







一、研究背景
在现代商业环境中,预测客户购买行为已成为企业成功的关键因素之一。通过准确地预测客户是否会购买某种产品或服务,企业可以优化营销策略,提升客户满意度和忠诚度,最终增加销售额和利润。然而,由于客户数据的多样性和复杂性,如何有效地进行预测仍然是一个具有挑战性的问题。
二、研究意义
提升营销效果:通过精准预测客户购买行为,企业可以将营销资源集中于更有可能购买的客户群体,从而提高营销活动的有效性。优化客户关系管理:了解客户的购买倾向。。。
三、实证分析
导入基础工作需要的包已经画图可以显示中文的代码
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
plt.rcParams['font.sans-serif'] = ['KaiTi'] #中文
plt.rcParams['axes.unicode_minus'] = False #负号读取数据并且展示前5行:
train_data.head(5)
后5行也可以看看
查看数据整体形状:

可以了解到,数据的基本结构是20252*17。接下来查看一下数据具体类型:
接下来进行描述性统计分析:
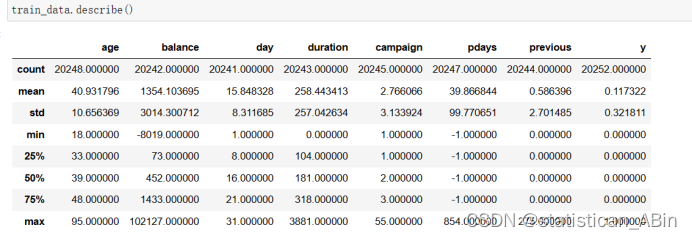 可以从中知道,Age(年龄):数据范围从18到95岁。平均年龄大约为40岁,标准差约为10.6岁,表明年龄分布相对集中。balance(账户余额):平均余额为1,354.13欧元,但标准差很大,为3,014.30欧元,这表明账户余额分布的差异性很大。最小余额为-8,019欧元,表明有账户是透支状态。最大余额为102,127欧元,显示有些客户的账户余额非常高。。。。。
可以从中知道,Age(年龄):数据范围从18到95岁。平均年龄大约为40岁,标准差约为10.6岁,表明年龄分布相对集中。balance(账户余额):平均余额为1,354.13欧元,但标准差很大,为3,014.30欧元,这表明账户余额分布的差异性很大。最小余额为-8,019欧元,表明有账户是透支状态。最大余额为102,127欧元,显示有些客户的账户余额非常高。。。。。
接下来使用函数可视化缺失值:
import missingno as msno
msno.matrix(train_data)
可以发现,还是存在一定的缺失值。后面要进行处理:
miss_ratio=0.3
for col in train_data.columns:
if train_data[col].isnull().sum()>train_data.shape[0]*miss_ratio:
print(col)
train_data.drop(col,axis=1,inplace=True)missing_values = train_data.isnull().sum()
missing_values_percentage = (missing_values / len(train_data)) * 100
missing_data = pd.DataFrame({
'Missing Values': missing_values,
'Percentage': missing_values_percentage
})
missing_data[missing_data['Missing Values'] > 0]再次查看

最终没有缺失值了。
接下来进行特征工程
y=cleaned_data['y']
cleaned_data.drop(['y'],axis=1,inplace=True)特征可视化:
# 为了确保中文显示正确,我们需要重新设置绘图时使用的字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用支持中文的字体(这里以SimHei为例)
plt.rcParams['axes.unicode_minus'] = False # 正确显示负号
# 可视化连续特征
continuous_features = ['age', 'balance', 'day', 'duration', 'campaign', 'pdays', 'previous']
# 设置绘图大小
plt.figure(figsize=(15, 10))
# 为每个连续特征绘制直方图
for i, feature in enumerate(continuous_features):
plt.subplot(3, 3, i+1)
sns.histplot(cleaned_data[feature], kde=True)
plt.title(f'分布:{feature}')
plt.xlabel(feature)
plt.ylabel('频率')
plt.tight_layout()
plt.show()
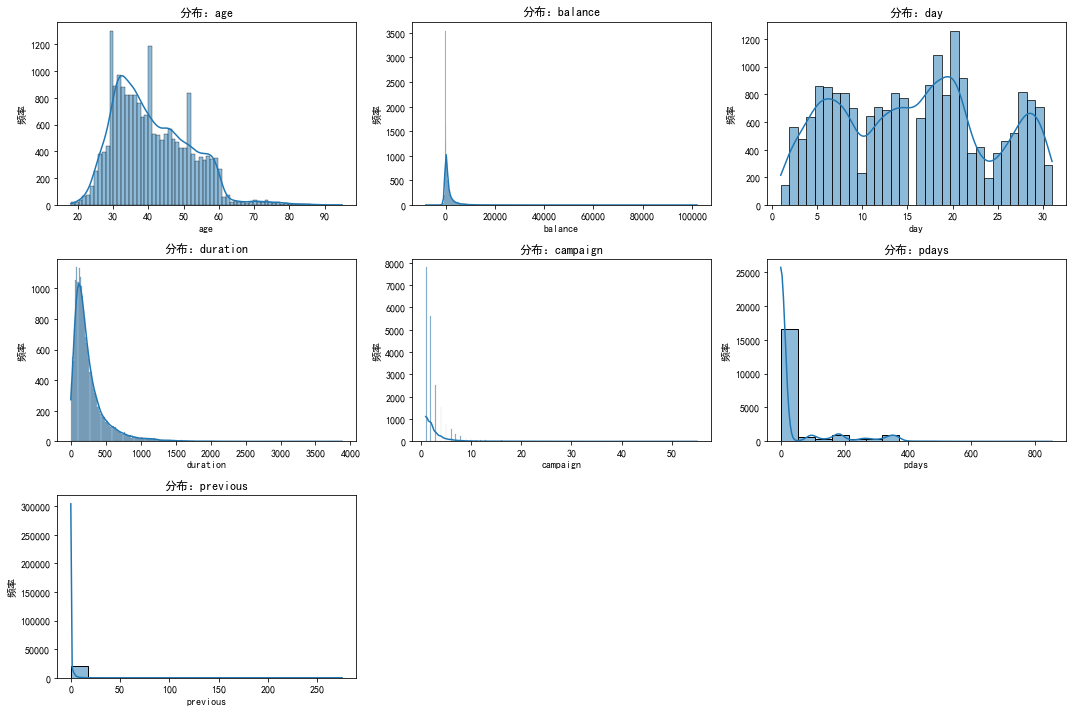
年龄(age)大部分客户年龄集中在30至40岁之间。年龄分布呈现出类似正态分布的形态,略微右偏。账户余额(balance):大多数客户的账户余额较低。分布呈现出显著的正偏态,有一小部分客户拥有非常高的账户余额。。。。
可视化分类特征
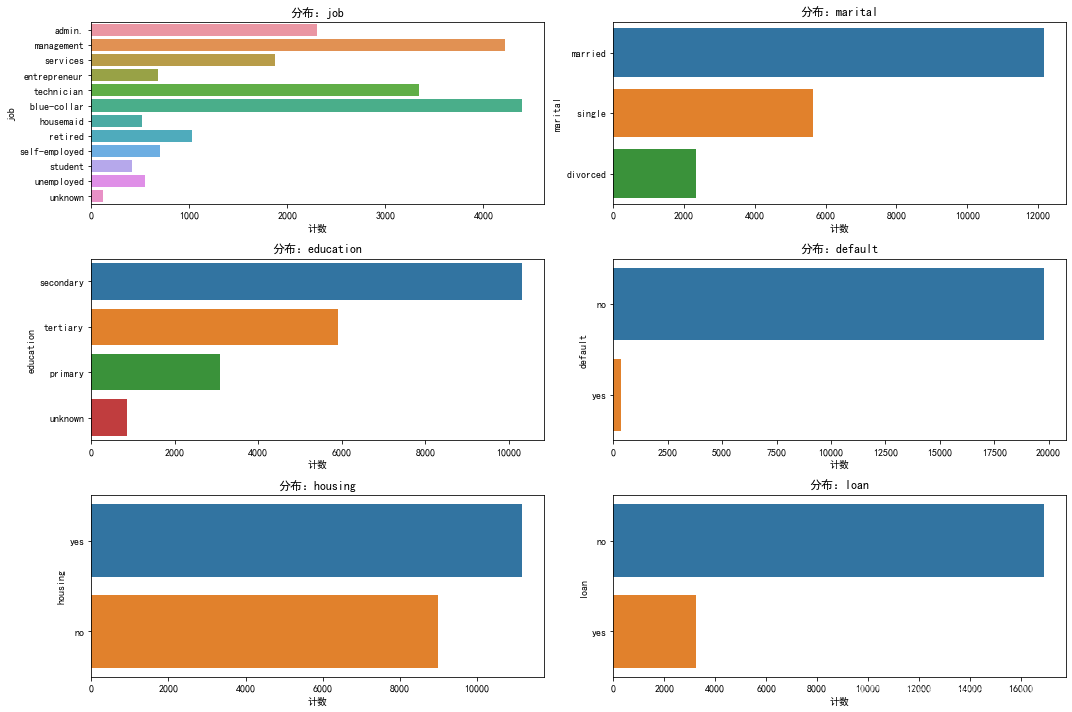
工作(job):最多的类别是管理层(management)和蓝领工人(blue-collar)。学生(student)、未知(unknown)和失业(unemployed)的数量相对较少。教育(education):拥有中等教育(secondary)的客户数量最多。。。。
查看响应变量分布
plt.figure(figsize=(6,2),dpi=128)
plt.subplot(1,3,1)
y.plot.box(title='响应变量箱线图')
plt.subplot(1,3,2)
y.plot.hist(title='响应变量直方图')
plt.subplot(1,3,3)
y.plot.kde(title='响应变量核密度图')
#sns.kdeplot(y, color='Red', shade=True)
#plt.savefig('响应变量.png')
plt.tight_layout()
plt.show() 
箱线图:显示所有的值都非常接近0,只有少量的1值,这表明大多数客户没有购买银行产品。由于数据的不平衡性,箱线图几乎没有显示任何的四分位数信息,这意味着1的值非常稀少。。。
再看一下相关系数矩阵热力图:
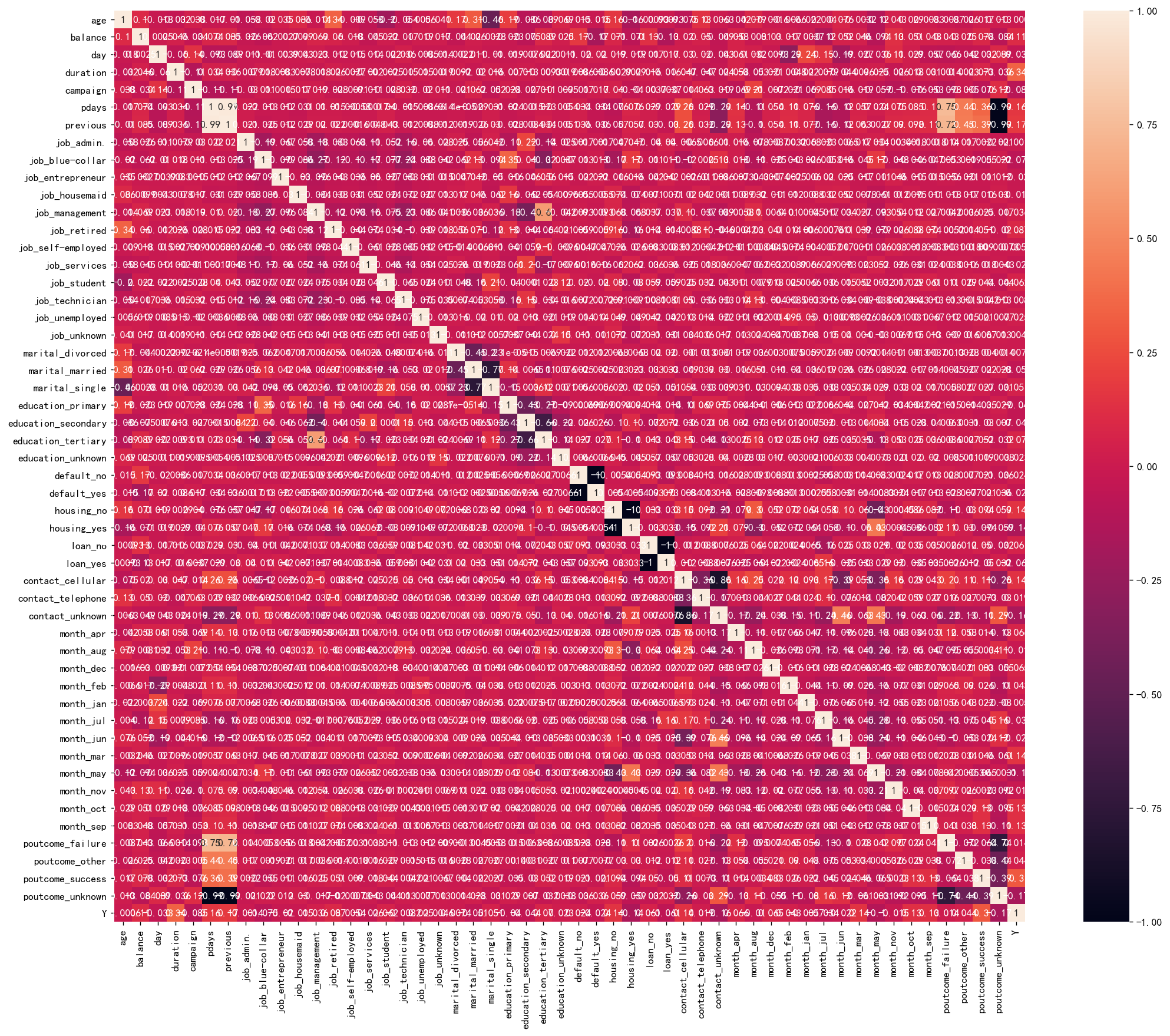 这里是因为我们对一一些分类变量进行独热编码了,所以特征变得很多。
这里是因为我们对一一些分类变量进行独热编码了,所以特征变得很多。
开始机器学习:
划分训练集和验证集
from sklearn.model_selection import train_test_split
X_train,X_val,y_train,y_val=train_test_split(data1,y,test_size=0.2,random_state=0)我这里选择了3种算法模型,对比他们在验证集的精度,再来进一步选择模型。
from sklearn.naive_bayes import BernoulliNB
model1 = BernoulliNB(alpha=1)
model1.fit(X_train_s, y_train)
model1.score(X_val_s, y_val)df_eval=pd.DataFrame(columns=['Accuracy','Precision','Recall','F1_score'])
s=classification_report(y_val, pred)
s=evaluation(y_val,pred)
df_eval.loc['BN',:]=list(s)
df_eval

from sklearn.metrics import ConfusionMatrixDisplay
ConfusionMatrixDisplay.from_estimator(model3, X_val_s, y_val,cmap='Blues')
plt.tight_layout()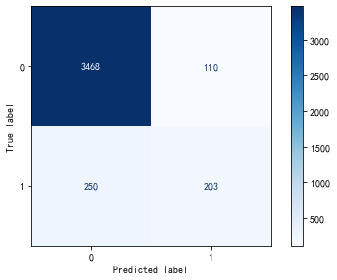
这个混淆矩阵中,我们可以看到:
模型正确预测未购买(0)的客户数为3480(TN)。
模型错误地将110名实际未购买的客户预测为购买了(FP)。
模型正确预测购买(1)的客户数为203(TP)。
模型将250名实际购买的客户预测为未购买(FN)。
这意味着模型对于未购买的预测相当准确,但对于实际购买的客户,模型则错过了较多(250个假负例)。
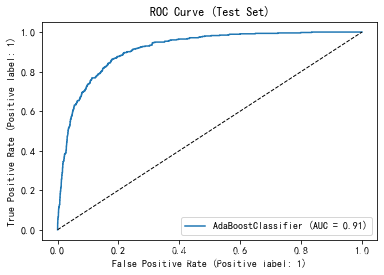
ROC曲线远高于对角线(随机猜测线),这表明模型有很好的区分能力。
AUC(Area Under Curve)值为0.91,接近1,这表示模型的整体性能非常好。AUC值越高,模型的预测性能越好。
四、结论
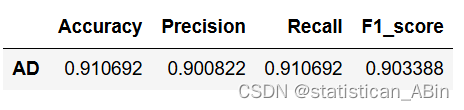
通过对客户数据的分析和多种机器学习模型的对比,本研究最终确定自适应提升模型(AdaBoost)在预测客户购买行为方面表现最佳,准确率达到了91%。具体结论如下:
数据特征的影响:研究发现,客户的年龄、账户余额、最后一次联系的持续时间等特征对客户是否购买有显著影响。这些特征的分析为理解客户购买行为提供了重要依据。
创作不易,希望大家多点赞关注评论!!!(类似代码或报告定制可以私信)















 3893
3893

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









