



一、引言
我是一名电子信息科学与技术专业的大四学生,正在考研冲刺阶段。今天想和大家聊聊机器学习中一个超级有趣的算法——GAN(生成对抗网络)。想象一下,如果AI不仅能识别猫,还能“凭空”创造出逼真的猫图片,是不是很酷?这就是GAN的魔力!
二、什么是GAN?
GAN就像一场“猫鼠游戏”,由两个神经网络组成:
-
生成器(Generator):负责制造假数据
-
判别器(Discriminator):负责辨别真假
它们相互对抗,共同进步,直到生成器能造出以假乱真的数据!
三、环境搭建
在Pycharm的终端中运行如下的指令:
pip show torch torchvision matplotlib numpy



四、生成手写数字
1.导入库
import torch
import torch.nn as nn # 神经网络模块
import torch.optim as optim # 优化器
from torchvision import datasets, transforms # 计算机视觉数据集和变换
from torch.utils.data import DataLoader # 数据加载器
import matplotlib.pyplot as plt # 绘图
import numpy as np # 数值计算
import os # 操作系统接口
import time # 时间相关功能
from tqdm import tqdm # 进度条库,让训练过程可视化
这个过程,想象你要建一个工厂(GAN),这些库就是你的工具包:
-
torch:主工具包,相当于你的工厂建筑 -
nn:神经网络组件,像工厂的生产线 -
optim:优化器,像工厂的调度员 -
torchvision:视觉工具,像质检设备 -
matplotlib:绘图工具,像监控摄像头
2.检查GPU状态
print("=" * 50)
print("GPU状态检查")
print("=" * 50)
print(f"PyTorch版本: {torch.__version__}")
print(f"CUDA可用: {torch.cuda.is_available()}")
if torch.cuda.is_available():
print(f"GPU名称: {torch.cuda.get_device_name(0)}")
print(f"GPU内存: {torch.cuda.get_device_properties(0).total_memory / 1e9:.2f} GB")
print("=" * 50)
# 设置设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"使用设备: {device}")
这个过程,就像开车前检查车辆:
-
torch.cuda.is_available():检查发动机(GPU)是否能用 -
get_device_name():看看是什么型号的发动机 -
get_device_properties():检查油箱有多大(显存) -
device:决定用汽车(GPU)还是自行车(CPU)
3.准备工作
# 创建保存目录
os.makedirs('gan_results_gpu', exist_ok=True)
# 超参数设置(可以根据GPU性能调整)
batch_size = 128 # GPU性能好,可以增大batch size
latent_dim = 100
learning_rate = 0.0002
num_epochs = 100 # 可以训练更多轮次
简单解释:
-
os.makedirs():新建一个文件夹,像准备一个展览厅放成品 -
batch_size = 128:一次训练128张图片,就像厨师一次炒128份菜 -
latent_dim = 100:噪声向量的维度,就像给AI的"想象空间"有100个维度 -
learning_rate = 0.0002:学习率,像AI的学习速度 -
num_epochs = 100:训练100轮,就像学生做100遍习题
4.定义生成器网络
class Generator(nn.Module):
def __init__(self, latent_dim):
super(Generator, self).__init__()
self.init_size = 7 # 初始特征图大小
self.l1 = nn.Sequential(
nn.Linear(latent_dim, 128 * self.init_size ** 2),
nn.BatchNorm1d(128 * self.init_size ** 2),
nn.LeakyReLU(0.2, inplace=True)
)
self.conv_blocks = nn.Sequential(
nn.Upsample(scale_factor=2), # 14x14
nn.Conv2d(128, 128, 3, stride=1, padding=1),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2, inplace=True),
nn.Upsample(scale_factor=2), # 28x28
nn.Conv2d(128, 64, 3, stride=1, padding=1),
nn.BatchNorm2d(64),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, 1, 3, stride=1, padding=1),
nn.Tanh()
)
def forward(self, z):
out = self.l1(z)
out = out.view(out.shape[0], 128, self.init_size, self.init_size)
img = self.conv_blocks(out)
return img
对于生成器,它就像一个"造假工厂":
-
输入:随机噪声(100维向量)→ 像是"创意灵感"
-
处理过程:
-
Linear:把100维噪声变成6272维(128×7×7) -
BatchNorm:标准化,让数据更稳定 -
LeakyReLU:激活函数,像给数据"打鸡血" -
Upsample:上采样,把7×7放大成14×14,再放大成28×28 -
Conv2d:卷积操作,提取和组合特征 -
Tanh:输出在[-1, 1]之间,适合图片数据
-
5.定义判别器网络
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
def discriminator_block(in_filters, out_filters, bn=True):
block = [nn.Conv2d(in_filters, out_filters, 3, 2, 1)]
if bn:
block.append(nn.BatchNorm2d(out_filters))
block.extend([nn.LeakyReLU(0.2, inplace=True), nn.Dropout2d(0.25)])
return block
self.model = nn.Sequential(
*discriminator_block(1, 16, bn=False),
*discriminator_block(16, 32),
*discriminator_block(32, 64),
*discriminator_block(64, 128),
)
# 计算特征图大小
ds_size = 28 // 2 ** 4 # 经过4次stride=2的卷积
self.adv_layer = nn.Sequential(
nn.Linear(128 * ds_size ** 2, 1),
nn.Sigmoid()
)
def forward(self, img):
out = self.model(img)
out = out.view(out.shape[0], -1)
validity = self.adv_layer(out)
return validity
这里,判别器就像一个"鉴定专家":
-
输入:28×28的图片
-
处理过程:
-
4个
discriminator_block:每个块包含卷积、标准化、激活和dropout -
卷积步长(stride)为2:每次卷积图片尺寸减半(28→14→7→4→2)
-
Dropout:随机丢弃一些信息,防止过拟合 -
Linear+Sigmoid:输出0-1的概率值,表示"这是真图片的可能性"
-
图片的尺寸变化过程:
28×28 → 14×14 → 7×7 → 4×4 → 2×2
6.数据加载
# 数据加载和预处理
transform = transforms.Compose([
transforms.ToTensor(), # 把图片变成张量
transforms.Normalize((0.5,), (0.5,)) # 归一化到[-1, 1]
])
train_dataset = datasets.MNIST(root='./data',
train=True,
transform=transform,
download=True)
train_loader = DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=4, # 使用多线程加载数据
pin_memory=True) # 加速数据传到GPU
在这里,准备训练材料:
-
MNIST:手写数字数据集,有6万张0-9的手写数字图片 -
ToTensor():把图片变成PyTorch能处理的张量格式 -
Normalize():把像素值从[0,255]变成[-1,1],让训练更稳定 -
DataLoader:数据加载器,像自动喂食机 -
num_workers=4:用4个工人同时准备数据 -
pin_memory=True:把数据放到固定内存,加速GPU传输
7.模型和优化器初始化
# 初始化模型
generator = Generator(latent_dim).to(device)
discriminator = Discriminator().to(device)
# 损失函数和优化器
adversarial_loss = nn.BCELoss()
optimizer_G = optim.Adam(generator.parameters(), lr=learning_rate, betas=(0.5, 0.999))
optimizer_D = optim.Adam(discriminator.parameters(), lr=learning_rate, betas=(0.5, 0.999))
# 固定噪声用于生成样本
fixed_noise = torch.randn(64, latent_dim, device=device)
-
.to(device):把模型放到GPU或CPU上 -
BCELoss():二分类交叉熵损失,用来衡量预测和真实值的差距 -
Adam:优化算法,像"智能导航"帮模型找到最佳参数 -
betas=(0.5, 0.999):Adam算法的超参数,控制动量 -
fixed_noise:固定的随机噪声,用来观察生成器的进步
8.训练循环
这里是最核心的部分
for epoch in range(num_epochs): # 训练100轮
progress_bar = tqdm(train_loader, desc=f'Epoch {epoch+1}/{num_epochs}')
for i, (real_imgs, _) in enumerate(progress_bar):
# 将数据移动到GPU
real_imgs = real_imgs.to(device)
batch_size = real_imgs.size(0)
# 真实和假的标签
real_labels = torch.ones(batch_size, 1, device=device) # 真图片标签为1
fake_labels = torch.zeros(batch_size, 1, device=device) # 假图片标签为0
-
epoch:训练轮次,就像学生复习多遍 -
tqdm:进度条,让你看到训练进度 -
real_imgs:真实的手写数字图片 -
real_labels = 1:告诉判别器"这是真货" -
fake_labels = 0:告诉判别器"这是假货"
8.1训练判别器
# ========== 训练判别器 ==========
optimizer_D.zero_grad() # 清除之前的梯度
# 真实图片的损失
real_pred = discriminator(real_imgs) # 判别器看真图片
d_real_loss = adversarial_loss(real_pred, real_labels) # 希望判别器说"1"
# 生成假图片
z = torch.randn(batch_size, latent_dim, device=device) # 随机噪声
fake_imgs = generator(z) # 生成器造假图片
# 假图片的损失
fake_pred = discriminator(fake_imgs.detach()) # 判别器看假图片
d_fake_loss = adversarial_loss(fake_pred, fake_labels) # 希望判别器说"0"
# 判别器总损失
d_loss = (d_real_loss + d_fake_loss) / 2
d_loss.backward() # 反向传播计算梯度
optimizer_D.step() # 更新判别器参数
我们拿它比喻为侦探破案:
-
案件1(真图片):警察(判别器)看到真钱,应该报告"这是真的"
-
案件2(假图片):警察看到假钞,应该报告"这是假的"
-
总结经验:警察从两个案件中学习如何分辨真假
-
提高能力:更新警察的知识库(参数)
8.2训练生成器
# ========== 训练生成器 ==========
optimizer_G.zero_grad() # 清除之前的梯度
# 生成器想让判别器认为假图片是真的
gen_pred = discriminator(fake_imgs) # 警察再看一次假钞
g_loss = adversarial_loss(gen_pred, real_labels) # 希望警察说"这是真的"
g_loss.backward() # 反向传播计算梯度
optimizer_G.step() # 更新生成器参数
我们拿它比喻为那些假钞制造者:
-
再次提交:假钞制造者(生成器)拿着自己造的假钞给警察看
-
希望结果:希望警察说"这是真钞"
-
改进技术:根据警察的反应改进造假技术
8.3对抗训练的数学表达
#text ------>数学公式
min_G max_D V(D, G) = E[log D(x)] + E[log(1 - D(G(z)))]
-
判别器目标:最大化V(D,G),正确区分真假
-
生成器目标:最小化V(D,G),让判别器犯错
9.保存和可视化结果
# 每个epoch结束后生成并保存样本
generator.eval() # 切换到评估模式
with torch.no_grad(): # 不计算梯度,节省内存
sample_imgs = generator(fixed_noise).cpu()
samples.append(sample_imgs)
generator.train() # 切换回训练模式
-
generator.eval():考试模式,关闭dropout等训练专用功能 -
torch.no_grad():不计算梯度,像考试时不用记笔记 -
用固定的
fixed_noise生成图片,可以看到生成器的进步
10.结果可视化
# 绘制训练过程
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 5))
# 损失曲线
ax1.plot(G_losses, label='生成器损失', alpha=0.7)
ax1.plot(D_losses, label='判别器损失', alpha=0.7)
ax1.set_xlabel('迭代次数')
ax1.set_ylabel('损失')
ax1.set_title('GAN训练损失曲线')
ax1.legend()
ax1.grid(True, alpha=0.3)
损失曲线解读:
-
理想情况:两者交替下降,最终达到平衡
-
如果生成器损失一直上升:造假技术太差,被警察轻易识破
-
如果判别器损失一直上升:警察能力太差,分不清真假
五、GAN的有趣应用
-
艺术创作:AI绘画、音乐生成
-
图像超分辨率:让模糊照片变清晰
-
风格迁移:把你的照片变成梵高风格
-
数据增强:生成更多训练数据
-
游戏开发:自动生成游戏场景
这里有个小彩蛋:后续会有个很好的数据增强的项目,敬请期待。
六、总结
GAN展示了AI的创造力,它的"对抗"思想也启发了许多其他算法。通过这样的小项目,我们既能巩固机器学习知识,又能保持学习的趣味性!
七、完整的项目源代码
一个简单的GAN实现:生成手写数字
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
import os
import time
from tqdm import tqdm # 进度条库
# 先检查GPU状态
print("=" * 50)
print("GPU状态检查")
print("=" * 50)
print(f"PyTorch版本: {torch.__version__}")
print(f"CUDA可用: {torch.cuda.is_available()}")
if torch.cuda.is_available():
print(f"GPU名称: {torch.cuda.get_device_name(0)}")
print(f"GPU内存: {torch.cuda.get_device_properties(0).total_memory / 1e9:.2f} GB")
print("=" * 50)
# 设置设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"使用设备: {device}")
# 创建保存目录
os.makedirs('gan_results_gpu', exist_ok=True)
# 超参数设置(可以根据GPU性能调整)
batch_size = 128 # GPU性能好,可以增大batch size
latent_dim = 100
learning_rate = 0.0002
num_epochs = 100 # 可以训练更多轮次
# 改进的生成器网络(更深的网络,利用GPU性能)
class Generator(nn.Module):
def __init__(self, latent_dim):
super(Generator, self).__init__()
self.init_size = 7 # 初始特征图大小
self.l1 = nn.Sequential(
nn.Linear(latent_dim, 128 * self.init_size ** 2),
nn.BatchNorm1d(128 * self.init_size ** 2),
nn.LeakyReLU(0.2, inplace=True)
)
self.conv_blocks = nn.Sequential(
nn.Upsample(scale_factor=2), # 14x14
nn.Conv2d(128, 128, 3, stride=1, padding=1),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2, inplace=True),
nn.Upsample(scale_factor=2), # 28x28
nn.Conv2d(128, 64, 3, stride=1, padding=1),
nn.BatchNorm2d(64),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, 1, 3, stride=1, padding=1),
nn.Tanh()
)
def forward(self, z):
out = self.l1(z)
out = out.view(out.shape[0], 128, self.init_size, self.init_size)
img = self.conv_blocks(out)
return img
# 改进的判别器网络(使用卷积网络)
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
def discriminator_block(in_filters, out_filters, bn=True):
block = [nn.Conv2d(in_filters, out_filters, 3, 2, 1)]
if bn:
block.append(nn.BatchNorm2d(out_filters))
block.extend([nn.LeakyReLU(0.2, inplace=True), nn.Dropout2d(0.25)])
return block
self.model = nn.Sequential(
*discriminator_block(1, 16, bn=False),
*discriminator_block(16, 32),
*discriminator_block(32, 64),
*discriminator_block(64, 128),
)
# 计算特征图大小
ds_size = 28 // 2 ** 4 # 经过4次stride=2的卷积
self.adv_layer = nn.Sequential(
nn.Linear(128 * ds_size ** 2, 1),
nn.Sigmoid()
)
def forward(self, img):
out = self.model(img)
out = out.view(out.shape[0], -1)
validity = self.adv_layer(out)
return validity
# 数据加载和预处理
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
train_dataset = datasets.MNIST(root='./data',
train=True,
transform=transform,
download=True)
train_loader = DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=4, # 使用多线程加载数据
pin_memory=True) # 加速数据传到GPU
# 初始化模型
generator = Generator(latent_dim).to(device)
discriminator = Discriminator().to(device)
# 损失函数和优化器
adversarial_loss = nn.BCELoss()
optimizer_G = optim.Adam(generator.parameters(), lr=learning_rate, betas=(0.5, 0.999))
optimizer_D = optim.Adam(discriminator.parameters(), lr=learning_rate, betas=(0.5, 0.999))
# 固定噪声用于生成样本
fixed_noise = torch.randn(64, latent_dim, device=device)
# 训练循环
G_losses = []
D_losses = []
samples = [] # 保存每个epoch的生成样本
print("\n开始训练GAN(使用GPU加速)...")
start_time = time.time()
for epoch in range(num_epochs):
progress_bar = tqdm(train_loader, desc=f'Epoch {epoch+1}/{num_epochs}')
for i, (real_imgs, _) in enumerate(progress_bar):
# 将数据移动到GPU
real_imgs = real_imgs.to(device)
batch_size = real_imgs.size(0)
# 真实和假的标签
real_labels = torch.ones(batch_size, 1, device=device)
fake_labels = torch.zeros(batch_size, 1, device=device)
# ========== 训练判别器 ==========
optimizer_D.zero_grad()
# 真实图片的损失
real_pred = discriminator(real_imgs)
d_real_loss = adversarial_loss(real_pred, real_labels)
# 生成假图片
z = torch.randn(batch_size, latent_dim, device=device)
fake_imgs = generator(z)
# 假图片的损失
fake_pred = discriminator(fake_imgs.detach())
d_fake_loss = adversarial_loss(fake_pred, fake_labels)
# 判别器总损失
d_loss = (d_real_loss + d_fake_loss) / 2
d_loss.backward()
optimizer_D.step()
# ========== 训练生成器 ==========
optimizer_G.zero_grad()
# 生成器想让判别器认为假图片是真的
gen_pred = discriminator(fake_imgs)
g_loss = adversarial_loss(gen_pred, real_labels)
g_loss.backward()
optimizer_G.step()
# 更新进度条
progress_bar.set_postfix({
'D_loss': f'{d_loss.item():.4f}',
'G_loss': f'{g_loss.item():.4f}'
})
# 保存损失
if i % 10 == 0:
G_losses.append(g_loss.item())
D_losses.append(d_loss.item())
# 每个epoch结束后生成并保存样本
generator.eval()
with torch.no_grad():
sample_imgs = generator(fixed_noise).cpu()
samples.append(sample_imgs)
generator.train()
# 每10个epoch保存一次图片
if (epoch + 1) % 10 == 0 or epoch == num_epochs - 1:
# 可视化生成的图片
fig, axes = plt.subplots(8, 8, figsize=(12, 12))
for idx, ax in enumerate(axes.flatten()):
ax.imshow(sample_imgs[idx].squeeze(), cmap='gray')
ax.axis('off')
plt.suptitle(f'GAN生成的手写数字 (Epoch {epoch+1})', fontsize=16)
plt.savefig(f'gan_results_gpu/epoch_{epoch+1:03d}.png', dpi=100)
plt.close()
print(f'Epoch [{epoch+1}/{num_epochs}] - 样本已保存')
# 训练完成
end_time = time.time()
training_time = end_time - start_time
print(f"\n训练完成! 总耗时: {training_time:.2f}秒 ({training_time/60:.2f}分钟)")
# 绘制训练过程
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 5))
# 损失曲线
ax1.plot(G_losses, label='生成器损失', alpha=0.7)
ax1.plot(D_losses, label='判别器损失', alpha=0.7)
ax1.set_xlabel('迭代次数')
ax1.set_ylabel('损失')
ax1.set_title('GAN训练损失曲线')
ax1.legend()
ax1.grid(True, alpha=0.3)
# 生成样本演变过程
n_epochs_to_show = min(10, len(samples))
for i in range(n_epochs_to_show):
epoch_idx = int(i * (len(samples) - 1) / (n_epochs_to_show - 1))
img = samples[epoch_idx][0].squeeze().numpy()
ax2.imshow(img, extent=[i, i+1, 0, 1], aspect='auto', cmap='gray', alpha=0.8)
ax2.set_xlabel('训练过程 (早期 → 后期)')
ax2.set_ylabel('生成样本演变')
ax2.set_title('生成样本随训练的变化')
ax2.set_xlim(0, n_epochs_to_show)
ax2.set_ylim(0, 1)
ax2.set_yticks([])
plt.tight_layout()
plt.savefig('gan_results_gpu/training_summary.png', dpi=120)
plt.show()
# 创建最终生成的动画(可选)
print("\n创建生成过程动画...")
import matplotlib.animation as animation
fig = plt.figure(figsize=(8, 8))
ims = []
for i in range(0, len(samples), max(1, len(samples)//20)):
im = plt.imshow(samples[i][0].squeeze(), animated=True, cmap='gray')
ims.append([im])
ani = animation.ArtistAnimation(fig, ims, interval=200, blit=True, repeat_delay=1000)
ani.save('gan_results_gpu/generation_process.gif', writer='pillow', fps=5)
# 保存模型
torch.save({
'generator_state_dict': generator.state_dict(),
'discriminator_state_dict': discriminator.state_dict(),
'G_losses': G_losses,
'D_losses': D_losses,
}, 'gan_results_gpu/gan_model.pth')
print("模型和结果已保存到 'gan_results_gpu' 文件夹!")
八、可能会有的问题
1.跑代码的不是GPU,而是CPU
运行代码之后,使用CPU来跑代码
原因:如果你是通过pip安装的,默认安装的是CPU版本。

对此,我们可以使用如下的代码做个小检查
import torch
print("PyTorch版本:", torch.__version__)
print("CUDA是否可用:", torch.cuda.is_available())
print("CUDA版本:", torch.version.cuda if torch.cuda.is_available() else "N/A")
print("可用GPU数量:", torch.cuda.device_count())
print("当前GPU名称:", torch.cuda.get_device_name(0) if torch.cuda.is_available() else "N/A")
# 检查GPU内存信息
if torch.cuda.is_available():
print("GPU内存总量:", torch.cuda.get_device_properties(0).total_memory / 1e9, "GB")
如果torch.cuda.is_available()返回False,那说明你的PyTorch安装的是CPU版本。

如何解决这个问题呢?
安装GPU版本的PyTorch
步骤1:卸载现有的PyTorch(如果有)
使用如下的命令:
# 在PyCharm的Terminal或系统终端中执行
pip uninstall torch torchvision torchaudio -y
在终端运行后的显示:

成功卸载:
步骤2:安装GPU版本的PyTorch
对于RTX 4060显卡,推荐使用CUDA 12.1版本:
# 使用pip安装(推荐)
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121

步骤3:验证安装
创建一个简单的测试脚本:
# test_gpu.py
import torch
import numpy as np
print("=" * 50)
print("PyTorch GPU测试")
print("=" * 50)
# 基本信息
print(f"PyTorch版本: {torch.__version__}")
print(f"CUDA可用: {torch.cuda.is_available()}")
print(f"CUDA版本: {torch.version.cuda}")
print(f"GPU数量: {torch.cuda.device_count()}")
print(f"GPU名称: {torch.cuda.get_device_name(0)}")
# 测试张量计算
print("\n" + "=" * 50)
print("GPU性能测试")
print("=" * 50)
if torch.cuda.is_available():
# 创建两个大矩阵
size = 10000
a = torch.randn(size, size).cuda()
b = torch.randn(size, size).cuda()
# 测试矩阵乘法速度
import time
start = time.time()
c = torch.matmul(a, b)
torch.cuda.synchronize() # 等待GPU完成计算
end = time.time()
print(f"矩阵乘法计算完成: {size} x {size}")
print(f"计算时间: {end - start:.4f} 秒")
print(f"结果形状: {c.shape}")
# 检查GPU内存使用
print(f"\nGPU内存使用情况:")
print(f"已分配: {torch.cuda.memory_allocated(0) / 1e9:.2f} GB")
print(f"已缓存: {torch.cuda.memory_reserved(0) / 1e9:.2f} GB")
# 简单的深度学习操作测试
print("\n深度学习操作测试:")
x = torch.randn(100, 100, device='cuda')
y = torch.randn(100, 100, device='cuda')
# 前向传播
z = torch.matmul(x, y).relu()
# 反向传播
loss = z.sum()
loss.backward()
print("前向传播和反向传播测试通过!")
# 释放内存
del a, b, c, x, y, z
torch.cuda.empty_cache()
print("GPU内存已清理")
else:
print("警告: CUDA不可用,请检查安装!")
print("\n可能的原因:")
print("1. PyTorch未安装GPU版本")
print("2. NVIDIA驱动未正确安装")
print("3. CUDA工具包未安装或版本不匹配")
2.升级pip,再安装PyTorch
pip版本过低,先升级pip
python -m pip install --upgrade pip -i https://pypi.tuna.tsinghua.edu.cn/simple

成功升级:
再安装PyTorch:
pip install torch torchvision torchaudio -i https://pypi.tuna.tsinghua.edu.cn/simple


成功下载:

3.卸载重装,指定CUDA版本
3.1先卸载现有的CPU版本
# 在PyCharm的Terminal中执行
pip uninstall torch torchvision torchaudio -y
3.2安装指定CUDA版本的PyTorch
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121 --no-cache-dir


测试代码:
import torch
print("PyTorch版本:", torch.__version__)
print("CUDA是否可用:", torch.cuda.is_available())
print("CUDA版本:", torch.version.cuda if torch.cuda.is_available() else "N/A")
print("可用GPU数量:", torch.cuda.device_count())
print("当前GPU名称:", torch.cuda.get_device_name(0) if torch.cuda.is_available() else "N/A")
# 检查GPU内存信息
if torch.cuda.is_available():
print("GPU内存总量:", torch.cuda.get_device_properties(0).total_memory / 1e9, "GB")
使用测试代码后的运行结果:

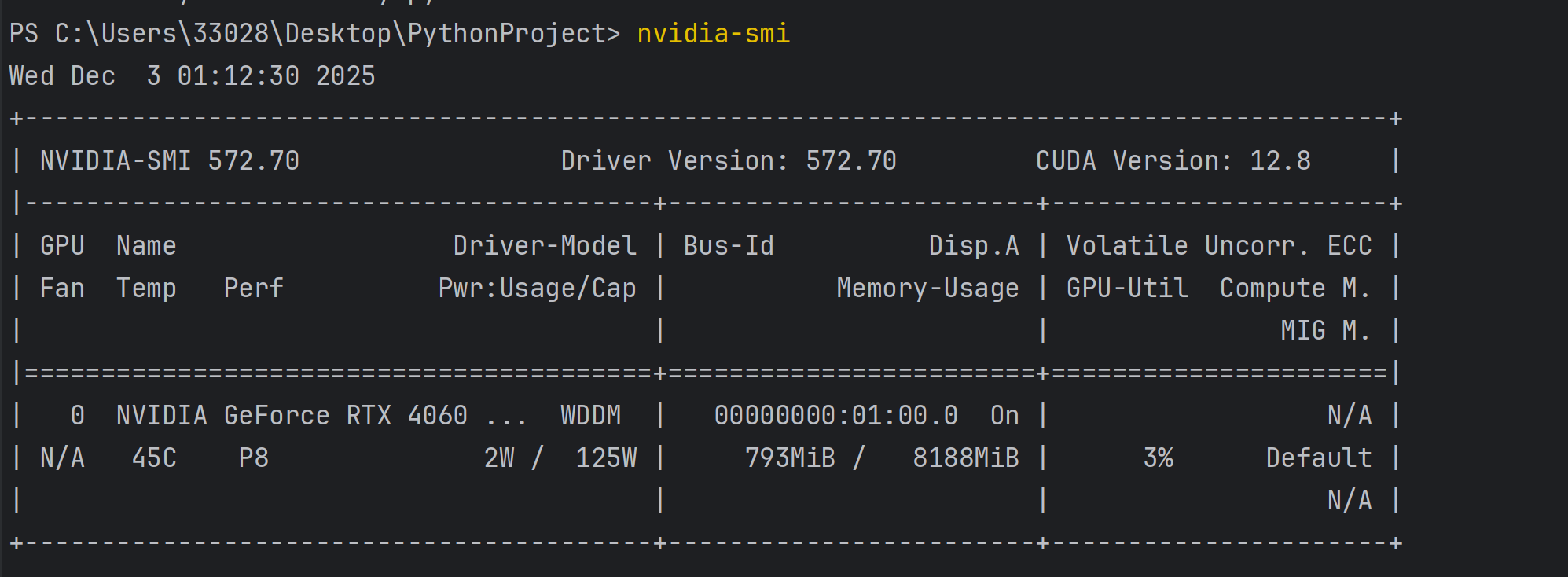
4.检查NVIDIA驱动
在python终端使用如下的命令,以检查NVIDIA驱动:
# 打开命令提示符,输入:
nvidia-smi
5.缺少库
如果运行项目的源代码后,出现如下问题,表示缺少了tqdm库。

此时,使用pip下载库即可:
pip install tqdm matplotlib numpy
九、项目结果
在这里,我们发现使用GPU跑代码速度将会明显比使用GPU快

恭喜你,GPU已经成功安装并能识别了!现在的问题是Windows系统下的多进程错误。这是一个常见问题,特别是在Windows上运行PyTorch时。别担心,我们来解决它!
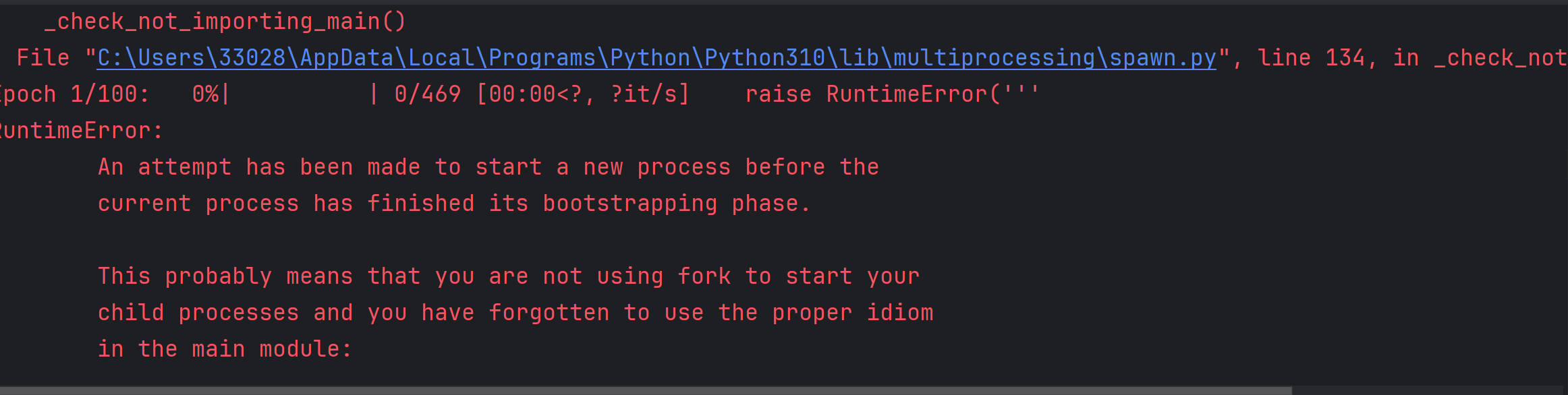
为了简单理解这个过程,我们需要改进代码:
如下是我优化后的项目源代码
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
import os
# 简单检查GPU
print("GPU状态检查:")
print(f"CUDA可用: {torch.cuda.is_available()}")
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"使用设备: {device}")
# 创建目录
os.makedirs('gan_simple', exist_ok=True)
# 超参数(简化)
batch_size = 64
latent_dim = 100
learning_rate = 0.0002
num_epochs = 20 # 只训练20轮,快速看到效果
# 简化版生成器
class SimpleGenerator(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Linear(latent_dim, 256),
nn.ReLU(),
nn.Linear(256, 512),
nn.ReLU(),
nn.Linear(512, 28*28),
nn.Tanh()
)
def forward(self, x):
x = self.model(x)
return x.view(-1, 1, 28, 28)
# 简化版判别器
class SimpleDiscriminator(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 256),
nn.ReLU(),
nn.Linear(256, 1),
nn.Sigmoid()
)
def forward(self, x):
x = x.view(x.size(0), -1)
return self.model(x)
# 准备数据
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
train_data = datasets.MNIST('./data', train=True, download=True, transform=transform)
train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True)
# 初始化模型
generator = SimpleGenerator().to(device)
discriminator = SimpleDiscriminator().to(device)
# 损失函数和优化器
loss_fn = nn.BCELoss()
g_optimizer = optim.Adam(generator.parameters(), lr=learning_rate)
d_optimizer = optim.Adam(discriminator.parameters(), lr=learning_rate)
# 固定噪声用于观察进展
fixed_noise = torch.randn(16, latent_dim, device=device)
print("\n开始简化版GAN训练...")
for epoch in range(num_epochs):
for i, (real_images, _) in enumerate(train_loader):
real_images = real_images.to(device)
batch_size = real_images.size(0)
# 训练判别器
d_optimizer.zero_grad()
# 真实图片
real_labels = torch.ones(batch_size, 1, device=device)
real_output = discriminator(real_images)
d_real_loss = loss_fn(real_output, real_labels)
# 生成假图片
noise = torch.randn(batch_size, latent_dim, device=device)
fake_images = generator(noise)
fake_labels = torch.zeros(batch_size, 1, device=device)
fake_output = discriminator(fake_images.detach())
d_fake_loss = loss_fn(fake_output, fake_labels)
d_loss = d_real_loss + d_fake_loss
d_loss.backward()
d_optimizer.step()
# 训练生成器
g_optimizer.zero_grad()
fake_output = discriminator(fake_images)
g_loss = loss_fn(fake_output, real_labels) # 想让判别器认为假图片是真的
g_loss.backward()
g_optimizer.step()
if i % 100 == 0:
print(f'Epoch {epoch+1}/{num_epochs}, Batch {i}, D_loss: {d_loss.item():.4f}, G_loss: {g_loss.item():.4f}')
# 每个epoch结束后生成图片
with torch.no_grad():
test_images = generator(fixed_noise).cpu()
# 保存结果
plt.figure(figsize=(8, 8))
for j in range(16):
plt.subplot(4, 4, j+1)
plt.imshow(test_images[j].squeeze(), cmap='gray')
plt.axis('off')
plt.suptitle(f'Epoch {epoch+1}', fontsize=16)
plt.savefig(f'gan_simple/epoch_{epoch+1:02d}.png')
plt.close()
print("训练完成!查看 gan_simple 文件夹中的结果")
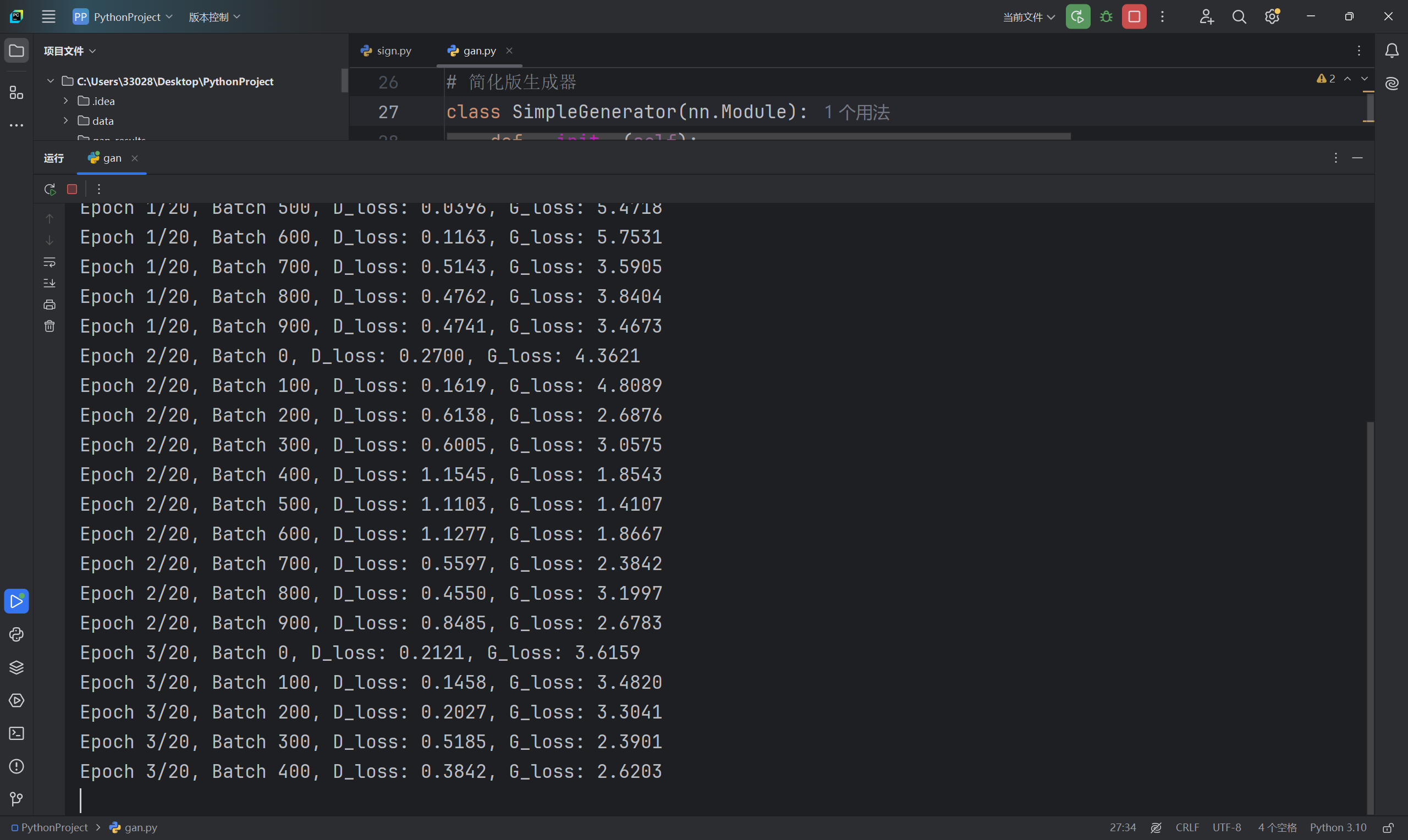
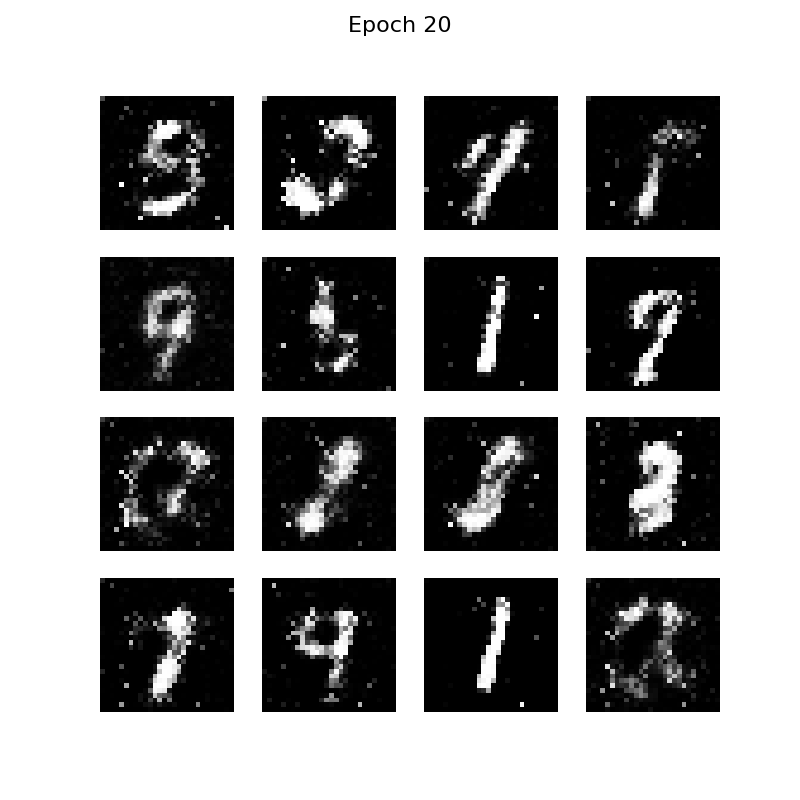
训练过程:
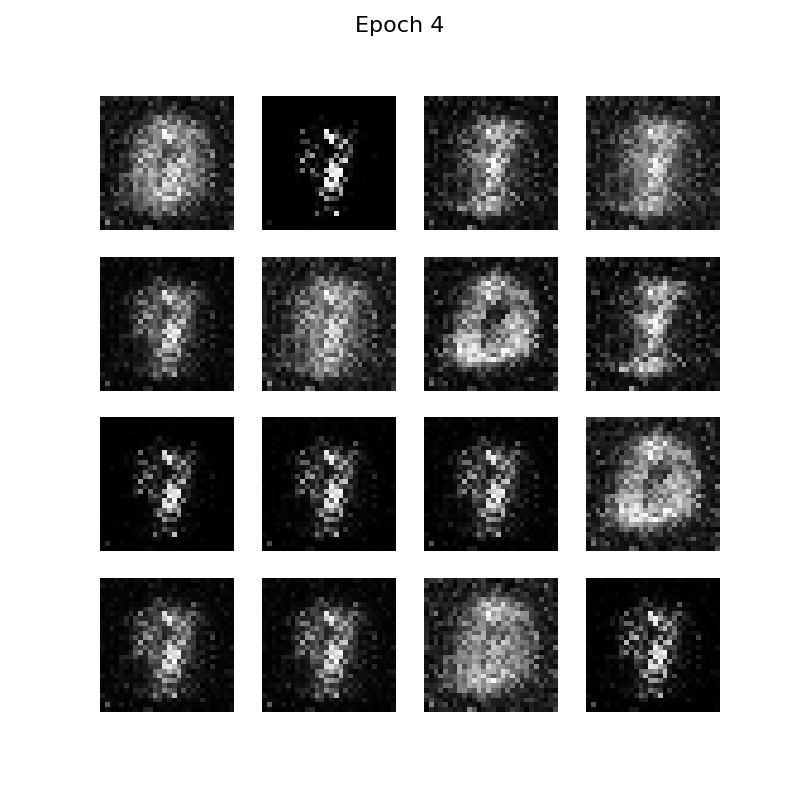
最终的结果:



































 1094
1094

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









