






一、特征维度约减 (降维)
主成分分析离不开降维,那么什么是降维呢?
特征维度约减,又称降维,是指通过特征变换或者投影矩阵实现特征空间的压缩,目的是将高维特征向量映射到低维子空间中,同时使低维特征能保留原始数据的关键信息,缓解维度灾难,提升模型泛化能力。特征选择是维度约减的另一种形式。
为什么要降维?
① 大多数机器学习算法在高维空间中表现不够鲁棒,查询速度与精度随着维度增加而降低,降维能提升分类或识别的精度;(噪声消除)
② 在高维数据中,有价值的维度往往很少;(消除冗余信息)
③ 降维能够让数据的存储与检索变得高效;
④ 低维特征更容易可视化、便于理解。(增强可解释性)
降维方法主要分为线性方法,比如主成分分析 (PCA) 、线性判别分析 (LDA) ;非线性方法,比如等距映射 (Isomap) 、局部线性嵌入 (LLE) 。其中PCA是无监督方法,LDA是监督方法。
二、主成分分析简介
主成分分析 (Principal Component Analysis,PCA) 是一种常用的降维技术,属于无监督方法,用于将高维数据转换为低维表示,同时尽可能保留原始数据的关键信息。
-
核心目标:通过线性变换,将原始高维向量通过投影矩阵,投射到低维空间,重新组合成一组新向量,这些向量称为主成分,它们具有无关性、正交的特点;其中前几个主成分能够捕获原始数据的大部分方差 (即信息) 。
-
直观理解:例如,在二维平面上有一组散点数据,PCA 会找到一条 “最佳” 直线 (第一主成分),使数据在该直线上的投影方差最大;再找一条与第一条直线垂直的直线 (第二主成分),捕获剩余的方差,以此类推。
- 关键性质:① 主成分互不相关 (任意两个主成分的协方差为0) 、② 方差递减 (第一主成分的方差最大,后续主成分的方差依次递减) 、③ 降维可逆性 (在保留主要主成分的情况下,可通过逆变换近似还原原始数据) 。
三、PCA的算法流程
3.1 数据标准化
① 假设样本数为 n ,对每个特征值 (列) ,计算其均值 μ 与标准差 σ ;
eg:对特征 j (第 j 列) ,均值为: ;(遍历该列所有样本,求和后除以n)
标准差为: ;(除以 n-1 ,进行无偏估计修正)
② 对每个样本 i 的第 j 个特征,代入公式: (即减去均值、除以标准差)
把每个特征都 “缩放” 到均值为 0、标准差为 1,消除不同特征之间的量纲差异,确保各特征对结果
影响均衡。
3.2 计算协方差矩阵
对标准化后的数据矩阵 X ,计算协方差矩阵 Σ ,公式为:
是标准化数据矩阵的转置矩阵, 除以 n-1 进行无偏估计修正。
协方差矩阵描述了特征间的线性关系,对角线元素为特征 j 与自身的协方差,即 j 的方差,非对角线元素为特征 i 与特征 j 之间的协方差,其中 i ≠ j。
协方差 Cov ( i , j ) > 0 :特征 i 与 j 正相关,即一个增大,另一个倾向增大;
协方差 Cov ( i , j ) = 0 :特征 i 与 j 线性无关;
协方差 Cov ( i , j ) > 0 :特征 i 与 j 负相关,即一个增大,另一个倾向减小。
3.3 求解特征值与特征向量
对协方差矩阵做特征分解,得到特征值 (表示对应方向方差大小) 和特征向量
(代表数据
投影的 “新坐标轴方向” )特征值和特征向量满足等式: 。
含义:用协方差矩阵 Σ 对向量 做线性变换后,结果相当于对
进行 “数乘缩放”,缩放系数就是
。
如果原始数据是 d 维,那么就有 d 个特征值 ; 越大,表示方差越大,说明这个方向 “包含的信息越多” ;不同特征值对应的特征向量天然正交 (协方差矩阵是对称矩阵的性质) 。
3.4 选择主成分
① 将所有特征值按从大到小排序 (假设有 d 个特征) ;
② 单个主成分的解释方差比例:第 i 个主成分 (对应第 i 大的特征值 ) ,它的解释方差比例
公式为: ;
③ 累计解释方差比例:把前 k 个主成分的解释方差比例相加,公式:
它衡量的是前 k 个主成分总共能 “解释” 原始数据方差 (信息) 的百分比;
④ 找到最小的 k ,让累计解释方差比例 ≥ 预设阈值 (常见90%、95%,可根据需求调整) ,然后选取前 k 个特征值对应的特征向量作为主成分,k 即为降维后的维度。
3.5 数据投影
选定的主成分按列构成矩阵 ( d × k 矩阵) ,这个矩阵就定义了一个从原始高维空间到低维空间的映射关系,用它对原始数据作线性变换,设降维后的矩阵为 Z ,则有
。
这样就实现了将标准化后的 n × d 维数据矩阵 X (n个样本,d个特征) ,通过线性变换投影到由前 k 个特征向量组成的 k 维子空间中,降维矩阵 Z 是一个 n × k 维矩阵,Z 的第 i 行第 j 列元素表示第 i 个样本在第 j 个主成分上的投影值。
四、示例:人脸识别
4.1 数据加载和预处理
给定数据集:大文件夹为ORL_Faces,包含40个子文件夹 (s1,s2...) ,每个文件夹存放了同个人不同角度的十张灰度人脸图像,数据集展示结果:
遍历每个子目录 (s1~s40) ,读取每张PGM格式图像,将图像转换为灰度图并展平为一维数组(112×92=10304个像素) ,构建数据集faces ( 形状:[400,10304] ) 和标签 labels ( 形状:[400] ) ,使用train_test_split按一定比例将数据集划分为训练集和测试集 ( 默认75%为训练集、25%为测试集 )。
4.2 模型训练和方差分析
模型训练:初始化 PCA 模型,保留若干个主成分 (这里保留 150 个) 并应用白化处理 (whiten=True),通过过 sklearn 提供的 fit_transform 方法计算训练集的主成分并转换数据。
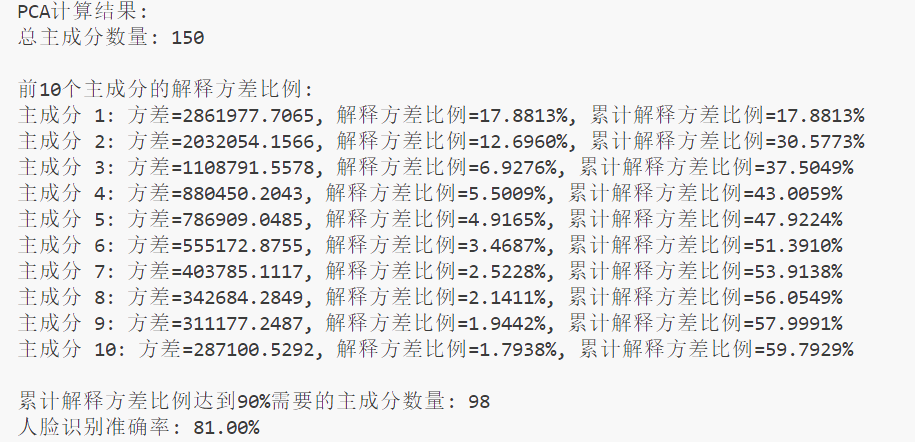
方差分析:计算每个主成分的解释方差比例,再计算前 k 个主成分的累积方差比例,设定阈值为90%,计算达到 90% 累积方差所需的主成分数量。
4.3 结果可视化
PCA 的components_ 属性包含前若干个 (前面保留的主成分数目,这里为150) 主成分,每个主成分是一个长度为10304的向量,将这些向量重塑为112×92的图像矩阵,即 “特征脸” ,使用 matplotlib绘制特征脸(可以根据需求决定绘制的特征个数和排列方法,这里设置为绘制10个特征脸,按2行5列排列) ,每个特征脸代表数据集中的一种主要变化模式 ( 如光照、面部轮廓等 ) 。
通过 pca.transform 将训练集投影到低维空间 (150 维 ) ,通过 pca.inverse_transform 将降维后的数据恢复到原始空间 (10304 维 ) ,可视化原始人脸与重建人脸的对比,验证降维过程中的信息保留程度。
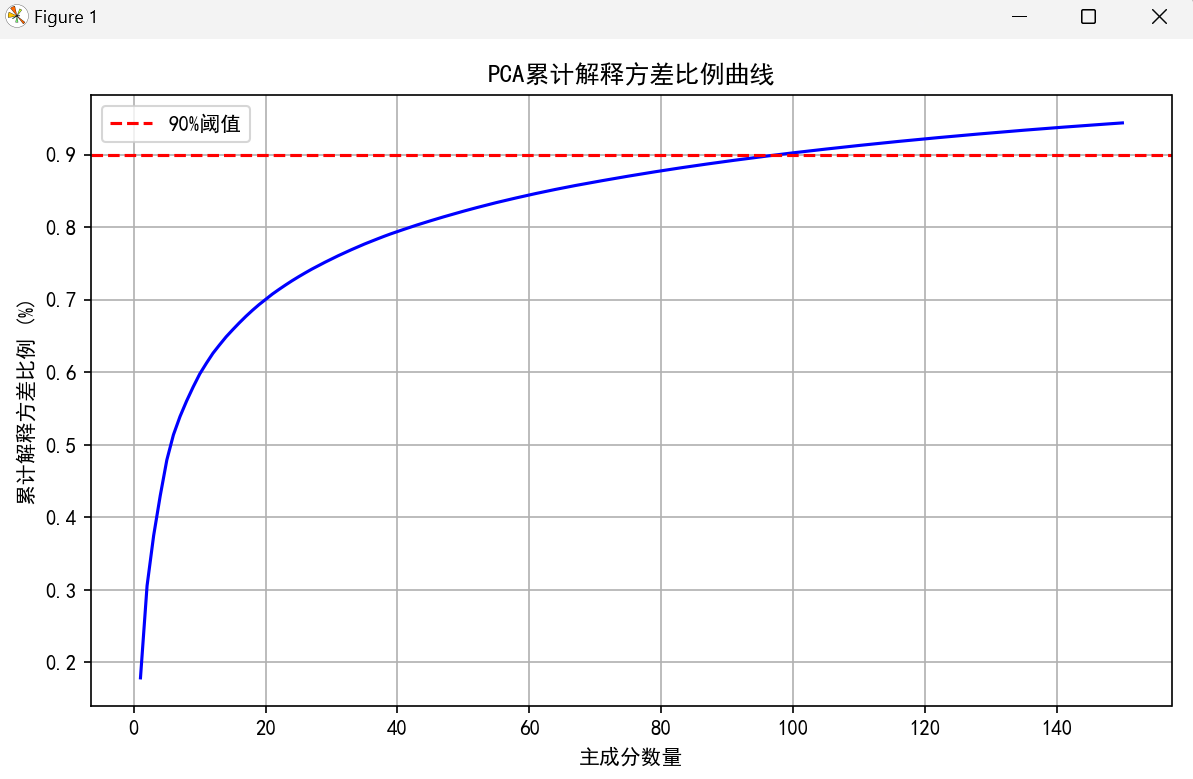
绘制主成分数量与累积方差比例的关系曲线,直观展示降维效果,例如,如果 60 个主成分即可解释 90% 的方差,说明原始数据中的大部分信息可由少数特征表示;打印主成分的解释方差比例和累积方差比例 (这里只打印前10个) ,输出达到 90% 累积方差所需的主成分数量,辅助选择合适的 k 值。
4.4 降维后的人脸识别模型训练与评估
使用 K 近邻分类器,设置 k = 1 ,在 PCA 降维后的训练数据上训练模型,在测试集上进行预测并计算准确率,高准确率表明 PCA 有效提取了人脸的关键特征,即降低维度的同时成功保留了判别信息。
4.5 代码实现
import os
import numpy as np
from PIL import Image
from sklearn.decomposition import PCA
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
import matplotlib.pyplot as plt
#设置中文,解决负号显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams["axes.unicode_minus"] = False
#加载人脸图像数据
def load_faces(data_dir):
faces, labels = [], []
for person_id in range(1, 41):
person_dir = os.path.join(data_dir, f"s{person_id}")
if not os.path.exists(person_dir):
continue
for img_id in range(1, 11):
img_path = os.path.join(person_dir, f"{img_id}.pgm")
try:
img = Image.open(img_path).convert('L')
faces.append(np.array(img).flatten())
labels.append(person_id)
except:
continue
return np.array(faces), np.array(labels)
#绘制特征脸
def plot_eigenfaces(eigenfaces, shape, n=10):
fig, axes = plt.subplots(2, 5, figsize=(8,5))
for i, ax in enumerate(axes.flat):
ax.imshow(eigenfaces[i].reshape(shape), cmap='gray')
ax.set_title(f'特征脸 {i+1}', fontsize=9)
ax.axis('off')
plt.tight_layout()
plt.suptitle('前10个特征脸', fontsize=12)
plt.subplots_adjust(top=0.9) #为标题留出空间
plt.show()
#对比原始人脸和重建人脸
def plot_reconstruction(original, reconstructed, shape, n=5):
fig, axes = plt.subplots(2, n, figsize=(8,5))
for i in range(n):
axes[0, i].imshow(original[i].reshape(shape), cmap='gray')
axes[1, i].imshow(reconstructed[i].reshape(shape), cmap='gray')
axes[0, i].set_title('原始', fontsize=9)
axes[1, i].set_title('重建', fontsize=9)
axes[0, i].axis('off')
axes[1, i].axis('off')
plt.tight_layout()
plt.suptitle('人脸重建对比', fontsize=12)
plt.subplots_adjust(top=0.9) #为标题留出空间
plt.show()
#绘制PCA累计解释方差比例曲线
def plot_variance_curve(pca):
explained_variance = pca.explained_variance_ratio_
cumulative_variance = np.cumsum(explained_variance)
plt.figure(figsize=(8, 5))
plt.plot(range(1, len(cumulative_variance) + 1), cumulative_variance, 'b-')
plt.axhline(y=0.9, color='r', linestyle='--', label='90%阈值')
plt.xlabel('主成分数量')
plt.ylabel('累计解释方差比例 (%)')
plt.title('PCA累计解释方差比例曲线', fontsize=12)
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
#打印PCA计算结果统计信息
def print_pca_statistics(pca):
explained_variance = pca.explained_variance_
explained_variance_ratio = pca.explained_variance_ratio_
cumulative_variance = np.cumsum(explained_variance_ratio)
print("PCA计算结果:")
print(f"总主成分数量: {len(explained_variance)}")
print("\n前10个主成分的解释方差比例:")
for i in range(min(10, len(explained_variance))):
print(f"主成分 {i+1}: 方差={explained_variance[i]:.4f}, 解释方差比例={explained_variance_ratio[i]:.4%}, 累计解释方差比例={cumulative_variance[i]:.4%}")
n_components_90 = np.argmax(cumulative_variance >= 0.9) + 1
print(f"\n累计解释方差比例达到90%需要的主成分数量: {n_components_90}")
def main():
#数据目录路径
data_dir = r'C:\Users\阿蒲\Desktop\机器学习数据\ORL_Faces'
#加载数据
faces, labels = load_faces(data_dir)
img_shape = (112, 92)
#划分数据集
X_train, X_test, y_train, y_test = train_test_split(
faces, labels, test_size=0.25, random_state=42 )
#PCA降维
pca = PCA(n_components=150, whiten=True)
X_train_pca = pca.fit_transform(X_train)
X_test_pca = pca.transform(X_test)
#打印PCA统计信息
print_pca_statistics(pca)
#可视化特征脸
plot_eigenfaces(pca.components_, img_shape)
#可视化重建效果
X_train_reconstructed = pca.inverse_transform(X_train_pca)
plot_reconstruction(X_train, X_train_reconstructed, img_shape)
#绘制方差贡献率曲线
plot_variance_curve(pca)
#训练分类器
knn = KNeighborsClassifier(n_neighbors=1)
knn.fit(X_train_pca, y_train)
#评估模型
accuracy = knn.score(X_test_pca, y_test)
print(f"人脸识别准确率: {accuracy:.2%}\n")
if __name__ == "__main__":
main()运行测试结果截图:


五、实验小结
PCA可以通过降维,实现噪声过滤、数据压缩、线性结构提取等,因此可以应用在多种场景,比如图像处理与计算机视觉、金融与经济数据分析、生物信息学与基因表达分析、自然语言处理与文本分析、工业与传感器数据处理。
优点:
① 无监督学习,无需标签数据;
② 降低数据复杂性,识别最重要的多个特征;
③ 计算效率高,适用于大规模数据;
④ 可解释性较强,通过特征值和特征向量分析数据结构。
缺点:
① 假设数据具有线性关系,对非线性结构处理效果差;
② 主成分的实际物理意义可能不明确 (尤其在复杂数据中) ;
③ 对异常值敏感,标准化处理可部分缓解;
④ 可能损失有用信息。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









