






yolov11快速入门->Quickstart - Ultralytics YOLO Docs
1.进入阿里云阿里云-计算,为了无法计算的价值,选择产品-人工智能平台PAI
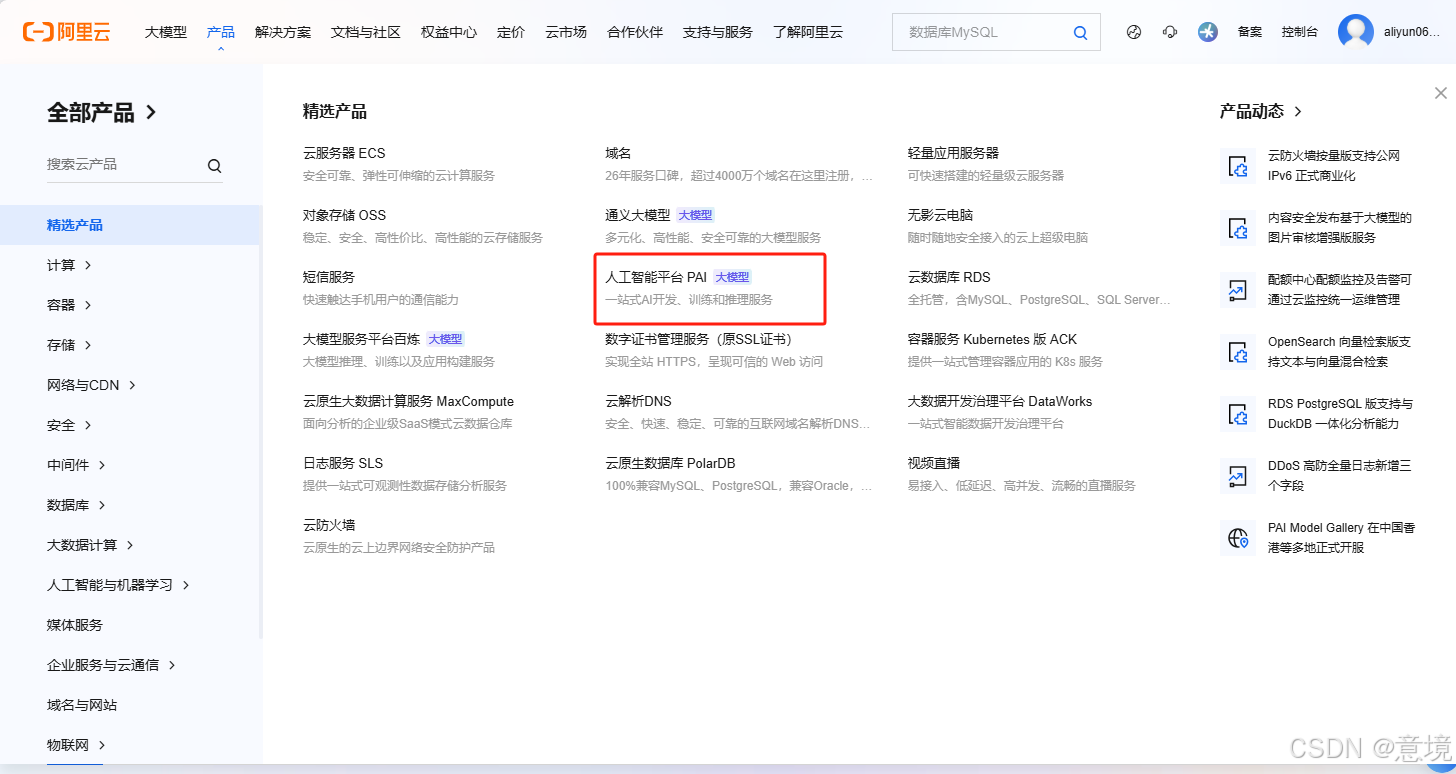 2.选择交互式建模PAI-DSW,在这里可以修改代码。而模型训练PAI-DLC则是通过命令行获取已经写好的代码进行运行,并且支持分布式训练。点击立即试用(我这里已经试用过了)
2.选择交互式建模PAI-DSW,在这里可以修改代码。而模型训练PAI-DLC则是通过命令行获取已经写好的代码进行运行,并且支持分布式训练。点击立即试用(我这里已经试用过了)
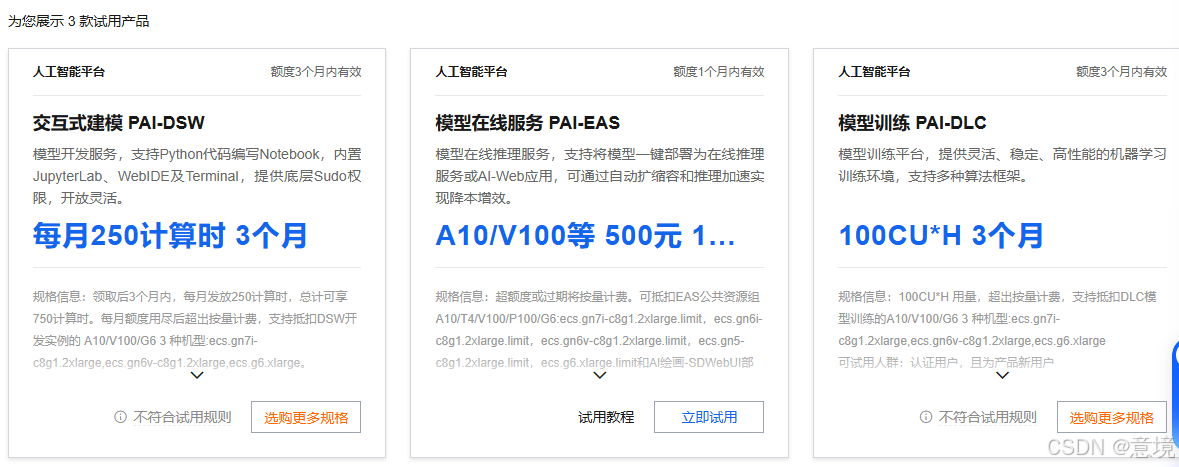
3.配置资源类型和镜像(后面也可以随意修改,并且用户文件不变)。使用GPU类型的资源,配置如下。
4.进入你的开发机,开始编写代码。我选择的资源配置中已经自动配置好了yolo所需要的环境,不需要再手动配置环境,直接编写代码:
点击上传按钮,上传数据集。在datasets文件夹下创建一个yolo配置文件cars.yaml
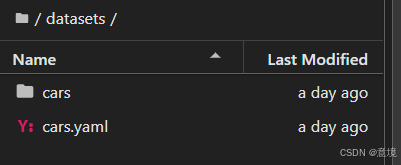
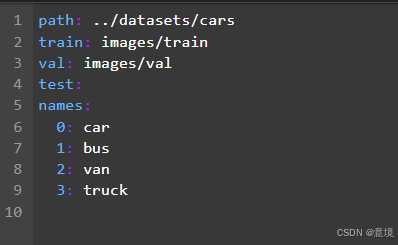
内容如下,我这里只做了基本配置,指明数据集位置以及对应标号的分类信息。其它的不写就是默认配置,yaml配置详见yolo官网Quickstart - Ultralytics YOLO Docs
然后就可以开始训练。
from ultralytics import YOLO
from ultralytics import settings
def main():
model = YOLO("yolo11n.yaml")
model.train(data = "/mnt/workspace/datasets/cars.yaml",epochs=50,cache=True,plots=True)
if __name__ == "__main__":
print("start...")
main()
print("--finish--")如果报错datasets路径错误,可以修改settings的数据集根路径.
from ultralytics import settings
print(settings)
settings.update({"key":"value"})
print(settings)训练好后右键点击模型文件,点击下载,就可以下载到本地了。

















 1240
1240

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









