






多层感知机(MLP,Multilayer Perceptron)也叫人工神经网络(ANN,Artificial Neural Network),除了输入输出层,它中间可以有多个隐层,最简单的MLP只含一个隐层,即三层的结构.多层感知机是最简单的神经网络,其每一层由线性神经网络构成。如下图所示: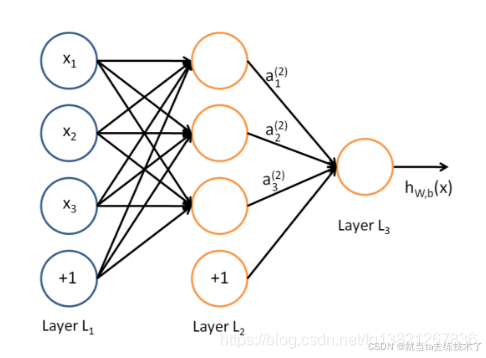
对于一个预测任务,怎么才能根据经验得到最佳的结果呢。比如要预测天气的任务,温度,湿度,云层厚度都是天气的影响因素。也就是说天气是关于温度,湿度,云层厚度的函数。一旦知道这个函数关系就可以通过当天的温度,湿度,云层厚度来预测天气。可是往往没有确切的一个数学表达式来描述这种函数关系,所以我们要通过神经网络来模拟这种函数。
加载数据和预处理:
housedata = fetch_california_housing()
# 切分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(housedata.data, housedata.target,test_size = 0.3, random_state = 42)
# 数据标准化处理
scale = StandardScaler()
X_train_s = scale.fit_transform(X_train)
X_test_s = scale.transform(X_test)
# 将数据集转为张量
X_train_t = torch.from_numpy(X_train_s.astype(np.float32))
y_train_t = torch.from_numpy(y_train.astype(np.float32))
X_test_t = torch.from_numpy(X_test_s.astype(np.float32))
y_test_t = torch.from_numpy(y_test.astype(np.float32))
train_data = Data.TensorDataset(X_train_t, y_train_t)
test_data = Data.TensorDataset(X_test_t, y_test_t)
train_loader = Data.DataLoader(dataset = train_data, batch_size = 64,
shuffle = True, num_workers = 0)这里加载的数据集是sklearn.datasets里加利福尼亚州的房屋数据,要实现预测房价这个任务。对于房价有8个影响因素。housedata里存的就是8个影响因素的数据和其对应的的房价。train_test_split是对数据集housedata.data(8个影响因素)和housedata.target(房价)进行分割。test_size=0.3是说测试集占总数据的0.3,训练集占总数的0.7.random_state随机数种子=42这个是默认不用改就好。
接下来是标准化处理,因为不同影响因素的值的大小之间差别可能非常大,所以要进行归一化。这里使用的是standardscaler包里的fit_transform对训练集和测试集进行归一化。
归一化后还要将数据集全部转化为张量tensor的形式,因为pytorch里神经网络在训练时,数据都是以tensor的形式存在的。而处理不了numpy数组这种数据,所以在构建训练网络之前要先进性数据的转换。
最后再将特征(影响因素)和标签(房价)用tensordataset做一个对应.train_loader是一个加载数据的管理器,dataset=train_data就是数据集里内容是训练集的特征,batch_size=64是一批训练64哥数据,shuffle=true是打乱数据的顺序,num_workers设置为0这样计算起来比较简单。
构建MLP网络模型
class MLPregression(nn.Module):
def __init__(self):
super(MLPregression, self).__init__()
# 第一个隐含层
self.hidden1 = nn.Linear(in_features=8, out_features=100, bias=True)
# 第二个隐含层
self.hidden2 = nn.Linear(100, 10)
# 第三个隐含层
self.hidden3 = nn.Linear(10, 50)
# 回归预测层
self.hidden4 = nn.Linear(50,25)
self.predict = nn.Linear(25, 1)
# 定义网络前向传播路径
def forward(self, x):
x = F.relu(self.hidden1(x))
x = F.relu(self.hidden2(x))
x = F.relu(self.hidden3(x))
x = F.relu(self.hidden4(x))
output = self.predict(x)
# 输出一个一维向量
return output[:, 0]
testnet = MLPregression()
# 定义优化器
optimizer = torch.optim.SGD(testnet.parameters(), lr = 0.01)
loss_func = nn.MSELoss() # 均方根误差损失函数
train_loss_all = []上面就是pytorch中构建网络的标准格式。nn.linear是构建的全连接层也就是线性的基本网络。首先是关于里面的几个参数,in_features=8是因为输入的原始数据的影响因素是8个,这个是对应数据集的情况是不能改变的,out_features=100这个是可以自己设置的隐藏层的个数,可以是任何正整数。bias=True是表示设置偏置项。同样后面的100,10,10,50,50,25,25这些参数都是可以改变的表示的是隐藏层的节点个数,而1是不可以改的,因为最后要得到的只有一个标签就是房价。所以除了8和1其他的参数都可以自己调节,甚至是中间隐藏层的个数。
后面的forward就是定义神经网络传播的路径,这里是选用的relu函数做的激发函数,当然也有其他函数可以作为激发。
最后定义优化器对网络的权重值做优化用的是torch.optim.SGD,使网络的参数越来越接近于预测值和实际值误差最小的方向改变,设置lr学习率=0.01。nn.mseloss是用来计算实际值和预测值之间的误差。
训练MLP网络模型
# 对模型迭代训练,总共epoch轮
for epoch in range(30):
train_loss = 0
train_num = 0
# 对训练数据的加载器进行迭代计算
for step, (b_x, b_y) in enumerate(train_loader):
output = testnet(b_x) # MLP在训练batch上的输出
loss = loss_func(output, b_y) # 均方根损失函数
optimizer.zero_grad() # 每次迭代梯度初始化0
loss.backward() # 反向传播,计算梯度
optimizer.step() # 使用梯度进行优化
train_loss += loss.item() * b_x.size(0)
train_num += b_x.size(0)
train_loss_all.append(train_loss / train_num)
# 可视化损失函数的变换情况
plt.figure(figsize = (8, 6))
plt.plot(train_loss_all, 'ro-', label = 'Train loss')
plt.legend()
plt.grid()
plt.xlabel('epoch')
plt.ylabel('Loss')
plt.show()
y_pre = testnet(X_test_t)
y_pre = y_pre.data.numpy()
mae = mean_absolute_error(y_test, y_pre)
print('在测试集上的绝对值误差为:', mae)最后对模型进行训练得到的误差下降图像如下图: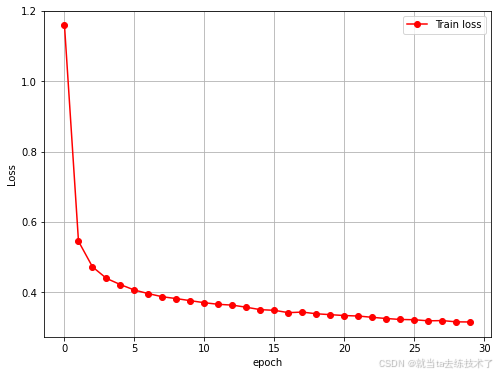
可以发现在训练的过程中训练的误差是一直下降的。
训练完网络后,用测试集做一个测试,可以发现绝对值误差是:
在测试集上的绝对值误差为: 0.4102067976196175
最后所有的主程序我放在这里:
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, mean_absolute_error
from sklearn.datasets import fetch_california_housing
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.optim import SGD
import torch.utils.data as Data
import matplotlib.pyplot as plt
import seaborn as sns
# 导入数据
housedata = fetch_california_housing()
# 切分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(housedata.data, housedata.target,test_size = 0.3, random_state = 42)
# 数据标准化处理
scale = StandardScaler()
X_train_s = scale.fit_transform(X_train)
X_test_s = scale.transform(X_test)
# 将数据集转为张量
X_train_t = torch.from_numpy(X_train_s.astype(np.float32))
y_train_t = torch.from_numpy(y_train.astype(np.float32))
X_test_t = torch.from_numpy(X_test_s.astype(np.float32))
y_test_t = torch.from_numpy(y_test.astype(np.float32))
train_data = Data.TensorDataset(X_train_t, y_train_t)
test_data = Data.TensorDataset(X_test_t, y_test_t)
train_loader = Data.DataLoader(dataset = train_data, batch_size = 64,
shuffle = True, num_workers = 0)
# 搭建全连接神经网络回归
class MLPregression(nn.Module):
def __init__(self):
super(MLPregression, self).__init__()
# 第一个隐含层
self.hidden1 = nn.Linear(in_features=8, out_features=100, bias=True)
# 第二个隐含层
self.hidden2 = nn.Linear(100, 10)
# 第三个隐含层
self.hidden3 = nn.Linear(10, 50)
# 回归预测层
self.hidden4 = nn.Linear(50,25)
self.predict = nn.Linear(25, 1)
# 定义网络前向传播路径
def forward(self, x):
x = F.relu(self.hidden1(x))
x = F.relu(self.hidden2(x))
x = F.relu(self.hidden3(x))
x = F.relu(self.hidden4(x))
output = self.predict(x)
# 输出一个一维向量
return output[:, 0]
testnet = MLPregression()
# 定义优化器
optimizer = torch.optim.SGD(testnet.parameters(), lr = 0.01)
loss_func = nn.MSELoss() # 均方根误差损失函数
train_loss_all = []
# 对模型迭代训练,总共epoch轮
for epoch in range(30):
train_loss = 0
train_num = 0
# 对训练数据的加载器进行迭代计算
for step, (b_x, b_y) in enumerate(train_loader):
output = testnet(b_x) # MLP在训练batch上的输出
loss = loss_func(output, b_y) # 均方根损失函数
optimizer.zero_grad() # 每次迭代梯度初始化0
loss.backward() # 反向传播,计算梯度
optimizer.step() # 使用梯度进行优化
train_loss += loss.item() * b_x.size(0)
train_num += b_x.size(0)
train_loss_all.append(train_loss / train_num)
# 可视化损失函数的变换情况
plt.figure(figsize = (8, 6))
plt.plot(train_loss_all, 'ro-', label = 'Train loss')
plt.legend()
plt.grid()
plt.xlabel('epoch')
plt.ylabel('Loss')
plt.show()
y_pre = testnet(X_test_t)
y_pre = y_pre.data.numpy()
mae = mean_absolute_error(y_test, y_pre)
print('在测试集上的绝对值误差为:', mae)


















 962
962

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









