






序列化反序列化的定义:
序列化就是把内存中的对象,转换成字节序列(或其他数据传输协议)以便于存储到磁盘(持久化)和网络传输。
反序列化就是将收到字节序列(或其他数据传输协议)或者是磁盘的持久化数据,转换成内存中的对象。
先写一个类

在java中,对应的序列化和反序列化的方法是:
1.让这个类实现 Serializable 接口,也就是在代码中补充implements Serializable。

2.序列化。新建文件输出流对象,并写入要实例化的实例。

反序列化。通过文件输入流读入文件,并使用ObjectInputStream来进一步实例化对象,然后调用readObject来生成对象。对应的代码如下

常用的Java的数据类型与Hadoop的序列化的类型对比。

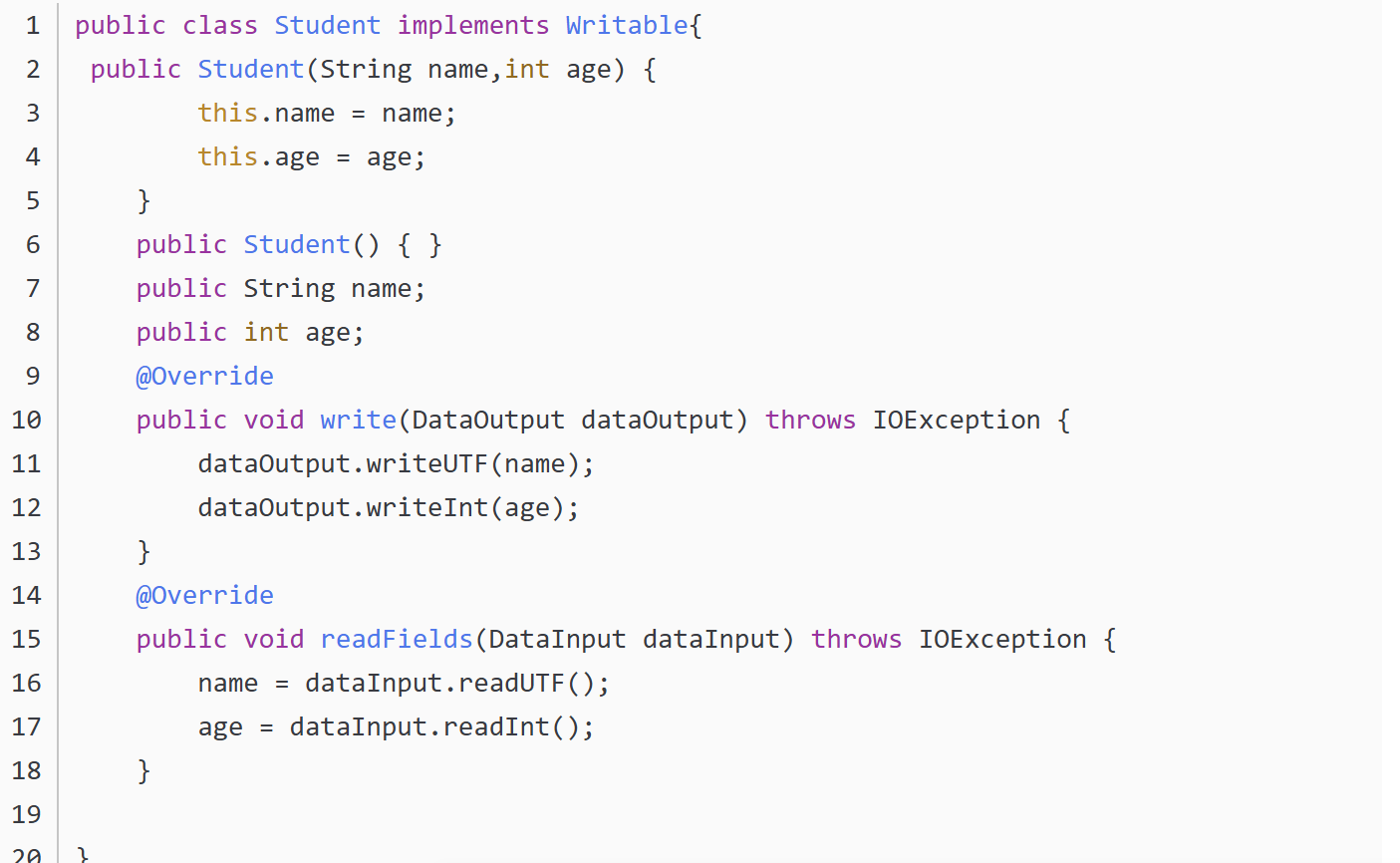
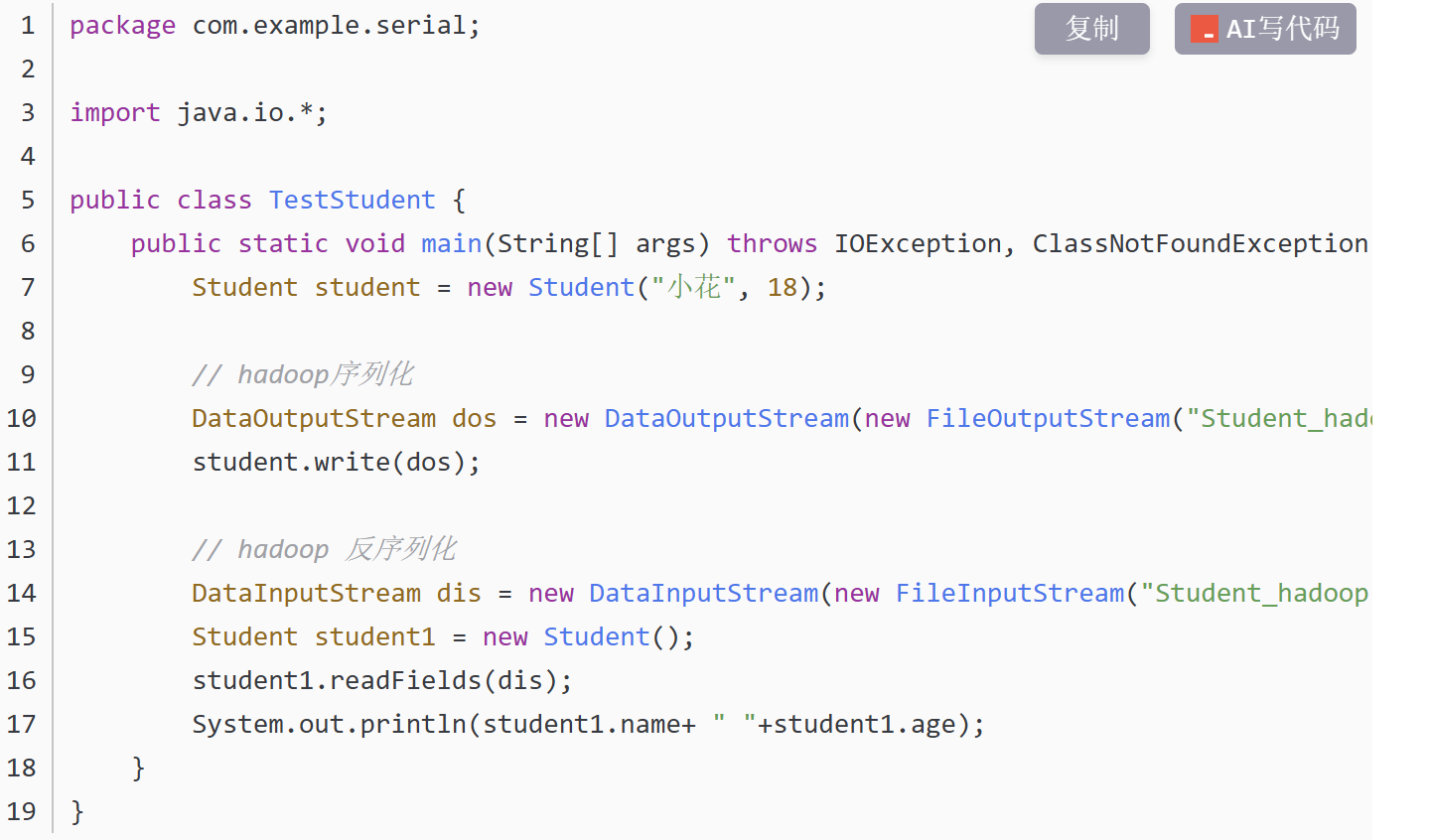
完整代码如下
Student
TestStudent

















 416
416

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









