






基于LLaMA-Factory对Qwen进行lora微调
1.实验环境
1.1 系统和硬件
- windows
- 3050(4GB显存)
1.2 环境搭建
-
LLaMA-Factory
git clone https://github.com/hiyouga/LLaMA-Factory.git cd LLaMA-Factory pip install -e '.[torch,metrics]' -
卸载CPU版本的torch并更换GPU版本的torch
pip uninstall torch torchvision torchaudio -y pip install torch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1 --index-url https://download.pytorch.org/whl/cu121
1.3 模型以及数据集下载
-
模型选择了
Qwen2.5-0.5B-instructgit clone https://www.modelscope.cn/Qwen/Qwen2.5-0.5B-Instruct.git -
数据集选择了华东师范大学开源的educhat-sft-002-data-osm
git clone https://huggingface.co/datasets/ecnu-icalk/educhat-sft-002-data-osm
2.数据处理
使用自定义数据集进行微调时,需要将数据集转换成AIpaca格式或者ShareGPT格式,并在data_info.json中注册
-
Educhat-sft的原始格式

-
需要的数据集格式
其中 human 和 observation 必须出现在奇数位置,gpt 和 function 必须出现在偶数位置
[ { "conversations": [ { "from": "human", "value": "人类指令" }, { "from": "function_call", "value": "工具参数" }, { "from": "observation", "value": "工具结果" }, { "from": "gpt", "value": "模型回答" } ], "system": "系统提示词(选填)", "tools": "工具描述(选填)" } ] -
注册
在
data_info.json文件中添加"数据集名称": { "file_name": "路径", "formatting": "sharegpt", "columns": { "messages": "conversations", "system": "system" } }
3.模型训练
-
训练配置文件
examples/train_lora/llama3_lora_sft修改### model model_name_or_path: ../Qwen2.5-0.5B-Instruct # 模型目录 trust_remote_code: true ### method stage: sft # 训练阶段 do_train: true finetuning_type: lora lora_rank: 8 # lora微调秩的大小,影响显存占用以及训练效果 lora_target: all ### dataset dataset: identity, res # 数据集名称,使用逗号隔开 template: qwen # 模板名程 cutoff_len: 2048 max_samples: 1000 overwrite_cache: true preprocessing_num_workers: 16 ### output output_dir: saves/Qwen-0.5b-identity/lora/sft # 输出 logging_steps: 10 save_steps: 500 plot_loss: true overwrite_output_dir: true ### train per_device_train_batch_size: 1 gradient_accumulation_steps: 8 learning_rate: 1.0e-4 num_train_epochs: 3.0 lr_scheduler_type: cosine warmup_ratio: 0.1 bf16: true # resume_from_checkpoint: saves/Qwen-0.5b/lora/sft/checkpoint-2500 # 断点续训目录 ddp_timeout: 180000000 ### eval # eval_dataset: alpaca_en_demo # val_size: 0.1 # per_device_eval_batch_size: 1 # eval_strategy: steps # eval_steps: 500 -
使用以下命令开始训练
llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml
4.微调模型推理
-
原始模型直接推理
修改
examples/inference/llama3.yamlmodel_name_or_path: ../Qwen2.5-0.5B-Instruct # 路径 template: qwen # 模板 infer_backend: huggingface # choices: [huggingface, vllm] trust_remote_code: true启动
llamafactory-cli webchat examples/inference/llama3.yaml效果如下:

-
微调模型推理
使用以下命令启动:
llamafactory-cli webchat --model_name_or_path ../Qwen2.5-0.5B-Instruct --adapter_name_or_path ./saves/QWen-0.5b-identity/lora/sft --template qwen --finetuning_type lora简单微调后,再次询问相似的问题效果如下;

5.模型合并
-
修改
/examples/merge_lora/llama3_lora_sft.yaml配置,将模型路径以及微调得到的权重路径进行修改。### Note: DO NOT use quantized model or quantization_bit when merging lora adapters ### model model_name_or_path: ../Qwen2.5-0.5B-Instruct # 模型路径 adapter_name_or_path: ./saves/Qwen-0.5b-identity/lora/sft # 微调得到的权重路径 template: qwen trust_remote_code: true ### export export_dir: output/qwen_lora_sft_1 # 输出路径 export_size: 5 export_device: auto export_legacy_format: false -
修改完配置文件后,使用下列指令导出合并后的模型
llamafactory-cli export ./examples/merge_lora/llama3_lora_sft.yaml
6.模型评估
-
llama-factory提供了对
cmmlu,mmlu,ceval的评测脚本,使用以下命令可以对微调前后的模型进行简单的评测:llamafactory-cli eval ` --model_name_or_path ../Qwen2.5-0.5B-Instruct ` # 模型路径 --template qwen ` --task cmmlu_test ` # 评测数据集 --lang zh ` # 语言 --n_shot 5 ` --batch_size 1 ` --trust_remote_code True -
模型在
cmmlu的中文评估结果如下:原始模型:
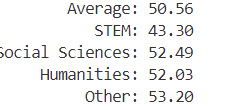
微调后的模型:
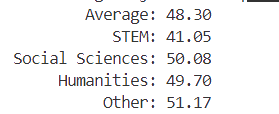
可能由于参数设置问题,导致微调后的模型相较于原始模型,模型各个方向的能力都出现了一定的下滑。
Lora微调原理
1. 其他微调方法
-
全量微调
对于模型中的所有矩阵中的参数,都必须参与更新。
- 主要优点:最大程度适应特定任务
- 主要缺点:计算资源消耗量大,显存占用大,训练时间长,资源受限场景下不适合
-
adapter tuning
针对全量微调计算资源消耗大的缺点,adapter turng在Transformer的基础上增加了一个adapter 模块,在微调时,除了该模块,模型的其他部分都是冻结的
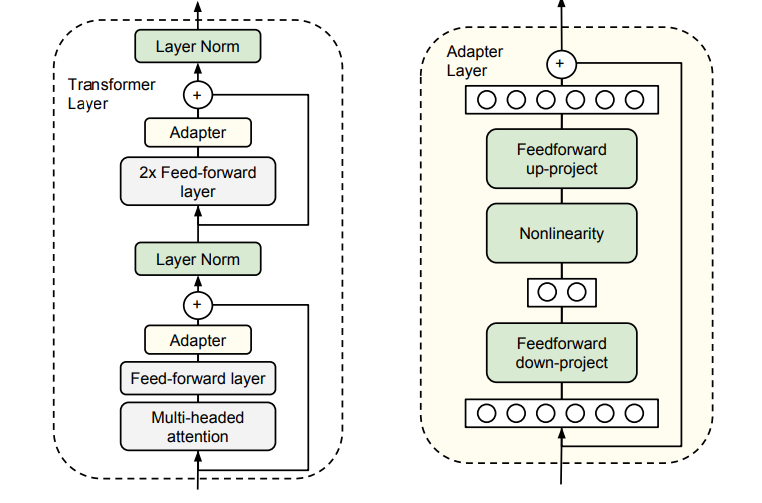
- 优点:相对于全量微调而言,adapter训练的参数量减小,更加节省资源。
- 缺点:增加adapter后,模型的层数变深,推理速度和训练速度减慢。
-
prefix tuning
prefix tuning是在模型的输入部分添加一系列可训练的前缀向量,这些向量会和输入数据一起被送入模型,从而影响模型的行为。
- 优点:显著减少训练的参数量,并且不会增加推理时间
- 缺点:
- 较难训练,且模型的效果并不严格随prefix参数量的增加而上升
- 会使得输入层有效信息长度减少。增加了prefix之后,留给原始文字数据的空间就少了,因此可能会降低原始文字中prompt的表达能力。
2.Lora微调
-
整体架构:
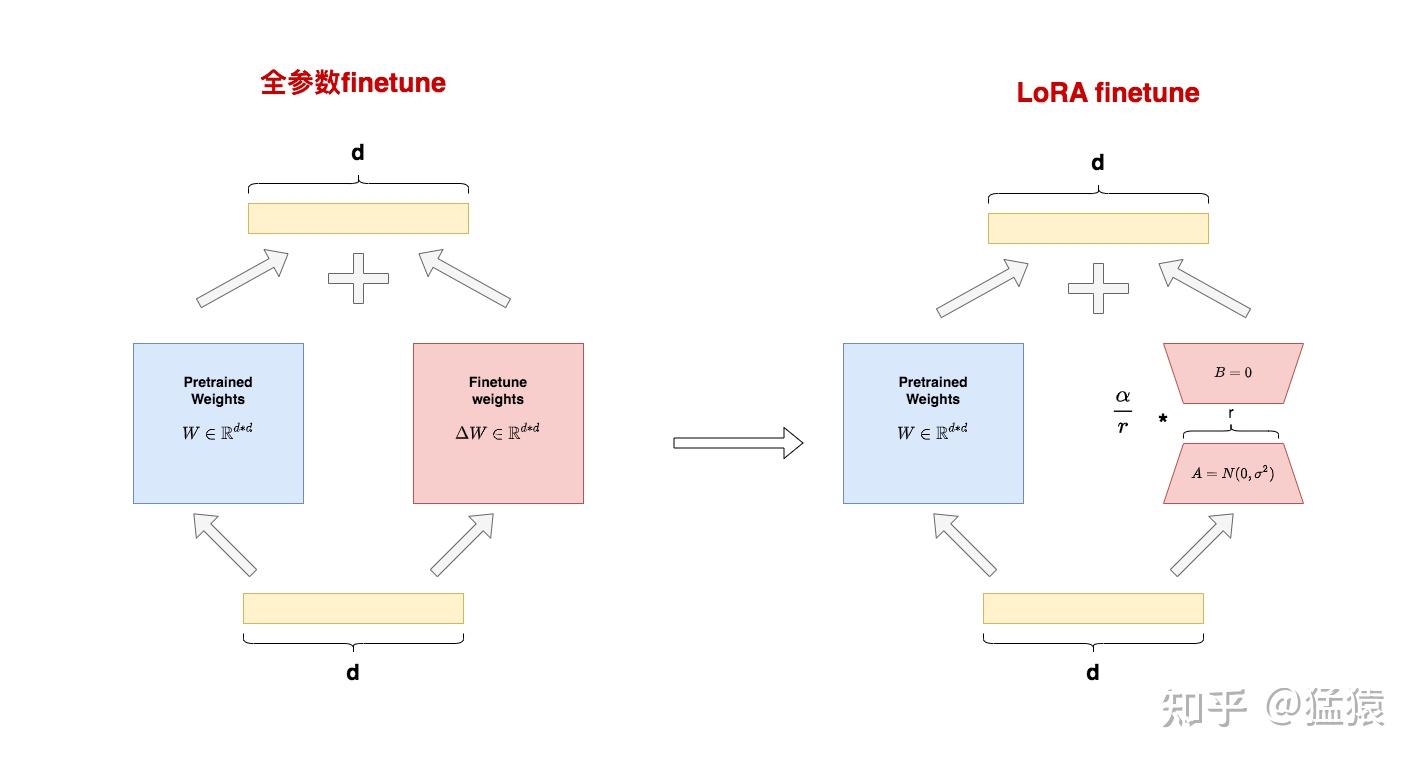
左侧将全参数微调分成两个部分,一个是冻结的权重$W$,另一个是微调产生的权重增量$ \Delta W $,此时有$ h=Wx+ \Delta Wx$,Lora 在该想法的基础上,将 $\Delta W $进一步拆解成两个低秩矩阵$A$, $B$的乘积,即$h = Wx + BAx$。
在原始预训练矩阵的旁路上,用低秩矩阵A和B来近似替代增量更新 $\Delta W$,训练只更新$A$, $B$矩阵,以此降低显存占用,达到高效微调的目的
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近70次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

五、AI产品经理大模型教程

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









