







赛项介绍
赛题以银行产品认购预测为背景,想让你来预测下客户是否会购买银行的产品。评价标准: Accuracy (所有分类正确的百分比)
数据准备
数据集的下将数据下载到自己的文件便于取用。
地址:【教学赛】金融数据分析赛题1:银行客户认购产品预测_学习赛_赛题与数据_天池大赛-阿里云天池的赛题与数据
参赛代码
1.导包及数据查看
import pandas as pd
import numpy as np
df=pd.read_csv("/train.csv")
test=pd.read_csv("/test.csv")
df['subscribe'].value_counts()
- 导入 pandas 库,并将其命名为 pd。
- 导入 numpy 库,并将其命名为 np。
- 使用 pandas 的 read_csv 函数读取名为 "train.csv" 的文件,并将其存储在变量 df 中。
- 使用 pandas 的 read_csv 函数读取名为 "test.csv" 的文件,并将其存储在变量 test 中。
- 计算 df 数据框中 'subscribe' 列的值的数量,并返回每个值的数量。
import matplotlib.pyplot as plt
import seaborn as sns
bins = [0, 143, 353, 1873, 5149]
df1 = df[df['subscribe'] == 'yes']
binning = pd.cut(df1['duration'], bins, right=False)
time = pd.value_counts(binning)
# 可视化
time = time.sort_index()
fig = plt.figure(figsize=(6, 2), dpi=120)
sns.barplot(x=time.index, y=time, color='royalblue') # 更新此行代码,指定x和y参数
x = np.arange(len(time))
y = time.values
# 做百分比
for x_loc, jobs in zip(x, y):
plt.text(x_loc, jobs + 2, '{:.1f}%'.format(jobs / sum(time) * 100), ha='center', va='bottom', fontsize=8)
plt.xticks(fontsize=8)
plt.yticks([])
plt.ylabel('')
plt.title('duration_yes', size=8)
sns.despine(left=True)
plt.show() 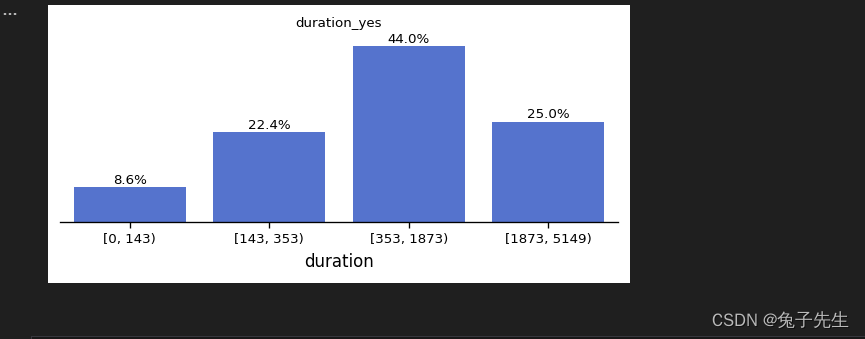
导入matplotlib.pyplot和seaborn库,用于绘图。定义一个bins列表,用于将持续时间分为四个区间。从原始数据中筛选出订阅为"yes"的数据,并将其存储在df1中。使用pd.cut()函数将df1中的持续时间数据按照bins进行分组,并将结果存储在binning中。使用pd.value_counts()函数统计每个分组的数量,并将结果存储在time中。对time进行排序,以便在绘制柱状图时按照正确的顺序显示。创建一个图形对象,并设置其大小和分辨率。使用seaborn的barplot()函数绘制柱状图,其中x参数为time的索引,y参数为time的值,颜色设置为'royalblue'。计算x轴的位置和对应的值,并在柱状图上添加文本标签,显示每个柱子的百分比。设置x轴和y轴的刻度字体大小,隐藏y轴标签,设置标题为'duration_yes'。使用seaborn的despine()函数移除左侧和底部的边框。最后,使用plt.show()函数显示图形。
# 分离数值变量与分类变量
Nu_feature = list(df.select_dtypes(exclude=['object']).columns)
Ca_feature = list(df.select_dtypes(include=['object']).columns)
#查看训练集与测试集数值变量分布
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
plt.figure(figsize=(20,15))
i=1
for col in Nu_feature:
ax=plt.subplot(4,4,i)
ax=sns.kdeplot(df[col],color='red')
ax=sns.kdeplot(test[col],color='cyan')
ax.set_xlabel(col)
ax.set_ylabel('Frequency')
ax=ax.legend(['train','test'])
i+=1
plt.show()
# 查看分类变量分布
Ca_feature.remove('subscribe')
col1=Ca_feature
plt.figure(figsize=(20,10))
j=1
for col in col1:
ax=plt.subplot(4,5,j)
ax=plt.scatter(x=range(len(df)),y=df[col],color='red')
plt.title(col)
j+=1
k=11
for col in col1:
ax=plt.subplot(4,5,k)
ax=plt.scatter(x=range(len(test)),y=test[col],color='cyan')
plt.title(col)
k+=1
plt.subplots_adjust(wspace=0.4,hspace=0.3)
plt.show() 
这段代码的主要目的是对训练集和测试集进行可视化分析,以便更好地理解数据的特征分布。
1. 首先,它将数值变量(Nu_feature)和分类变量(Ca_feature)从数据集中分离出来。数值变量是那些可以取连续值的变量,而分类变量是那些只能取有限个值的变量。
2. 然后,它使用seaborn库的kdeplot函数绘制了每个数值变量在训练集和测试集中的密度图。这样可以直观地看到这两个数据集在这些数值变量上的分布情况。
3. 最后,它使用matplotlib库的scatter函数绘制了每个分类变量在训练集和测试集中的散点图。这样可以直观地看到这两个数据集在这些分类变量上的分布情况。
总的来说,这段代码可以帮助我们更好地理解训练集和测试集的数据特征,从而为后续的数据分析和建模提供依据。
2.数据预处理
from sklearn.preprocessing import LabelEncoder
lb = LabelEncoder()
cols = Ca_feature
for m in cols:
df[m] = lb.fit_transform(df[m])
test[m] = lb.fit_transform(test[m])
df['subscribe']=df['subscribe'].replace(['no','yes'],[0,1])
correlation_matrix=df.corr()
plt.figure(figsize=(12,10))
sns.heatmap(correlation_matrix,vmax=0.9,linewidths=0.05,cmap="RdGy")
# 几个相关性比较高的特征在模型的特征输出部分也占据比较重要的位置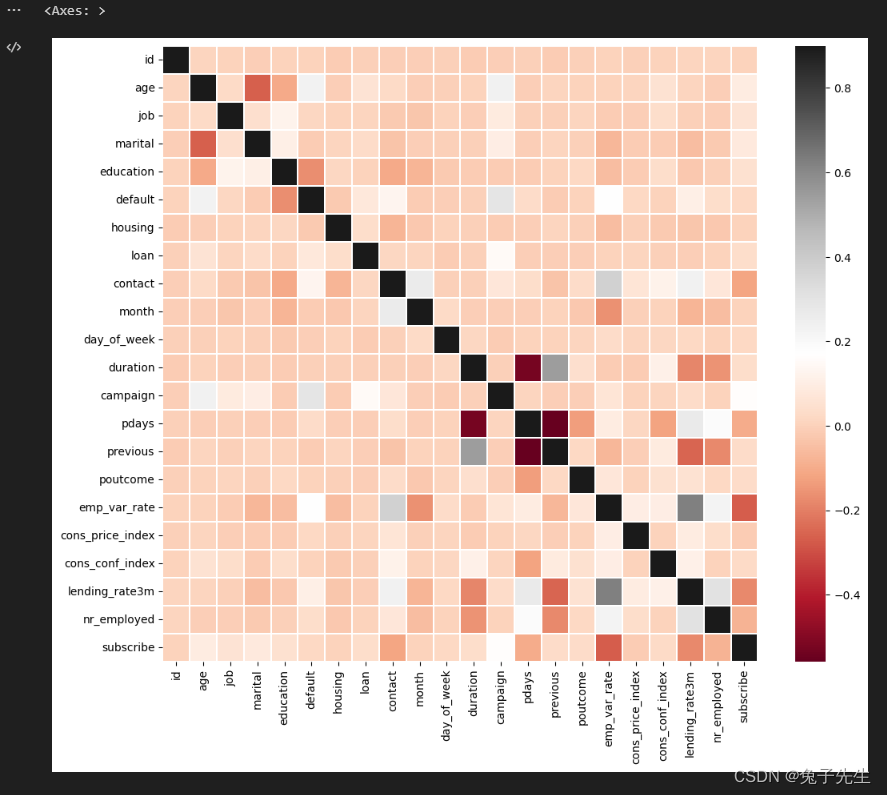
导入了sklearn库中的LabelEncoder类,用于将分类变量转换为数值型变量。
创建了一个LabelEncoder对象lb。
对数据集df和测试集test中的分类变量进行编码转换,将其转换为数值型变量。
将数据集df中的subscribe列的取值从['no','yes']替换为[0,1],即将'no'替换为0,'yes'替换为1。
计算数据集df中各个特征之间的相关性矩阵correlation_matrix。
使用seaborn库中的heatmap函数绘制相关性矩阵的热力图,其中vmax参数表示颜色的最大值,linewidths参数表示每个单元格之间的间隔线宽度,cmap参数表示颜色映射方案。
from sklearn import preprocessing
# 数据预处理
x = df1[['job','marital','education','default','housing','loan','contact','month','day_of_week','poutcome','subscribe']].values
encoder=preprocessing.OrdinalEncoder() # 创建了一个OrdinalEncoder对象encoder,将分类变量转换为数值型变量
encoder.fit(x)
x=encoder.transform(x)
df1[['job','marital','education','default','housing','loan','contact','month','day_of_week','poutcome','subscribe']]=x
df1.head()归一化处理
import numpy as np
# 归一化 X 数据
def normalize_data(data):
# 计算数据的最小值和最大值
data_min = np.min(data, axis=0)
data_max = np.max(data, axis=0)
# 归一化数据到 [0, 1] 区间
normalized_data = (data - data_min) / (data_max - data_min)
return normalized_data, data_min, data_max
normalized_X, X_min, X_max = normalize_data(df1)
df1=normalized_X
df1.to_csv('train11.csv',index=False)
df13.划分数据集-分析与预测
from lightgbm.sklearn import LGBMClassifier
from sklearn.model_selection import train_test_split, KFold
from sklearn.metrics import roc_auc_score, accuracy_score
import pandas as pd
import numpy as np
# 数据准备
X = df.drop(columns=['id', 'subscribe'])
Y = df['subscribe']
test = test.drop(columns='id')
# 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=0.3, random_state=1)
# 建立模型 基于LightGBM框架的分类模型,LightGBM分类器,是一种高效的机器学习算法,主要用于解决分类问题。
gbm = LGBMClassifier(n_estimators=666, learning_rate=0.01, boosting_type='gbdt',
objective='binary', max_depth=-1,
random_state=2022, metric='auc')
# 交叉验证
result1 = []
mean_score1 = 0
n_folds = 5
kf = KFold(n_splits=n_folds, shuffle=True, random_state=2022)
for train_index, test_index in kf.split(X):
x_train_fold, x_val_fold = X.iloc[train_index], X.iloc[test_index]
y_train_fold, y_val_fold = Y.iloc[train_index], Y.iloc[test_index]
gbm_fold = LGBMClassifier(n_estimators=666 learning_rate=0.01, boosting_type='gbdt',
objective='binary', max_depth=-1,
random_state=2022, metric='auc')
gbm_fold.fit(x_train_fold, y_train_fold)
y_pred1 = gbm_fold.predict_proba(x_val_fold)[:, 1]
print('验证集AUC: {}'.format(roc_auc_score(y_val_fold, y_pred1)))
mean_score1 += roc_auc_score(y_val_fold, y_pred1) / n_folds
y_pred_final1 = gbm_fold.predict_proba(test)[:, 1]
result1.append(y_pred_final1)
# 模型评估
print('mean 验证集auc: {}'.format(mean_score1))
cat_pre1 = np.sum(result1, axis=0) / n_folds
ret1 = pd.DataFrame(cat_pre1, columns=['subscribe'])
ret1['subscribe'] = np.where(ret1['subscribe'] > 0.5, 'yes', 'no').astype('str')
ret1.to_csv('GBM预测.csv', index=False)
比赛结果排名
赛后收获
-
提升技能:参加比赛可以锻炼自己的编程能力、数据处理能力和算法设计能力,提高自己在相关领域的技术水平。
-
学习新知识:比赛中涉及到的问题和场景可能与自己平时的工作或学习不同,通过参加比赛可以学习到新的知识和技术。
-
增加经验:参加比赛可以积累实际项目经验,了解实际问题的解决方案和优化方法,就比如在做项目的时候很多模型啊,还有一些方法都需要自己去一个一个的去查找和学习了解

















 2574
2574

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









