






DeepSeek模型微调(理论篇)

1. 简介
在大模型的微调过程中,**LoRA(低秩适配)**参数设置是提升训练效率和性能的关键。通过减少需更新的参数量,LoRA能够在维持模型性能的同时显著降低计算成本。
然而,LoRA并非唯一影响训练效果的因素。诸如学习率、批次大小以及优化器(如AdamW)等参数同样在微调过程中起着至关重要的作用。
学习率决定了模型每次更新的幅度,批次大小则影响了每次训练中样本的处理量,而优化器则确保模型参数的平稳更新。了解并灵活调整这些训练参数,不仅能帮助你在微调过程中得心应手,更能快速提升训练效果。
本文将通过使用多轮对话数据集进行微调实验,帮助你深入了解微调的核心原理,并提供一套完整的操作指南。
在本教程中,你将学习到:
- 如何进行LoRA参数的设置,并掌握在不同任务中的应用。
- 训练过程中如何合理调整学习率、批次大小等关键参数,以优化模型性能。
- 多轮对话数据集的微调方法和原理,为你提供实践的基础。
本实验基于transformers和openMind均已实现本次微调,代码均可在github链接上查看。
通过本次实验,你不仅能够完成多轮对话数据的微调,还能掌握这些方法,并将其迁移到其他微调实验中,独立进行高效的模型调优。
2. 链接资料
数据集:https://github.com/SmartFlowAI/EmoLLM/blob/main/datasets/data_pro.json
模型地址:https://www.modelscope.cn/models/deepseek-ai/deepseek-llm-7b-chat
代码地址:
https://github.com/828Tina/deepseek-llm-7B-chat-lora-ft
可视化工具SwanLab项目地址:
https://swanlab.cn/@LiXinYu/deepseek-llm-7b-chat-finetune/overview
友情链接-魔乐社区:https://modelers.cn/

3. 多轮对话数据构建
多轮对话微调其实和单轮对话(或者说指令数据)差不多,在我看来其实类似于多个指令数据的组合,单轮对话数据处理的时候只需要处理输入和输出即可,训练的时候输入置为-100,输出不变,而多轮对话微调数据集以及标签
3.1 训练不充分
第一种方法是,只把最后一轮机器人的回复作为要学习的标签,其它地方作为语言模型概率预测的condition,无需学习,赋值为-100,忽略这些地方的loss。
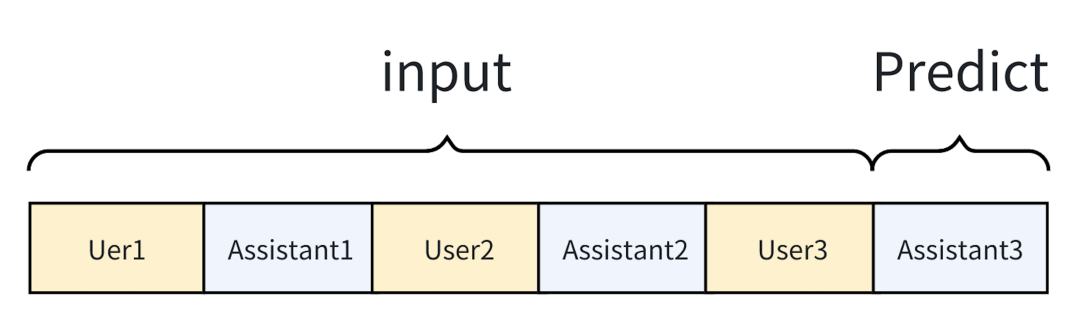

这种方法由于没有对中间轮次机器人回复的信息进行学习,因此存在着严重的信息丢失,是非常不可取的。
3.2 训练不高效
第二种方法是,把一个多轮对话拆解,构造成多条样本,以便对机器人的每轮回复都能学习。
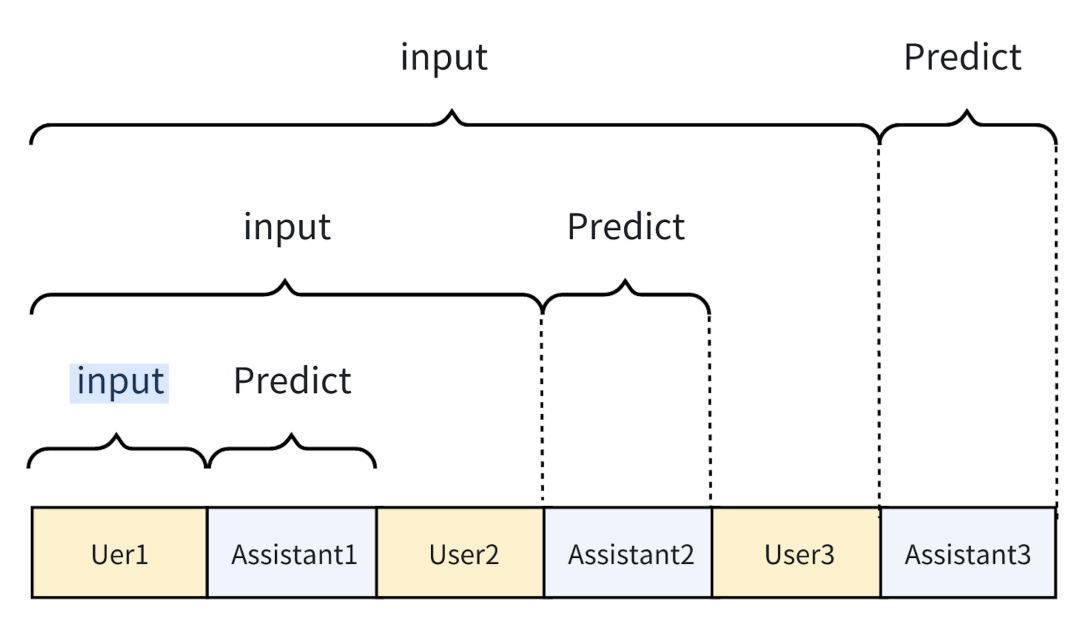

这种方法充分地利用了所有机器人的回复信息,但是非常低效,模型会有大量的重复计算。
3.3 合适的数据组合方式
第三种方法是,直接构造包括多轮对话中所有机器人回复内容的标签,充分地利用了所有机器人的回复信息,同时也不存在拆重复计算,非常高效。目前大部分微调框架用的都是这个组合方式。
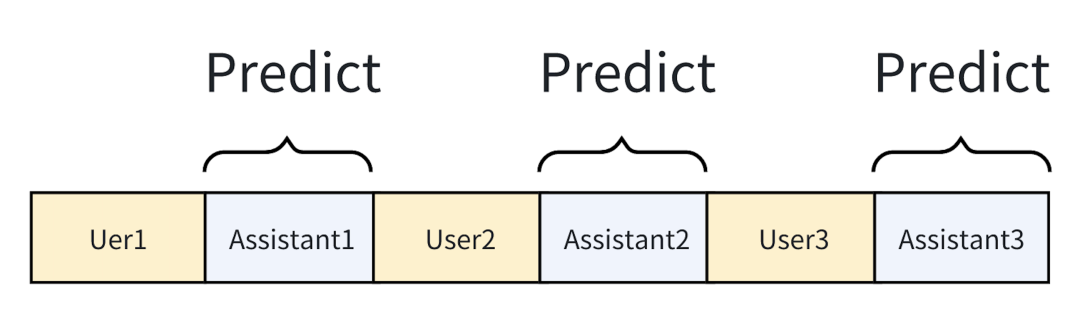

我们为什么可以直接构造多轮对话样本?难道将第二轮和第三轮对话内容加入 inputs 中不会干扰模型对第一轮对话的学习吗?
答案是:不会。原因在于,作为一种语言模型,LLM(大语言模型)采用的是基于注意力机制的结构,其中的自注意力机制(Self-Attention) 在处理输入时,具有天然的局部性约束。具体来说,LLM 在处理每一个输入时,使用掩码注意力(Masked Attention)来确保每个位置的预测只依赖于前面已经生成的内容,而不会提前“看到”后续的对话轮次。
也就是说,尽管输入数据中包含了多轮对话的信息,模型在进行每一轮对话的生成时,仅会关注当前回合的上下文,而不受后续轮次内容的影响。这样,第一轮的对话内容与后续轮次的对话并不会相互干扰,从而保持了学习的纯粹性。通过这种机制,模型能够有效地在多轮对话的框架下进行训练,同时保证每轮对话的独立性和准确性。
简而言之,LLM 能够通过其掩码机制在多轮对话中进行“局部”学习,每次生成的内容都仅与当前上下文相关,而不会受到其他轮次的干扰。

4. 各实验参数原理
4.1 lora参数
LoRA(Low-Rank Adaptation)是一种针对大型语言模型的微调技术,旨在降低微调过程中的计算和内存需求。其核心思想是通过引入低秩矩阵来近似原始模型的全秩矩阵,从而减少参数数量和计算复杂度。
在LoRA中,原始模型的全秩矩阵被分解为低秩矩阵的乘积。具体来说,对于一个全秩矩阵W,LoRA将其分解为两个低秩矩阵A和B的乘积,即W ≈ A * B。其中,A和B的秩远小于W的秩,从而显著减少了参数数量。
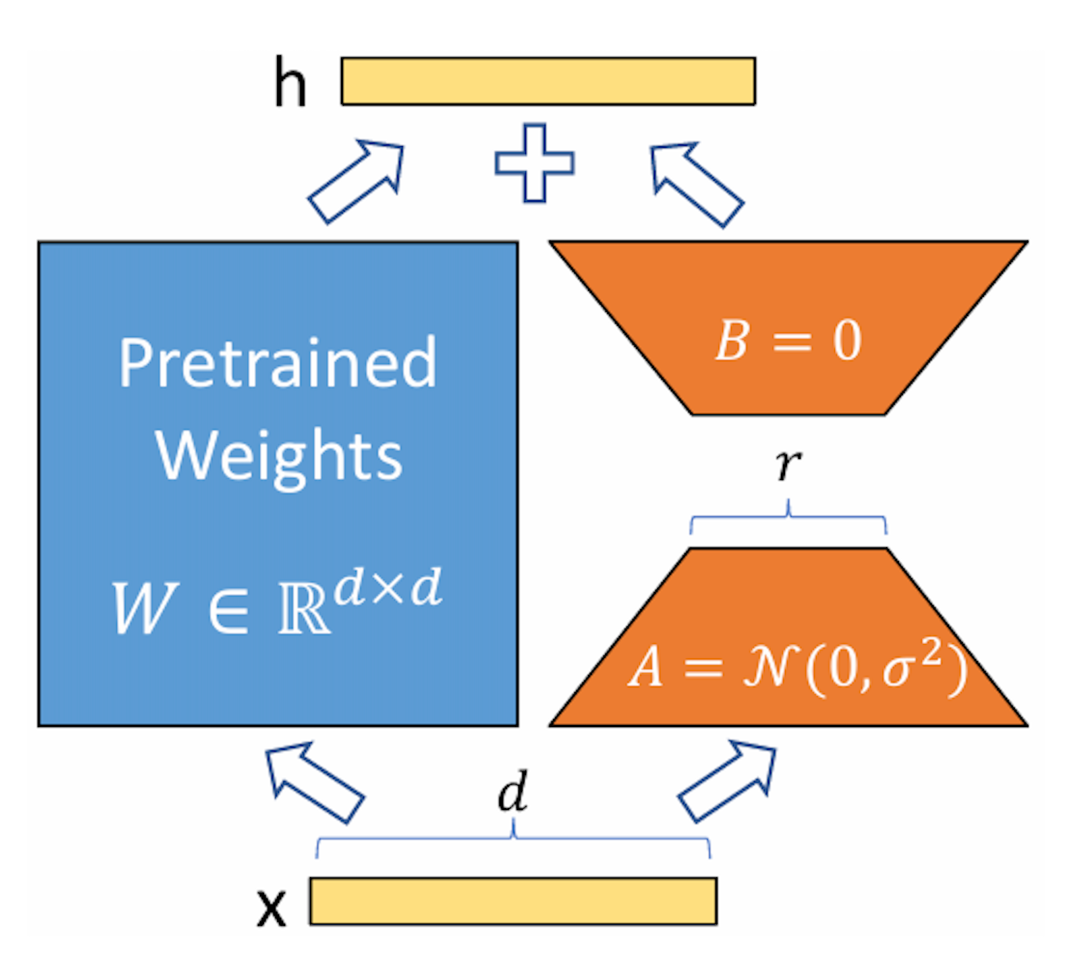
上图为 LoRA 的实现原理,其实现流程为:
- 在原始预训练语言模型旁边增加一个旁路,做降维再升维的操作来模拟内在秩;
- 用随机高斯分布初始化 A,用零矩阵初始化B,训练时固定预训练模型的参数,只训练矩阵 A 与矩阵 B ;
- 训练完成后,将 B 矩阵与 A 矩阵相乘后合并预训练模型参数作为微调后的模型参数。
公式表示为:
𝑊′=𝑊+Δ𝑊=𝑊′+𝐴⋅𝐵
其中,W是原始的权重矩阵,A是一个尺寸为dr的矩阵,B是一个尺寸为rd’的矩阵,r是低秩矩阵的秩。通过这种分解,原始矩阵W的更新仅由A和B的乘积决定。进一步地,LoRA引入了一个缩放因子α,使得更新公式为:
𝑊′=𝑊+𝛼𝑟𝐴⋅𝐵
那么在实际使用的时候,我们如何确定lora参数?这些参数的变化对实验结果产生什么影响?模型具体哪些部分参数需要使用lora?等等这些问题,我们应该如何应对?下面我将详细介绍。
LoraConfig各个参数设置
peft(Parameter-Efficient Fine-Tuning)库是一个用于高效微调大规模预训练模型的工具,旨在减少训练时的计算和存储成本,同时保持模型性能。它通过引入LoRA、Adapter等技术,使得只需调整部分参数即可实现有效的微调。LoraConfig是peft库中的一个配置类,用于设置LoRA相关的超参数,如低秩矩阵的秩、缩放因子等,它帮助用户定制LoRA微调的细节,优化训练过程的效率和效果。
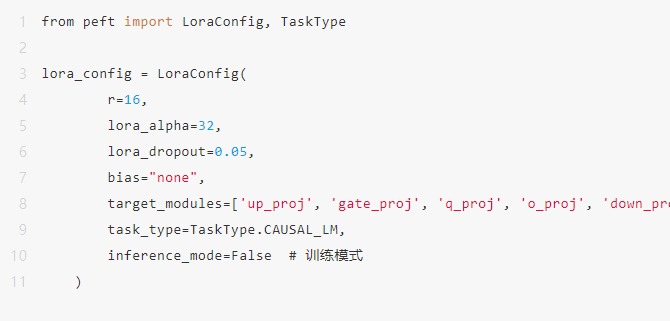
target_modules
target_modules是 LoRA(Low-Rank Adaptation)中的关键参数,用于指定模型中需要插入低秩矩阵调整的模块。LoRA 的核心思想是通过对预训练模型中的特定层进行低秩矩阵插入,实现参数高效微调而无需修改原始权重。对于语言模型,通常选择影响权重更新较大的模块,例如q_proj和k_proj(负责查询和键的变换),v_proj(值的变换),以及o_proj(输出投影)等。这些模块主要集中在自注意力和前馈网络中,通过插入的低秩矩阵调整这些模块的权重,使模型在保持原始能力的同时适应新任务,极大减少微调的计算和存储开销。
具体如下,我们使用deepseek观察模型每一层具体都是什么:

具体模型结构如下:

可以看到deepseek模型也是采取的Llama模型结构,那么具体哪些层会参与lora微调呢?下面将详细介绍
1. Attention层
-
Self-attention层: 这些层通常对模型性能影响较大。LoRA会被应用于自注意力的查询(q_proj)、键(k_proj)、值(v_proj)和输出(o_proj)投影矩阵。这些矩阵包含了大量的可训练参数,因此是LoRA微调的理想目标。
-
LlamaSdpaAttention中的矩阵:
-
- q_proj: 查询投影
- k_proj: 键投影
- v_proj: 值投影
- o_proj: 输出投影
- Rotary Embedding: 虽然在一些实现中会对嵌入进行微调,但通常LoRA不会直接用于rotary_emb,因为它通常是固定的。
2. MLP层 - MLP层中的Gate、Up和Down投影:
- gate_proj:控制门投影
- up_proj:上升投影
- down_proj:下降投影
MLP层的Gate、Up和Down投影通常涉及大量的可训练参数,因此对这些投影进行LoRA微调,可以在不显著增加计算负担的情况下优化模型表现。
通过低秩适应,LoRA能够在减少参数量的同时,增强模型对复杂模式的适应能力。这些曾在处理非线性变换时起到重要作用,通常也是LoRA微调的目标。
3. LayerNorm层
- RMSNorm: 在Llama中使用的是LlamaRMSNorm(Root Mean Square Layer Normalization),它与标准的LayerNorm不同,但也可以通过LoRA微调。虽然这部分常常不会进行微调,但如果需要微调,通常会集中在注意力层和MLP层上。
4.Embedding层
- embed_tokens:如果对词嵌入有需要进行微调,LoRA也可以应用于嵌入矩阵。尤其在词汇量较大的情况下,嵌入矩阵的参数量非常庞大,这样进行LoRA微调也可以获得一定的性能提升。
5. 线性层(lm_head)
- lm_head:在模型输出时,lm_head是从隐藏层到词汇表的最后一层线性转换。通常,LoRA不会直接应用于输出层,但在某些微调场景下,可以将LoRA应用于该层以调整模型输出。
总结:
一般来说,LoRA微调会集中在以下层:
Attention层的查询、键、值和输出投影(q_proj, k_proj, v_proj, o_proj)
MLP层的gate_proj、up_proj和down_proj
可能在某些场景下微调embed_tokens和lm_head
通过这种方式,LoRA能够有效减少参数量和计算成本,同时保持微调的效果。
r、alpha、dropout
在模型微调的过程中,r、alpha和dropout是常见的超参数,用于优化模型训练和提升其泛化能力。
-
r:通常用于LoRA(Low-Rank Adaptation)方法中,表示低秩矩阵的秩值。r决定了微调时使用的低秩矩阵的维度,较小的r可以减少参数数量,从而提高训练效率,但可能牺牲一定的模型表现。较小的r(例如 8-32)适用于较小模型或需要较低资源的情况,而较大的r(例如 64-128)适用于更大规模的模型。
-
alpha:是LoRA中的一个超参数,用来控制低秩矩阵的缩放因子。通过调整alpha,可以平衡低秩矩阵的影响,使模型能够在微调过程中保持足够的表达能力。16-32 是比较常见的选择,较大的alpha值通常会增加模型的表达能力,但也可能增加训练难度。
-
Dropout:是一种正则化技术,通过在训练过程中随机丢弃神经网络中的部分神经元来防止过拟合。dropout率控制丢弃的概率,较高的dropout率有助于减少模型的复杂度,从而提升其在新数据上的泛化能力。对于大多数任务,0.2-0.3 是比较常见的取值,较低的dropout值(如 0.1)适合于较小的模型,而较高的dropout值(如 0.4-0.5)适合于较大的网络,尤其是在防止过拟合时。
总结:
r:通常选择 8-128,根据任务和模型规模调整。
alpha:常见值在 16-64,推荐 16-32。
Dropout:常见值在 0.1-0.5,推荐 0.2-0.3。
task_type
在LoraConfig中的task_type是一个指定模型任务类型的参数,它帮助LoRA配置不同的微调策略,以适应特定的任务需求。task_type可以有多个选项,通常包括以下几种类型:
1、CAUSAL_LM
自回归语言建模任务,模型基于输入的部分文本(上下文)来预测下一个词,适用于生成任务,如文本生成和语言建模。
2、SEQ_CLS
文本分类任务,模型将整个输入文本分类到某个类别。常见的应用包括情感分析、垃圾邮件检测、新闻分类等。
3、SEQ_2_SEQ_LM
序列到序列的语言建模任务。该任务类型处理输入序列并生成一个输出序列。通常用于机器翻译、文本摘要等任务。
4、TOKEN_CLS
标记分类任务,模型为输入文本的每个标记(通常是词或子词)分配一个类别标签。常见应用包括命名实体识别(NER)、词性标注(POS)、依存句法分析等。
5、QUESTION_ANS
问答任务,模型根据输入的问题和上下文,提取答案。常见应用包括阅读理解、基于文档的问答等。
6、FEATURE_EXTRACTION
特征提取任务,模型提取输入数据的隐藏状态(通常是编码器的输出),这些隐藏状态可以用于下游任务,如聚类、分类或作为其他任务的输入特征。比如给定一段文本,模型输出该文本的向量表示,这些向量可以用于情感分析、推荐系统或相似度计算等任务。
bias
在LoraConfig 配置中,bias参数用于指定 LoRA 微调时如何处理偏置(bias)项。具体来说,这个参数控制了在低秩适应中,是否保留或者修改偏置项。LoRA微调一般会将权重矩阵拆分成低秩矩阵来减少训练时的计算开销,但偏置项通常会保留或处理得不同。
bias参数的常见选项:
\1. “none”:不对偏置项进行微调,也就是说,偏置项保持原样,不参与LoRA的低秩适应过程。这是默认选项,表示不修改偏置项,保持原有权重。
\2. “all”:对所有的偏置项进行微调,这意味着LoRA不仅会对权重矩阵进行低秩适应,还会对偏置项进行相应的调整。
\3. “lora_only”:仅对LoRA引入的低秩矩阵中的偏置项进行微调。即在LoRA的低秩变换部分,偏置项会被包含在内,并进行优化。
为什么选择 “none” 作为 bias 的值?
在许多LoRA微调的实现中,偏置项通常被认为是模型的一个稳定部分,尤其是在进行低秩微调时,可能并不需要对它们进行调整。使用 “none” 的选择意味着微调过程只会集中在权重矩阵的低秩部分,而不涉及偏置项的变动,这有助于减少额外的计算和参数调节,保持模型的原始结构。
如何学习大模型
下面这些都是我当初辛苦整理和花钱购买的资料,现在我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍!

四、AI大模型各大场景实战案例

五、AI大模型面试题库

六、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。

















 319
319

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









