#癌症分类预测 -- 良性 / 恶性乳腺癌肿瘤预测
import pandas as pd
import numpy as np
#获取数据(读取时加上names)
path = "https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data"
column_name = ['Sample code number', 'Clump Thickness', 'Uniformity of Cell Size', 'Uniformity of Cell Shape',
'Marginal Adhesion', 'Single Epithelial Cell Size', 'Bare Nuclei', 'Bland Chromatin',
'Normal Nucleoli', 'Mitoses', 'Class']
data1 = pd.read_csv(path,names = column_name)
display(data1.head())
#数据处理(处理缺失值)
data1 = data1.replace(to_replace = "?",value = np.nan)
data1.dropna(inplace = True)
# data1.isnull().any()
#数据集划分
from sklearn.model_selection import train_test_split
x = data1.iloc[:,1:-1]
# display(x)
y = data1["Class"]
# display(y)
x_train,x_test,y_train,y_test = train_test_split(x,y)
#特征工程(标准化)
from sklearn.preprocessing import StandardScaler
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
#逻辑回归预估器
from sklearn.linear_model import LogisticRegression
estimator = LogisticRegression()
estimator.fit(x_train,y_train)
#逻辑回归的模型参数:权重系数和偏置
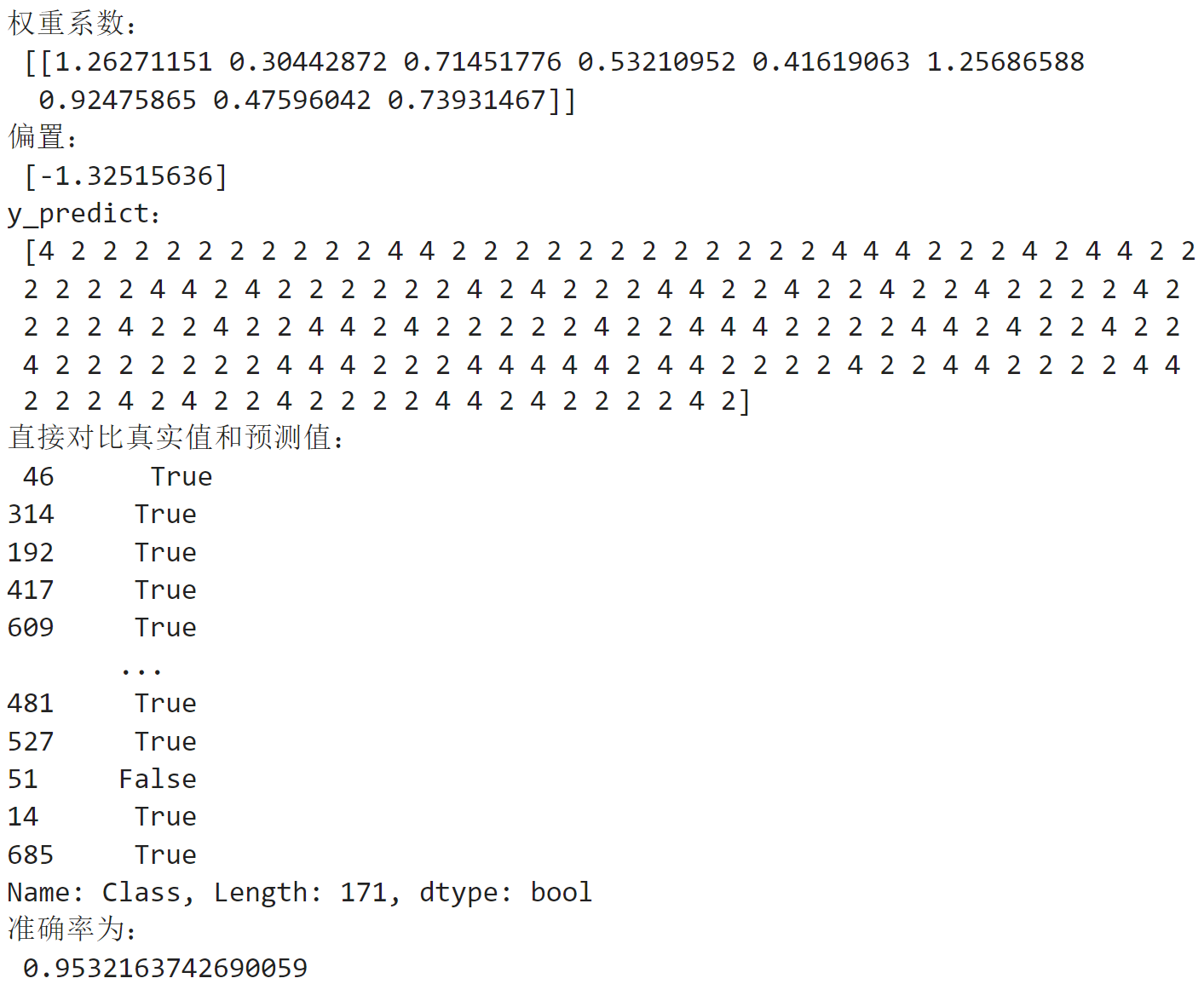
print("权重系数:\n",estimator.coef_)
print("偏置:\n",estimator.intercept_)
#模型评估
#方法一:直接对比真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n",y_predict)
print("直接对比真实值和预测值:\n",y_test == y_predict)
#方法二:计算准确率
score = estimator.score(x_test,y_test)
print("准确率为:\n",score)

























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









