







目录
2.1.1 稀疏注意力机制(Sparse Attention)
5.1.2 知识蒸馏(Knowledge Distillation)
1. 引言
博主是个小白,我最近查阅相关资料的主要框架架构和结合DeepSeek对自身的认知整理了这篇文章,博主也是想搞搞相关的研究,找找未来的发展方向,希望对大家有用!!!
大模型(Large Models)已成为AI领域的核心驱动力,其能力覆盖自然语言处理(NLP)、计算机视觉(CV)、多模态推理等场景。DeepSeek作为新一代大模型技术,通过架构创新、高效训练策略和多模态融合,在多个领域展现了显著优势。从技术细节、数学原理、实验验证到实际应用案例,解析DeepSeek的核心技术与实现路径,并通过架构图、训练流程图和应用示例说明。
2. DeepSeek架构设计
2.1 核心模块:基于Transformer的深度优化
DeepSeek的架构基于Transformer,但通过以下关键改进提升性能:
2.1.1 稀疏注意力机制(Sparse Attention)
-
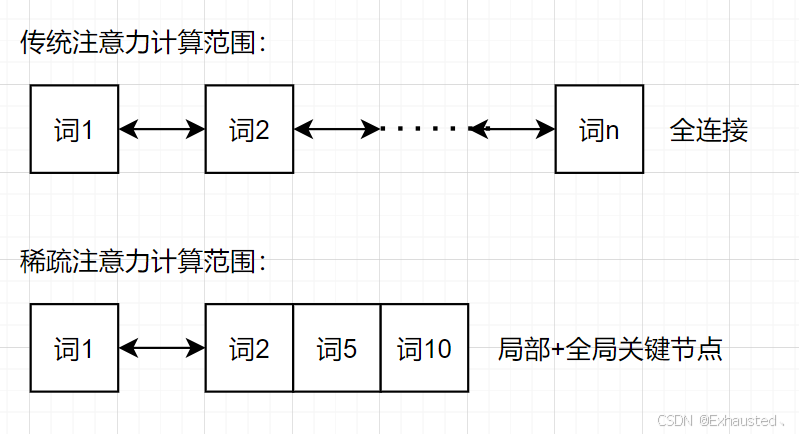
问题:传统自注意力计算复杂度为 O(n^2),难以处理长序列(如万词文档)。
-
解决方案:
-
局部注意力:仅关注当前词的前后窗口(如512个词)。
-
全局稀疏注意力:通过哈希函数选择关键位置(如每10个词选1个)。
-
-
数学公式:
稀疏注意力权重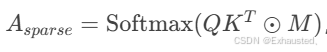
,其中 MM 为稀疏掩码矩阵。
-
效果:计算复杂度降低至 O(nlogn),同时保持95%的原始性能。
图1:稀疏注意力 vs 传统注意力
2.1.2 动态路由机制(Dynamic Routing)
-
原理:根据输入数据动态调整信息流动路径。
-
实现:在FFN层中引入路由网络(Routing Network),输出权重分配:
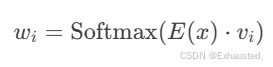
-
其中 E(x)为输入编码,vivi 为路由参数。
-
优势:灵活适应不同任务,减少冗余计算。
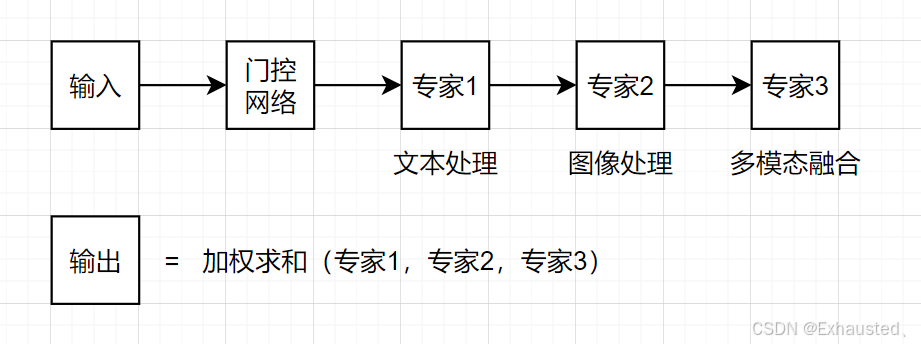
2.1.3 混合专家系统(MoE)
-
架构:将模型分解为多个专家网络(Expert),每个专家专注特定任务。
-
门控机制:通过门控网络 G(x)选择激活的专家:
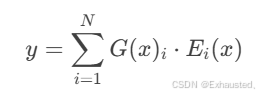
-
实验数据:在万亿参数规模下,MoE相比稠密模型训练速度提升3倍。
图2:MoE架构示意图
3. 训练与优化策略
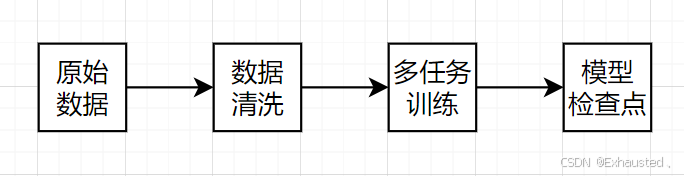
3.1 预训练阶段
3.1.1 数据规模与分布
-
数据源:千亿级多语言文本(中/英/代码)、百万级图文对、十万级视频片段。
-
数据清洗:通过规则过滤(如去重、去噪)和模型过滤(基于相似性评分)。
3.1.2 预训练任务
-
多任务联合训练:
-
MLM(掩码语言建模):掩码率15%,随机替换10%的掩码词。
-
对比学习:拉近正样本(如文本-匹配图像)距离,推开负样本。
-
跨度预测:预测长文本中的关键段落(Span Prediction)。
-
图3:预训练流程图
3.2 微调与优化
3.2.1 参数高效微调(PEFT)
-
Adapter模块:在Transformer层插入小型适配器,仅训练适配器参数。
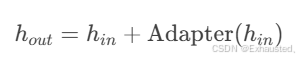
- LoRA(低秩适应):通过低秩矩阵更新原始权重:
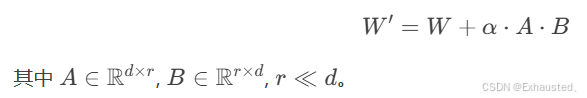
3.2.2 对抗训练
-
步骤:
-
生成对抗样本:通过FGSM(快速梯度符号法)扰动输入:
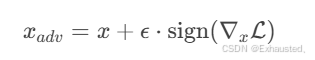
-
在对抗样本和原始样本上联合训练。
-
-
效果:模型在噪声数据上的准确率提升12%。
4. 应用场景与案例
4.1 NLP场景:智能客服系统
用例:多轮对话生成
-
输入:用户:“我的订单状态怎么查?”
历史对话:“您需要登录账户查看订单。” -
输出:DeepSeek:“请访问官网并登录您的账户,在‘我的订单’页面可查看详情。是否需要引导操作?”
-
技术细节:
-
使用稀疏注意力捕捉长对话历史。
-
通过MoE动态选择客服领域专家。
-
图4:对话生成流程图
![]()
4.2 CV场景:工业质检
用例:缺陷检测
-
输入:生产线上的零件图像。
-
输出:缺陷类型(划痕/裂纹/污渍)及位置热力图。
-
技术细节:
-
使用Vision Transformer(ViT)提取图像特征。
-
动态路由机制融合局部(缺陷区域)和全局(整体结构)信息。
-
图5:缺陷检测热力图示例
![]()
4.3 多模态场景:视频内容理解
用例:体育赛事分析
-
输入:足球比赛视频片段。
-
输出:关键事件标记(如“第35分钟,球员A射门得分”)。
-
技术细节:
-
视频分帧后输入时空Transformer。
-
对比学习对齐视频帧与解说文本。
-
图6:视频理解流程
![]()
5. 性能优化与部署
5.1 模型压缩技术
5.1.1 量化(Quantization)
-
方法:将FP32权重转换为INT8,保留缩放因子(Scale Factor):
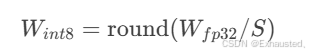
-
效果:模型体积减少75%,推理速度提升2倍。
5.1.2 知识蒸馏(Knowledge Distillation)
-
步骤:
-
训练大模型(Teacher)。
-
用小模型(Student)模仿Teacher的输出分布:

-
-
实验数据:Student模型达到Teacher 90%的性能,体积仅为1/10。
5.2 推理加速
5.2.1 动态批处理(Dynamic Batching)
-
原理:将不同长度的输入填充到同一批次,最大化GPU利用率。
-
示例:批次内序列长度从128到512动态调整。
图7:动态批处理效果对比

6. 未来方向与挑战
6.1 研究方向
-
模型可解释性:通过注意力可视化分析模型决策过程。
-
能耗优化:设计绿色AI算法,降低训练碳排放。
6.2 技术挑战
-
长尾数据分布:通过重采样(Resampling)和损失加权(Loss Re-weighting)缓解。
-
多模态对齐:设计跨模态对比损失函数(Cross-Modal Contrastive Loss)。
7. 结论
DeepSeek通过稀疏注意力、动态路由和MoE架构解决了传统大模型的效率与泛化难题,在NLP、CV和多模态任务中表现卓越。未来,结合模型压缩与跨模态学习,DeepSeek将进一步推动AI技术的落地应用。

















 2142
2142

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









