猫狗分类
数据集准备

1.导入资源包
from sched import scheduler
import torch.optim as optim
import torch
import torch.nn as nn
import torch.utils.data
import torchvision.transforms as transforms
import torchvision.datasets as datasets
from torch.utils.data import DataLoader
import torch.optim.lr_scheduler as lr_scheduler
import os
from torchvision import models
2.定义数据预处理
# 定义数据预处理
transform = {
'train': transforms.Compose([
transforms.RandomResizedCrop(size=256, scale=(0.8, 1.0)),
transforms.RandomRotation(degrees=15),
transforms.RandomHorizontalFlip(),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(size=256),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
])
}
3.读取数据
# 读取数据
dataset = './dataset'
train_directory = os.path.join(dataset, 'train')
valid_directory = os.path.join(dataset, 'val')
batch_size = 32
num_classes = 2 # 修改为您的分类数
data = {
'train': datasets.ImageFolder(root=train_directory, transform=transform['train']),
'val': datasets.ImageFolder(root=valid_directory, transform=transform['val'])
}
train_loader = DataLoader(data['train'], batch_size=batch_size, shuffle=True, num_workers=8)
test_loader = DataLoader(data['val'], batch_size=batch_size, shuffle=False, num_workers=8)
4.定义自定义的 VGG-19 模型
from torchvision.models import vgg19
定义自定义的 VGG-19 模型
class CustomVGG19(nn.Module):
def __init__(self):
super(CustomVGG19, self).__init__()
self.vgg19_model = vgg19(pretrained=True)
for param in self.vgg19_model.features.parameters():
param.requires_grad = False
num_features = self.vgg19_model.classifier[6].in_features
self.vgg19_model.classifier[6] = nn.Sequential(
nn.Linear(num_features, 4096),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(4096, 2)
)
def forward(self, x):
return self.vgg19_model(x)
创建 CustomVGG19 模型实例
vgg19_model = CustomVGG19()
定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(vgg19_model.parameters(), lr=0.001, weight_decay=1e-4)
首先,检查是否有可用的 GPU
```python
if torch.cuda.is_available():
定义 GPU 设备
device = torch.device('cuda')
print("CUDA is available! Using GPU for training.")
else:
如果没有可用的 GPU,则使用 CPU
device = torch.device('cpu')
print("CUDA is not available. Using CPU for training.")
将模型移动到 GPU
vgg19_model.to(device)
如果你有优化器和其他需要移动到 GPU 的参数,例如梯度
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(vgg19_model.parameters(), lr=0.001, weight_decay=1e-4)
5.定义了一个训练函数
def train(model, device, train_loader, optimizer, epoch):
model.train()
running_loss = 0.0
correct = 0
total = 0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = torch.max(output.data, 1)
total += target.size(0)
correct += (predicted == target).sum().item()
if batch_idx % 10 == 0: # 每10个批次打印一次
print(f'Epoch {epoch}, Batch {batch_idx}, Loss: {loss.item()}')
print(f'Epoch {epoch}, Loss: {running_loss / len(train_loader)}, Accuracy: {100 * correct / total}%')
6.定义验证过程
定义验证过程
def val(model, device, test_loader, criterion):
model.eval()
running_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
loss = criterion(output, target)
running_loss += loss.item()
_, predicted = torch.max(output.data, 1)
total += target.size(0)
correct += (predicted == target).sum().item()
print(f'Validation, Loss: {running_loss / len(test_loader)}, Accuracy: {100 * correct / total}%')
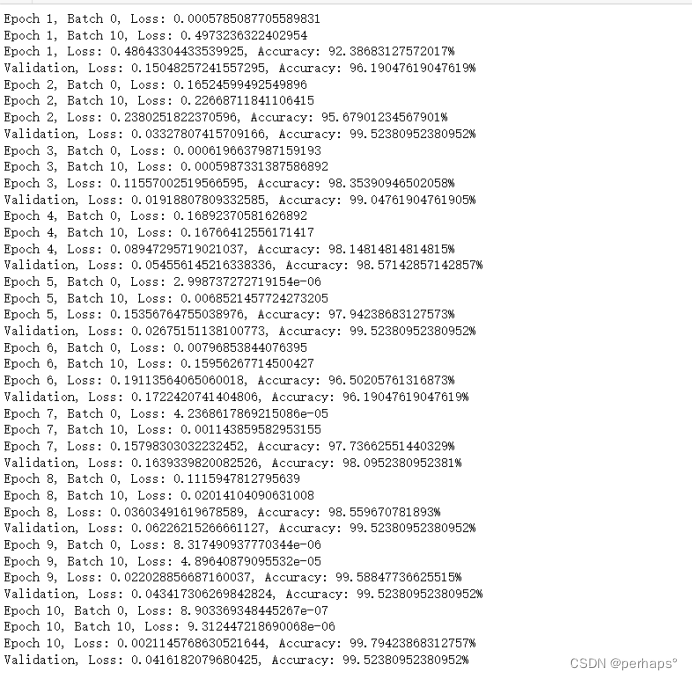
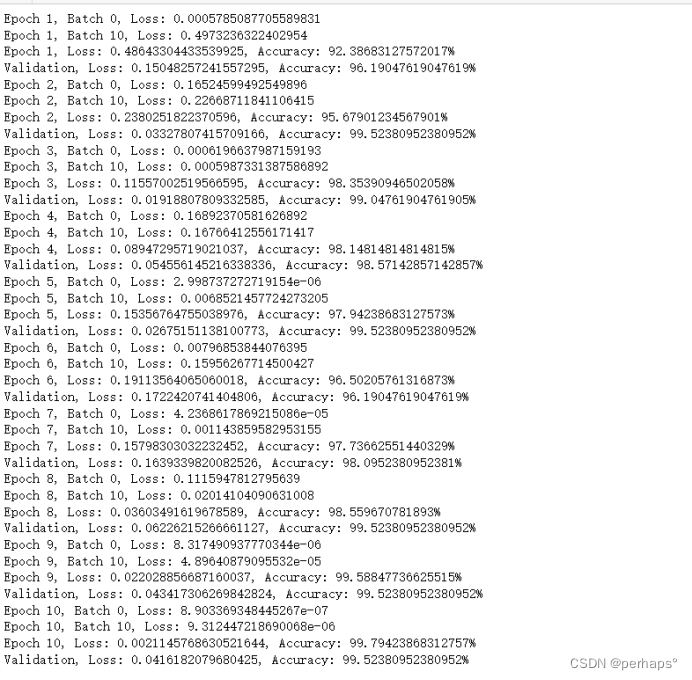
7.用于训练模型并应用学习率调整策略的循环
# 定义学习率调整策略
scheduler = lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)
# 训练模型
EPOCHS = 10
for epoch in range(1, EPOCHS + 1):
train(vgg19_model, device, train_loader, optimizer, epoch)
val(vgg19_model, device, test_loader, criterion)
scheduler.step() # 调整学习率
8.保存模型的状态字典
# 保存模型的状态字典
torch.save(vgg19_model.state_dict(), 'vgg19_model_weights.pth'
9.预测
# 定义数据预处理
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
# 定义类别
classes = ['cat', 'dog'] # 替换为您的实际类别名称
# 检查是否有可用的 GPU
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
注:这些步骤是图像识别任务中的常见操作,用于准备数据和选择计算设备。在实际应用中,您可能需要根据您的具体任务和数据集调整这些参数。
9.3.定义自定义的 VGG-19 模型
# 定义自定义的 VGG-19 模型
class CustomVGG19(nn.Module):
def __init__(self):
super(CustomVGG19, self).__init__()
self.vgg19_model = models.vgg19(pretrained=True)
for param in self.vgg19_model.features.parameters():
param.requires_grad = False
num_features = self.vgg19_model.classifier[6].in_features
self.vgg19_model.classifier[6] = nn.Sequential(
nn.Linear(num_features, 4096),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(4096, len(classes))
)
def forward(self, x):
return self.vgg19_model(x)
注:这个自定义的VGG-19模型是用于二分类任务的,它保留了VGG-19的卷积层和池化层不变,只修改了最后的全连接层以适应新的类别数。在实际应用中,您可能需要根据您的具体任务调整最后的全连接层,以匹配您的类别数。
9.4.创建 CustomVGG19 模型实例
# 创建 CustomVGG19 模型实例
model = CustomVGG19()
# 加载权重
model.load_state_dict(torch.load("vgg19_model_weights.pth"))
model.to(DEVICE)
model.eval()
注:用于创建自定义的VGG-19模型实例,加载模型的权重,并将模型移动到指定的设备上。
9.5.定义预测函数
# 定义预测函数
def predict_image(image_path):
# 打开图片
image = Image.open(image_path)
# 应用预处理
image = transform(image).unsqueeze(0) # 添加batch维度
# 转换为Variable(如果模型需要)
image = Variable(image).to(DEVICE)
# 获取模型预测
output = model(image)
_, prediction = torch.max(output.data, 1)
return classes[prediction.item()]
# 上传的图片路径
uploaded_image_path = '1111.jpg'
# 进行预测
predicted_class = predict_image(uploaded_image_path)
print(f"The uploaded image is predicted as: {predicted_class}")
注:这个预测函数是使用模型进行图像分类的基本框架,我们可以根据需要调整打印频率或其他参数。在实际应用中,您需要确保在调用这个函数之前已经定义了模型、数据预处理和类别列表。
运行结果:
10.定义了一个可视化函数
import matplotlib.pyplot as plt
# 定义可视化函数
def visualize_prediction(image_path, predicted_class):
# 打开图片
image = Image.open(image_path)
# 显示图片
plt.imshow(image)
plt.axis('off')
plt.title(f'Predicted: {predicted_class}')
plt.show()
# 上传的图片路径
uploaded_image_path = '44.jpg'
# 进行预测
predicted_class = predict_image(uploaded_image_path)
# 可视化预测结果
visualize_prediction(uploaded_image_path, predicted_class)
print(f"The uploaded image is predicted as: {predicted_class}")
注:当我们运行这个脚本时,它会打开一个Matplotlib窗口,显示上传的图片,并在图片上添加一个标题显示预测的类别。同时,脚本会打印出预测结果。这个脚本是用于可视化图像分类结果的基本框架,您可以根据需要调整打印频率或其他参数。在实际应用中,您需要确保在调用这个函数之前已经定义了模型、数据预处理和类别列表。
运行结果:
















 1513
1513











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









