







目录
3.2 K近邻分类(K-Nearest Neighbors, KNN)
3.4 K-means聚类(K-Means Clustering)
第一章:机器学习概述
1.1 什么是机器学习?
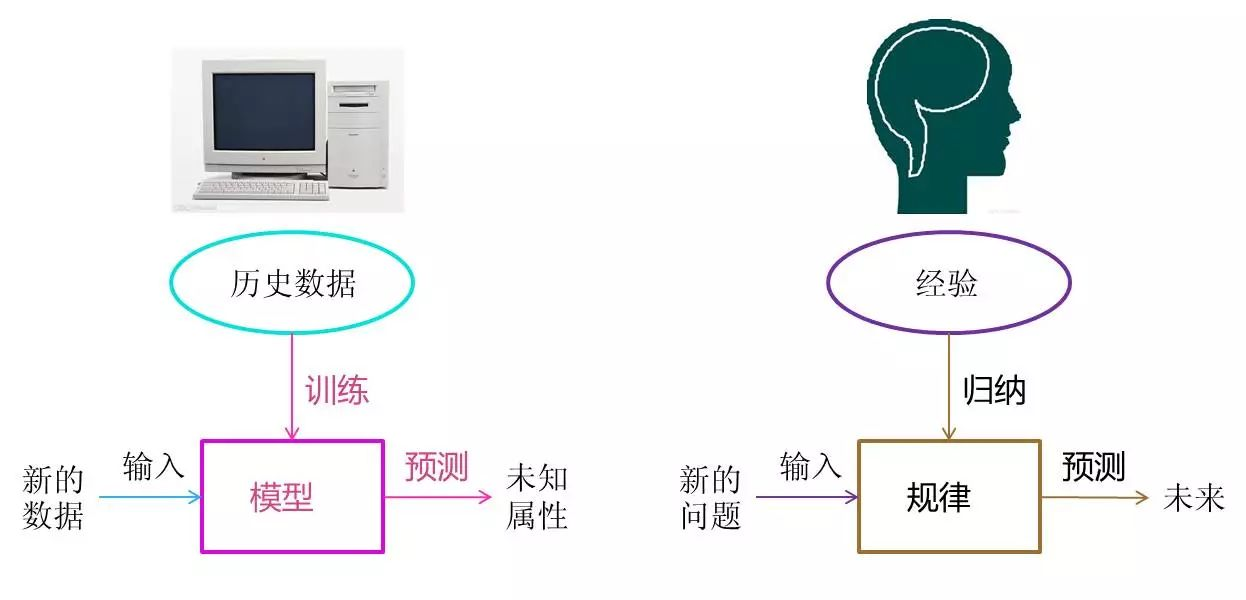
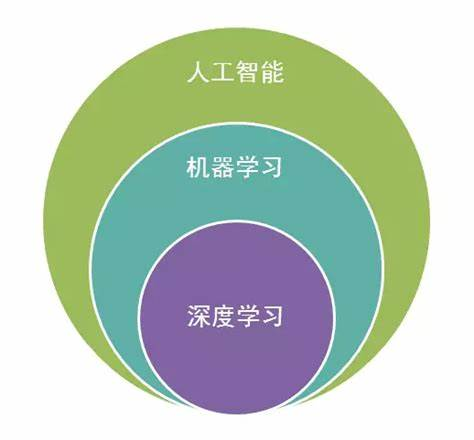
机器学习(Machine Learning, ML)是人工智能(AI)的一个重要分支,其核心思想是通过算法从数据中自动学习规律,并利用这些规律对未知数据进行预测或决策。与传统编程不同,机器学习不需要人为编写明确的规则,而是通过数据驱动的方式构建模型。
1.2 机器学习的主要类型
-
监督学习(Supervised Learning)
- 定义:使用带标签的数据进行训练,模型通过学习输入特征与输出标签之间的映射关系,预测新数据的标签。
- 典型任务:分类(如垃圾邮件识别)、回归(如房价预测)。
- 常见算法:线性回归、逻辑回归、决策树、支持向量机(SVM)、K近邻(KNN)。
-
无监督学习(Unsupervised Learning)
- 定义:使用无标签的数据进行训练,模型通过发现数据中的隐藏结构或模式进行学习。
- 典型任务:聚类(如客户分群)、降维(如PCA)。
- 常见算法:K-means聚类、DBSCAN、主成分分析(PCA)。
-
强化学习(Reinforcement Learning)
- 定义:智能体在环境中通过试错学习最优策略,以最大化长期奖励。
- 典型任务:游戏AI(如AlphaGo)、自动驾驶。
- 常见算法:Q-learning、深度Q网络(DQN)。
第二章:机器学习的数学与编程基础
2.1 数学基础
机器学习的核心依赖于以下数学知识:
-
线性代数
- 矩阵运算、特征值分解、奇异值分解(SVD)。
- 应用场景:神经网络的权重更新、降维算法(如PCA)。
-
概率论与统计学
- 概率分布、贝叶斯定理、最大似然估计(MLE)。
- 应用场景:朴素贝叶斯分类器、生成对抗网络(GAN)。
-
微积分
- 导数、梯度、链式法则。
- 应用场景:梯度下降法优化模型参数。
-
优化理论
- 凸优化、非凸优化、梯度下降、牛顿法。
- 应用场景:损失函数最小化。
2.2 编程基础
机器学习的实现主要依赖Python语言及其科学计算库:
-
Python基础
- 数据类型(列表、字典、元组)、循环、函数、面向对象编程。
-
科学计算库
- NumPy:用于高效处理数组和矩阵运算。
- Pandas:用于数据清洗和处理(如缺失值填充、数据标准化)。
- Matplotlib/Seaborn:用于数据可视化(如散点图、直方图)。
- Scikit-learn:提供机器学习算法和工具(如KNN、K-means)。
- TensorFlow/PyTorch:用于深度学习模型的构建和训练。
第三章:经典机器学习算法与代码示例
3.1 线性回归(Linear Regression)
3.1.1 原理
线性回归是一种用于预测连续值的监督学习算法。假设目标变量 yy 与输入特征 xx 之间存在线性关系,模型形式为:
y = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \dots + \beta_n x_ny=β0+β1x1+β2x2+⋯+βnxn
其中,\betaβ 是模型参数,通过最小化损失函数(如均方误差)来优化。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











