






前言
随着 DeepSeek AI 大模型的崛起,近期私有化部署逐渐成为行业趋势。常见的部署方式之一是使用 Ollama,这对于个人用户和本地开发环境而言,具有较好的兼容性,尤其是支持各种 GPU 硬件和大模型的兼容性,且无需复杂的配置就能够启动。然而,相比于专业的推理引擎,如 SGLang、vLLM,Ollama 在性能上存在一定差距。
今天,将介绍如何结合云原生K8s、SGLang、LeaderWorkerSet 和 Volcano 等技术栈,来高效部署分布式 DeepSeek-r1 满血版推理集群。通过这一架构,可以充分利用云原生技术的优势,确保模型的高性能推理以及集群的灵活扩展性。
选型SGLang推理引擎的理由:

图1 来自deepseek-ai/DeepSeek-V3
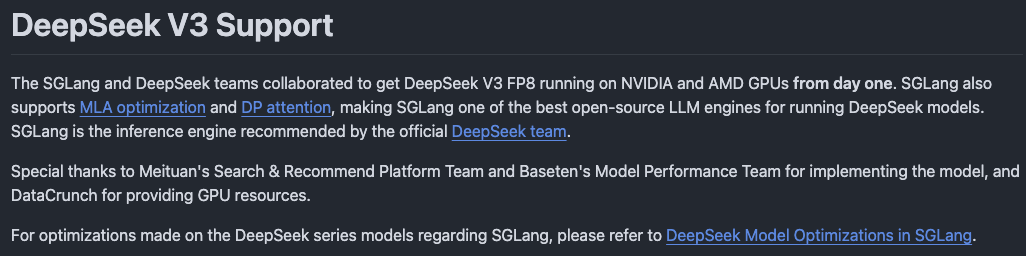
图2 来自deepseek-ai/DeepSeek-V3 Support
环境准备
1. 模型下载
本次阿程部署的是企业级满血版的Deepseek-R1 671B。
方式一:通过
HuggingFace下载
仓库地址:https://huggingface.co/deepseek-ai/DeepSeek-R1
方式二:通过
ModelScope下载 (阿程通过此方式下载)
仓库地址:https://modelscope.cn/models/deepseek-ai/DeepSeek-R1/files
1、安装ModelScope pip3 install modelscope 2、下载完整模型repo mkdir /file_CPU_01/modelServing/DeepSeek-R1 -p nohup modelscope download --model deepseek-ai/DeepSeek-R1 --local_dir /file_CPU_01/modelServing/DeepSeek-R1/ &
在Linux环境下载后的完整DeepSeek-R1模型大小为638G

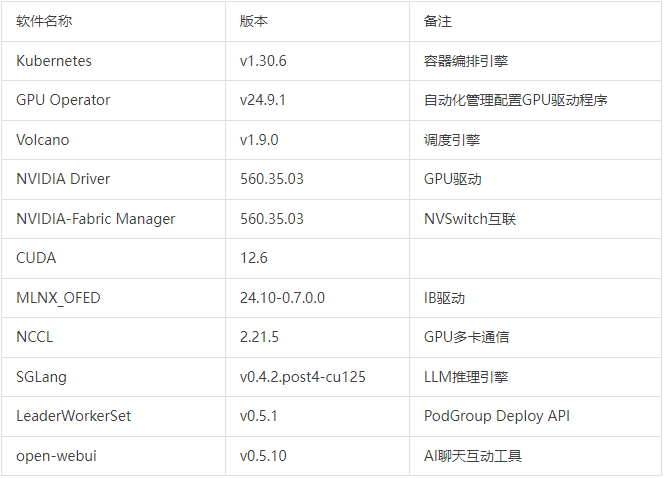
2. 软硬件环境介绍
硬件配置

软件平台
正式部署
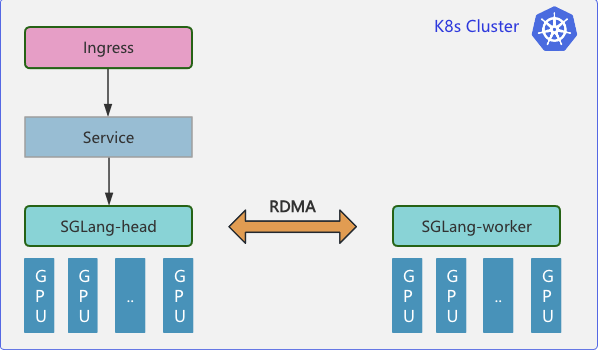
云原生分布式推理集群部署拓扑:
1. 部署LWS API
Github项目地址:
https://github.com/kubernetes-sigs/lws
在企业分布式推理架构中,需要多个 Pod 共同组成一个推理服务,同时不同 Pod 还具有不同的主从角色(在 sglang 和 vllm 中称为head 和 worker 节点)。Kubernetes 原生提供了如 Deployments、StatefulSet 等资源管理对象,能够很好管理单个 Pod 的生命周期和扩缩容。但是对于多机多卡分布式推理需要跨多个 Pod 部署资源并对多个 Pod 进行扩缩容的场景,就无法使用 Deployments 或 StatefulSet 。
为了应对这个挑战,Kubernetes 社区在 StatefulSet 的基础上提出了 Leader-Worker Set (LWS) API ,LWS API 提供了一种原生的方式来管理分布式推理任务中常见的 Leader-Worker 模式,其中 Leader Pods 通常负责协调任务、Worker Pods 则负责执行实际的推理任务或计算工作。LWS API 能够确保 Leader Pods 在完全就绪之前,不会启动 Worker Pods。同时可以单独定义 Leader 和 Worker 所需的 Pod 数量
使用 LWS API 的主要优势包括:
-
简化分布式推理的部署:通过
LWS API,提供了一个声明式的API,用户只需定义Leader和Worker的配置,Kubernetes控制器会自动处理其生命周期管理。用户可以更轻松地部署复杂的分布式推理工作负载,而无需手动管理Leader和Worker的依赖关系和副本数量; -
无缝水平扩容:分布式推理的服务需要多个
Pods共同提供服务,在进行扩容时也需要以多个Pod一组为原子单位进行扩展,LWS可以与k8s HPA无缝对接,将LWS作为HPA扩容的Target,实现推理服务整组扩容; -
拓扑感知调度 :在分布式推理中,不同
Pod之间需要进行大量数据交互。为了减少通信延时LWS API结合了拓扑感知调度,保证能够保证Leader和Worker Pod能够调度到RDMA网络中拓扑距离尽可能接近的节点上。
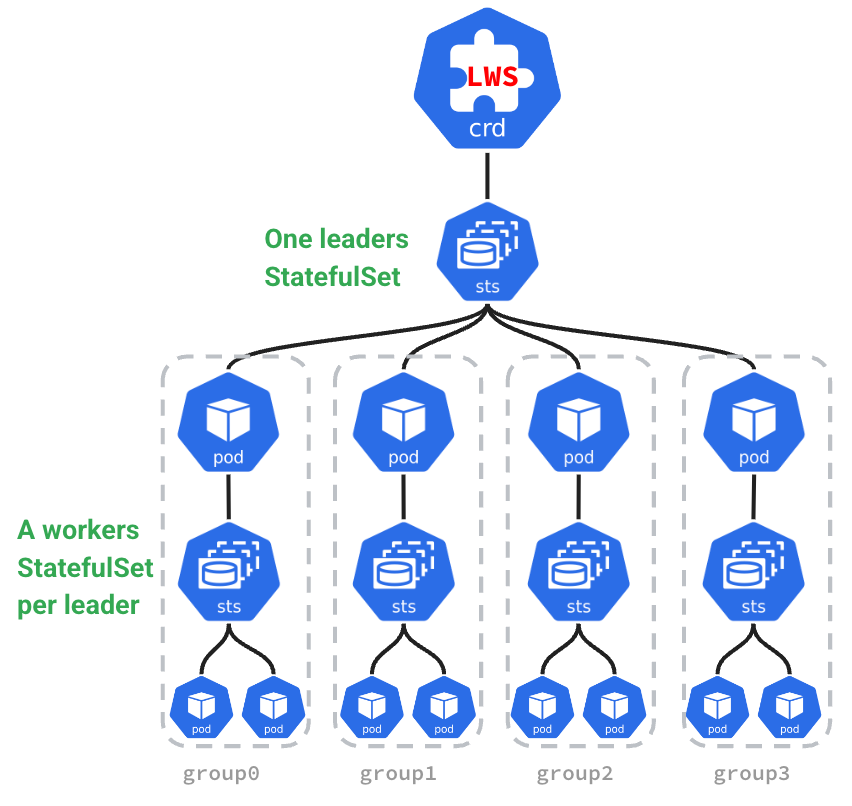
来自LWS官网
1. 安装 LWS API 的 CRD ~# VERSION=v0.5.1 ~# kubectl apply --server-side -f https://github.com/kubernetes-sigs/lws/releases/download/$VERSION/manifests.yaml 2. 检查LWS 资源 ~# kubectl get pods -n lws-system NAME READY STATUS RESTARTS AGE lws-controller-manager-7474f46db-xb8br 1/1 Running 0 14h lws-controller-manager-7474f46db-xkcf2 1/1 Running 0 14h ~# kubectl get svc -n lws-system NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE lws-controller-manager-metrics-service ClusterIP 10.233.35.119 <none> 8443/TCP 14h lws-webhook-service ClusterIP 10.233.4.24 <none> 443/TCP 14h ~# kubectl api-resources |grep -i lws leaderworkersets lws leaderworkerset.x-k8s.io/v1 true LeaderWorkerSet
2. 通过 LWS 部署DeepSeek-r1模型
Deploy Manifest Yaml 如下:
apiVersion: leaderworkerset.x-k8s.io/v1 kind: LeaderWorkerSet metadata: name: sglang labels: app: sglang spec: replicas: 1 startupPolicy: LeaderCreated rolloutStrategy: type: RollingUpdate rollingUpdateConfiguration: maxSurge: 0 maxUnavailable: 2 leaderWorkerTemplate: size: 2 restartPolicy: RecreateGroupOnPodRestart leaderTemplate: metadata: labels: role: leader spec: containers: - name: sglang-head image: ccr.ccs.tencentyun.com/kason/sglang:v0.4.2.post4-cu125 imagePullPolicy: IfNotPresent workingDir: /sgl-workspace command: ["sh", "-c"] args: - > cd /sgl-workspace && python3 -m sglang.launch_server --model-path /root/.cache/modelscope/DeepSeek-R1 --served-model-name deepseek-r1 --tp 16 --dist-init-addr $LWS_LEADER_ADDRESS:20000 --nnodes $LWS_GROUP_SIZE --node-rank 0 --trust-remote-code --context-length 131072 --enable-metrics --host 0.0.0.0 --port 8000 env: - name: GLOO_SOCKET_IFNAME value: eth0 - name: NCCL_IB_HCA value: "mlx5_0,mlx5_1,mlx5_4,mlx5_5" - name: NCCL_P2P_LEVEL value: "NVL" - name: NCCL_IB_GID_INDEX value: "0" - name: NCCL_IB_CUDA_SUPPORT value: "1" - name: NCCL_IB_DISABLE value: "0" - name: NCCL_SOCKET_IFNAME value: "eth0" #value: "ibs13,ibs11,ibs15,ibs17" - name: NCCL_DEBUG value: "INFO" - name: NCCL_NET_GDR_LEVEL value: "2" - name: POD_NAME valueFrom: fieldRef: fieldPath: metadata.name - name: SGLANG_USE_MODELSCOPE value: "true" ports: - containerPort: 8000 name: http protocol: TCP - containerPort: 20000 name: distributed protocol: TCP resources: limits: cpu: "128" memory: "1Ti" nvidia.com/gpu: "8" rdma/ib: "4" requests: cpu: "128" memory: "1Ti" nvidia.com/gpu: "8" rdma/ib: "4" securityContext: capabilities: add: - IPC_LOCK - SYS_PTRACE volumeMounts: - mountPath: /root/.cache/modelscope name: modelscope-cache - mountPath: /dev/shm name: shm-volume - name: localtime mountPath: /etc/localtime readOnly: true readinessProbe: tcpSocket: port: 8000 initialDelaySeconds: 120 periodSeconds: 30 volumes: - name: modelscope-cache hostPath: path: /file_CPU_01/modelServing - name: shm-volume emptyDir: sizeLimit: 512Gi medium: Memory - name: localtime hostPath: path: /etc/localtime type: File schedulerName: volcano workerTemplate: metadata: name: sglang-worker spec: containers: - name: sglang-worker image: ccr.ccs.tencentyun.com/kason/sglang:v0.4.2.post4-cu125 imagePullPolicy: IfNotPresent workingDir: /sgl-workspace command: ["sh", "-c"] args: - > cd /sgl-workspace && python3 -m sglang.launch_server --model-path /root/.cache/modelscope/DeepSeek-R1 --served-model-name deepseek-r1 --tp 16 --dist-init-addr $LWS_LEADER_ADDRESS:20000 --nnodes $LWS_GROUP_SIZE --node-rank $LWS_WORKER_INDEX --trust-remote-code --context-length 131072 --enable-metrics --host 0.0.0.0 --port 8000 env: - name: GLOO_SOCKET_IFNAME value: eth0 - name: NCCL_IB_HCA value: "mlx5_0,mlx5_1,mlx5_4,mlx5_5" - name: NCCL_P2P_LEVEL value: "NVL" - name: NCCL_IB_GID_INDEX value: "0" - name: NCCL_IB_CUDA_SUPPORT value: "1" - name: NCCL_IB_DISABLE value: "0" - name: NCCL_SOCKET_IFNAME value: "eth0" #value: "ibs13,ibs11,ibs15,ibs17" - name: NCCL_DEBUG value: "INFO" - name: NCCL_NET_GDR_LEVEL value: "2" - name: SGLANG_USE_MODELSCOPE value: "true" - name: LWS_WORKER_INDEX valueFrom: fieldRef: fieldPath: metadata.labels['leaderworkerset.sigs.k8s.io/worker-index'] ports: - containerPort: 8000 name: http protocol: TCP - containerPort: 20000 name: distributed protocol: TCP resources: limits: cpu: "128" memory: "1Ti" nvidia.com/gpu: "8" rdma/ib: "4" requests: cpu: "128" memory: "1Ti" nvidia.com/gpu: "8" rdma/ib: "4" securityContext: capabilities: add: - IPC_LOCK - SYS_PTRACE volumeMounts: - mountPath: /root/.cache/modelscope name: modelscope-cache - mountPath: /dev/shm name: shm-volume - name: localtime mountPath: /etc/localtime readOnly: true volumes: - name: modelscope-cache hostPath: path: /file_CPU_01/modelServing - name: shm-volume emptyDir: sizeLimit: 512Gi medium: Memory - name: localtime hostPath: path: /etc/localtime type: File schedulerName: volcano
~# kubectl apply -f deepseek-r1-lws-sglang.yaml ~# kubectl get lws -n sre-tools NAME AGE sglang 13h ~# kubectl get pods -n sre-tools |grep sglang sglang-0 1/1 Running 0 15h sglang-0-1 1/1 Running 0 15h ##查看日志 ~# kubectl logs -n sre-tools sglang-0 INFO 02-13 22:10:34 __init__.py:190] Automatically detected platform cuda. [2025-02-13 22:10:40] server_args=ServerArgs(model_path='/root/.cache/modelscope/DeepSeek-R1', tokenizer_path='/root/.cache/modelscope/DeepSeek-R1', tokenizer_mode='auto', load_format='auto', trust_remote_code=True, dtype='auto', kv_cache_dtype='auto', quantization_param_path=None, quantization=None, context_length=131072, device='cuda', served_model_name='deepseek-r1', chat_template=None, is_embedding=False, revision=None, skip_tokenizer_init=False, host='0.0.0.0', port=8000, mem_fraction_static=0.79, max_running_requests=None, max_total_tokens=None, chunked_prefill_size=8192, max_prefill_tokens=16384, schedule_policy='lpm', schedule_conservativeness=1.0, cpu_offload_gb=0, prefill_only_one_req=False, tp_size=16, stream_interval=1, stream_output=False, random_seed=824694846, constrained_json_whitespace_pattern=None, watchdog_timeout=300, download_dir=None, base_gpu_id=0, log_level='info', log_level_http=None, log_requests=False, show_time_cost=False, enable_metrics=True, decode_log_interval=40, api_key=None, file_storage_pth='sglang_storage', enable_cache_report=False, dp_size=1, load_balance_method='round_robin', ep_size=1, dist_init_addr='sglang-0.sglang.sre-tools:20000', nnodes=2, node_rank=0, json_model_override_args='{}', lora_paths=None, max_loras_per_batch=8, lora_backend='triton', attention_backend='flashinfer', sampling_backend='flashinfer', grammar_backend='outlines', speculative_draft_model_path=None, speculative_algorithm=None, speculative_num_steps=5, speculative_num_draft_tokens=64, speculative_eagle_topk=8, enable_double_sparsity=False, ds_channel_config_path=None, ds_heavy_channel_num=32, ds_heavy_token_num=256, ds_heavy_channel_type='qk', ds_sparse_decode_threshold=4096, disable_radix_cache=False, disable_jump_forward=False, disable_cuda_graph=False, disable_cuda_graph_padding=False, disable_outlines_disk_cache=False, disable_custom_all_reduce=False, disable_mla=False, disable_overlap_schedule=False, enable_mixed_chunk=False, enable_dp_attention=False, enable_ep_moe=False, enable_torch_compile=False, torch_compile_max_bs=32, cuda_graph_max_bs=160, cuda_graph_bs=None, torchao_config='', enable_nan_detection=False, enable_p2p_check=False, triton_attention_reduce_in_fp32=False, triton_attention_num_kv_splits=8, num_continuous_decode_steps=1, delete_ckpt_after_loading=False, enable_memory_saver=False, allow_auto_truncate=False, enable_custom_logit_processor=False, tool_call_parser=None, enable_hierarchical_cache=False) INFO 02-13 22:10:43 __init__.py:190] Automatically detected platform cuda. INFO 02-13 22:10:43 __init__.py:190] Automatically detected platform cuda. INFO 02-13 22:10:44 __init__.py:190] Automatically detected platform cuda. INFO 02-13 22:10:44 __init__.py:190] Automatically detected platform cuda. INFO 02-13 22:10:44 __init__.py:190] Automatically detected platform cuda. INFO 02-13 22:10:44 __init__.py:190] Automatically detected platform cuda. INFO 02-13 22:10:44 __init__.py:190] Automatically detected platform cuda. INFO 02-13 22:10:44 __init__.py:190] Automatically detected platform cuda. INFO 02-13 22:10:44 __init__.py:190] Automatically detected platform cuda. [2025-02-13 22:10:49 TP7] MLA optimization is turned on. Use triton backend. [2025-02-13 22:10:49 TP7] Init torch distributed begin. [2025-02-13 22:10:50 TP0] MLA optimization is turned on. Use triton backend. [2025-02-13 22:10:50 TP0] Init torch distributed begin. [2025-02-13 22:10:51 TP6] MLA optimization is turned on. Use triton backend. [2025-02-13 22:10:51 TP6] Init torch distributed begin. [2025-02-13 22:10:51 TP5] MLA optimization is turned on. Use triton backend. [2025-02-13 22:10:51 TP5] Init torch distributed begin. [2025-02-13 22:10:51 TP1] MLA optimization is turned on. Use triton backend. [2025-02-13 22:10:51 TP1] Init torch distributed begin. [2025-02-13 22:10:51 TP2] MLA optimization is turned on. Use triton backend. [2025-02-13 22:10:51 TP2] Init torch distributed begin. [2025-02-13 22:10:51 TP4] MLA optimization is turned on. Use triton backend. [2025-02-13 22:10:51 TP4] Init torch distributed begin. [2025-02-13 22:10:51 TP3] MLA optimization is turned on. Use triton backend. [2025-02-13 22:10:51 TP3] Init torch distributed begin. [2025-02-13 22:10:57 TP0] sglang is using nccl==2.21.5 [2025-02-13 22:10:57 TP3] sglang is using nccl==2.21.5 [2025-02-13 22:10:57 TP6] sglang is using nccl==2.21.5 [2025-02-13 22:10:57 TP5] sglang is using nccl==2.21.5 [2025-02-13 22:10:57 TP2] sglang is using nccl==2.21.5 [2025-02-13 22:10:57 TP7] sglang is using nccl==2.21.5 [2025-02-13 22:10:57 TP4] sglang is using nccl==2.21.5 [2025-02-13 22:10:57 TP1] sglang is using nccl==2.21.5 sglang-0:99:99 [0] NCCL INFO NCCL_SOCKET_IFNAME set by environment to eth0 sglang-0:99:99 [0] NCCL INFO Bootstrap : Using eth0:10.233.73.96<0> sglang-0:99:99 [0] NCCL INFO cudaDriverVersion 12060 NCCL version 2.21.5+cuda12.4 [2025-02-13 22:11:02 TP1] Custom allreduce is disabled because this process group spans across nodes. [2025-02-13 22:11:02 TP0] Custom allreduce is disabled because this process group spans across nodes. [2025-02-13 22:11:02 TP3] Custom allreduce is disabled because this process group spans across nodes. [2025-02-13 22:11:02 TP2] Custom allreduce is disabled because this process group spans across nodes. [2025-02-13 22:11:02 TP5] Custom allreduce is disabled because this process group spans across nodes. [2025-02-13 22:11:02 TP4] Custom allreduce is disabled because this process group spans across nodes. [2025-02-13 22:11:02 TP6] Custom allreduce is disabled because this process group spans across nodes. [2025-02-13 22:11:02 TP7] Custom allreduce is disabled because this process group spans across nodes. sglang-0:103:103 [4] NCCL INFO cudaDriverVersion 12060 sglang-0:103:103 [4] NCCL INFO NCCL_SOCKET_IFNAME set by environment to eth0 sglang-0:103:103 [4] NCCL INFO Bootstrap : Using eth0:10.233.73.96<0> sglang-0:103:103 [4] NCCL INFO Plugin Path : /opt/hpcx/nccl_rdma_sharp_plugin/lib/libnccl-net.so sglang-0:103:103 [4] NCCL INFO P2P plugin IBext_v8 sglang-0:103:103 [4] NCCL INFO NCCL_SOCKET_IFNAME set by environment to eth0 sglang-0:103:103 [4] NCCL INFO NET/IB : Using [0]mlx5_0:1/IB/SHARP [1]mlx5_1:1/IB/SHARP [2]mlx5_4:1/IB/SHARP [3]mlx5_5:1/IB/SHARP [RO]; OOB eth0:10.233.73.96<0> sglang-0:103:103 [4] NCCL INFO Using non-device net plugin version 0 sglang-0:103:103 [4] NCCL INFO Using network IBext_v8 ...... sglang-0:100:1012 [1] NCCL INFO Setting affinity for GPU 1 to ffff,ffffffff,00000000,0000ffff,ffffffff sglang-0:100:1012 [1] NCCL INFO comm 0x5568e6555af0 rank 1 nRanks 16 nNodes 2 localRanks 8 localRank 1 MNNVL 0 sglang-0:100:1012 [1] NCCL INFO Trees [0] 2/-1/-1->1->0 [1] 2/-1/-1->1->0 [2] 2/-1/-1->1->0 [3] 2/-1/-1->1->0 sglang-0:100:1012 [1] NCCL INFO P2P Chunksize set to 131072 sglang-0:100:1012 [1] NCCL INFO Channel 00/0 : 1[1] -> 14[6] [send] via NET/IBext_v8/0(0)/GDRDMA sglang-0:100:1012 [1] NCCL INFO Channel 02/0 : 1[1] -> 14[6] [send] via NET/IBext_v8/0(0)/GDRDMA sglang-0:100:1012 [1] NCCL INFO Channel 01/0 : 1[1] -> 0[0] via P2P/IPC sglang-0:100:1012 [1] NCCL INFO Channel 03/0 : 1[1] -> 0[0] via P2P/IPC ...... sglang-0:106:1010 [7] NCCL INFO threadThresholds 8/8/64 | 128/8/64 | 512 | 512 [2025-02-13 22:11:06 TP1] Load weight begin. avail mem=78.37 GB [2025-02-13 22:11:06 TP5] Load weight begin. avail mem=78.37 GB [2025-02-13 22:11:06 TP6] Load weight begin. avail mem=78.26 GB [2025-02-13 22:11:06 TP4] Load weight begin. avail mem=78.15 GB [2025-02-13 22:11:06 TP2] Load weight begin. avail mem=78.26 GB [2025-02-13 22:11:06 TP7] Load weight begin. avail mem=78.38 GB [2025-02-13 22:11:06 TP3] Load weight begin. avail mem=78.38 GB [2025-02-13 22:11:06 TP0] Load weight begin. avail mem=78.15 GB [2025-02-13 22:11:06 TP6] Detected fp8 checkpoint. Please note that the format is experimental and subject to change. [2025-02-13 22:11:06 TP2] Detected fp8 checkpoint. Please note that the format is experimental and subject to change. [2025-02-13 22:11:06 TP3] Detected fp8 checkpoint. Please note that the format is experimental and subject to change. [2025-02-13 22:11:06 TP4] Detected fp8 checkpoint. Please note that the format is experimental and subject to change. [2025-02-13 22:11:06 TP1] Detected fp8 checkpoint. Please note that the format is experimental and subject to change. [2025-02-13 22:11:06 TP7] Detected fp8 checkpoint. Please note that the format is experimental and subject to change. [2025-02-13 22:11:06 TP0] Detected fp8 checkpoint. Please note that the format is experimental and subject to change. [2025-02-13 22:11:06 TP5] Detected fp8 checkpoint. Please note that the format is experimental and subject to change. sglang-0:106:1010 [7] NCCL INFO 4 coCache shape torch.Size([163840, 64]) Loading safetensors checkpoint shards: 0% Completed | 0/162 [00:00<?, ?it/s] Loading safetensors checkpoint shards: 1% Completed | 1/162 [00:00<02:09, 1.24it/s] Loading safetensors checkpoint shards: 1% Completed | 2/162 [00:01<02:12, 1.20it/s] Loading safetensors checkpoint shards: 2% Completed | 3/162 [00:02<02:14, 1.19it/s] Loading safetensors checkpoint shards: 2% Completed | 4/162 [00:03<02:11, 1.20it/s] Loading safetensors checkpoint shards: 3% Completed | 5/162 [00:04<02:07, 1.23it/s] Loading safetensors checkpoint shards: 4% Completed | 6/162 [00:04<02:06, 1.24it/s] ...... Loading safetensors checkpoint shards: 99% Completed | 161/162 [01:34<00:00, 1.44it/s] Loading safetensors checkpoint shards: 100% Completed | 162/162 [01:35<00:00, 1.48it/s] Loading safetensors checkpoint shards: 100% Completed | 162/162 [01:35<00:00, 1.70it/s] ...... sglang-0:103:2984 [4] NCCL INFO Channel 01/0 : 14[6] -> 4[4] [receive] via NET/IBext_v8/2/GDRDMA sglang-0:103:2984 [4] NCCL INFO Channel 03/0 : 14[6] -> 4[4] [receive] via NET/IBext_v8/2/GDRDMA sglang-0:103:2984 [4] NCCL INFO Channel 01/0 : 4[4] -> 14[6] [send] via NET/IBext_v8/2/GDRDMA sglang-0:103:2984 [4] NCCL INFO Channel 03/0 : 4[4] -> 14[6] [send] via NET/IBext_v8/2/GDRDMA sglang-0:103:2984 [4] NCCL INFO Connected all trees sglang-0:103:2984 [4] NCCL INFO threadThresholds 8/8/64 | 128/8/64 | 512 | 512 100%|██████████| 23/23 [01:30<00:00, 3.92s/it] [2025-02-13 22:14:23] INFO: Started server process [1] [2025-02-13 22:14:23] INFO: Waiting for application startup. [2025-02-13 22:14:23] INFO: Application startup complete. [2025-02-13 22:14:23] INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit) #启动成功 sglang-0:103:2984 [4] NCCL [2025-02-13 22:14:24] INFO: 127.0.0.1:33198 - "GET /get_model_info HTTP/1.1" 200 OK [2025-02-13 22:14:31] INFO: 127.0.0.1:33208 - "POST /generate HTTP/1.1" 200 OK [2025-02-13 22:14:31] The server is fired up and ready to roll!
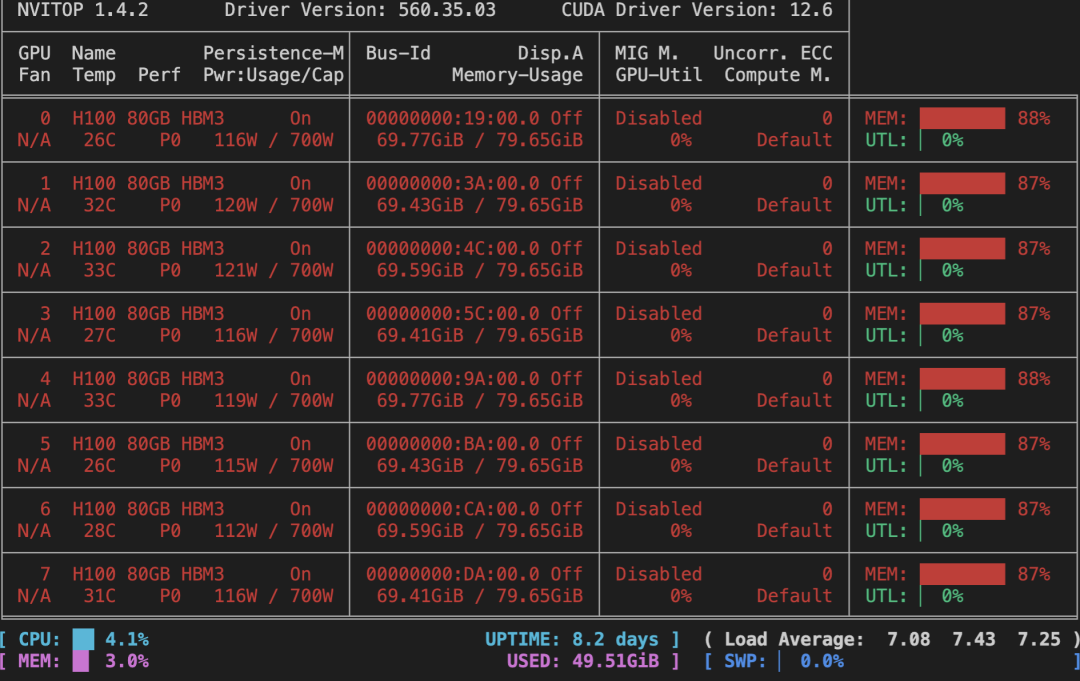
3. 查看显存占用情况
4. 服务对外暴露
`apiVersion: v1 kind: Service metadata: name: sglang-api-svc labels: app: sglang spec: selector: leaderworkerset.sigs.k8s.io/name: sglang role: leader ports: - protocol: TCP port: 8000 targetPort: http name: http type: NodePort #这里临时通过NodePort测试`
~# kubectl apply -f deepseek-r1-svc.yaml -n sre-tools #check ~# kubectl get svc -n sre-tools |grep sglang sglang ClusterIP None <none> <none> 13h sglang-api-svc NodePort 10.233.57.205 <none> 8000:32169/TCP 13h
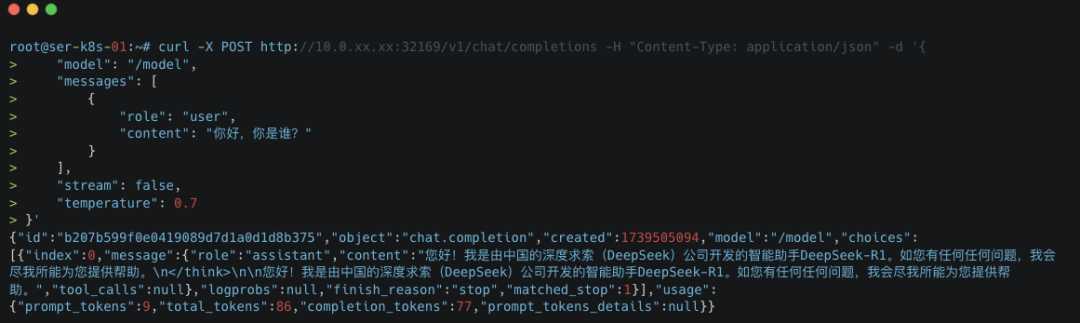
到此已完成了 DeepSeek R1 大模型的部署和服务对外暴露。接下来通过本地 curl 命令调用 API 或者 终端软件工具来测试部署效果。
5. 测试部署效果
5.1 通过 curl
curl -X POST http://10.0.xx.xx:32169/v1/chat/completions -H "Content-Type: application/json" -d '{ "model": "/model", "messages": [ { "role": "user", "content": "你好,你是谁?" } ], "stream": false, "temperature": 0.7 }'
5.2 通过 OpenWebUI
a. 部署 OpenWebUI
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: open-webui-data-pvc spec: accessModes: - ReadWriteOnce resources: requests: storage: 100Gi storageClassName: nfs-client --- apiVersion: apps/v1 kind: Deployment metadata: name: open-webui-deployment spec: replicas: 1 selector: matchLabels: app: open-webui template: metadata: labels: app: open-webui spec: containers: - name: open-webui image: ccr.ccs.tencentyun.com/kason/open-webui:main imagePullPolicy: Always ports: - containerPort: 8080 env: - name: OPENAI_API_BASE_URL value: "http://10.0.xx.xxx:32169/v1" # 替换为SGLang API - name: ENABLE_OLLAMA_API # 禁用 Ollama API,只保留 OpenAI API value: "False" volumeMounts: - name: open-webui-data mountPath: /app/backend/data volumes: - name: open-webui-data persistentVolumeClaim: claimName: open-webui-data-pvc --- apiVersion: v1 kind: Service metadata: name: open-webui-service spec: type: ClusterIP ports: - port: 3000 targetPort: 8080 selector: app: open-webui
b. 通过Ingress暴露 OpenWebUI
apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: open-webui-ingress spec: rules: - host: open-webui.xxxx-sh.com http: paths: - backend: service: name: open-webui-service port: number: 3000 path: / pathType: Prefix tls: - hosts: - open-webui.xxxx-sh.com secretName: xxxx-tls
c. 访问 OpenWebUI
在浏览器访问相应的地址即可进入 OpenWebUI 页面。首次进入会提示创建管理员账号密码,创建完毕后即可登录,然后默认会使用前面下载好的大模型进行对话。



还有一些其他可视化交互工具,例如:
1.Chatbox AI:https://chatboxai.app/zh
2.Cherry Studio:https://cherry-ai.com
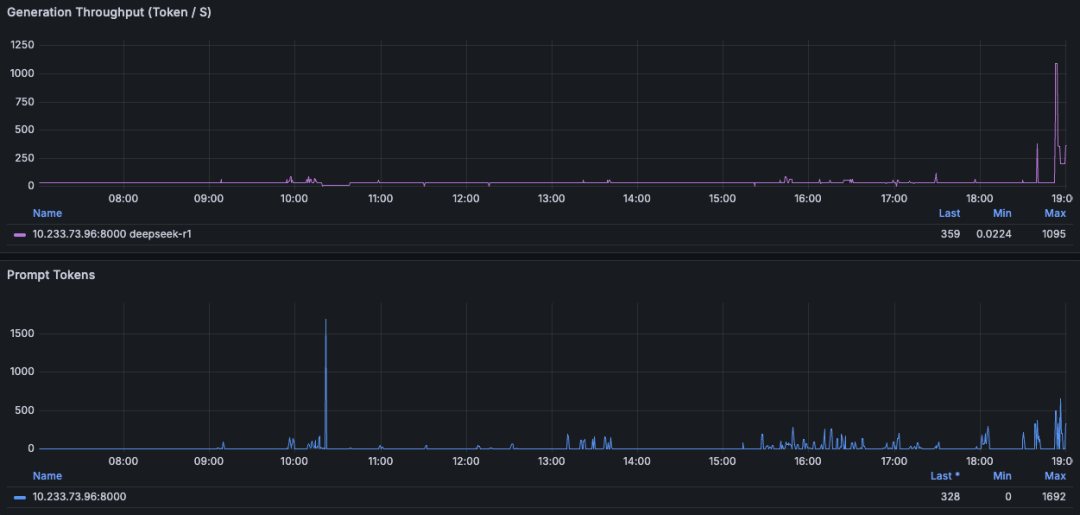
地表最强LLM推理引擎-SGLang:Generation Throughput (Token / s):1095(Max)
Ollama运行的话稳定会保持在 30~32 tokens/s
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 1455
1455

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









