







一.逻辑回归求解二分类问题
本讲将介绍分类模型。对于二分类模型,我们将介绍逻辑回归和Fisher线性判别分析两种分类算法;对于多分类模型,我们将简单介绍SPSS中的多分类线性判别分析和多分类逻辑回归的步骤。
我们以一个水果分类的例子引入内容。

这个例子的大体意思是给了我们42个水果样本,其中,每个样本都有5个属性,包括水果重量,水果的宽度,水果的高度,水果的颜色数值,范围0-1和水果的类别。根据每个样本间这5个属性的不同,可将这42个样本大体分为两类,一类是苹果,一类是橙子。其中,前19个样本已被确定是苹果,后19个样本被确定是橙子,后面4个样本的分类情况是未知的,我们要用这38个样本去预测后四个样本对应的水果种类。
这个例子就是一个简单的二分类模型,我们把数据导入到SPSS中,在SPSS中进行数据的分析和求解。其中,前4个属性都是定量变量,最后一个水果的类别是定性变量,我们在进行数据预处理时应先建立水果类别的虚拟变量。通过SPSS我们可以很方便的建立虚拟变量,我们令虚拟变量等于1的水果类别为苹果,而虚拟变量值等于0的水果类别为橙子。
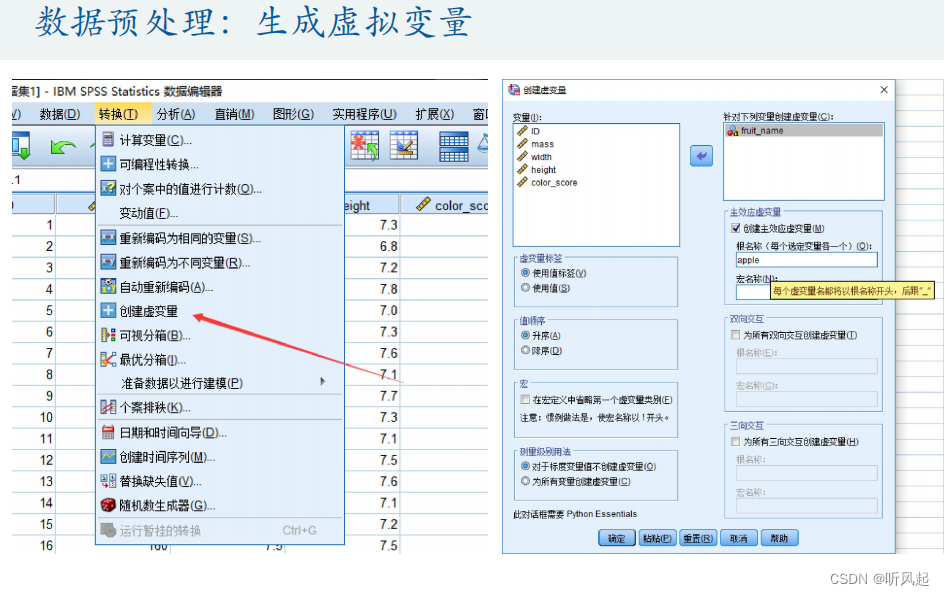

在多元线性回归中,我们曾提到过,根据Y的类型不同,我们有不同的回归类型。在这里,被解释变量是我们水果类别的虚拟变量,是一个二值变量,因此,我们应建立0-1回归,而0-1回归的模型就是逻辑回归。
通过建立回归模型,我们可以完成一定情况的预测。在得出各个解释变量的回归系数后,我们可将被预测样本的解释变量带入我们建立的回归模型中,就可以得出y的估计值。由于y在这里是一个二值变量,因此,我们可以把y看成是事件发生的概率,当y大于等于0.5时就表示发生,y小于0.5时表示不发生。对应到我们的例子中,即最后估计出的y值大于0.5时,我们就认为它是苹果,否则为橙子。

逻辑回归可以依靠线性概率模型进行回归。线性概率模型可直接用原来的线性回归模型进行回归。其中,u是扰动项,整个回归的式子可以写成向量乘积的形式,x是解释变量的向量,β是回归系数矩阵。与原来不同的是,这里的被解释变量y的值只能取0或1,这就引起了内生性问题,导致预测值可能会出现y>1或y<1这种不现实的情况。

那么我们肯定要想办法取解决内生性引起的问题。这里,我们先来介绍一下高中学过的两点分布,可见,两点分布与我们的二值变量y有着极高的相似性,可将y看作是事件1,理解为是y=1发生的概率。这里比较抽象。在给定x的情况下,考虑y的两点分布概率,这样就成功地将y的值限制在0-1。我们将y的两点分布概率称为连接函数。简单的理解就是我们定义一个连接函数,这个函数通过相乘或一些计算与我们的y的估计值进行关联,使最终y的估计值限制在0-1之内。

通过连接函数,我们就可以成功解决由于内生性引起的问题。这又牵扯出了一个问题,那就是我们连接函数怎么取才合适。ppt中给出了我们两种取法,一是取标准正态分布的累计密度函数;二是取为Sigmoid函数。而其中,第一种取法我们建立的回归称为probit回归;第二种取法我们建立的回归称为logistic回归 。又因为后者有解析表达式,而前者牵扯到了积分运算,所以计算logistic模型比probit模型更加方便。
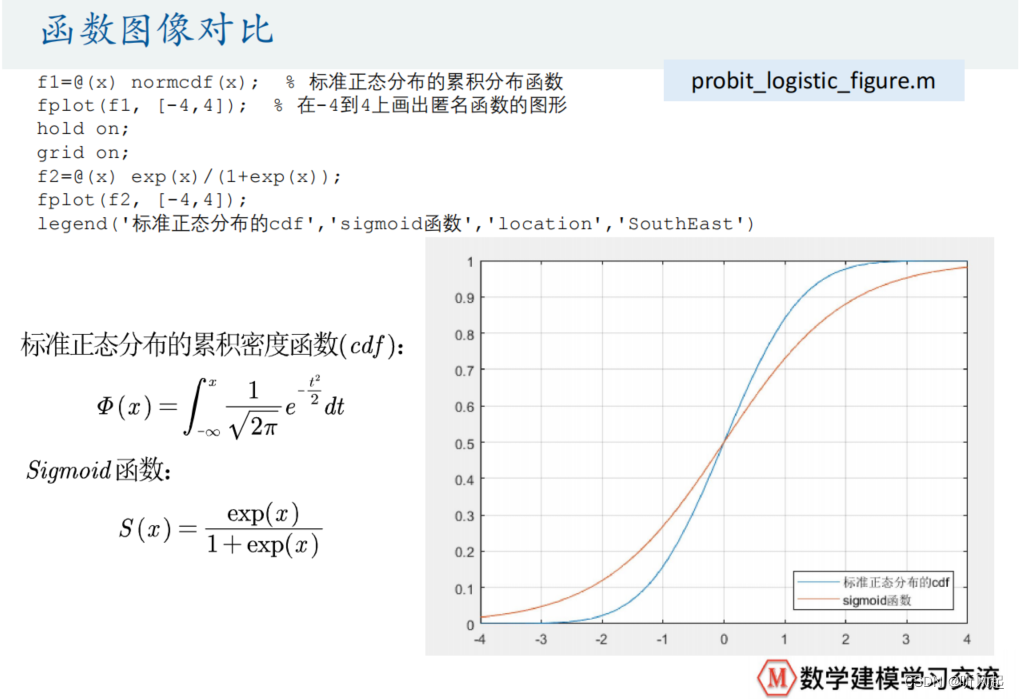
分别给出了标准正态分布和sigmoid函数的累积密度函数的函数图像。观察图像我们可以发现,两个函数都在0-1之内,满足了我们需要的连接函数的条件。

这样就成功的建立了逻辑回归模型。接下来的问题就是求解逻辑回归了,怎样求解回归系数,怎样求解被解释变量的估计值,这里,求解逻辑回归的原理仅供我们了解即可,重要的是我们使用SPSS应用逻辑回归。我们求解逻辑回归的原理是极大似然估计,这里我们不做详细介绍具体求解的推导步骤,因为十分复杂,感兴趣的话可以参考ppt中网址。

求解出逻辑回归后,重要的是把逻辑回归应用到我们的分类中。如我们之前所说,如果我们求解出的y的估计值大于0.5,那么就认为我们预测的y=1,否则则认为其预测的y=0;
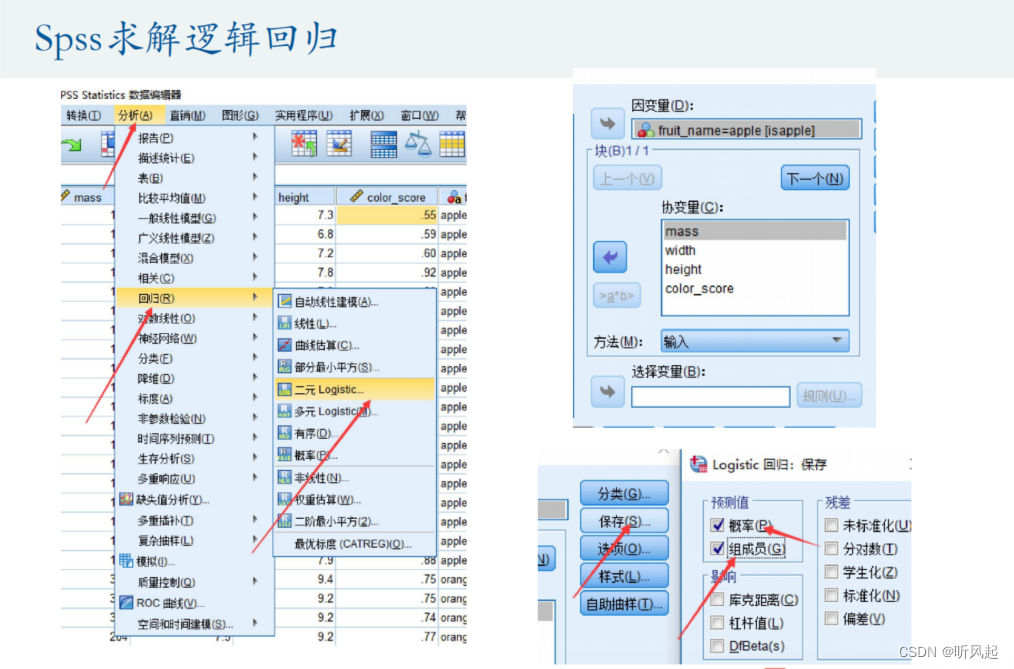
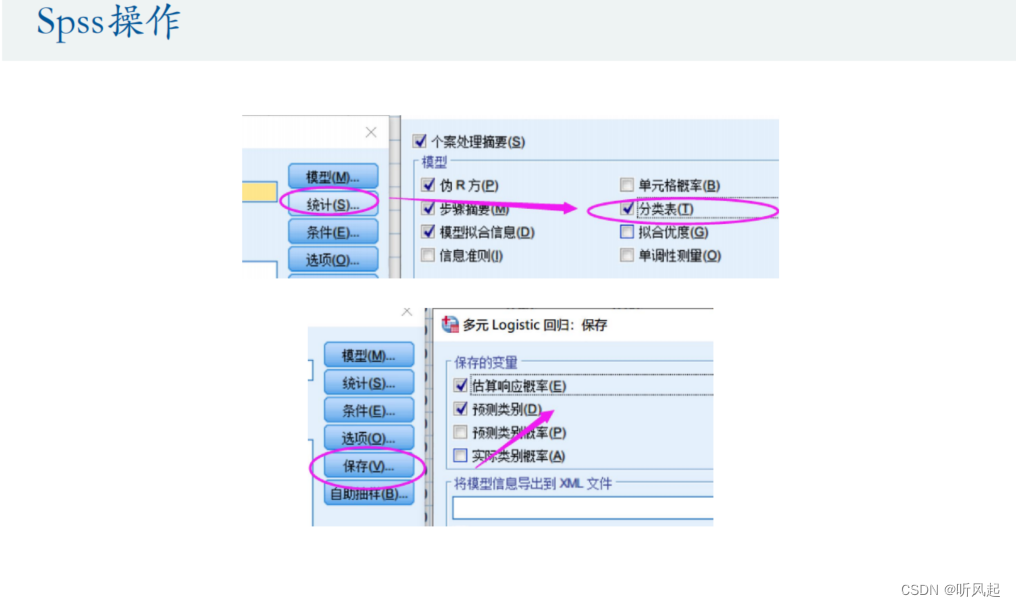
在这里仅给出SPSS求解逻辑回归的大概步骤,具体操作以实际操作为准。
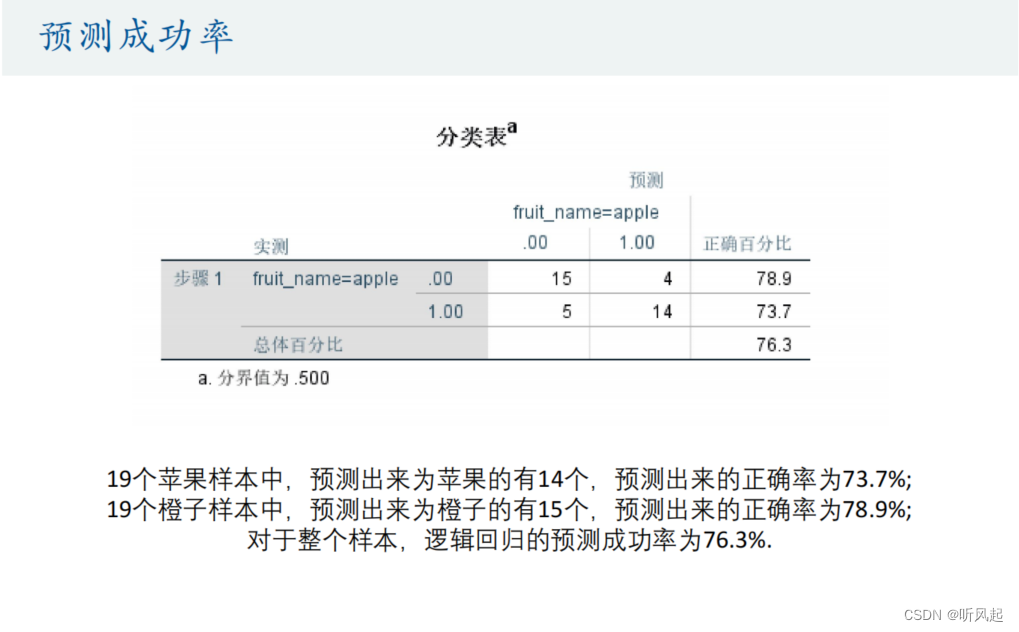
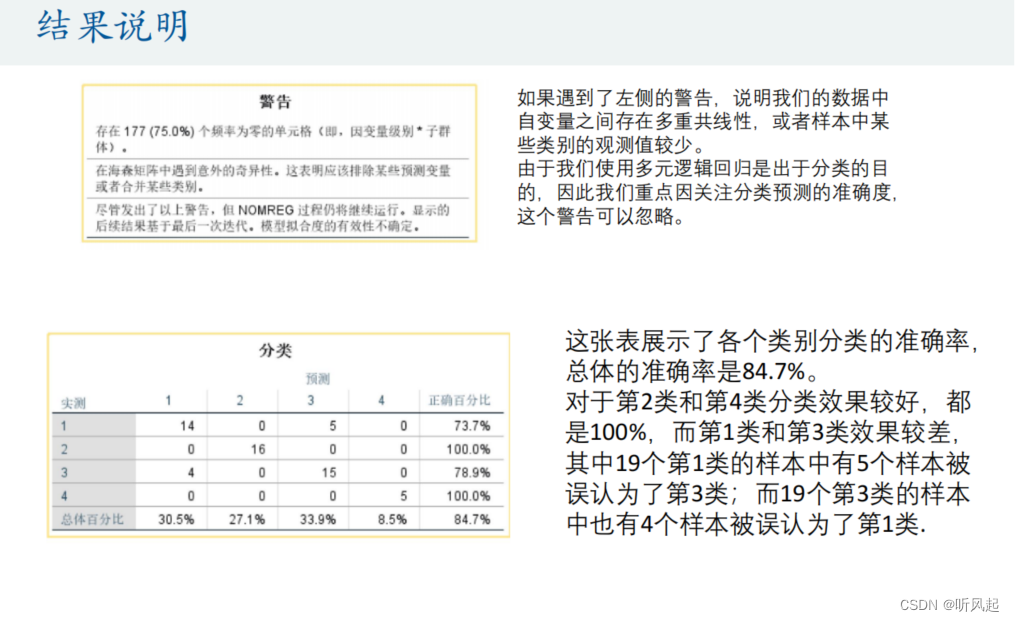
这是最后SPSS给我们输出的预测成功率的图表。在预测未知样本的数据之前,我们先观察实际的情况与预测的情况的比较。在19个苹果样本中,预测出来为苹果的有14个;在19个橙子样本中,预测出来为橙子的有15个,最后对于整个样本,逻辑回归的预测成功率为76.3%,可见,我们预测的情况并不是100%正确的,这与现实中的预测情况也相符。
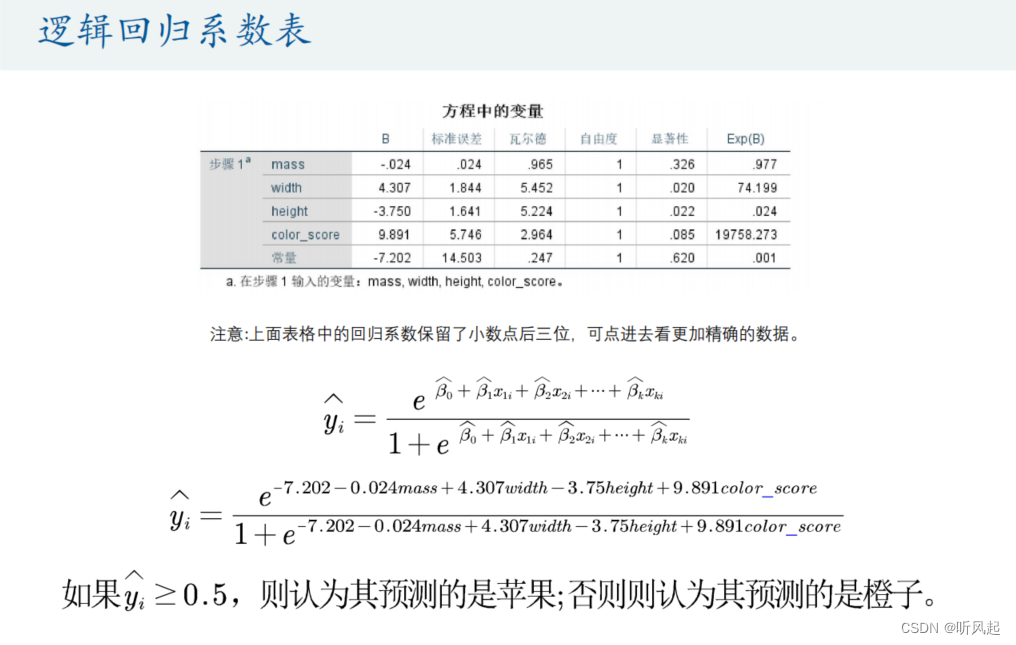
SPSS还给我们提供了各个解释变量的回归系数。其实,得到了回归系数之后,我们便可将样本数据带入回归表达式中手动去计算被解释变量的预测值。经事实考察,我们手动计算的预测值与SPSS输出给我们的预测值相符。
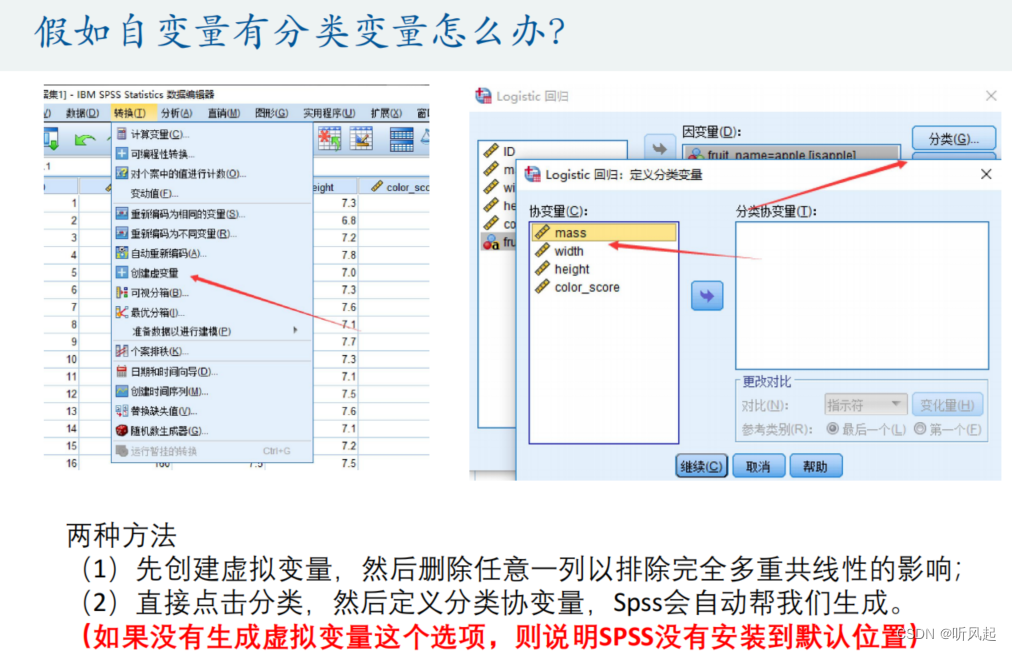
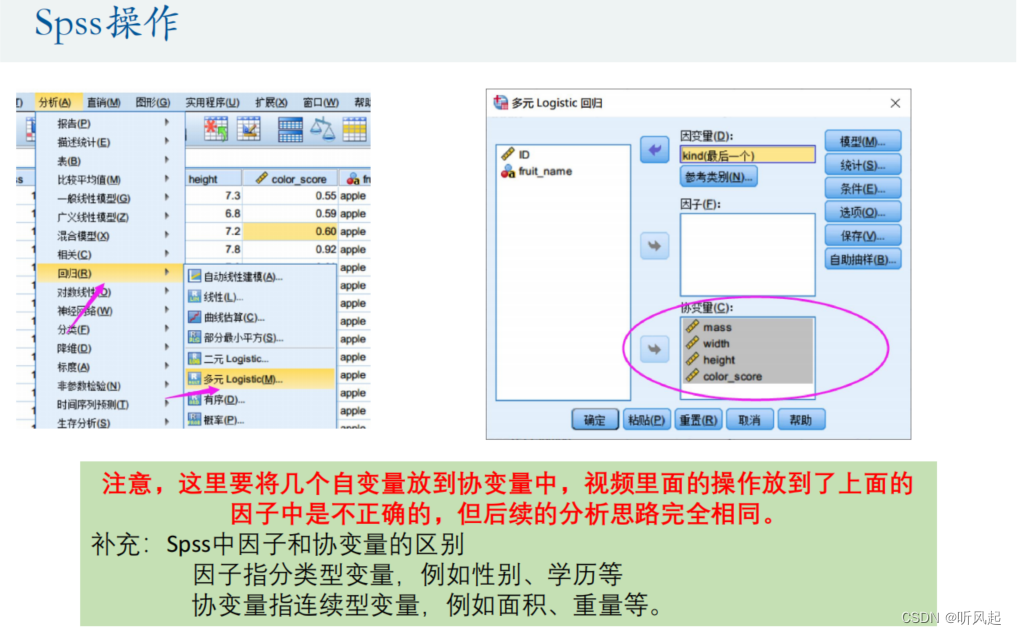
这里,SPSS也给我们提供了应对自变量有分类变量的解决方式。因为我们的自变量并不总是定量变量,如果是定性变量,我们在建立回归之前需先将定性变量转化为虚拟变量。而SPSS可以十分方便地在建立回归时自动将定性变量转化为虚拟变量,同时可自动避免完全多重共线性地影响。
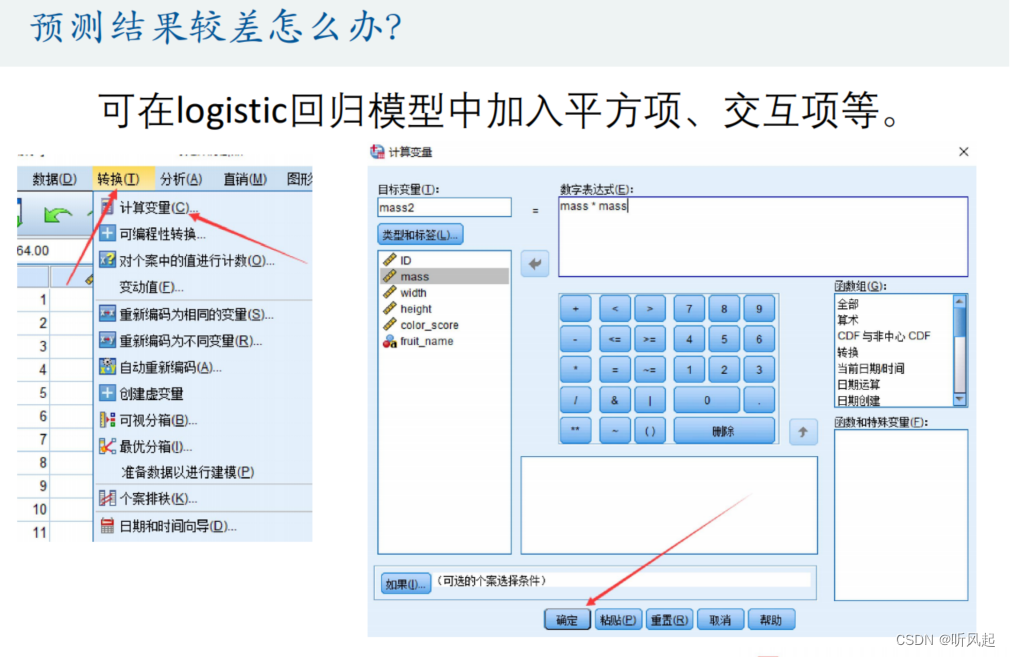
在之前我们注意到,我们最终预测出来的成功率并不是100%,如果我们想追求成功率的话,就需要改进我们的模型,也即训练我们的模型。其中,提供给我们一种方法就是在逻辑回归时加入自变量的平方项或交互项。
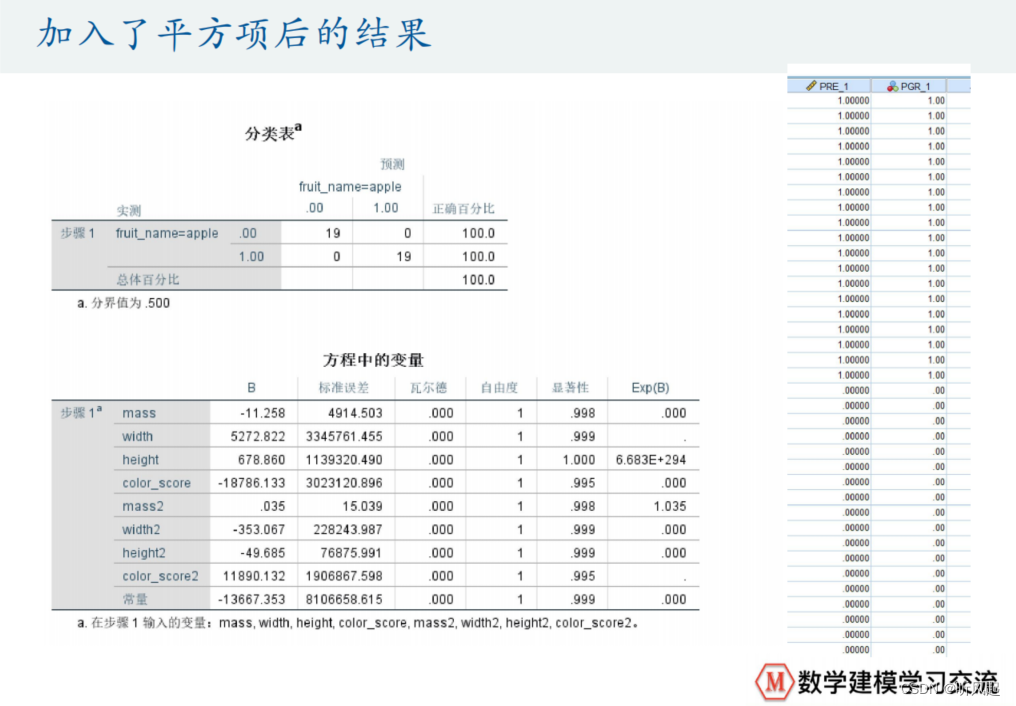
这是我们加入了平方项之后预测的结果,可见成功率达到了100%,当然,这是有偶然性的,一般我们预测的成功率并不会是100%。
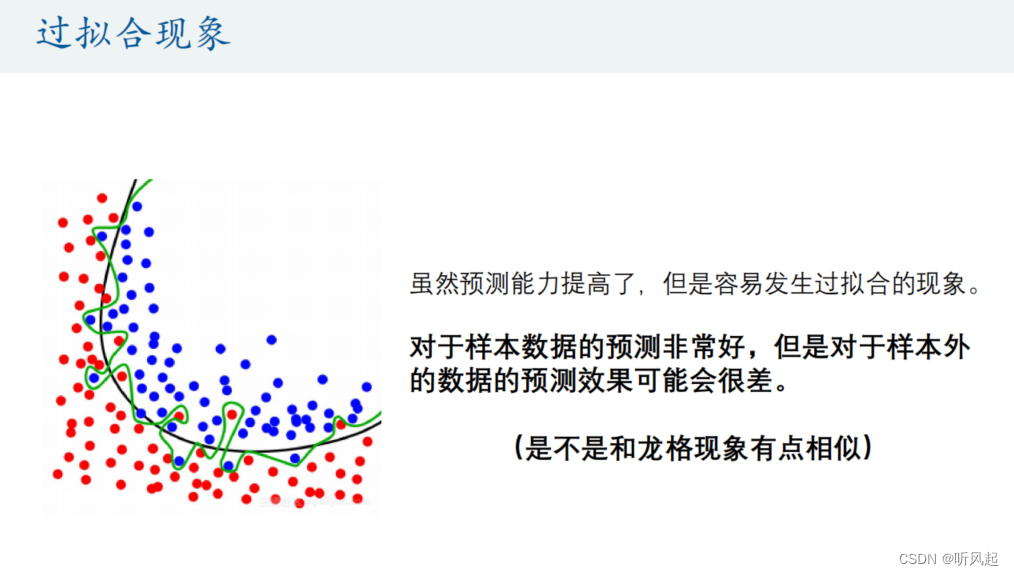
这里我们提出一个新的概念叫过拟合现象。那么什么是过拟合现象呢?我们先来看图片上黑线是我们第一次预测的结果,可见预测的准确率并不是100%的,没有完全的将红色点与蓝色点分开。绿线是我们第二次在模型中加入了自变量的平方项之后得到的预测结果,可见这是多么的恐怖,歪歪扭扭的。这里就指出来了我们的预测能力提高了,但是容易发现过拟合的现象。这就提示我们不能一味地去追求预测的准确率,因为要提高预测的准确率,就需要向模型中加入越多的自变量的平方项或交互项之类的,这会使我们的模型越来越复杂,最终会导致我们对于样本外的数据的预测效果可能会很差。

那么,为了达到一个相对来说好的结果,就需要我们确定合适的模型 ,这也就是我们训练模型的步骤。这里我们直接参考ppt中的步骤去训练我们的模型即可。
二.Fisher线性判别分析和多分类问题探究
这里,我们给出另一种求解二分类问题的方法,就是Fisher线性判别分析。
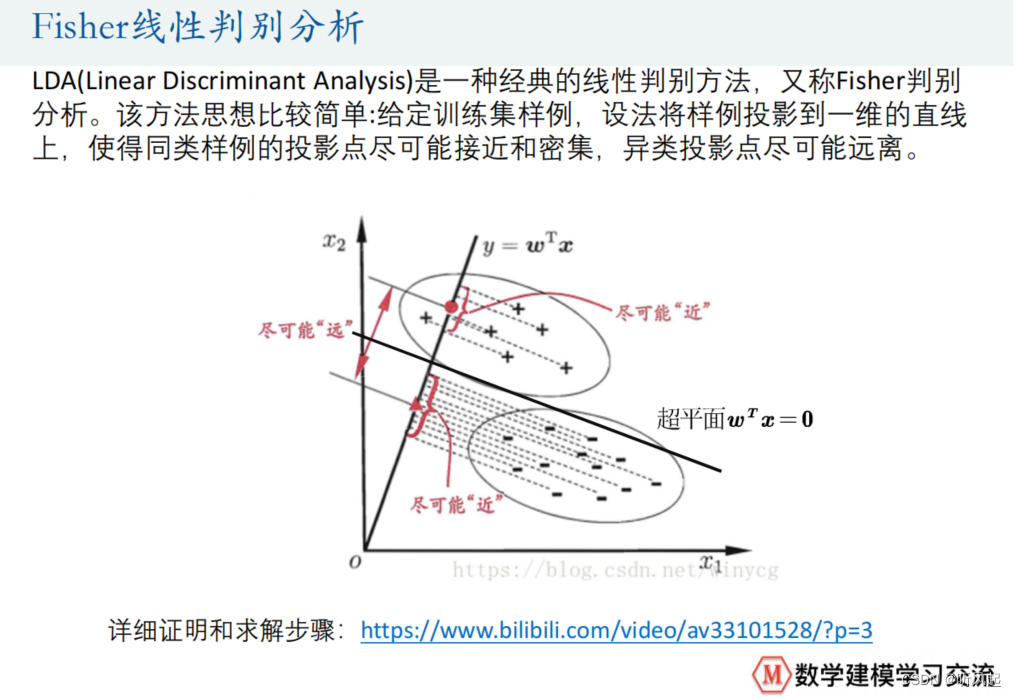
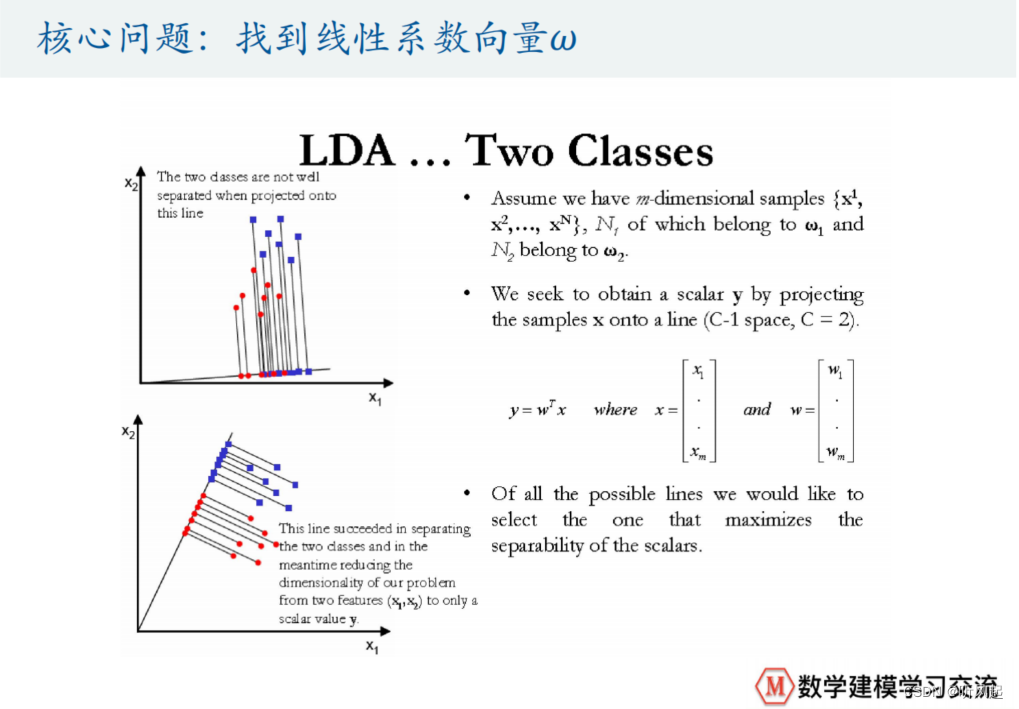
同样,这里我们仅侧重于使用SPSS求解即可,具体的理论推导我们不作深究,感兴趣的可以观看ppt中网址的视频。理论上最后分析的结果就是通过一个超平面,将我们的两类样例点给分开。因此,在这个方法里,最重要的问题就是找到我们的超平面。
那么,怎么找这个超平面呢?这又涉及到了一系列难懂晦涩的理论推导,如计算找出平面对应的法向量啥的,这里我们也不做详细探讨。

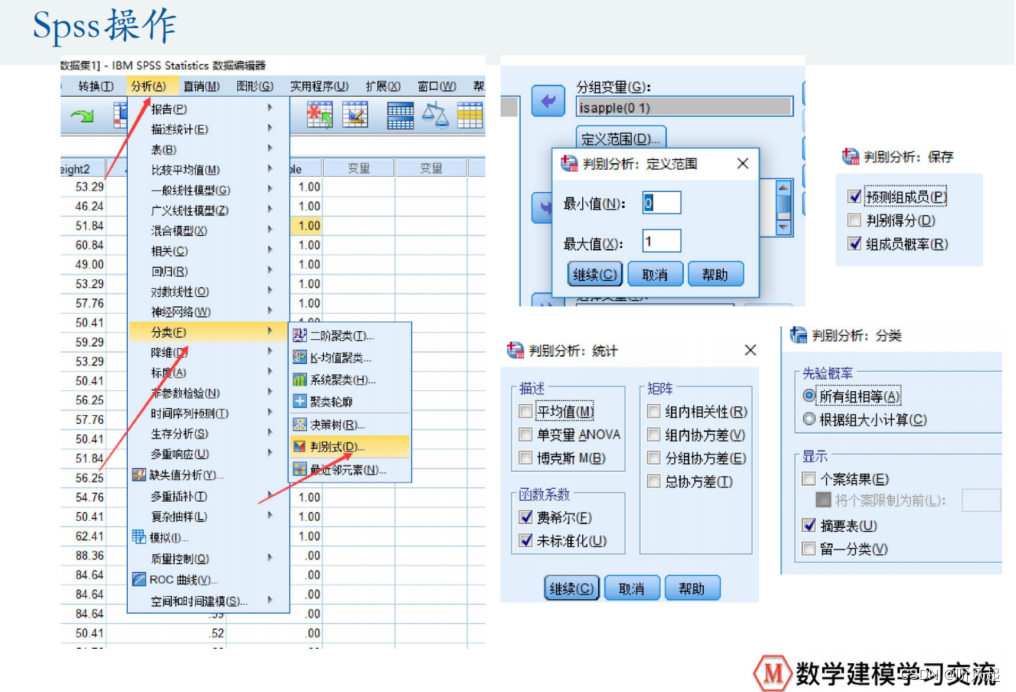
直接给出我们使用SPSS使用Fisher线性判别分析的步骤。
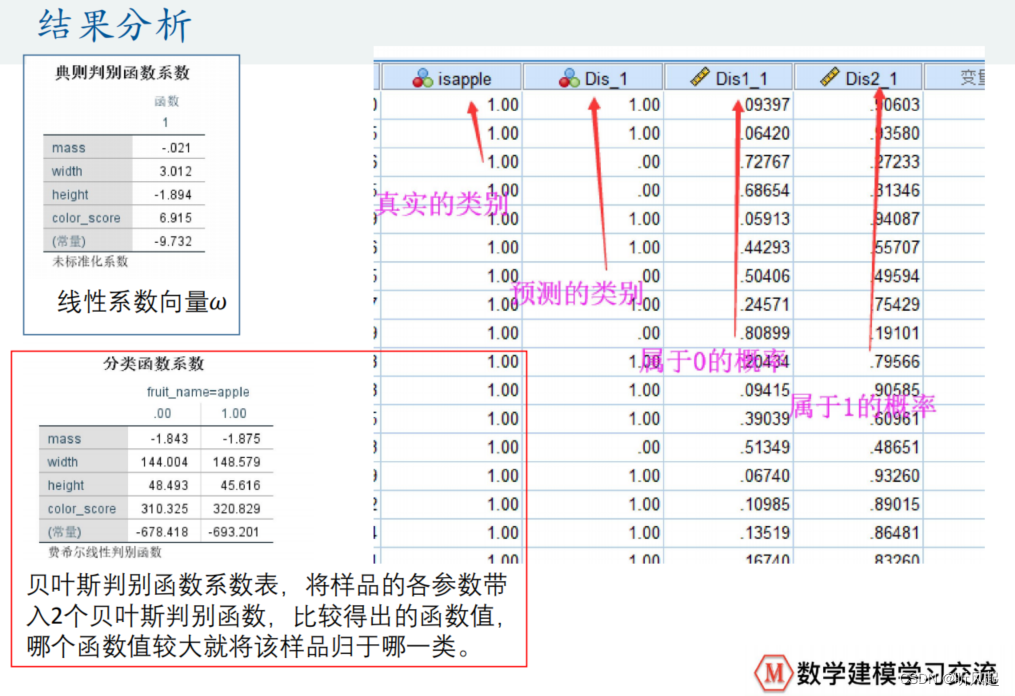
接着,我们来进行多分类问题的探究。
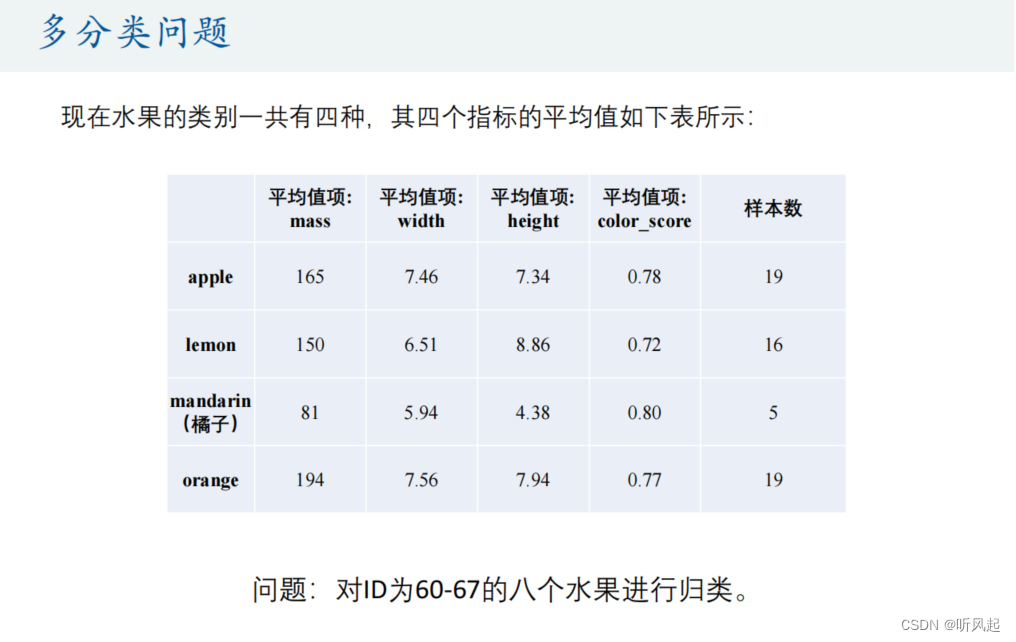
多分类问题也就是在二分类问题的基础上,多加入了几种分类类别而已。对于求解多分类问题,我们仍可以使用Fisher线性判别分析。
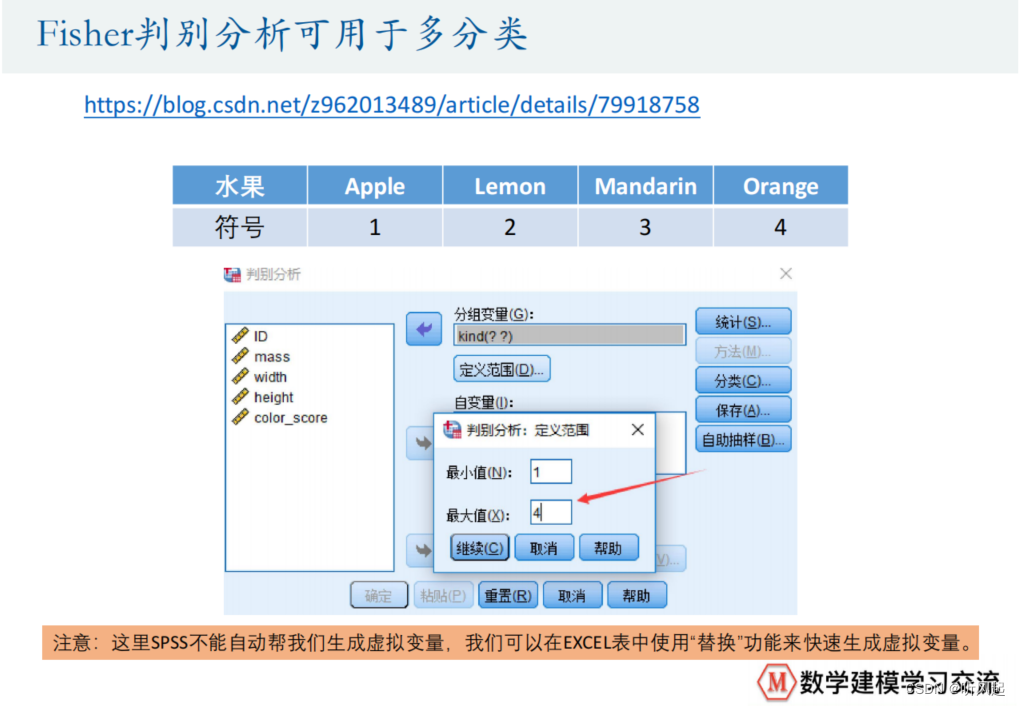
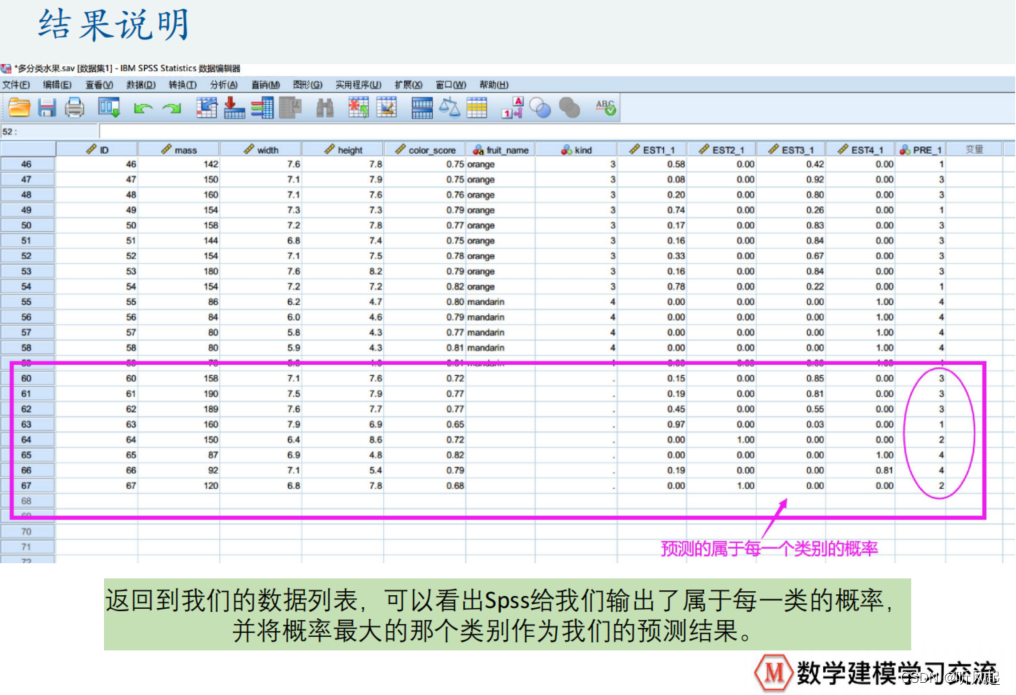
这里,我们仍然对定性变量建立了虚拟变量。如果预测出y的值等于1,就认为是苹果,等于2,认为是柠檬,等于3,认为橙子,等于4,认为是橘子。
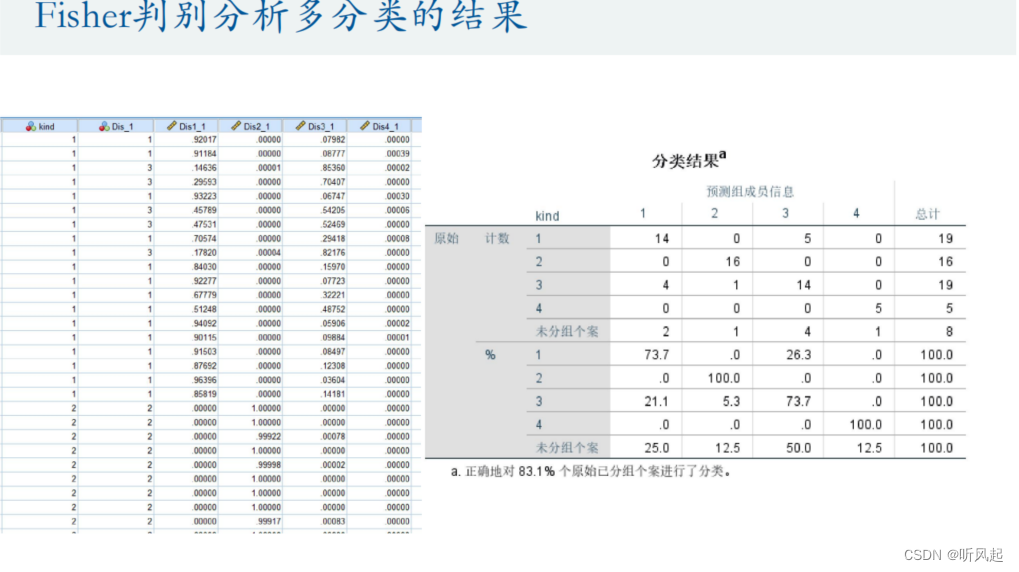
我们重点关注Fisher线性判别分析多分类问题为我们给出的结果。观察分类结果可知,正确的对83.1%个原始已分组的个案进行了分类。
但其实,我们的逻辑回归也可以用来求解多分类问题。
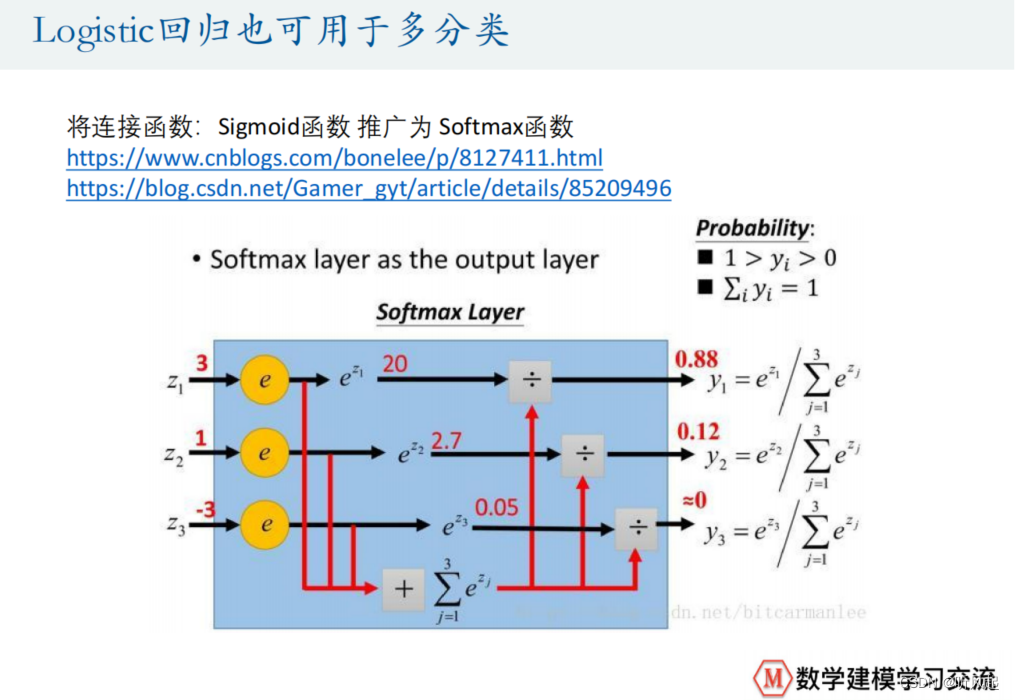
需注意的是,之前我们使用逻辑回归求解二分类问题时,使用的连接函数是Sigmoid函数,而在多分类问题中,我们需将Sigmoid函数替换为Softmax函数。
重要的是应用,我们有关算法的原理有一概不展开探究。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









