






构建模型(假设为mde1)后,接下来就是训练模型。pyToxch训练模型主要包括加载数据集、损失计算、定义优化算法、反向传播、参数更新等主要步骤。
1.加载预处理数据集
加载和预处理数据集,可以使用PyTorch的数据处理工具,如torch.utils和torchvision等,这些工具将在第4章详细介绍。
2.定义损失函数
定义损失函数可以通过自定义方法或使用PvIorch内署的损失函数,如回归使用的loss fimem, SELoss0),分类使用的m.BCELoss等损失函数,更多内容可参考本书5.2.4节。
3.定义优化方法
Pytoch常用的优化方法都封装在torch.optin里面,其设计很灵活,可以扩展为自定义的优化方法。所有的优化方法都是继承了基类optin.optinizer,并实现
了自己的优化步骤。
最常用的优化算法就是梯度下降法及其各种变种,具体将在5.4节详细介绍,这些优化算法大多使用梯度更新参数。如使用SGD优化器时,可设需为optimizer=torch.optim.sGD(params,lr=0.001)。
4.循环训练模型
1)设需为训练模式:
model.train()
调用model.train()会把所有的module设置为训练模式。
2)梯度清零:
optimizer.zero grad()在默认情况下梯度是累加的,需要手工把梯度初始化或清零,调用optimizer.zero_grad()即可。3)求损失值:yprevmodel(x)loss=loss fu(y prev,y true)4)自动求导,实现梯度的反向传播:loss.backward()5)更新参数:optimizer.step)
5.循环测试或验证模型1)设置为测试或验证模式:
model.eval()
调用model.eval()会把所有的training属性设置为False。2)在不跟踪梯度模式下计算损失值、预测值等:
with.torch.no grad():
- 可视化结果下面我们通过实例来说明如何使用nm来构建网络模型、训练模型。说明,model.train()与model.eval()的使用如果模型中有BN(Batch Normalization)层和Dropout,需要在训练时添加model.train(),在测试时添加mode1,exa10)。其中mode1,tain(0)是保证B层用每一批数据的均值和方差,而mode1:exa10)是保证取用全部训练数据的均值和方差;而对干Dropout,mode1.train()是随机取一部分网络连接来训练更新参数,而mode1.eva1()是利用到了所有网络连接。
3.5实现神经网络实例
前面我们介绍了使用PVTorch构建神经网络的一些组件、常用方法和主要步骤等,本节通过一个构建神经网络的实例把这些内容有机结合起来,
3.5.1背景说明
本节将利用神经网络完成对手写数字进行识别的实例,来说明如何借助m工具箱来实现一个神经网络,并对神经网络有个直观了解。在这个基础上,后续我们将对nm的各模块进行详细介绍。实例环境使用PyTorch1.5+,GPU或CPu,源数据集为IDIIST。
主要步骤如 下。
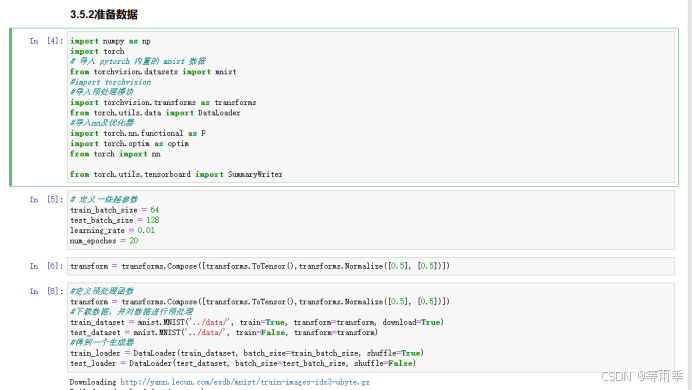
利用PyTorch内置函数mnist下载数据。
利用torchvision对数据进行预处理,调用torch.utils建立一个数据选代器。
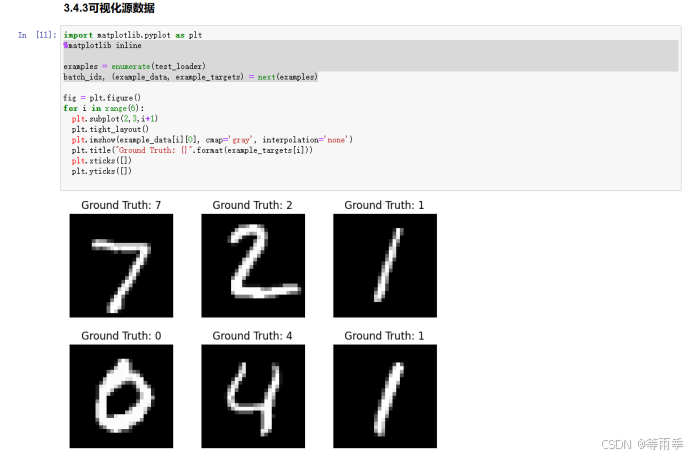
可视化源数据。
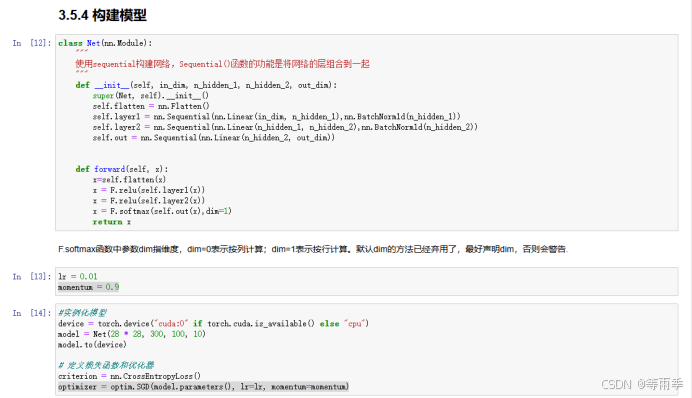
利用nn工具箱构建神经网络模型。
实例化模型,并定义损失函数及优化器。
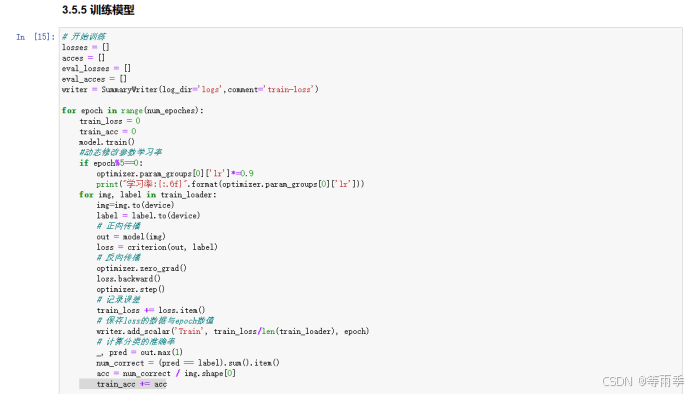
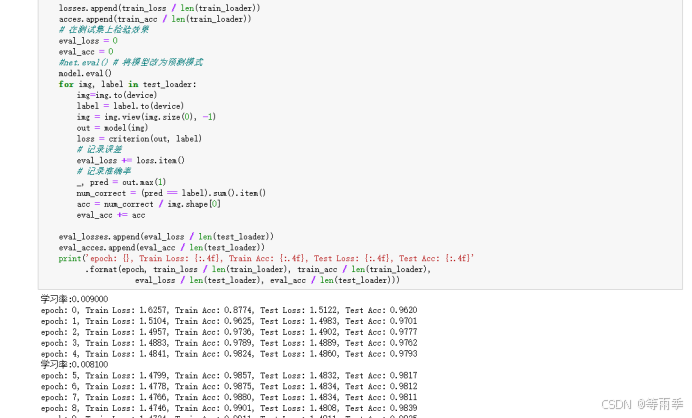
训练模型。
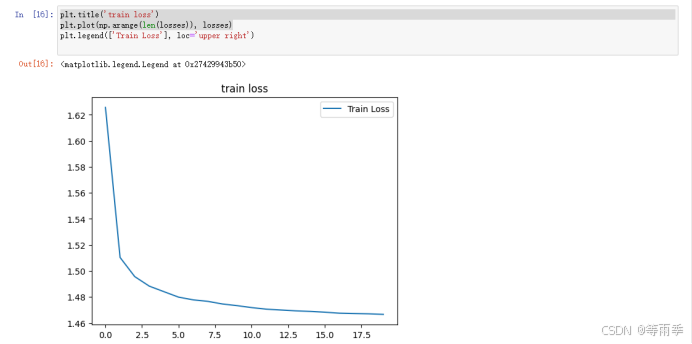
可视化结果。
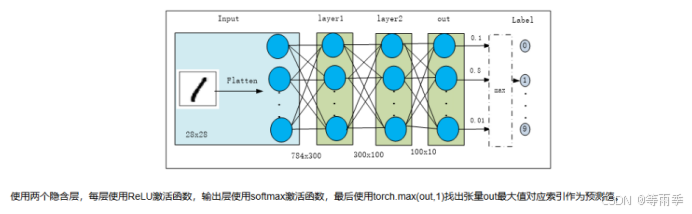
神经网络的结构如图3-5所示:

















 2174
2174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









