







 本文介绍了多层感知机的基本概念,通过解读Python代码实现,重点解析了线性层的构造和前向、反向传播过程。代码示例展示了如何使用`Linear`类构建一个多层神经网络,并使用sigmoid和ReLU作为激活函数。
本文介绍了多层感知机的基本概念,通过解读Python代码实现,重点解析了线性层的构造和前向、反向传播过程。代码示例展示了如何使用`Linear`类构建一个多层神经网络,并使用sigmoid和ReLU作为激活函数。
注:
目前仅提供原理的python代码实现,并未实例进行。如果有需要可以评论亦或者是查阅其他博客的实现过程
在本文的代码原理实现中,使用了Linear层进行搭建
MLP介绍:
MLP简称多层感知机,其结构与我的一篇博客BP神经网络(python实现)-CSDN博客相似,其实也可以讲大部分的神经网络结构相似,就比如多层感知机(MLP)、全连接神经网络(FCNN)、前馈神经网络(FNN)、深度神经网络(DNN)这些网络其实侧重点不同,但在大体结构上并未过多的差别,在此篇博客中有详细讲解:多层感知机(MLP)、全连接神经网络(FCNN)、前馈神经网络(FNN)、深度神经网络(DNN)与BP算法详解_mlp神经网络-CSDN博客
回到我们的正题,了解多层感知机之前,我们可以先了解一下单层感知机结构:
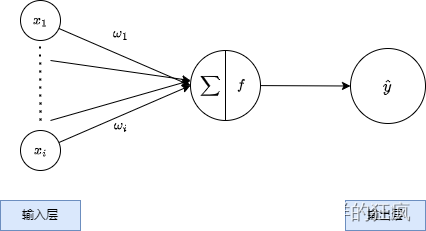
而在此基础上添加多层神经元,这样就是实现了多层感知机
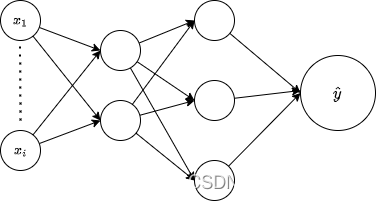
python实现:
在此处的实现来源于此篇博客
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1552
1552

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









