








基本信息:
完成日期:2024年9月16-17日
用时:25+小时
问题定义:
模拟英雄联盟、王者荣耀类似的多人在线游戏的入局匹配机制系统(仅需实现一支队伍的匹配,理想条件),要求实现从等待队列中(同段位)匹配各司其职(对抗top、中路mid、发育adc、打野jungle、辅助sup)的五位玩家为一队入局,1)段位内分数尽可能接近; 2)匹配时间不宜过长。
理论分析&算法设计:
这个问题是一个基于线性数据算结构的三条件优化搜索问题,可以使用数组(顺序存储)、链表(链式存储)作为数据容器,二者各有利弊,笔者选用C++标准库STL里的vector容器(可以扩容的数组设计)。
先排队的玩家居于vector容器(以下简称数组)的前端,依次累积,系统将从最前端元素进行遍历,队伍里最早等待的玩家被锁定进入当前局。总体而言进行三轮筛选:(1)凑齐五种角色;(2)利用分数表征元素迭代缩小搜索;(3)当表征元素达到特定标准且时间未超设定最大等待时间时,匹配入局;当时间超过最大等待时间时,选取保底匹配结果入局。
笔者建立Player类,使用vector库push_back函数完成player入队等待、erase函数完成出队入局;将角色功能种类数量化(type=0,1,2,3,4),以【极差】作为分数表征元素,设置目标最大极差,同时加入计时函数进行匹配时间约束,通过逻辑与、或条件完成系统建构。
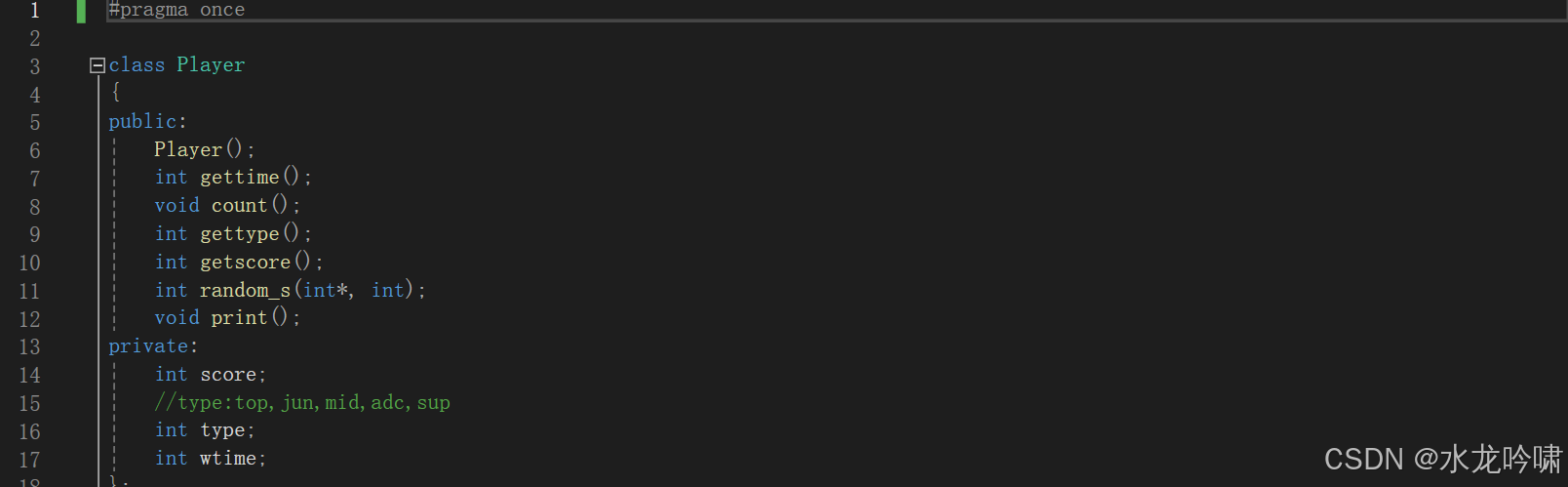
图 1 Player类定义
实验设计:
(1)运行环境&数据来源:
利用C++ random库实现符合泊松分布的随机数生成,模拟一时间段内入队等待玩家数量;利用python scipy、numpy库实现偏峰beta分布随机数生成,模拟入队玩家段位分数,进行C++调用Python的混合编译运行(VS选用Release,添加附加包含目录、附加库目录和附加依赖项,注意python解释器路径的DLLs、Scripts目录和自身父目录要添加到系统环境变量);利用op.gg网站获得LOL Platinum玩家不同分段(I、II、III、IV)的分布数据,每个分段100分,并计算beta分布形状双参数,使用matlab绘图辅助验证;利用C++ fstream库进行文件读写,将实验结果数据分别存储到三个txt文本文件中。
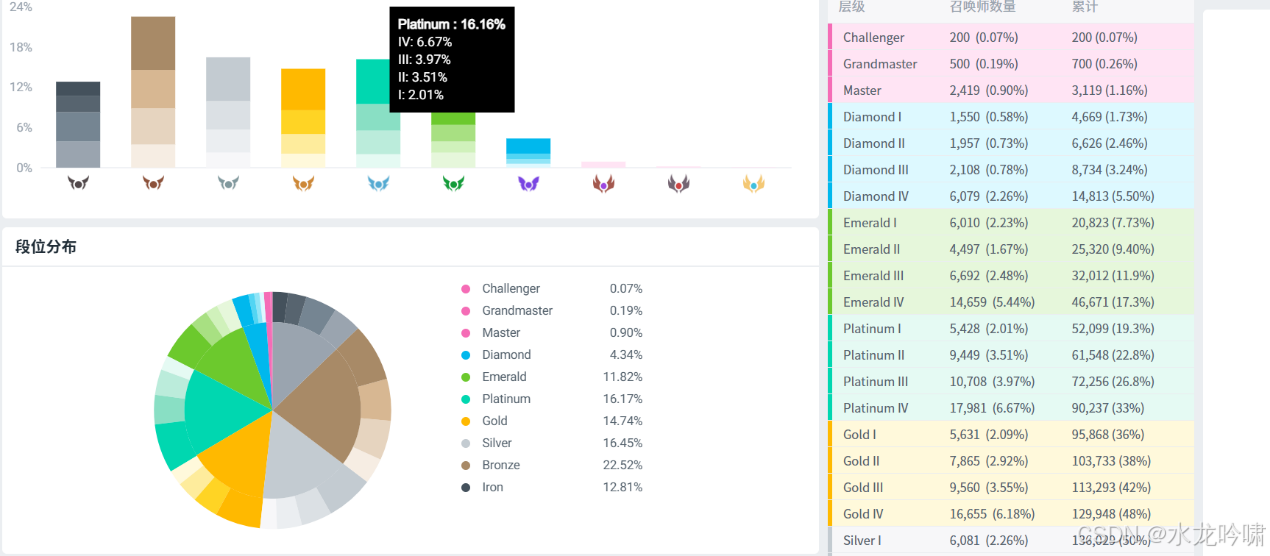
图 2 OP.GG网站获取LOL段位分数据(以铂金段位作为实验参考)

图 3 MATLAB绘图验证(铂金段位四分段数量占比)
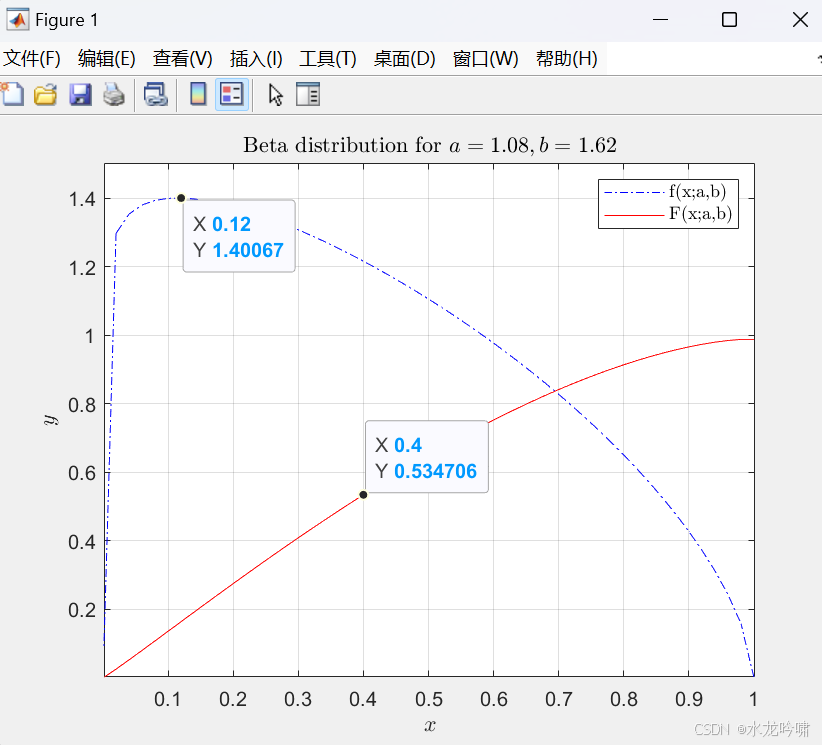
图 4 MATLAB绘图验证(各分段以分段中间分作为分段平均值和众数,铂金段位均值、众数比对)
(2)条件假设:
假设五大角色偏好率服从古典概型,泊松分布参数为平均2.0人/秒,beta分布α、β分别为1.08、1.62,最低匹配度匹配时间上限设为60秒,目标极差goal_gap设为90分(代码里设置的goal_gap并非真实的goal_gap),初始搜索极差bound设为400(最大可能分差),迭代公式为bound=int((goal_gap-10)/3.0+maxgap(当前匹配数据的极差)*2.0/3); 局内平均游戏时间24分钟(1440秒);
(3)实验指标(反馈):
打印同队玩家(最长)匹配时间、最大分差、等待玩家数随时间变化的数据、同队玩家在等待队伍中的位次和角色与段位分、每组队伍匹配用时(笔者未实现,理论可行)、预选入局队伍实时(每秒)匹配情况。

|
图 5 预计匹配时间计算及原理 |
提升版本:预计匹配时间计算(已实现,与实际贴合度不高,由于数据不准确||算法不精确)、Team类(MMR预测总胜率接近)、表征元素选用匹方差(标准差)。
(4)模拟过程与数据输出:
笔者的代码并没有进行计算机非实时模拟(压缩时间轴),由于发现vector库的数据操作函数可能受到运行时间的影响(非实时计算导致预选队伍的size总是无法到达5个,在模拟数据一致的情况下),采用实时模拟的方式进行实验,分别进行为时2分钟、20分钟的实验,数据输出保存在“Line_Size.txt”(等待玩家数随时间变化的数据,append写入)、“Queue_Information.txt”(每秒已入局玩家数量、在线玩家数量、等待队列中所有玩家预计匹配的完整时间;append写入)、“Players.txt”(最大分差、同队玩家(最长)匹配时间、同队玩家在等待队伍中的位次和角色与段位分,其中2分钟实验位次记录在实验进行时代码存在纰漏,导致部分位次记录不完整;单out写入)三个文本文件内,20分钟实验的输出文件用“(20min)”标记出,2分钟实验相关实时模拟的视频参见以下链接(B站)。
链接:英雄联盟、王者荣耀--游戏匹配机制算法设计&模拟实验_哔哩哔哩_bilibili
实验结果分析:
2分钟实验/120个时间单位数据:
从“Line_Size.txt”文件中可以看到,63s-120s等待队伍玩家数量基本稳定在100名左右,一定程度上证明了数据和匹配算法的科学有效性;“Queue_Information.txt”文件中,预计匹配完整时间最后仍处于非稳状态(未收敛),在16分钟左右;“Players.txt”文件中预选队伍实时情况可以映证极差迭代缩小搜索算法的有效性。
20分钟实验/1200个时间单位数据:
根据队伍规模的变化,可以将“Line_Size.txt(20min)”文件的时间线分为7个阶段(以秒为单位):1 第一阶段稳定(58-325),人数在80-110之间稳定波动;2 第一阶段低谷(326-384),人数在40-80之间波动,其中342秒队伍人数更是少至37个;3 第二阶段稳定(385-598),人数在70-100之间波动;4 第二阶段低谷(599-670),人数在40-70波动;5 缓慢上升期(671-795),人数从平均70逐渐抬升至平均80;6 第三阶段稳定(796-938),人数在80-110之间波动,同第一阶段稳定期;7 膨胀稳定期(939-1200),15分钟40秒左右,队列人数爆发式增长并得以维持相对稳定,最终在120-140间波动,这样也符合预计排队时间相对恒定的情况。“Queue_Information.txt(20min)”中,弥补了2分钟实验时间不足的问题,验证了预计匹配时间算法在一定程度上的科学有效,预计时间最终收敛,在60s-120s之间波动,由于笔者设置的单局游戏时间为24分钟,所以当排队队列启动时间达到24分钟时,需要考虑玩家总数、已匹配玩家数量(队列内玩家数)的减少,最终铂金段位的玩家在线总数、局内局外分配比、预计排队时间会和泊松分布的λ参数、算法的内禀属性参数(如1/3、2/3的权重参数和目标最大极差、最长匹配时间限制等);“Players.txt(20min)”文件中预选队伍实时情况可以映证极差迭代缩小搜索算法的有效性。
心得体悟:
16、17号加上写报告花了近一天半的时间,虽然艰辛、虽然漫长,在身体状况不是很好的情况下,依然感受到学以致用的乐趣,此外搜集资料、自主学习的过程也充满着多巴胺。大公司(腾讯、网易、暴雪、碧育、米哈游等)的游戏设计师究竟每天做哪些工作?在收获满满的同时我不禁也产生了这样的疑问,上学期的高级语言程序设计实训课我也几乎用100% C++自己开发了一个植物大战僵尸游戏,放到了Github上。
10月6号补充进行了20分钟的排队实验和相关分析、总结。
参考资料:
(1)PyImport_ImportModule 返回空NULL py模块import其他库-CSDN博客(笔者使用Python3.7.1解释器,故有关目录及文件都不是python38而是python37,python37.lib对应的是Release版本的VS编译模式);

















 3454
3454

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









