









声明:非广告,为用户体验文章
目录
引言
本文详细讲解如何在蓝耘智算平台上搭建多机多卡分布式训练环境,以DeepSeek模型为例,覆盖网络配置、通信优化、并行策略选择、资源管理与监控等核心环节,助力开发者高效实现大模型训练任务
一、蓝耘平台与DeepSeek模型简介
1.1 蓝耘智算平台核心优势
蓝耘智算平台基于Kubernetes构建,提供高性能GPU集群(如RTX 4090、A100等),支持动态资源调配与分布式计算框架(如PyTorch、DeepSpeed),并具备自动化调度和故障恢复能力,可显著提升训练效率。
其关键特性包括:
-
灵活资源配置:按需选择GPU数量、内存大小,支持按量付费模式
-
分布式训练优化:内置容器化编排工具,简化多节点通信配置
-
实时监控界面:提供GPU利用率、内存消耗等指标的图形化展示

1.2 DeepSeek模型特点
DeepSeek是由深度求索(DeepSeek Cognition)研发的AI模型,支持7B至671B参数规模,擅长数学推理、代码生成及自然语言处理任务。
其优势包括:
-
全量数据混合训练:融合文本与代码数据,增强多任务泛化能力
-
高效推理性能:通过强化学习优化,训练成本仅为同类模型的1/20
-
开源与商用兼容:提供MIT协议的开源版本及企业级API服务

二、多机多卡环境搭建与网络配置
2.1 硬件与资源准备
-
注册与资源选择
-
注册蓝耘账号并完成实名认证,获取API密钥
注册完成后,系统会发送一封验证邮件到您填写的邮箱,点击邮件中的验证链接,完成账号激活。完成账号注册并登录,新用户可享受免费算力配额,适合初期测试。
👉 立即注册体验:蓝耘智算平台
-
在“应用市场”中选择DeepSeek-R1或DeepSeek-V3模型,推荐使用RTX 4090(24GB显存)或更高规格GPU,按需配置节点数量
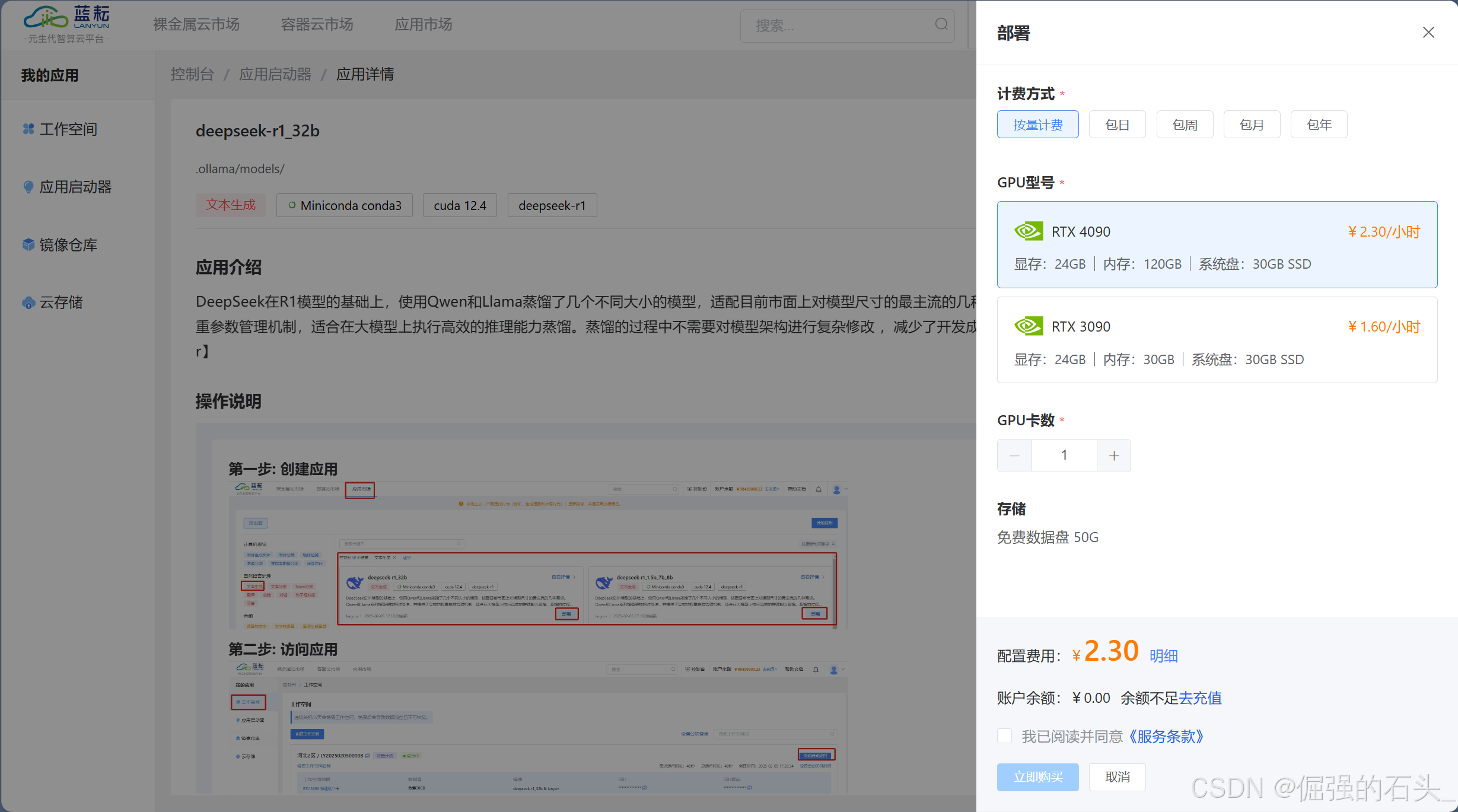
-
-
创建分布式集群
-
进入【个人中心】→【分布式集群】,创建深度学习集群,设置主节点(Master)并添加从节点(Worker)
-
确保所有节点处于同一局域网,通过
ifconfig验证IP互通,并在/etc/hosts中配置主机名映射
-
2.2 网络通信配置
-
环境变量设置
-
主节点配置
MASTER_ADDR与MASTER_PORT,从节点通过SSH公钥连接主节点:export MASTER_ADDR=192.168.1.1 export MASTER_PORT=29500 export WORLD_SIZE=8 # 总GPU数(2节点×4卡):cite[2]:cite[9] -
配置NCCL网络接口,避免通信阻塞:
export NCCL_SOCKET_IFNAME=eth0 export GLOO_IFACE=eth0
-
-
SSH免密登录
-
在主节点生成SSH密钥并分发至从节点,实现节点间无密码访问:
ssh-keygen -t rsa ssh-copy-id user@worker_ip
-
三、分布式训练策略选择与实现
3.1 数据并行 vs 模型并行
| 策略 | 适用场景 | 实现方式 |
|---|---|---|
| 数据并行 | 模型参数量适中,单卡可加载 | 使用DeepSpeed或DistributedDataParallel,将数据分片至各GPU,同步梯度 |
| 模型并行 | 超大模型(如DeepSeek-67B) | 通过流水线并行(Pipeline Parallelism)或张量切分(Tensor Slicing)分割模型 |
推荐方案:针对DeepSeek-7B/33B等中等规模模型,优先采用数据并行;对于DeepSeek-67B,结合模型并行与ZeRO优化(Zero Redundancy Optimizer)减少显存占用
3.2 DeepSeek集成与配置
DeepSeek 是一款高效的深度学习优化库,能够显著提升分布式训练的效率。
在蓝耘智算平台上集成 DeepSeek 并进行配置的步骤如下:
首先,创建 DeepSeek 配置文件,例如ds_config.json,内容如下:
{
"train_batch_size": 1024,
"gradient_accumulation_steps": 4,
"fp16": {"enabled": true},
"zero_optimization": {
"stage": 2,
"contiguous_gradients": true,
"overlap_comm": true
}
}其中,train_batch_size表示训练时的批大小,gradient_accumulation_steps是梯度累积步数,fp16表示是否启用混合精度训练,zero_optimization则配置了 ZeRO 优化的相关参数。
然后,在启动训练脚本时,使用 DeepSeek 进行包装。例如:
deepspeed --num_gpus=4 --master_addr=192.168.1.1 train.py对于多节点训练,还需要指定--node_rank参数,例如:
deepspeed --num_gpus=4 --master_addr=192.168.1.1 --node_rank=1 train.py四、训练流程与代码适配
4.1 数据预处理与加载
在进行分布式训练之前,需要对数据进行预处理和加载。
以 PyTorch 为例,数据预处理和加载的代码如下:
from torch.utils.data import DataLoader, DistributedSampler
# 假设已经定义了数据集dataset
sampler = DistributedSampler(dataset)
dataloader = DataLoader(dataset, batch_size=64, sampler=sampler)其中,DistributedSampler用于在分布式环境下对数据进行分片,确保每个 GPU 都能处理不同的数据子集。
4.2 模型初始化与训练循环
在分布式训练中,模型的初始化和训练循环也需要进行相应的适配。
以下是 PyTorch 中的示例代码:
import torch
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
# 初始化分布式环境
dist.init_process_group(backend='nccl')
# 获取当前进程的GPU编号
local_rank = torch.distributed.get_rank()
device = torch.device(f'cuda:{local_rank}')
# 初始化模型
model = DeepSeekModel().to(device)
model = DDP(model, device_ids=[local_rank])
# 定义损失函数和优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 训练循环
for epoch in range(num_epochs):
for batch in dataloader:
inputs, labels = batch[0].to(device), batch[1].to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()五、资源管理与监控
5.1 资源动态调配
-
弹性扩缩容:根据训练任务负载,通过蓝耘平台控制台动态增减GPU节点
-
成本控制:启用按量付费模式,结合训练周期预估预算
5.2 监控与调优
-
平台内置工具
-
实时查看GPU利用率、显存占用及网络吞吐量
-
分析日志定位瓶颈(如通信延迟或数据加载阻塞)
-
-
自定义监控脚本
-
使用
nvidia-smi与gpustat定时采集硬件指标:watch -n 1 "nvidia-smi --query-gpu=utilization.gpu --format=csv"
-
六、常见问题与解决方案
-
节点通信失败
-
排查步骤:验证防火墙设置、检查NCCL环境变量、重试SSH连接
-
案例:若出现
NCCL timeout错误,增加NCCL_IB_TIMEOUT=1800
-
-
显存溢出(OOM)
-
优化方法:减小
batch_size、启用ZeRO-3阶段优化或激活检查点(Activation Checkpointing)
-
结语
通过蓝耘智算平台的多机多卡分布式训练能力,开发者可高效部署DeepSeek等大模型,结合数据并行与模型并行策略,实现资源利用率最大化。未来,随着蓝耘平台对新型硬件(如量子计算)的支持,分布式训练效率将进一步提升
声明:本文部分配置示例参考了CSDN技术社区及蓝耘官方文档,实际部署时请根据硬件环境调整参数
🚀 平台直达链接:蓝耘智算平台
💡 提示:新用户可领取 20 元代金券,体验高性能 GPU 算力!


















 1620
1620

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











