







高性能内存数据库的深度解析与技术对比
目录

一、Redis简介
Redis(Remote Dictionary Server)是一款开源的高性能键值存储系统,因其卓越的性能和丰富的数据结构支持,已成为现代互联网架构中的核心组件。自2009年由Salvatore Sanfilippo(antirez)开发以来,Redis已经从一个简单的键值存储工具演变为支持分布式集群、持久化、事务处理等复杂功能的内存数据库。
Redis的核心特性包括:
- 内存存储:数据存储在内存中,提供微秒级的读写速度。
- 多种数据类型:支持字符串、哈希、列表、集合、有序集合等数据结构。
- 持久化:通过RDB快照和AOF日志实现数据持久化。
- 高可用性:支持主从复制、哨兵模式和集群模式。
- 分布式锁:通过原子操作实现分布式锁。
- 发布/订阅:支持消息队列功能。
二、Redis的核心特性
1. 内存存储与高性能
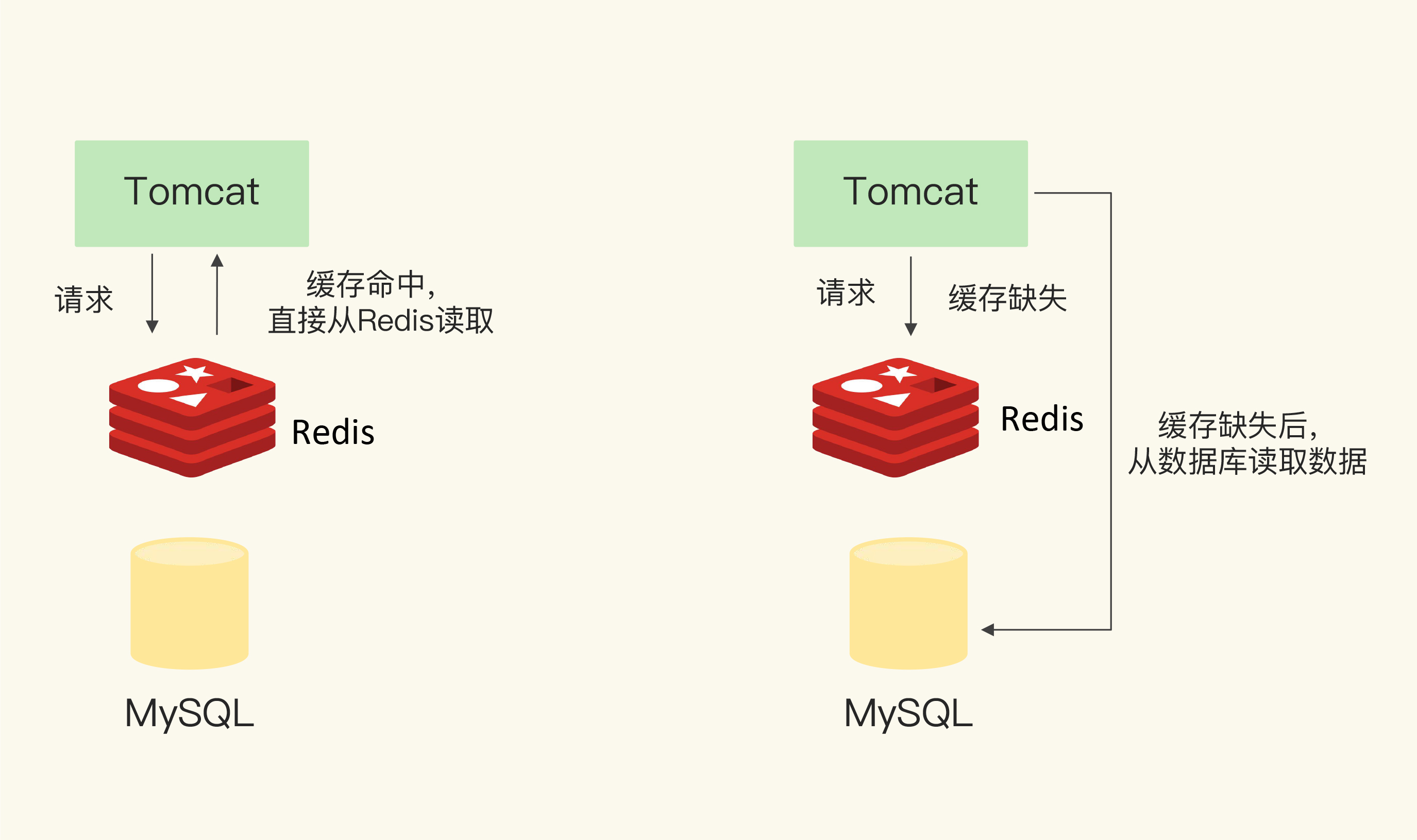
Redis将数据存储在内存中,避免了磁盘I/O的延迟。其单线程模型通过事件驱动和非阻塞IO实现高并发性能。例如,Redis在单机环境下可以处理10万+ QPS(每秒查询数)。
对比传统关系型数据库:
- MySQL:基于磁盘存储,读写速度受限于磁盘I/O,通常为毫秒级。
- PostgreSQL:虽然支持复杂的查询和事务,但性能仍无法与Redis的内存存储相比。
案例:某电商平台的用户登录功能,将用户会话信息存储在Redis中,响应时间从原来的10ms降低到1ms。
# Python示例:使用Redis存储用户会话
import redis
import uuid
r = redis.Redis(host='localhost', port=6379, db=0)
# 用户登录时生成会话ID
session_id = str(uuid.uuid4())
user_id = 12345
r.set(f"session:{session_id}", user_id, ex=3600) # 设置过期时间为1小时
# 验证会话
def validate_session(session_id):
user_id = r.get(f"session:{session_id}")
if user_id:
return int(user_id)
return None2. 丰富的数据结构
Redis支持多种数据结构,使其能够适应不同的业务场景:
| 数据类型 | 用途 | 示例 |
|---|---|---|
| String | 存储简单的键值对 | 缓存用户信息 |
| Hash | 存储对象属性 | 缓存商品详情 |
| List | 实现消息队列 | 日志记录 |
| Set | 去重和集合运算 | 用户标签管理 |
| ZSet(有序集合) | 排行榜 | 游戏积分排名 |
对比Memcached:
- Memcached仅支持简单的键值对,而Redis提供了更复杂的数据结构。
- Redis的有序集合可以高效实现排行榜功能,而Memcached需要额外的业务逻辑。
案例:某在线游戏的积分排行榜,使用Redis的ZSet存储玩家积分。
# Python示例:使用ZSet实现排行榜
import redis
r = redis.Redis(host='localhost', port=6379, db=0)
# 添加玩家积分
r.zadd("player_scores", {"player:1": 1000, "player:2": 800, "player:3": 1200})
# 获取前10名玩家
top_players = r.zrange("player_scores", 0, 9, withscores=True)
print(top_players) # 输出: [(b'player:3', 1200.0), (b'player:1', 1000.0), ...]3. 持久化与容灾
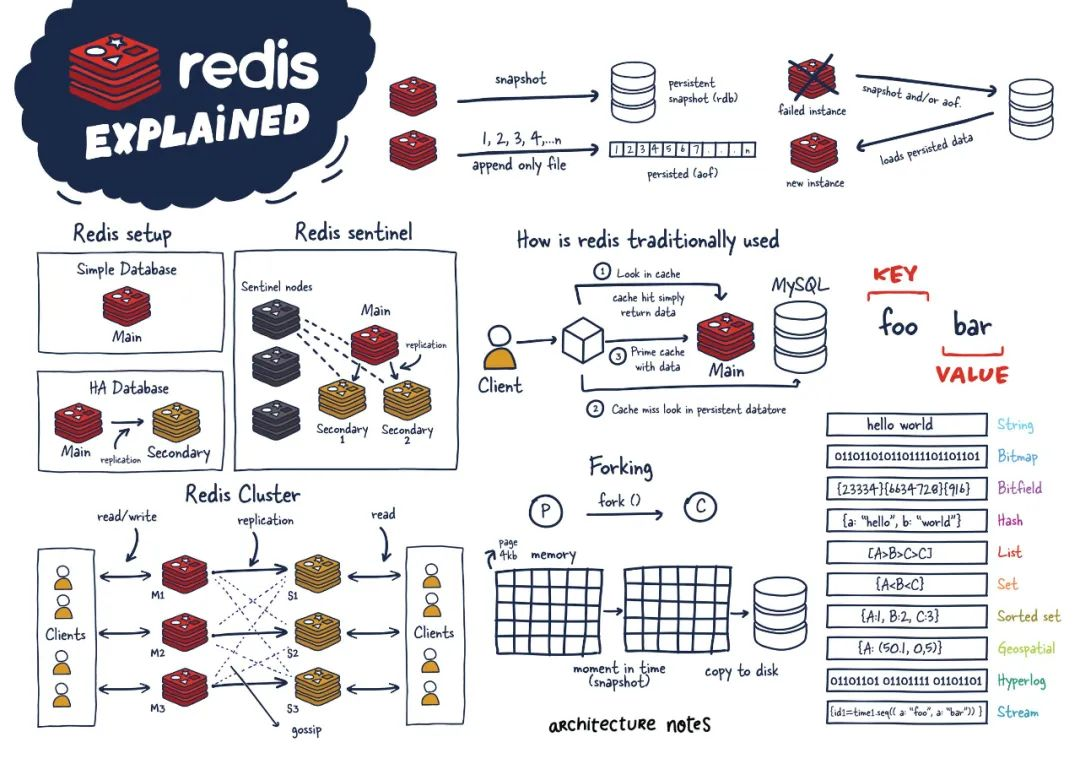
Redis通过两种机制实现数据持久化:
- RDB(快照):定期将内存数据保存到磁盘文件(如
dump.rdb)。 - AOF(Append-Only File):记录每个写操作命令,重启时通过重放命令恢复数据。
对比Memcached:
- Memcached默认不支持持久化,数据丢失风险高。
- Redis通过RDB和AOF结合,可以在崩溃后快速恢复数据。
案例:某金融系统的交易记录缓存,使用AOF模式确保数据一致性。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 887
887

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











